 電子發燒友App
電子發燒友App


當前,全球處在一個由工業時代逐步過渡到信息時代的階段,數據正在成為世界上最有價值的資源。伴隨人類的各種行為,產生了龐大的數據,如何存儲這些數據并進一步利用好數據,這個問題變得越來越重要。從內部部署存儲遷移到云存儲是過去十年的主題,而且這一趨勢正在加速。另一方面,大量的存儲空間在世界各地的人們的硬盤上未被使用,很多資源在無形中被浪費了。
區塊鏈技術的誕生,為軟件定義存儲的發展開辟了新的道路。它創造了一種可能:在技術層面和經濟體系層面重新思考云存儲并解決行業困境。首先,存儲的池化可以在更廣闊的空間,以更豐富的形態來實現。其次,區塊鏈的 Token 激勵機制,可以驅動大家將企業級存儲、服務器、PC、移動存儲等的剩余存儲空間貢獻出來。最后,每個節點實際存放的數據只是數據的一些切片,而且這些切片還以加密的方式保存起來。數據能夠更安全地保護起來,即使提供存儲節點的用戶有機會查看這些切片,看到的也是沒有實際意義的數據段。區塊鏈的DAO這種分布式商業模式,有機會借助全球的資源和人才,類似眾人拾柴火焰高一樣,加速分布式存儲產業的發展。與現有云存儲解決方案相比,基于區塊鏈的分布式存儲更安全、更快、成本更低、更具審查性,并且分布更廣。它創造了一個允許人們把他們備用存儲空間貨幣化的市場,全球存儲市場的涌入的供應將降低存儲價格。區塊鏈能夠保證以安全、去信任、點對點的方式做到這一點。從中心化存儲到去中心化存儲。從中心化互聯網到去中心化互聯網。我們正站在歷史的轉折點。
基于區塊鏈的分布式存儲優勢:
1)分布式存儲真正發揮了共享經濟的優勢。用戶可以將硬盤的空余空間充分的利用起來,并且獲得收益。
2)數據被切割成小塊后,需要經過加密后才會分散到眾多節點上。即避免了中心化存儲“竊取”文件的事件,同時即便解鎖某一塊數據,也只是部分數據,并非全部。另外,也不用擔心中心化服務器因為故障造成的數據泄露等風險。
3)文件在下載的過程中,碎片會進行重組,并行的速度會遠大于中心化存儲。
什么是IPWeb?
在此基礎上構建的分布式存儲服務平臺,比中心化存儲更快捷、更安全、成本更低。將文件分割成多個小的部分(保證一定的冗余性),分散存儲在網絡眾多節點上,只要一定數量節點的正常運轉,就能保證文件的安全和完整。
當用戶輸入一個 URL 在網頁瀏覽器來獲取網上信息時,URL 會解析到一個 IP 地址。這個 IP 地址會找到存儲著用戶所需要尋找的信息的那臺服務器。網上的幾乎每個發布者,供應商和服務都會把信息存在他們控制的特定的數據中心的服務器里,這就讓我們今天的網絡變得中心化。
IPWeb 網絡協議本身能確保用戶的文件得到存儲。作為 IPWeb 挖礦過程中產生的副產品,創新的加密證明給客戶創造了一套有用且有價值的服務。礦工被激勵去用他們的硬盤空間在 IPWeb 的可驗證的存儲市場上賺錢,他們將會得到等量的獎勵:礦工存儲的量越大,他們將會賺取更多的權益證明 -Token。
我們相信,這些新增的去中心化的儲存空間供應會讓客戶減低網絡存儲花費且享受到更優質的存儲服務。作為一個去中心化的協議,網絡上儲存的數據和與這些數據的鏈接不會被一個中央點所控制,這種設置能提高牢靠性。比起現在單一集中的服務器和大型內容分發網絡,在 IPWeb 礦工間被大規模傳送的信息會被儲存在更靠近用戶的地方,使信息搜索更加快捷。在 IPWeb 上通過加密算法被編入檢索的數據能夠使客戶更加高效地管理和更新龐大的數據。最后,作為一個開源項目,不同于今天大多數的云存儲與分發平臺,IPWeb 軟件本身公開接受檢查,驗證和提升。隨著 IPWeb 的不斷升級與新功能不斷地被加入,我們希望 IPWeb 的網絡可以成為一個面向大眾(即使不是所有人)的網絡信息存儲和分發的平臺。
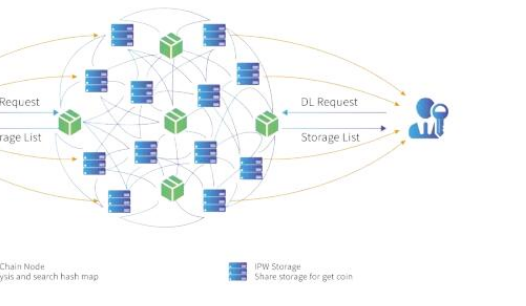
IPWeb的基礎設施
IPWeb 將為所有生態參與者提供多種基礎設施,包括:
· 基于共享經濟模式的 P2P 云存儲服務;
· 連接全球數據的 P2P 數據交易平臺;
· P2P 去中心化互聯網:IPWeb 協議下的域名系統、瀏覽器;
· 去中心化服務和內容平臺;
· 區塊鏈:高性能公有鏈、自定義側鏈;
· 基于去中心化互聯網生態的數字貨幣。

IPWeb的技術體系
1. 總體架構設計

IPWeb計算文件的哈希值作為系統中對象的唯一標識,文件進行加密、編碼后產生的碎片為對象數據。存儲節點將對象數據存儲在自己的存儲單元中,超級節點負責維護對象數據到存儲節點的映射關系。其中存儲節點是完全對等的,通過一套 P2P傳輸協議,存儲節點間可相互傳輸數據。超級節點作為調度者,接受存儲節點的信息,并根據廣播更新存儲對象的實時信息,以便用戶訪問存儲對象時可快速的返回對象位置。
1.1 雙層網絡設計
IPWeb將存儲和檢索兩層網絡分離,提高了網絡效率,也降低了挖礦門檻。存儲和檢索對于礦機的要求是不一樣的。檢索需要昂貴的算力和能源消耗,而存儲需要存閑置的存儲資源和帶寬資源。存儲和檢索分離更有助于以低成本的礦機為IPWeb貢獻。
1.2 多鏈結構(主側鏈設計:多鏈多共識)
IPW Chain主鏈采用PoRep(復制證明)、PoE(提取證明)。IPW Chain提供Consensus接口,提供POW、POS、DPOS等實裝。開發者可以通過主鏈提供的Consensus接口創建并完成自己節點的部署。對性能要求高的側鏈可以采用DPOS,對去中心化要求高的可以采用POW。
2. 存儲網絡
2.1 DHT
P2P 的本質即是一種新的網絡傳播技術。這種新的傳播技術打破了傳統的架構,逐步地去中心化,扁平化,從而達到節點平等的未來趨勢。P2P 文件分享的應用(BTs/eMules 等 ) 是 P2P 技術最集中的體現。IPWeb 是以 P2P 文件分享網絡作為入口,圍繞一個文件網絡系統,將其可操作性結合區塊鏈的公式算法設計出新型扁平化,去中心化的云存儲網絡。同時保留了區塊鏈公開,透明的特性。
分布式哈希表 DHT(Distributed Hash Table)是一種分布式存儲方法。在 DHT中,一類可由鍵值來唯一標示的信息按照某種約定 / 協議被分散地存儲在多個節點上,可以有效地避免“中央集權式”的服務器(比如:Tracker)的單一故障而帶來的整個網絡癱瘓。和中心節點服務器不同,DHT 網絡中的各節點并不需要維護整個網絡的信息,而是只在節點中存儲其臨近的后繼節點信息,大幅減少了帶寬的占用和資源的消耗。DHT 網絡還在與關鍵字最接近的節點上備份冗余信息,避免了單一節點失效問題。
實現 DHT 的技術 / 算法有很多種,如 Chord、CAN、Pastry、Kademlia 等。考慮技術成熟度以及市場運用情況,IPWeb 使用 Kademlia 算法。Kademlia 通常又被稱為第三代 P2P 技術,是一種 P2P 通用協議,適用于所有的分布式點對點計算機網絡。Kademlia 定義了網絡的結構,規劃了節點之間的通訊以及具體的信息交互過程。在Kademlia 中,網絡節點之間使用 UDP 進行通信,通過一種分布式哈希表來存儲數據,每個節點都會有一個自己的 ID,在用來標識節點本身的同時,也用以協助實現Kademlia 算法和流程。
2.2 KAD 網絡
KAD DHT 存儲網絡中的節點(Node)包括如下特性:
· NodeID 在 KAD 中需要是 160bits 或者 20bytes;
· Contact 包含 NodeID(NodeID),Address(string),UDP Port Number;
· Bucket[VaugeKConst]*Contact 用在 Node 的 Routing 中,一個 Bucket 能包含的 k 個Node,所有的 Node 在 60 分鐘后消失;
· VaugeKConst 統計上設為 20;
· Router 包含 Contact 和 KBucket,KBucket 是在 ID 的每一個 bit 中,都有一個 Bucket。
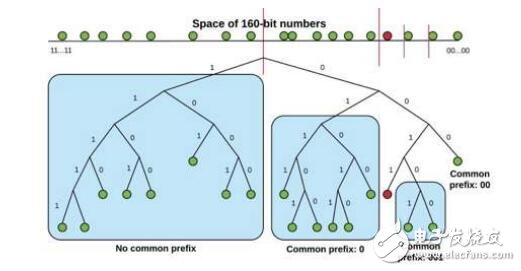
Kademlia使用鍵值來確認在KAD網絡上的節點和數據。KAD的鍵值是不透明的,長度160個比特。參加進來的電腦每一個都會擁有一個鍵值,稱為NodeID,填充在160比特的鍵值空間中。由于KAD存儲內容的時候是由KV(key-value)對來存儲的,每一個在KAD DHT中的Data也都是獨立于160位鍵值中的key對應的空間的。在開始時,一個Node不了解任何其他的Nodes。當新的Nodes注冊后,找到這個節點的鏈接,然后將新的NodeID存起來。當存儲滿溢,Contact會被選擇性去掉,然后在bucket內部被組織。從一個Node找一個NodeID的方式,是從一個已知的路由表中,從一個Node找到另一個最近的Node,直到找到RequestNode。
每個KAD節點都有160比特的NodeID,每個數據的鍵值也是一個160位的標識符。想要確定KV對存在哪個節點中,KAD用了兩個標識符間距離的概念。在給定兩個160位標識符,x和y下,KAD通過他們兩個的“異或”來確定他們之間的距離,并表達為一個整數d(x,y)=x⊕y。XOR(異或)獲得到的是系統二叉樹框架中對距離的定義。在一個完全的160位ID二叉樹ID中,兩個ID距離的大小是最小的包含兩個節點的子樹。當樹不是一個完全二叉樹的時候,距離IDx最近的葉是與x共享最長公共前綴的葉。舉例來說,在0011和1001之間的距離則是0011⊕1001=1010,1010通過整數表達則是10,所以在這兩個節點的距離則是10。
2.3 節點身份ID
對等節點身份信息的生成以及路由規則是通過Kademlia協議生成制定, KAD協議實質是構建了一個分布式松散Hash表,簡稱DHT,每個加入這個DHT網絡的人都要生成自己的身份信息,然后才能通過這個身份信息去負責存儲這個網絡里的資源信息和其他成員的聯系信息。如果新節點A需要尋找另外一個節點B的聯系信息,而A節點沒有節點B的聯系方方式,那么節點A可以通過聯系任意和節點B有聯系的節點來獲取節點B的聯系信息。
2.4 查找算法
在KAD里面的節點查找過程是通過KAD根據給定的鍵值去定位k個最近節點的。KAD在節點查找中選擇采用的是遞歸算法。發起查找的一方首先從非空k-bucket中找到一個節點(或者,如果那個bucket有比 α 少的鍵值對數組,那他就只能通過鍵值得到 α 個最近節點)。發起方通過并行異步方式發送FIND_NODERPC給選到的 α個節點。 α 是一個系統的并發參數。在遞歸的階段,發起方重新發送FindNode給之前發過RPC的節點。無法迅速回應的節點就會被移除,除非直到這些節點回復。
如果一輪下來尋找節點沒有找到任何比最近觀察節點更近的節點,發起方會重新發送FindNode給那些沒有被請求過的節點中尋找k個最近的。當發起者請求后得到k個最近觀察節點的回復后,查找過程就會結束。每一個節點至少知道它每個子樹中的一個節點,每一個節點都可以通過NodeID定位到其他節點。要存一個KV對,節點需要通過鍵值定位對應k個最近節點然后發送STORERPC。要找一個KV對,節點需要查找到對應鍵值最近的k個節點。但是,值(value)的查找會使用FIND_VALUE而不是FIND_NODE,而且這個過程當任何節點返回值的時候立刻停止。
2.5 存儲爭議解決
在分布式存儲網絡中,數據節點分散在不可信任的邊緣網絡中,需要確保數據存儲在數據節點上,并可抵擋女巫攻擊、外包攻擊、代攻擊等作弊手段。在考慮存在惡意節點情況下,分布式存儲系統需要防范各種攻擊,IPWEB通過零知識證明(zkSNARK)和封裝(Seal)來實現復制證明(PoRep)和提取證明(PoE),實現占用資源少并且效率極高的存儲證明。
復制證明(PoRep – Proof of Replication)
存儲證明區別于工作量證明、權益證明等,存儲證明是一種用于分布式存儲領域的共識算法。是根據用戶對分布式云存儲平臺貢獻的存儲空間,并結合流量、帶寬、在線時長等因素進行激勵。證明允許存儲提供用戶通過提供副本證明(π)來說服驗證者,在驗證者發出隨機挑戰時,提供證明:證明數據X相對于證明者的特定副本Y已經存儲在唯一的專用物理存儲區了。PoRep算法可以保證每份數據的存儲都是獨立的,可以防止女巫攻擊,外源攻擊和生成攻擊。
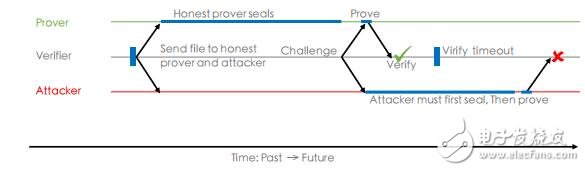
PoRep的三個構建階段 :
·PoRep.setup()--》副本 Y,副本 Hash 樹根 Merkel root of Y,封裝證明πSEAL。
·PoRep.prove()--》存儲證明πPoRep。
·PoRep.Verify()--》bit b (存儲有效性證明 b1(πPoRep)^封裝有效性證明b2(πSEAL))。
提取證明(PoE – Proof of Extract)
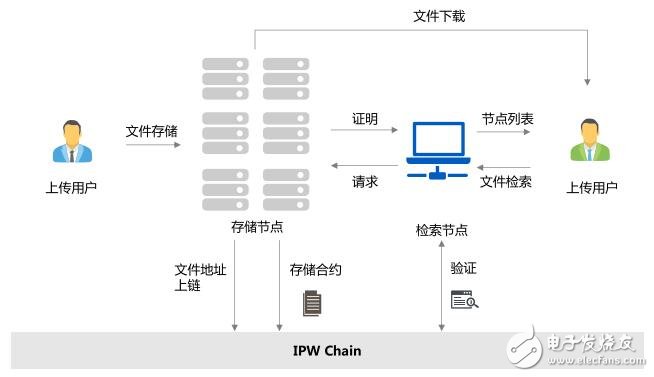
為了避免一遍遍的檢索存儲節點是否按照要求正確的存儲了數據,造成算力資源的浪費,IPWeb設計了新的證明算法提取證明(Proof of Extract),通過通證經濟的利益驅動,當存儲節點響應用戶的檢索及下載需求時,存儲節點主動提供一個證明信息返給檢索礦工。IPWeb不需要再頻繁地檢索某個存儲節點是否正確存儲文件,只有當文件能被成功檢索到時,網絡會執行一個獎勵智能合約,該存儲節點才能獲得獎勵。
整個流程如下:
·IPWeb和存儲節點先簽訂一個存儲合約,比如存儲節點拿出100G的空間用于存儲挖礦;
·存儲節點開始儲存文件;
·用戶檢索文件時,檢索節點根據存儲合約發送請求給到存儲節點;
·存儲節點收到檢索請求后,返回一個存儲證明給到檢索節點;
·檢索節點驗證存儲節點反饋的證明信息;
·用戶成功從驗證的存儲節點列表調用該節點的文件;
·存儲節點獲取存儲到本次檢索的存儲獎勵。
2.6 冗余處理
如果一個節點巡查失敗或者不可到達,系統就發起一個網絡復制過程,通過把網絡上一個現有的副本轉移到一個新的節點上。因此,網絡就能在每次巡查之后恢復正常。每個碎片都是唯一加密的。這意味著,當惡意用戶只有一個文件副本時,不能假裝擁有多個冗余副本。我們可以通過在集中加密碎片時,加入確定性的混淆值來完成。即使解密密鑰是一個已知的特定文件,惡意用戶也不能完成他們沒有被分配到的碎片的審核。這樣,我們可以證明一個特定的碎片的冗余,因為每一個冗余副本是獨一無二的。
另外,用戶和應用都被K-M糾刪碼技術的參數和分布式的冗余控制。對于簡單的數據存儲,用戶可以選擇推薦的文件存儲級別設置。如果數據特別重要,用戶可以選擇高級別的文件存儲設置,把數據分散到多個存儲節點(含多個超級節點)中,這能保護數據免受特殊情況的侵擾(如自然災害等)。
2.7 文件分發網絡
其核心思路是避開互聯網上有可能影響數據傳輸速度和穩定性的瓶頸和環節,使文件傳輸的更快、更穩定。通過在網絡各處放置節點服務器所構成的在現有的互聯網基礎之上的一層智能虛擬網絡,CDN系統能夠實時地根據網絡流量和各節點的連接、負載狀況以及到用戶的距離和響應時間等綜合信息將用戶的請求重新導向離用戶最近的服務節點上。其目的是使用戶可就近取得所需內容,解決Internet網絡擁擠的狀況,提高用戶訪問網站的響應速度。
3. 加密安全(可搜索加密/IP隱蔽)
在數據保護中,個人信息的隱私性是需要得到優先考慮的,其次要支持的就是動態數據的改動,也就是Dapp對于去中心化數據存儲的修改。IPWeb基于業務場景,使用可搜索對稱加密(SSE: SearchableSymmetricEncryption)方法,SSE由五個算法組成:
K=KeyGen(k):輸入安全參數k,輸出隨機產生的密鑰K。該操作通常在數據擁有者端本地執行。
(I,C)=Enc(K,D):輸入密鑰K和明文文件集D=(D1,D2,…,Dn),輸出索引和密文文件集。該操作在數據擁有者端本地執行。
TW=Trapdoor(K,W):輸入密鑰K和關鍵詞W,輸出關鍵詞對應的陷門。該操作在數據擁有者端本地執行。
D(W)=Search(I,TW):輸入索引I和待搜索關鍵字的陷門TW,輸出包含關鍵字W的文件的標識符集合。Search操作在Genaro中由密鑰分發控件執行。
Di=Dec(K,Ci):輸入密鑰K和密文文件Ci,輸出解密后對應的明文文件Di。該操作在數據擁有者端本地執行。
另外,IPWeb將存儲和檢索兩層網絡分離,提高了網絡效率,提升了用戶體驗。但檢索節點是整個P2P網絡最容易被尋找和攻擊的部分,需要對檢索節點有額外保護,通過對檢索節點的IP地址加密保護,用戶無法通過IP直接查詢,實現對節點的保護。
4. 其他技術創新
4.1 分散存儲
把文件分散成碎片能更好的保證數據的安全性,以致于只要存儲的文件是標準碎片大小,就沒有用戶擁有一個完整的副本。我們把出租他或者她的硬盤空間給網絡的用戶定義為用戶。定義標準碎片大小為字節的倍數(8KB/16KB/32KB/256KB/1024KB,根據文件大小,智能篩選分散標準)。這些都是保持在預先設定的大小,以阻止試圖惡意存儲小文件(對于大文件,大數量的碎片切割更有優勢。對于小文件,特別是對小于一定大小(如64M)的文件,小文件的P2P傳輸效率很低,對網絡容易造成額外負擔)。
4.2 Peer評級/節點分級
在Filecoin里所有節點都是同級的,這帶來了更多的去中心化,但犧牲了效率。IPWeb會把存儲節點按可靠性分級。初步決定把存儲節點分為手機、個人計算機、專業礦機、企業級節點、超級節點。超級節點和企業級節點會有非常高的可靠性,所有文件的碎片會首先在超級節點和企業級節點備份,以提高IPWeb網絡的效率和可靠性。
4.3 存儲級別設置
用戶可以根據自己的需要對文件存儲級別進行設置。比如將文件丟失恢復比設置為1/3、1/2、2/3。級別越高,安全性越高(丟失的風險越小)。
4.4 防作弊機制
存儲節點A和用戶B可能會串通作弊騙取存儲獎勵。比如存儲節點A謊稱自己存儲了1T的文件F,而用戶B謊稱自己成功檢索到了存儲在A的文件F。對于這種作弊行為,我們有多重防范。首先,我們會采取動態IP機制(防刷機作弊、檢索作弊、存儲作弊)(每次換Peer)。其次,大文件更容易用于作弊,但是大文件也會被分成更多數量的文件存在很多節點。用戶B可能會付出檢索費用卻只能A節點獲得了很少的獎勵,而其他節點獲得了絕大多數存儲獎勵。這同樣能有效抑制刷機套利作弊的行為。
4.5 IPWeb瀏覽器
IPWeb瀏覽器是可以訪問IPWeb協議網絡的瀏覽器,同時也兼容HTTP協議。不僅如此,用戶還可以通過瀏覽器設置個人設備的存儲空間用于挖礦。瀏覽器將能極大地增長IPWeb用戶數和社區。更多的人能為IPWeb網絡做貢獻,也能成為IPWeb生態的消費者。IPWeb還將自帶錢包功能。所有瀏覽器裝機用戶也會有自己的錢包。在必要的時候,IPWeb瀏覽器也可以兼容IPWEB協議,成為IPWEB生態的流量入口。
IPWeb 的經濟模型是一套激勵生產者(服務提供者)和消費者參與到 IPWeb 體系的經濟激勵機制,是一套激勵數據存儲和檢索的經濟激勵機制。IPWeb 有簡潔明確的底層激勵模型,和豐富、可拓展的多層激勵模型。
從基礎設施到 C 端內容消費 / 服務提供,互聯網生態中有豐富的生產 - 消費關系。多層次的、豐富的生產消費關系才能刺激了生態的蓬勃發展。在互聯網最初誕生的時候,互聯網的生態是很簡單、單薄的,只有大型科學項目和大企業在使用互聯網。甚至很多時候生產者和消費者是同一批人,互聯網是他們工作的工具。后來,有了一些人在互聯網上創造了一些內容,另一部分人需要一個入又瀏覽這些內容。這個時候,瀏覽器應運而生。生產者和消費者開始分化。除了內容的生產者以外,第一層工具(瀏覽器)的生產者也開始出現。再往后,網站日益變多,Yahoo一類的門戶網站成為了互聯網生態的新入又。互聯網的生產者和消費者進一步增加,第二層工具(門戶網站)的生長者也出現,生產 - 消費關系進一步豐富。我們可以看到只有多層次的、豐富的生產 - 消費關系才能支持一個偉大的生態體系。
在底層經濟模型里,IPWeb 的生產者主要是存儲節點和檢索節點,消費者主要是發起數據存儲和檢索請求的用戶。消費者在 IPWeb 發起數據存儲請求和數據檢索請求,并支付代幣 IPW 作為存儲 Gas 和檢索 Gas。存儲節點貢獻閑置的存儲空間和帶寬,為消費者提供 P2P 分布式數據存儲服務,并獲得存儲 Gas 作為獎勵。檢索節點則貢獻閑置的算力和帶寬,為消費者提供 P2P 分布式數據檢索服務,并獲得檢索 Gas 代幣。除了存儲獎勵和檢索獎勵以外,部分超級節點還可以參與 IPW Chain 的記賬,獲得區塊產生獎勵。
單純的存儲和檢索服務只是一個去中心化數據存儲和檢索平臺。這是一種可以對標中心化云存儲服務的平臺。但是這樣的基礎設施也類似于互聯網的第一個階段,只有大企業和大項目(比如視頻影像公司)會考慮到 P2P 存儲成本成為企業付費用戶。只有底層設施,沒有豐富的應用層生產者和消費者,IPWeb無法支撐去中心化互聯網的偉大構想。 所以 IPWeb 還設計了建立于底層經濟模型之上的高層次經濟模型。
第二層經濟模型里,IPWeb 瀏覽器作為 IPWeb網絡的流量入又的承載了。IPWeb瀏覽器會內置存儲挖礦和 IPW 錢包兩大功能。用戶可以在瀏覽器里設置把閑置的存儲空間貢獻出來進行存儲挖礦。得到了存儲獎勵會直接到用戶的 IPW 錢包里。瀏覽器挖礦能讓幾乎所有用戶都能成為生產者獲得 IPW 激勵。用戶也可以便捷地在瀏覽器中進行支付和轉賬等操作。錢包里擁有 IPW 的用戶會更容易參與到高層的經濟活動中。
第三層經濟模型里,我們有一套經濟機制來鼓勵開發者開發基于 IP-Web 的網站和應用。在這一層的生態中,去中心化互聯網生態與中心 化互聯網生態已經趨于接近。IPWeb 的目標就是塑造一個去中心化版的互聯網應用生態,并讓 IPW 成為這個應用生態的通貨。讓開發者可 以用 IPW 支付技術成本,可以從消費者手里獲得 IPW 的盈利。IPWeb 通過多層次的、不斷完善的經濟模型激勵更多節點和用戶加入到去中心化存儲和去中心化互聯網的技術浪潮中來。這是共享經濟和區塊鏈技術帶來的嶄新時代。
IPWeb的應用場景
1. 分布式文件存儲
IPWEB 分布式存儲云能夠提供基礎的云存儲服務。通過 OpenAPI,客戶可以很容易的接入和使用 IPWEB 云存儲服務。分布式存儲云能夠提供更安全、更可靠和具有極高性價比的云存儲服務。
2 分布式文件共享
分布式共享云是利用分布式存儲云一共的存儲服務作為基礎,用戶可以把他們擁有的一些文件(數字媒體或其他有價值的內容)進行共享。共享時可以根據具體的內容設定一定額度的IPW打賞要求。如果其他用戶希望能夠完整的下載或觀看該文件,就需要支付相應額度的 IPW 作為打賞給上傳者。作為一種文件共享服務,IPWEB 將嚴格按照運營所在地的法律要求對用戶的上傳內容進行審核和管理。
3 多媒體應用
目前傳統在線視頻網站采用的是中心化存儲服務,這需要高額的儲存費用和帶寬費用,相關的費用會轉化為:觀看長時間的廣告及限制非會員觀看等。而使用了IPWeb 作存儲服務,將大大降低了相同資源的冗余,同時節約了大量用戶播放視頻時產生的帶寬成本,使得觀看視頻更加高效和低廉。
4 數字內容交易
由于采用了區塊鏈和分布式存儲技術,IPWEB 存儲云非常適合為長尾內容的版權交易提供存儲能力。分布式賬本能夠為交易提供公開、透明和不可篡改的交易記錄。也能為數字內容作品在區塊鏈上留下不可篡改的、唯一的數字簽名作為版權所有的標識。在IPWEB平臺的支持下,大量的長尾視頻、音頻和攝影創作能夠有了一個低成本、可持續運作的交易平臺。
5 社交應用
使用IPWeb技術創建一個去中心化的社交網絡。作為一個去中心化的應用程序,IPWeb 網絡可以讓社交應用可以在沒有任何中心點的情況下工作,完全點對點。
IPWeb的生態建設
1 存儲生態
存儲礦工為網絡提供數據存儲,存儲礦工通過提供磁盤空間和響應客戶請求來參與 IPWeb 運作。要想成為存儲礦工,用戶需要提供存儲空間及帶寬資源。礦工將用戶的數據片段存儲到扇區,并以此賺取 IPW。存儲礦工通過在特定時間內存儲數據,來響應用戶的存儲請求。存儲礦工生成證明并提交到區塊鏈網絡,來證明他們在特定時間內存儲了數據。如果數據失效或丟失,存儲礦工將被罰沒部分抵押的 IPW。存儲礦工工作流程:
· 存儲礦工在區塊鏈中存放抵押的 IPW,來保證向網絡提供穩定的存儲。抵押品為了保證服務而存在,如果礦工為所存儲的數據生成了存儲量證明,抵押品就會被退回。如果沒有成功生成存儲量證明,礦工將失去抵押品。
· 一旦抵押交易在區塊鏈中出現,礦工就可以在存儲市場中提供存服務。
· 一旦訂單匹配,客戶就將數據發給存儲礦工。存儲礦工數據接收完成后,礦工和客戶簽署交易訂單并提交到區塊鏈。
· 當存儲礦工被分配了數據時,必須重復生成存儲量證明來確保他們正在存儲數據證明被發布在區塊鏈中,并由網絡來驗證。
· 驗證成功后,存儲礦工將會獲得相應的存儲獎勵。
2 檢索生態
檢索礦工為網絡提供數據檢索服務,檢索礦工通過提供用戶檢索請求所需要的數據來參與 IPWeb 運作。和存儲礦工不同,他們不需要抵押品,不需要提交存儲數據,也不需要提供存儲證明。
3 應用開發者生態
IPWeb 需要更多的商業來繁榮整個生態,需要有相應的應用開發商來經營業務,讓更多的存儲需求進來。
4 應用服務生態
IPWeb 為用戶提供文件存儲及檢索服務,用過通過 IPWeb 瀏覽器使用 IPWeb提供的各項服務。














 工商網監
工商網監
評論