") 云知聲詳解AI計(jì)算用途和未來(lái)的發(fā)展趨勢(shì)
云知聲詳解AI計(jì)算用途和未來(lái)的發(fā)展趨勢(shì)
計(jì)算任務(wù)容器化
Docker 是目前業(yè)內(nèi)主流的容器技術(shù),在各個(gè)領(lǐng)域得到廣泛的應(yīng)用。容器的概念具有新穎的設(shè)計(jì)思想,非常方便開(kāi)發(fā)、測(cè)試以及發(fā)布產(chǎn)品,并能保證在這幾個(gè)環(huán)節(jié)中軟件運(yùn)行環(huán)境的一致性。Docker 和虛擬機(jī)是不一樣的,兩者差異很大,虛擬機(jī)需要大量的資源來(lái)模擬硬件,運(yùn)行操作系統(tǒng),而 Docker 幾乎不會(huì)有計(jì)算性能的損失,輕量級(jí)是其顯著特點(diǎn),所以得到廣泛的應(yīng)用。
容器本質(zhì)上是宿主機(jī)上的一個(gè)進(jìn)程,一般來(lái)說(shuō),容器技術(shù)主要包括 cgroups (control groups) 和 namespace 這兩個(gè)內(nèi)核特性,namespace 實(shí)現(xiàn)資源隔離,cgroups 實(shí)現(xiàn)資源限制。除此之外,在容器鏡像制作時(shí),利用UnionFS 實(shí)現(xiàn) Copy on Write 的 Volume 文件系統(tǒng)。
Namespace 的作用就是隔離,是 Linux 在內(nèi)核級(jí)別的隔離技術(shù),從內(nèi)核 2.4.19 開(kāi)始逐漸引入并完善。它可以讓進(jìn)程擁有自己獨(dú)立的進(jìn)程號(hào),網(wǎng)絡(luò),文件系統(tǒng)(類似 chroot )等,不同 namespace 下的進(jìn)程之間相互不可見(jiàn)。主要包括以下六類 namespace:
Mount namespace系統(tǒng)內(nèi)核版本 >2.4.19
實(shí)現(xiàn)文件系統(tǒng)掛載
每個(gè)容器內(nèi)有獨(dú)立的文件系統(tǒng)層次結(jié)構(gòu)
UTS namespace
系統(tǒng)內(nèi)核版本 >2.6.19
每個(gè)容器有獨(dú)立的 hostname 和 domain
name
IPC namespace
系統(tǒng)內(nèi)核版本 >2.6.19
每個(gè)容器內(nèi)有獨(dú)立的 System V IPC 和
POSIX 消息隊(duì)列系統(tǒng)
PID namespace
系統(tǒng)內(nèi)核版本 >2.6.24
每個(gè) PID namespace 中的進(jìn)程有獨(dú)立的 PID,容器中的每個(gè)進(jìn)程有兩個(gè)PID:容器中的 PID 和 host 上的 PID
Network namespace
系統(tǒng)內(nèi)核版本 >2.6.29
每個(gè)容器用有獨(dú)立的網(wǎng)絡(luò)設(shè)備,IP 地址、
IP 路由表、端口號(hào)等
User namespace
系統(tǒng)內(nèi)核版本 >3.8
容器中進(jìn)程的用戶和組 ID 和 host 上不
同,每個(gè)容器有不同的用戶和組 、ID;
host 上的非 root 可以成為
usernamespace 中的root
容器通過(guò) namespace 實(shí)現(xiàn)資源的隔離,每個(gè)容器可以有上述六種獨(dú)立的 namespace,有了資源隔離之后,如果不能對(duì)各個(gè) namespace 下進(jìn)程的資源使用做限制的話,那么 namespace 隔離也沒(méi)有意義了,所以在容器中,我們利用 cgroups 實(shí)現(xiàn)對(duì)進(jìn)程以及其子進(jìn)程的資源限制。
Cgroups 顧名思義就是把進(jìn)程放到一個(gè)組里統(tǒng)一加以控制。根據(jù)官方的定義:
cgroups 是 Linux 內(nèi)核提供的一種機(jī)制,這種機(jī)制可以根據(jù)特定的行為,把一系列系統(tǒng)任務(wù)及其子任務(wù)整合(或分隔)到按資源劃分等級(jí)的不同組內(nèi),從而為系統(tǒng)資源管理提供一個(gè)統(tǒng)一的框架。
通俗的來(lái)說(shuō),cgroups 可以限制、記錄、隔離進(jìn)程組所使用的物理資源(包括:CPU、memory、IO 等)。需要說(shuō)明是,我們可以通過(guò)本地的文件系統(tǒng)來(lái)管理 cgroups 配置,就像修改 /sys 目錄下的文件內(nèi)容一樣,來(lái)類似修改cgroups配置。而且,在 docker引擎這一層已經(jīng)幫我們屏蔽了底層的細(xì)節(jié),我們可以通過(guò) docker 命令很方便的配置 cgroups 相關(guān)的參數(shù)。
針對(duì)CPU資源,cgroups 提供了三種限制CPU資源的方式:cpuset、cpuquota 和 cpushares。針對(duì)內(nèi)存資源,提供包括物理內(nèi)存和swap兩塊的限制。另外,blkio子系統(tǒng)的功能提供對(duì)塊設(shè)備讀寫的速率限制。由于篇幅限制,關(guān)于cgroups 的介紹不詳細(xì)展開(kāi)。
除了上述 namespace 和 cgroups 實(shí)現(xiàn)資源隔離和限制之外,容器利用 UnionFS 提供容器鏡像 (images) 的基礎(chǔ)文件系統(tǒng)。UnionFS 文件系統(tǒng)是分層的,當(dāng)我們需要修改一個(gè)文件的內(nèi)容的時(shí)候,會(huì)將這個(gè)文件拷貝一份新的放到最上層的目錄上然后修改文件,實(shí)際上,下層的目錄并沒(méi)有改動(dòng)。這也是容器鏡像文件系統(tǒng)的一個(gè)核心特性,基于此特性:
實(shí)現(xiàn)容器鏡像的分層復(fù)用和共享,在基礎(chǔ)鏡像的基礎(chǔ)上構(gòu)建新鏡像,而不需要從零開(kāi)始構(gòu)建,容器鏡像也有自己的標(biāo)準(zhǔn)規(guī)范(https://github.com/opencontainers/image-spec),多鏡像之間可以復(fù)用共享,還可以通過(guò) DockerHub 等網(wǎng)站共享與分發(fā)鏡像。
由于 Copy on Write 特性,在使用時(shí)需要注意避免不當(dāng)?shù)臉?gòu)建方式,導(dǎo)致鏡像的 size 過(guò)大。
容器鏡像中只包含必要的運(yùn)行環(huán)境(依賴的庫(kù)等),,同一節(jié)點(diǎn)上的各個(gè)容器共享 kernel,相比與虛擬機(jī)的重量級(jí)封裝,鏡像的 size 可以做的很小。
容器的核心特點(diǎn)是輕量級(jí)的資源隔離、限制和封裝,極大的簡(jiǎn)化了程序運(yùn)行時(shí)的環(huán)境依賴,同時(shí)還能解決多版本共存運(yùn)行的問(wèn)題,計(jì)算程序和運(yùn)行節(jié)點(diǎn)之間獨(dú)立,為進(jìn)一步的多節(jié)點(diǎn)間的自動(dòng)調(diào)度奠定了基礎(chǔ)。下圖展示的是容器中計(jì)算程序封裝的邏輯圖。其最大好處是整體運(yùn)行環(huán)境的封裝,在此邏輯下,用戶也會(huì)逐步從傳統(tǒng)的 make build 生成可執(zhí)行文件過(guò)渡到利用 docker build 制作應(yīng)用鏡像,容器的使用也會(huì)越來(lái)越廣泛。
總結(jié)一下,使用容器技術(shù)作為計(jì)算程序運(yùn)行環(huán)境封裝,帶來(lái)諸多優(yōu)勢(shì):
一致的運(yùn)行環(huán)境,解決計(jì)算框架環(huán)境依賴、安裝配置繁瑣的問(wèn)題;
多個(gè)計(jì)算框架可以共存運(yùn)行,同一個(gè)計(jì)算框架的多版本也可以共存運(yùn)行;
計(jì)算節(jié)點(diǎn)與運(yùn)行環(huán)境獨(dú)立,這是實(shí)現(xiàn)多節(jié)點(diǎn)計(jì)算自動(dòng)調(diào)度的基礎(chǔ);
一次構(gòu)建,隨時(shí)隨地多次運(yùn)行;
基于上述容器技術(shù)帶來(lái)的優(yōu)勢(shì),目前主流的 AI 計(jì)算框架都支持以容器的方式運(yùn)行,也逐漸成為社區(qū)的標(biāo)準(zhǔn)運(yùn)行方式,TensorFlow 官方也在 Dockerhub 上直接提供 TensorFlow 各個(gè)版本的相關(guān)鏡像下載。其他 AI 計(jì)算框架也以提供 Dockerfile 的形式或者直接提供 Docker images 供用戶使用。同時(shí),用戶也可以根據(jù)自己的計(jì)算需求或者以自己的應(yīng)用算法為基礎(chǔ),創(chuàng)建和維護(hù)專用鏡像文件。
GPU計(jì)算任務(wù)容器化
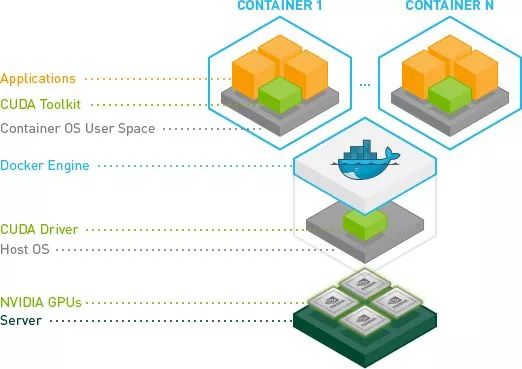
AI 算法目前使用 GPU 提供計(jì)算加速,所以,容器方式運(yùn)行的 AI 計(jì)算框架需要同時(shí)支持 CPU 和 GPU 兩種運(yùn)行方式。CPU 版的運(yùn)行和常規(guī)容器運(yùn)行方式無(wú)異,GPU 版的運(yùn)行方式略微復(fù)雜,為此 Nvidia 官方推出 Nvidia-docker(https://github.com/NVIDIA/nvidia-docker)工具簡(jiǎn)化 GPU 版的運(yùn)行方式和流程。在介紹 nvidia-docker 工具之前,我們先看下 GPU 容器的架構(gòu)邏輯圖,如下所示,從下往上分為:
硬件層:在每個(gè) GPU 計(jì)算節(jié)點(diǎn)上配置一個(gè)或者多個(gè) GPU 硬件資源。
軟件層:每個(gè)計(jì)算節(jié)點(diǎn)安裝操作系統(tǒng)和相應(yīng)的 GPU drivers。
Docker:每個(gè)計(jì)算節(jié)點(diǎn)安裝 Docker engine 服務(wù)。
容器:容器中包含計(jì)算相關(guān)的運(yùn)行環(huán)境和 CUDA 庫(kù),并且將 host 上的 GPU 設(shè)備和驅(qū)動(dòng)動(dòng)態(tài)庫(kù)映射到容器中。
用戶可以通過(guò) docker 命令 --device 和 --volume 等參數(shù)實(shí)現(xiàn) GPU 設(shè)備和動(dòng)態(tài)庫(kù)映射,但是,使用起來(lái)不方便,而 nvidia-docker 的功能就是簡(jiǎn)化 GPU 容器創(chuàng)建和運(yùn)行,其是一個(gè) wrapper 的 Bash 腳本,封裝了 docker 的命令參數(shù)。從下面腳本中可以看出,當(dāng)用戶使用 nvidia-docker 執(zhí)行 run 和 create 這兩個(gè)子命令時(shí),nvidia-docker 做了兩個(gè)改變:
切換runtime 為 nvidia runtime
如果用戶定義了 NV_GPU 環(huán)境變量,則將 NV_GPU 環(huán)境變量的信息傳給環(huán)境變量 NVIDIA_VISIBLE_DEVICES

基于以上分析,我們可以得到兩個(gè)結(jié)論:
nvidia-docker 在除 run 和 create 之外的其他子命令,和普通的 docker 并無(wú)太大區(qū)別。所以,我們沒(méi)法在使用其他 docker 子命令時(shí)(比如 docker build),執(zhí)行需要使用 GPU 資源的相關(guān)代碼。
nvidia-docker 實(shí)現(xiàn)簡(jiǎn)化 GPU container 運(yùn)行,實(shí)際上是通過(guò) nvidia runtime 實(shí)現(xiàn),并利用 runtime 的環(huán)境變量 NVIDIA_VISIBLE_DEVICES 控制容器中能夠使用的 GPU 數(shù)量。
NVIDIA_VISIBLE_DEVICES 默認(rèn)值是 all,其含義是 GPU Container 可使用計(jì)算節(jié)點(diǎn)上的所有 GPU 資源,用戶利用 NV_GPU 控制可用 GPU 資源數(shù)量,而 nvidia-docker 腳本再將 NV_GPU 傳遞給 NVIDIA_VISIBLE_DEVICES。我們可以通過(guò)兩種方式設(shè)置 NV_GPU:
指定 GPU index,此 index 和 nvidia-smi 顯示的 GPU index 一致
指定 GPU 的 UUID
如下面所示:
# Running nvidia-docker isolating specific GPUs by index
NV_GPU='0,1' nvidia-docker
# Running nvidia-docker isolating specific GPUs by UUID
NV_GPU='GPU-836c0c09,GPU-b78a60a' nvidia-docker
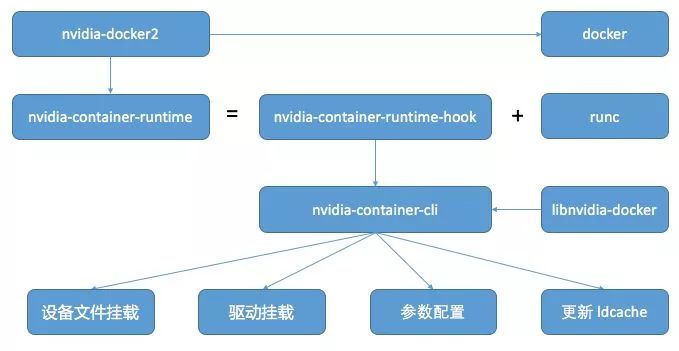
下圖展示的是 nvidia-docker2 的工作邏輯圖,GPU 相關(guān)的核心工作是由 nvidia-container-runtime 實(shí)現(xiàn)的。nvidia container runtime 是 Nvidia 定義的一種 GPU 運(yùn)行環(huán)境 (https://github.com/NVIDIA/nvidia-container-runtime),基于對(duì) runc (https://github.com/opencontainers/runc)運(yùn)行環(huán)境的一種修改版本,符合 openContainer 的 OCI 標(biāo)準(zhǔn)定義。
為了提供一定的靈活性,nvidia-container-runtime 定義了一些 GPU 相關(guān)的環(huán)境變量。比如,控制 GPU 使用數(shù)目的 NVIDIA_VISIBLE_DEVICES。下面所示的是兩個(gè)常用的環(huán)境變量示例。詳細(xì)的環(huán)境變量參見(jiàn):
https://github.com/NVIDIA/nvidia-container-runtime#environment-variables-oci-spec
NVIDIA_VISIBLE_DEVICES:控制在容器中使用的 GPU 數(shù)目,可選項(xiàng):
0,1,2, GPU-fef8089b …: GPU UUID 或者 GPU 索引列表
all: 默認(rèn)值,在容器中可以使用節(jié)點(diǎn)上的所有 GPU 資源
none: 只加載 GPU 驅(qū)動(dòng),但 GPU 設(shè)備不可使用
void or empty or unset: 等同于常規(guī)的 runc
NVIDIA_DRIVER_CAPABILITIES:控制容器如何掛載 GPU 驅(qū)動(dòng)和附屬文件,可選項(xiàng):
compute,video,graphics,utility …: 驅(qū)動(dòng)功能列表,對(duì)于 deep learning 需要開(kāi)啟 compute
compute: CUDA and OpenCL 計(jì)算應(yīng)用
compat32: 兼容 32位計(jì)算應(yīng)用
graphics: OpenGL and Vulkan 圖形應(yīng)用
utility: nvidia-smi and NVML 等命令行工具使用
video: 視頻編解碼
all: 開(kāi)啟驅(qū)動(dòng)所有功能
empty or unset: 空或者不設(shè)置,默認(rèn)值為:utility
我們根據(jù)nvidia-container-runtime Github 上的代碼,具體分析其是如何工作的。首先,我們看一下 nvidia-container-runtime 如何編譯出來(lái)的,通過(guò)下面節(jié)選的關(guān)鍵代碼,nvidia-container-runtime 是在 runc 代碼的基礎(chǔ)上,打上一個(gè) patch,然后編譯,并重命名為 nvidia-container-runtime。

此 patch 加了一個(gè) prestart Hook,在容器創(chuàng)建時(shí),執(zhí)行程序 nvidia-container-runtime-hook。除此改動(dòng)之外,nvidia-container-runtime 其余相關(guān)的功能依賴 runc 實(shí)現(xiàn)。nvidia-container-runtime-hook 是一個(gè) go 語(yǔ)言實(shí)現(xiàn)的可執(zhí)行程序,主要功能是讀取當(dāng)前容器的配置信息 config.json,和 runtime 配置文件 /etc/nvidia-container-runtime/config.toml,并處理 runtime 定義的環(huán)境變量。
nvidia-container-runtime-hook 的上述功能是通過(guò)調(diào)用 nvidia-container-cli 實(shí)現(xiàn) (https://github.com/NVIDIA/libnvidia-container),nvidia-container-cli 也是 Nvidia 官方維護(hù)的一個(gè) GPU 工具,其主要功能包括:
加載 GPU 驅(qū)動(dòng)運(yùn)行動(dòng)態(tài)庫(kù)
掛載 GPU 設(shè)備文件
配置參數(shù)
更新系統(tǒng)動(dòng)態(tài)庫(kù)緩存
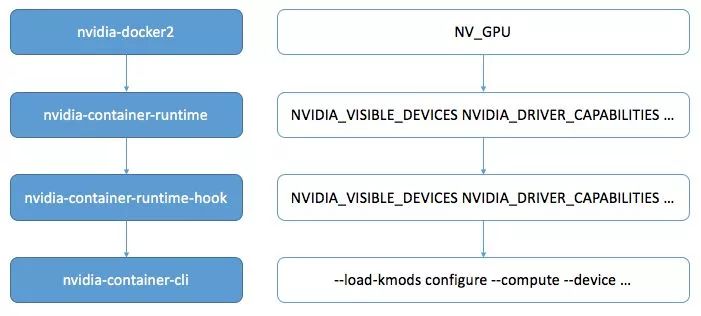
下圖展示的是 nvidia-docker2 調(diào)用邏輯與環(huán)境變量傳遞圖,從 nvidia-docker2 開(kāi)始,容器最終的 GPU 配置由 nvidia-container-cli 執(zhí)行。圖中右側(cè)是用戶可以設(shè)置的環(huán)境變量傳遞圖,從 nvidia-docker2 層級(jí)的 NV_GPU 到最終轉(zhuǎn)化為 nvidia-container-cli 命令的 --compute --device 等參數(shù)。
總結(jié)
本篇針對(duì)如何簡(jiǎn)單有效的實(shí)現(xiàn)在單機(jī)上使用 GPU 和 TensorFlow 等 AI 計(jì)算框架,深入介紹任務(wù)容器化的基本思路和概念,詳細(xì)分析了 nvidia-docker2 的工作流程和實(shí)現(xiàn)邏輯。借助 nvidia-docker2,在單機(jī)上運(yùn)行 AI 計(jì)算任務(wù)更加方便,解決了安裝配置框架以及多版本共存運(yùn)行的問(wèn)題,也避免了配置使用 GPU 的繁瑣工作量。
本篇為 AI 計(jì)算系列:從單機(jī)到集群(上),那么后續(xù)篇 —— 從單機(jī)到集群(中)繼續(xù)為大家?guī)?lái) AI 計(jì)算系列的分享,將在本篇介紹單機(jī) AI 計(jì)算的基礎(chǔ)上,實(shí)現(xiàn)從單機(jī)到集群的跨越,重點(diǎn)介紹如何構(gòu)建面向 AI 計(jì)算的 GPU 集群,分析最新 AI 計(jì)算集群的 GPU 資源調(diào)度邏輯,幫助大家更進(jìn)一步理解如何實(shí)現(xiàn)多機(jī) GPU 資源的自動(dòng)分配和管理。
-
硬件
+關(guān)注
關(guān)注
11文章
3471瀏覽量
67310 -
軟件
+關(guān)注
關(guān)注
69文章
5139瀏覽量
89051 -
人工智能
+關(guān)注
關(guān)注
1805文章
48863瀏覽量
247632
發(fā)布評(píng)論請(qǐng)先 登錄





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論