 基于代碼的機器學習是什么,它的原理如何
基于代碼的機器學習是什么,它的原理如何

(文章來源:CDA數據分析師)
隨著IT組織的發展,其代碼庫的大小以及開發人員工具鏈的復雜性也在不斷增長。工程負責人對其代碼庫,軟件開發過程和團隊狀態了解的非常有限。通過將現代數據科學和機器學習技術應用于軟件開發,大型企業有機會顯著提高其軟件交付性能和工程效率。
在過去的幾年中,許多大型公司,例如Google,Microsoft,Facebook以及類似Jetbrains等較小的公司已經與學術研究人員合作,為基于代碼的機器學習奠定了基礎。
基于代碼的機器學習?代碼機器學習(MLonCode)是一個新的跨學科研究領域,涉及自然語言處理,編程語言結構以及社會和歷史分析,例如貢獻圖形和提交時間序列。MLonCode旨在從大規模的源代碼數據集中學習,從而能自動執行軟件工程任務,例如輔助代碼審查,代碼重復數據刪除,軟件專業知識評估等。
為什么MLonCode很難?某些MLonCode問題要求零錯誤率,例如與代碼生成有關的錯誤率。自動程序修復是一個特定的示例。一個微小的單一錯誤預測可能會導致整個程序的編譯失敗。
在其他一些情況下,錯誤率必須足夠低。理想的模型應犯的錯誤應盡可能少,所以用戶(軟件開發人員)的信噪比仍是可承受且值得信賴的。因此,可以使用與傳統靜態代碼分析工具相同的方式來使用該模型。最佳實踐挖掘就是一個很好的例子。
最后,絕大多數MLonCode問題是無監督的,或至多是弱監督的。手動標記數據集可能會非常昂貴,因此研究人員通常必須開發相關的啟發式方法。例如,有許多相似性分組任務,例如向相似的開發人員展示或根據專業領域幫助團隊。我們在本主題中的經驗在于挖掘代碼格式化規則,并將其應用于修復錯誤,這與短絨一樣,但完全不受監督。有一個相關的學術競賽來預測格式問題,稱為CodRep。
MLonCode問題包括各種數據挖掘任務,這些任務從理論上講可能是微不足道的,但由于規模或對細節的關注,在技術上仍然具有挑戰性。示例包括代碼克隆檢測和類似的開發人員聚類。此類問題的解決方案在年度學術會議“ 采礦軟件存儲庫”中進行了介紹。
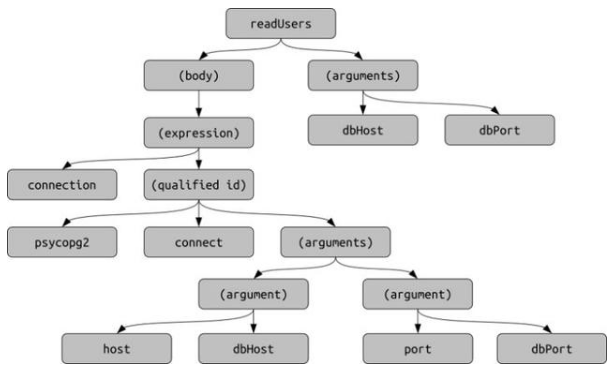
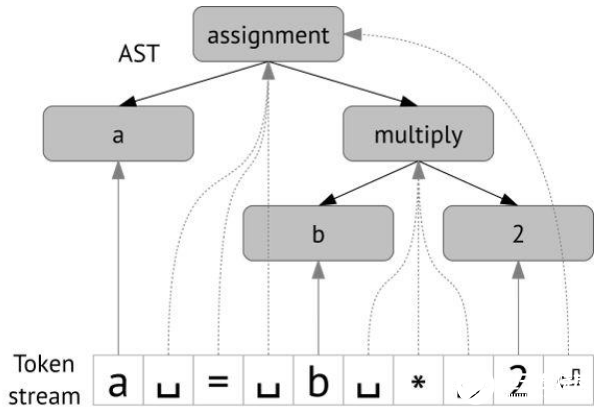
采礦軟件存儲庫會議徽標。解決MLonCode問題時,通常用以下方式之一表示源代碼:頻率字典(加權詞袋,BOW)。示例:函數內的標志符;文件中的graphlet;存儲庫的依賴性;可以通過TF-IDF加權頻率等。這些表示是最簡單,可伸縮性最高的。順序令牌流(TS),對應于源代碼解析序列。該流通常通過指向相應抽象語法樹節點的鏈接來增強。此表示形式對常規自然語言處理算法(包括序列到序列深度學習模型)很友好。
一棵樹,它自然地來自抽象語法樹。在進行不可逆的簡化或標志符后,我們執行各種轉換。這是最強大的表示形式,也是最難使用的表示形式。以下是相關的ML模型包括各種圖嵌入和門控圖神經網絡。
解決MLonCode問題的許多方法都基于所謂的自然假說(Hindle等):“從理論上講,編程語言是復雜,靈活且功能強大的,但很多人實際上編寫的程序大多是簡單且相當重復的,因此它們具有有用的可預測統計屬性,可以在統計語言模型中捕獲并用于軟件工程、任務。”
該聲明證明了大代碼的有用性:分析的源代碼越多,強調的統計屬性越強,并且訓練有素的機器學習模型所獲得的指標越好。底層關系與當前最新的自然語言處理模型相同:如XLNet,ULMFiT等。類似地,通用MLonCode模型可以在下游任務中進行訓練和利用。
(責任編輯:fqj)
-
代碼
+關注
關注
30文章
4892瀏覽量
70428 -
機器學習
+關注
關注
66文章
8499瀏覽量
134303
發布評論請先 登錄
傳統機器學習方法和應用指導

如何選擇云原生機器學習平臺
自然語言處理與機器學習的關系 自然語言處理的基本概念及步驟
什么是機器學習?通過機器學習方法能解決哪些問題?






 工商網監
工商網監
評論