 如何向大規模預訓練語言模型中融入知識?
如何向大規模預訓練語言模型中融入知識?

本文介紹了復旦大學數據智能與社會計算實驗室 (Fudan DISC)在ACL 2021上錄用的一篇Findings長文: K-Adapter: Infusing Knowledge into Pre-Trained Models with Adapters
文章摘要
本文關注于向大規模預訓練語言模型(如RoBERTa、BERT等)中融入知識。提出了一種靈活、簡便的知識融入框架K-Adapter,通過外掛知識插件的方式來增強原模型,緩解了知識遺忘的問題、且支持連續知識學習。本文提出的模型在三種知識驅動的任務,包括了命名實體識別、關系分類、問答等任務上取得了顯著的效果。
研究背景
預訓練語言模型,如BERT、GPT、XLNet、RoBERTa,可以通過無監督訓練目標(如MLM)來從大規模文本語料中學習通用表示,并且在各種各樣的下游任務上取得了SOTA的表現。盡管這些模型取得了巨大的進步,但是最近的一些工作表明這些通過無監督方式訓練的模型很難學習到豐富的知識,如邏輯知識、事實類知識、語言學知識、特定領域的知識等等。因此這啟發了本文來研究如何向預訓練模型中融入知識。
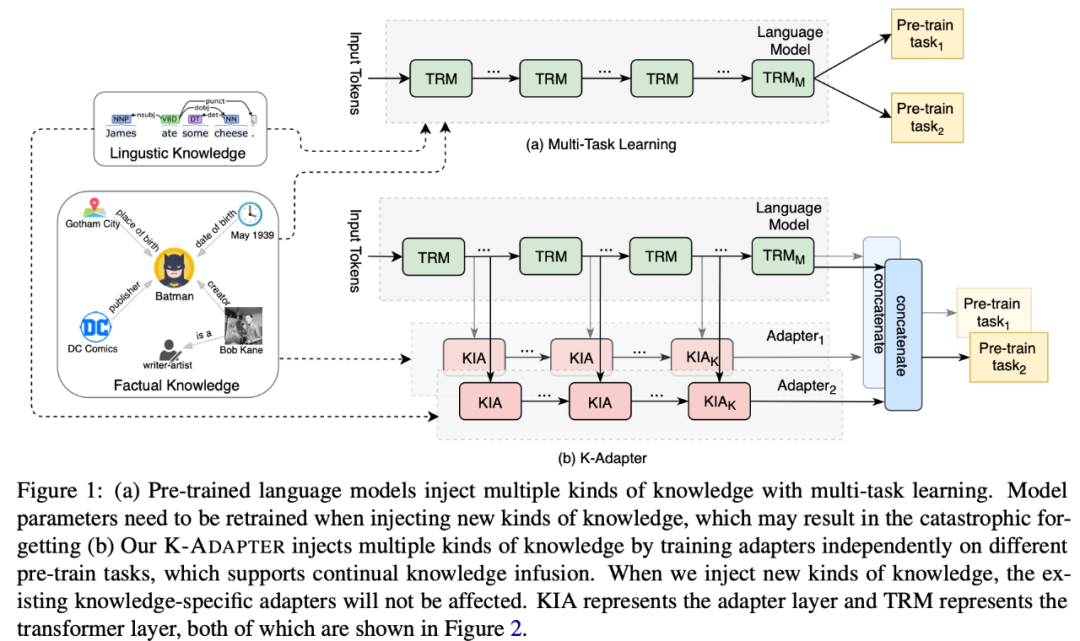
最近出現了一些向預訓練模型中融入知識的工作,如ERNIE、WKLM、KnowBERT等。下表中展示了本文工作和先前融入知識工作的對比。先前的工作通過多任務(multi-task)學習的方式訓練模型,也就是在原有的MLM訓練目標的基礎上,額外增加了用于融入知識的訓練目標,例如ERINE通過增加Entity Linking的訓練目標學習相關知識。由于這些方法在預訓練融入知識的階段BERT不是固定的,需要更新模型的全部參數,會使得模型融入知識的代價較大。而且他們不支持連續學習,模型的參數在引入新知識的時候需要重新訓練;對于已經學到的知識來說,會造成災難性遺忘(catastrophic forgetting)的問題。為了更好地解決上述問題,本文提出了 K-Adapter,一種靈活、簡便地向預訓練模型中注入知識的方法。
方法描述
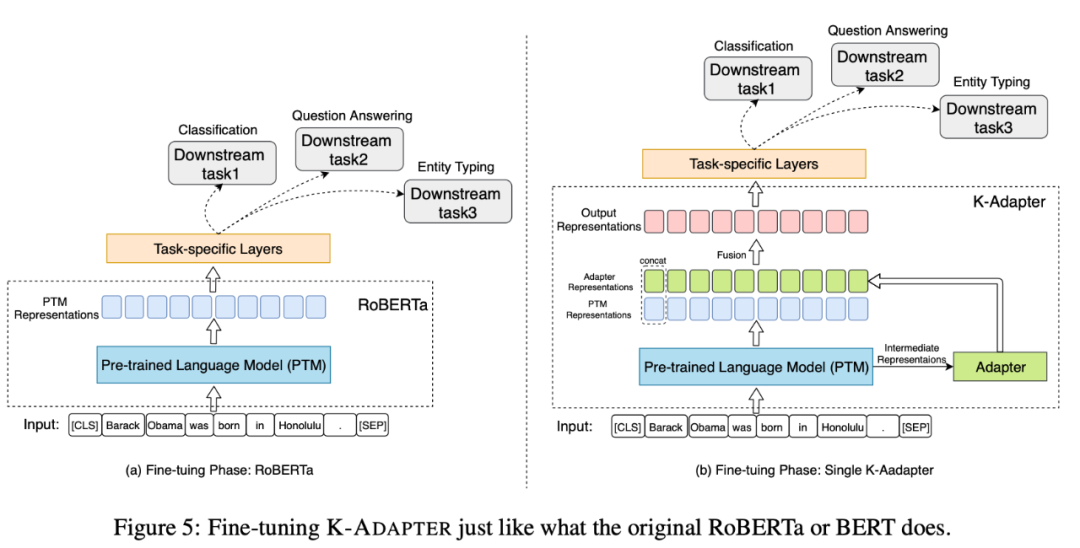
本文提出的方法如下圖所示。圖a是基于多任務學習融入知識的方法,圖b是本文模型K-Adapter,通過外掛在原始模型外的adapter,融入不同種類的知識。
1. Adapter結構
Adapter模型可以看做是知識特定模型,可以看做為插件,掛載在預訓練模型外部。具體而言,每個Adapter模型由K個Adapter層(如下圖所示,KIA)組成,其中每個Adapter層包含了N個Transformer層和兩個映射層(Projection Layer)。對于Adapter模型,本文將Adapter層插入到預訓練模型的不同Transformer層之間,將預訓練模型的中間層輸出的特征和前一個Adapter層的輸出特征拼接作為Adapter層的輸入。本文將預訓練模型和Adapter的最后一個隱藏特征拼接作為最終的輸出特征。
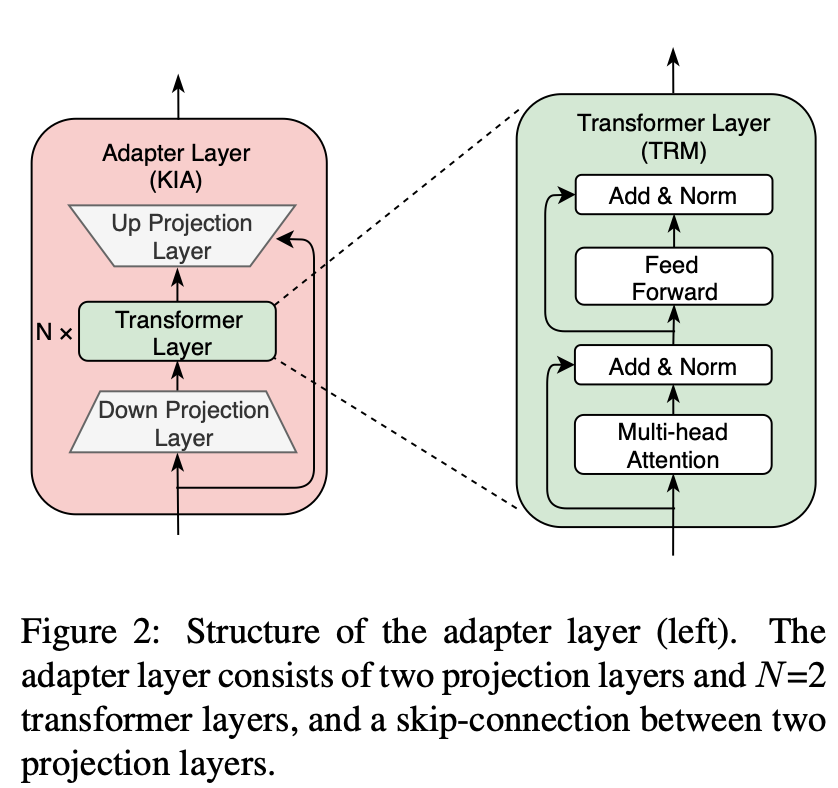
本文采用RoBERTa作為backbone。需要注意的是,RoBERTa在融入知識的預訓練過程中是固定的,但Adapter的參數是可訓練的。這樣的模型和訓練設定,緩解了融入知識時災難性遺忘的問題,不同知識的學習不受影響,融入知識效率更高;而且不同的Adapter間沒有信息流、可以利用分布式的方式同時、獨立地訓練。
本文通過設置不同的預訓練任務向Adapter中融入不同的知識。接下來介紹如何將不同種類的知識融入到特定的Adapter中。
2. 知識融入
下圖展示了向知識特定Adapter中融入知識的框圖。
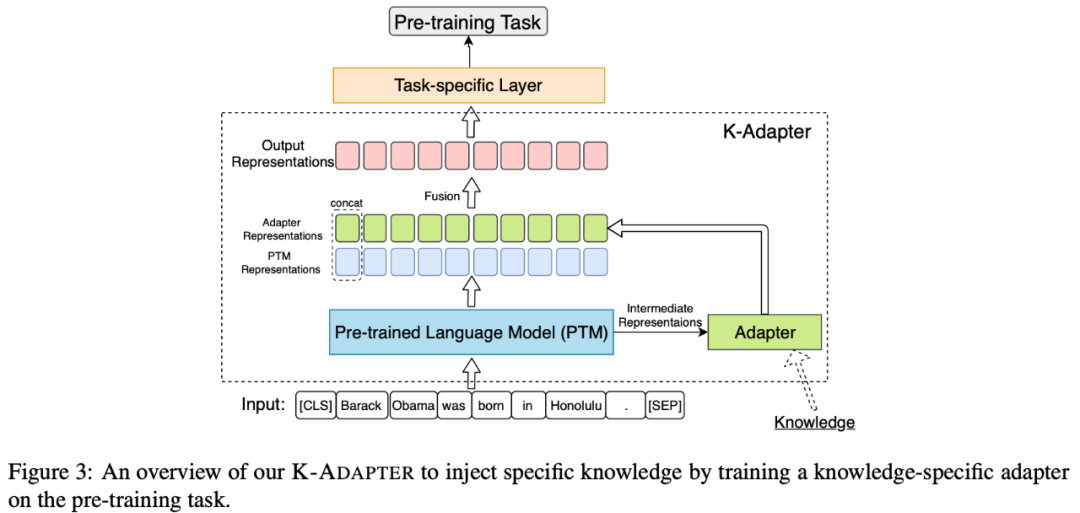
本文主要融入了2種知識——事實類知識和語言類知識,分別融入到了2種知識特定的adapter中:
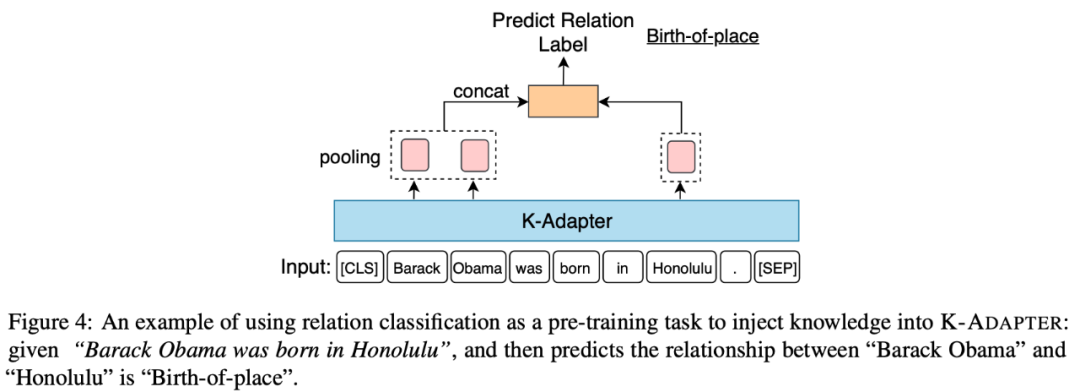
(1)Factual Adapter:Factual Adapter融入了事實類知識。此處的事實類知識指文本中實體之間的關系,來源于Wikipedia和Wikidata之間自動對齊的文本-三元組對。本文在關系分類任務上進行預訓練來融入知識,該任務要求給定1個句子和句子中的2個實體,然后要求模型預測出這兩個實體的關系。如下圖展示了融入事實類知識的示意圖。
(2)Linguistic Adapter:Linguistic Adapter融入了語言類知識。語言類的知識是自然語言中最基本的一類知識,比如說語義和語法信息。本文中的語言類知識指文本中詞之間的依存關系。本文在依存關系預測任務上進行預訓練來融入知識。這個任務要求模型預測出給定句子中,每個詞的father的index。
下圖展示了如何將Adapter應用在下游任務中。此處關鍵的點是預訓練模型特征+知識特征,即一方面利用預訓練模型的通用信息,一方面利用Adapter中的特定知識。
實驗
本文在3種知識驅動的下游任務上進行實驗,包含命名實體識別,問答和關系分類。此外,還通過案例分析和探究性實驗對模型學習事實類知識的有效性進行了分析。K-ADAPTER (F+L) 代表同時外掛事實類(factual) adapter和語言類(linguistic) adapter;K-ADAPTER (F) 代表外掛事實類(factual) adapter,K-ADAPTER (L) 代表外掛語言(linguistic) adapter。實驗中RoBERTa均指RoBERTa-Large。
1. 命名實體識別(Entity Typing)
命名實體識別任務是給定一個文本和指定的實體,讓模型預測出指定實體的類別。在OpenEntity和FIGER數據集上的結果如下表所示。在OpenEntity數據集上,本文模型K-ADAPTER(F+L)相比于RoBERTa進一步提高了1.38%的Mi-F1。在FIGER數據集上,與WKLM相比,K-ADAPTER (F+L)提高了2.88%的Ma-F1,提高了2.54%的Mi-F1。
2. 問答(Question Answering)
問答任務的目的是給定一個問題和一個文本,來讓模型做出回答,有時還會提供問題的上下文信息。在問答任務上的實驗結果如下表所示。在CosmosQA上,與BERT-FTRACE+SWAG相比,本文的RoBERTa在準確率上顯著提高了11.89%。與RoBERTa相比,K-ADAPTER(F+L)進一步提高了1.24%的準確率,這表明K-ADAPTER可以獲得更好的常識推理能力。在開放域的QA數據集(SearchQA和Quasar-T)上,與其他baseline相比,K-ADAPTER取得了更好的結果。這表明K-ADAPTER可以充分利用融入的知識,有利于根據檢索到的段落來回答問題。具體來說,在SearchQA上,K-ADAPTER(F+L)WKLM相比,顯著提高了4.01%的F1,甚至比WKLM+Ranking略高。值得注意的是,K-ADAPTER沒有建模檢索到的段落的置信度,而WKLM+Ranking額外利用了另一個基于BERT的ranker為檢索到的段落進行打分、排序。
3. 關系分類(Relation Classification)
關系分類任務是指給定一個文本和文本中的兩個實體,要求模型預測出這兩個實體之間的關系。在關系分類任務上的實驗結果如下表所示。結果表明,K-ADAPTER明顯優于所有baseline。特別地,(1)K-ADAPTER模型優于RoBERTa,證明了利用Adapter進行知識融入的有效性;(2)與RoBERTa+multitask相比,K-ADAPTER取得了更大的提升,這直接說明了K-ADAPTER相比于多任務學習方式融入知識的效果更好,有助于模型充分利用知識。
4. 案例分析(Case Study)
下表中展示了在TACRED數據集上,K-ADAPTER和RoBERTa的定性比較。結果表明,K-ADAPTER中的事實知識可以幫助模型從預測“no_relation”轉換到預測正確的類別標簽。
為了檢驗模型學習事實類知識的能力,本文在LAMA數據集上進行了探究(Probing)實驗。具體來說,該實驗是在zero-shot的設定下進行的,要求模型不在微調的情況下完成關于事實知識的完型填空,例如將“The native language of Mammootty is [MASK] ”作為輸入,讓模型預測出 [MASK]是什么。
總結
提出了一種靈活而簡單的方法K-Adapter,支持將知識注入到大規模預訓練語言模型中。
K-Adapter保持原有預訓練模型參數不變,使用不同的知識特定"插件"學習不同類別的知識,支持連續知識學習,從而緩解“知識遺忘”問題,即融入新的知識不會影響原有的知識;且由于不同adapter間沒有信息流,所以adapter可以用分布式的方式進行高效地訓練。
在三種知識驅動的任務上取得了顯著的效果,包括了命名實體識別、關系分類、問答。詳細的分析進一步證明K-Adapter可以學習到更為豐富的事實類知識,為如何有效地進行知識融入提供了一些見解。
責任編輯:lq6
-
語言
+關注
關注
1文章
97瀏覽量
24479 -
模型
+關注
關注
1文章
3504瀏覽量
50190
原文標題:通過外掛"插件"向預訓練語言模型中融入知識
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
AI原生架構升級:RAKsmart服務器在超大規模模型訓練中的算力突破
用PaddleNLP為GPT-2模型制作FineWeb二進制預訓練數據集

小白學大模型:訓練大語言模型的深度指南

用PaddleNLP在4060單卡上實踐大模型預訓練技術

騰訊公布大語言模型訓練新專利
【「基于大模型的RAG應用開發與優化」閱讀體驗】+大模型微調技術解讀

從零開始訓練一個大語言模型需要投資多少錢?

使用EMBark進行大規模推薦系統訓練Embedding加速

直播預約 |數據智能系列講座第4期:預訓練的基礎模型下的持續學習






 工商網監
工商網監
評論