") Prompt范式你們了解多少
Prompt范式你們了解多少

卷友們好,我是rumor。
之前我學(xué)習(xí)Prompt范式的源起PET后就鴿了很久,相信卷友們已經(jīng)把Prompt的論文都追完了,把我遠(yuǎn)遠(yuǎn)地落在了后面。周末我不甘被卷,奮起直追,連刷三篇paper,希望能趕上大家學(xué)習(xí)的步伐。
Prefix-tuning- Optimizing continuous prompts for generation
P-tuning-GPT Understands, Too
Prompt-tuning-The Power of Scale for Parameter-Efficient Prompt Tuning
自動化Prompt
Prompt范式的第一個(gè)階段,就是在輸入上加Prompt文本,再對輸出進(jìn)行映射。但這種方式怎么想都不是很優(yōu)雅,無法避免人工的介入。即使有方法可以批量挖掘,但也有些復(fù)雜(有這個(gè)功夫能標(biāo)不少高質(zhì)量語料),而且模型畢竟是黑盒,對離散文本輸入的魯棒性很差:

怎么辦呢?離散的不行,那就連續(xù)的唄
用固定的token代替prompt,拼接上文本輸入,當(dāng)成特殊的embedding輸入,這樣在訓(xùn)練時(shí)也可以對prompt進(jìn)行優(yōu)化,就減小了prompt挖掘、選擇的成本。
如何加入Prompt
前面的想法非常單純,但實(shí)際操作起來還是需要些技巧的。
Prefix-tuning
Prefix-tuning是做生成任務(wù),它根據(jù)不同的模型結(jié)構(gòu)定義了不同的Prompt拼接方式,在GPT類的自回歸模型上采用[PREFIX, x, y],在T5類的encoder-decoder模型上采用[PREFIX, x, PREFIX‘, y]:
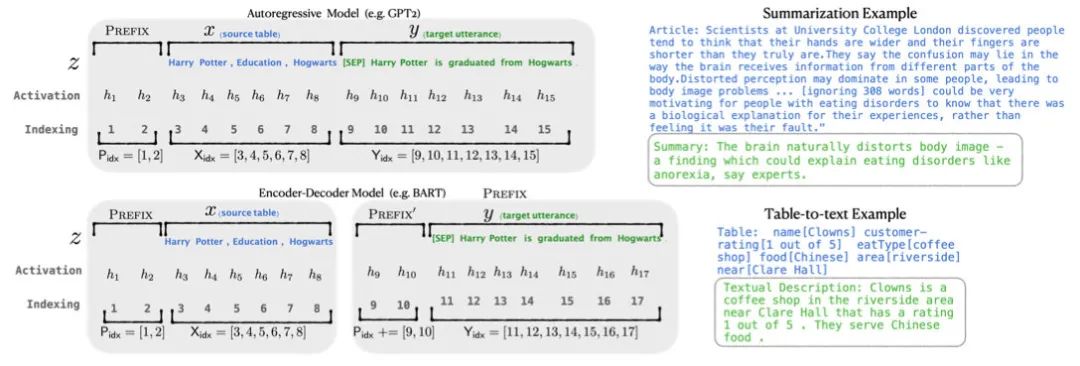
值得注意的還有三個(gè)改動:
把預(yù)訓(xùn)練大模型freeze住,因?yàn)榇竽P蛥?shù)量大,精調(diào)起來效率低,畢竟prompt的出現(xiàn)就是要解決大模型少樣本的適配
作者發(fā)現(xiàn)直接優(yōu)化Prompt參數(shù)不太穩(wěn)定,加了個(gè)更大的MLP,訓(xùn)練完只保存MLP變換后的參數(shù)就行了
實(shí)驗(yàn)證實(shí)只加到embedding上的效果不太好,因此作者在每層都加了prompt的參數(shù),改動較大
P-tuning
P-tuning是稍晚些的工作,主要針對NLU任務(wù)。對于BERT類雙向語言模型采用模版(P1, x, P2, [MASK], P3),對于單向語言模型采用(P1, x, P2, [MASK]):
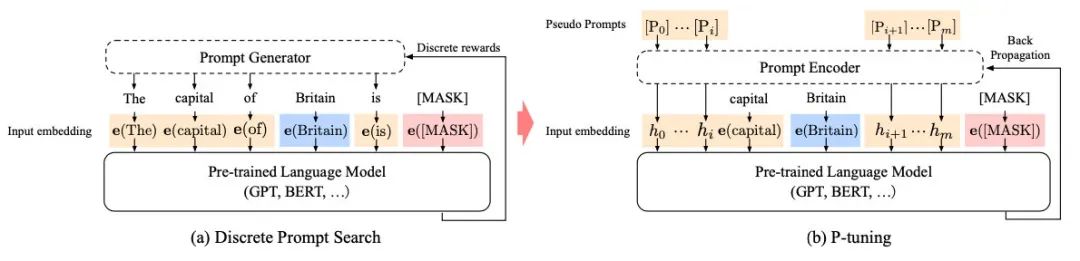
同時(shí)加了兩個(gè)改動:
考慮到預(yù)訓(xùn)練模型本身的embedding就比較離散了(隨機(jī)初始化+梯度傳回來小,最后只是小范圍優(yōu)化),同時(shí)prompt本身也是互相關(guān)聯(lián)的,所以作者先用LSTM對prompt進(jìn)行編碼
在輸入上加入了anchor,比如對于RTE任務(wù),加上一個(gè)問號變成[PRE][prompt tokens][HYP]?[prompt tokens][MASK]后效果會更好
P-tuning的效果很好,之前的Prompt模型都是主打小樣本效果,而P-tuning終于在整個(gè)數(shù)據(jù)集上超越了精調(diào)的效果:
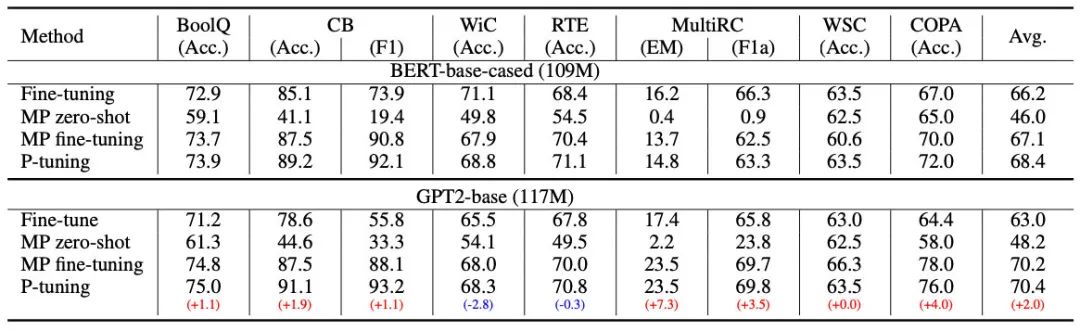
雖然P-tuning效果好,但實(shí)驗(yàn)對比也有些問題,它沒有freeze大模型,而是一起精調(diào)的,相當(dāng)于引入了額外的輸入特征,而平時(shí)我們在輸入加個(gè)詞法句法信息也會有提升,所以不能完全肯定這個(gè)效果是prompt帶來的。同時(shí)隨著模型尺寸增大,精調(diào)也會更難。
Prompt-tuning
Prompt-tuning就更加有信服力一些,純憑Prompt撬動了大模型。
Prompt-tuning給每個(gè)任務(wù)定義了自己的Prompt,拼接到數(shù)據(jù)上作為輸入,同時(shí)freeze預(yù)訓(xùn)練模型進(jìn)行訓(xùn)練,在沒有加額外層的情況下,可以看到隨著模型體積增大效果越來越好,最終追上了精調(diào)的效果:
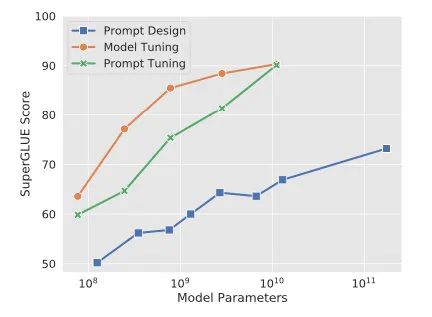
同時(shí),Prompt-tuning還提出了Prompt-ensembling,也就是在一個(gè)batch里同時(shí)訓(xùn)練同一個(gè)任務(wù)的不同prompt,這樣相當(dāng)于訓(xùn)練了不同「模型」,比模型集成的成本小多了。
其他Trick
除了怎么加Prompt之外,Prompt向量的初始化和長度也有所講究。
Prompt初始化
Prefix-tuning采用了任務(wù)相關(guān)的文字進(jìn)行初始化,而Prompt-tuning發(fā)現(xiàn)在NLU任務(wù)上用label文本初始化效果更好。不過隨著模型尺寸的提升,這種gap也會最終消失。
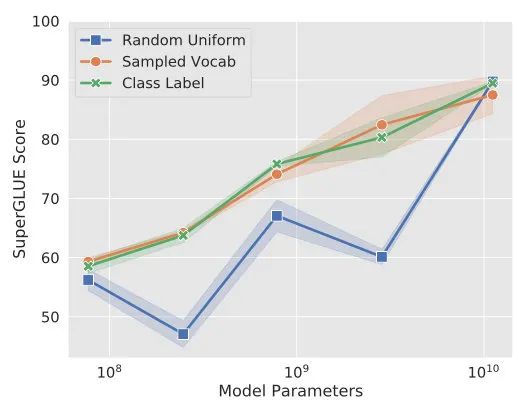
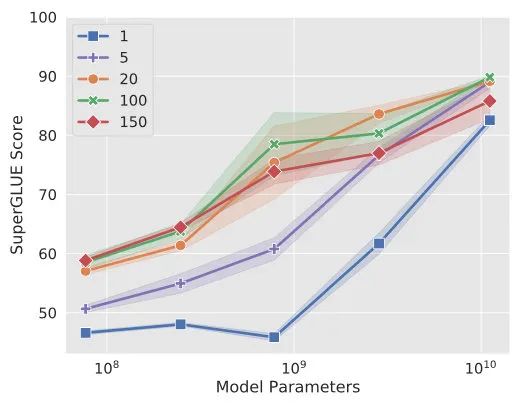
Prompt長度
從Prompt-tuning的實(shí)驗(yàn)可以看到,長度在10-20時(shí)的表現(xiàn)已經(jīng)不錯(cuò)了,同時(shí)這個(gè)gap也會隨著模型尺寸的提升而減小。
總結(jié)
要說上次看PET時(shí)我對Prompt范式還是將信將疑,看完這幾篇之后就比較認(rèn)可了。尤其是Prompt-tuning的一系列實(shí)驗(yàn),確實(shí)證明了增加少量可調(diào)節(jié)參數(shù)可以很好地運(yùn)用大模型,并且模型能力越強(qiáng),所需要的prompt人工調(diào)參就越少。
這種參數(shù)化Prompt的方法除了避免「人工」智能外,還有一方面就是省去了Y的映射。因?yàn)樵诰{(diào)的過程中,模型的輸出就被拿捏死了,而且Prompt-tuning還用label初始化Prompt,更加讓模型知道要輸出啥。
Finally,終于追上了前沿,大家的鬼點(diǎn)子可真多啊。
來源:李rumor
編輯:jq
-
PET
+關(guān)注
關(guān)注
1文章
45瀏覽量
18958 -
MLPM
+關(guān)注
關(guān)注
0文章
2瀏覽量
6859 -
prompt
+關(guān)注
關(guān)注
0文章
15瀏覽量
2767
原文標(biāo)題:Prompt范式,真香
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
【Milk-V Duo S 開發(fā)板免費(fèi)體驗(yàn)】Milk-V Duo S 開發(fā)板試用報(bào)告(6) 美化
物聯(lián)網(wǎng)+低代碼:解鎖高效開發(fā),縱橫智控Node-RED平臺引領(lǐng)新范式
研華科技攜手九大高校共探新工科人才培養(yǎng)新范式
AI了,這場盛會,見證傳統(tǒng)工廠的智造創(chuàng)新范式

ArkUI介紹
如何將一個(gè)FA模型開發(fā)的聲明式范式應(yīng)用切換到Stage模型
北京君正如何實(shí)現(xiàn)國產(chǎn)芯片的范式跨越
ALVA空間智能視覺焊接方案重構(gòu)工業(yè)焊接范式
AUDI攜手Momenta打造豪華智能輔助駕駛新范式
電子工程師如何利用AI革新設(shè)計(jì)范式
西湖大學(xué):科學(xué)家+AI,科研新范式的樣本

第四范式前三季度營收穩(wěn)健增長
東軟引領(lǐng)醫(yī)院智慧服務(wù)新范式
AI對話魔法 Prompt Engineering 探索指南






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論