 英偉達H100 Transformer引擎加速AI訓練 準確而且高達6倍性能
英偉達H100 Transformer引擎加速AI訓練 準確而且高達6倍性能

在當今計算平臺上,大型 AI 模型可能需要數月來完成訓練。而這樣的速度對于企業來說太慢了。
隨著一些模型(例如大型語言模型)達到數萬億參數,AI、高性能計算和數據分析變得日益復雜。
NVIDIA Hopper 架構從頭開始構建,憑借強大的算力和快速的內存來加速這些新一代 AI 工作負載,從而處理日益增長的網絡和數據集。
Transformer 引擎是全新 Hopper 架構的一部分,將顯著提升 AI 性能和功能,并助力在幾天或幾小時內訓練大型模型。
使用 Transformer 引擎訓練 AI 模型
Transformer 模型是當今廣泛使用的語言模型(例如 asBERT 和 GPT-3)的支柱。Transformer 模型最初針對自然語言處理用例而開發,但因其通用性,現在逐步應用于計算機視覺、藥物研發等領域。
與此同時,模型大小不斷呈指數級增長,現在已達到數萬億個參數。由于計算量巨大,訓練時間不得不延長到數月,而這樣就無法滿足業務需求。
Transformer 引擎采用 16 位浮點精度和新增的 8 位浮點數據格式,并整合先進的軟件算法,將進一步提升 AI 性能和功能。
AI 訓練依賴浮點數,浮點數是小數,例如 3.14。TensorFloat32 (TF32) 浮點格式是隨 NVIDIA Ampere 架構而面世的,現已成為 TensorFlow 和 PyTorch 框架中的默認 32 位格式。
大多數 AI 浮點運算采用 16 位“半”精度 (FP16)、32 位“單”精度 (FP32),以及面向專業運算的 64 位“雙”精度 (FP64)。Transformer 引擎將運算縮短為 8 位,能以更快的速度訓練更大的網絡。
與 Hopper 架構中的其他新功能(例如,在節點之間提供直接高速互連的 NVLink Switch 系統)結合使用時,H100 加速服務器集群能夠訓練龐大網絡,而這些網絡此前幾乎無法以企業所需的速度進行訓練。
更深入地研究 Transformer 引擎
Transformer 引擎采用軟件和自定義 NVIDIA Hopper Tensor Core 技術,該技術旨在加速訓練基于常見 AI 模型構建模塊(即 Transformer)構建的模型。這些 Tensor Core 能夠應用 FP8 和 FP16 混合精度,以大幅加速 Transformer 模型的 AI 計算。采用 FP8 的 Tensor Core 運算在吞吐量方面是 16 位運算的兩倍。
模型面臨的挑戰是智能管理精度以保持準確性,同時獲得更小、更快數值格式所能實現的性能。Transformer 引擎利用定制的、經NVIDIA調優的啟發式算法來解決上述挑戰,該算法可在 FP8 與 FP16 計算之間動態選擇,并自動處理每層中這些精度之間的重新投射和縮放。
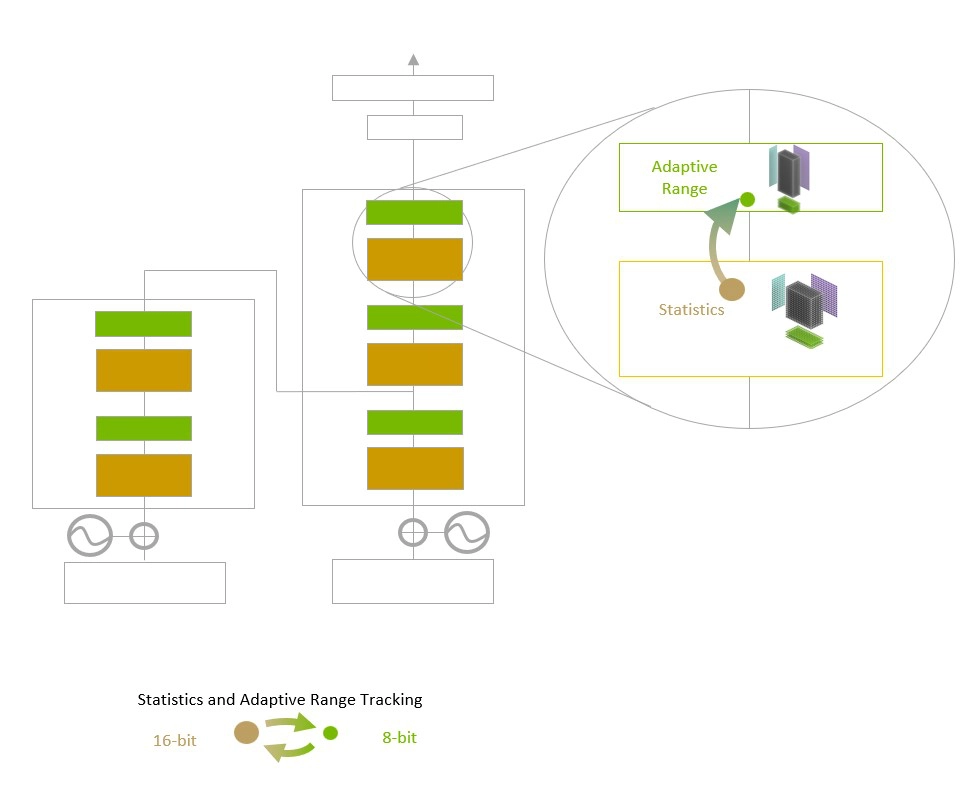
Transformer Engine 使用每層統計分析來確定模型每一層的最佳精度(FP16 或 FP8),在保持模型精度的同時實現最佳性能。
與上一代 TF32、FP64、FP16 和 INT8 精度相比,NVIDIA Hopper 架構還將每秒浮點運算次數提高了三倍,從而在第四代 Tensor Core 的基礎上實現了進一步提升。Hopper Tensor Core 與 Transformer 引擎和第四代 NVLink 相結合,可使 HPC 和 AI 工作負載的加速實現數量級提升。
加速 Transformer 引擎
AI 領域的大部分前沿工作都圍繞 Megatron 530B 等大型語言模型展開。下圖顯示了近年來模型大小的增長趨勢,業界普遍認為這一趨勢將持續發展。許多研究人員已經在研究用于自然語言理解和其他應用的超萬億參數模型,這表明對 AI 計算能力的需求有增無減。
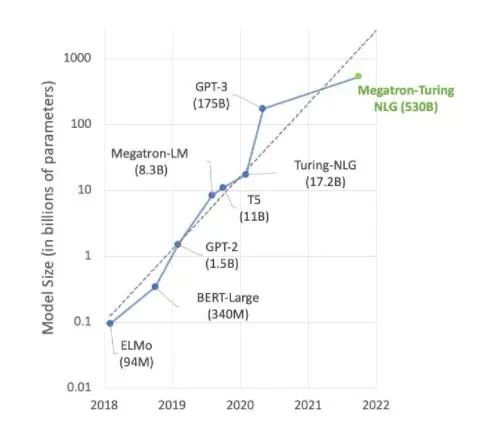
自然語言理解模型仍在快速增長。
為滿足這些持續增長的模型的需求,高算力和大量高速內存缺一不可。NVIDIA H100 Tensor Core GPU 兩者兼備,再加上 Transformer 引擎實現的加速,可助力 AI 訓練更上一層樓。
通過上述方面的創新,就能夠提高吞吐量,將訓練時間縮短 9 倍——從 7 天縮短到僅 20 個小時:
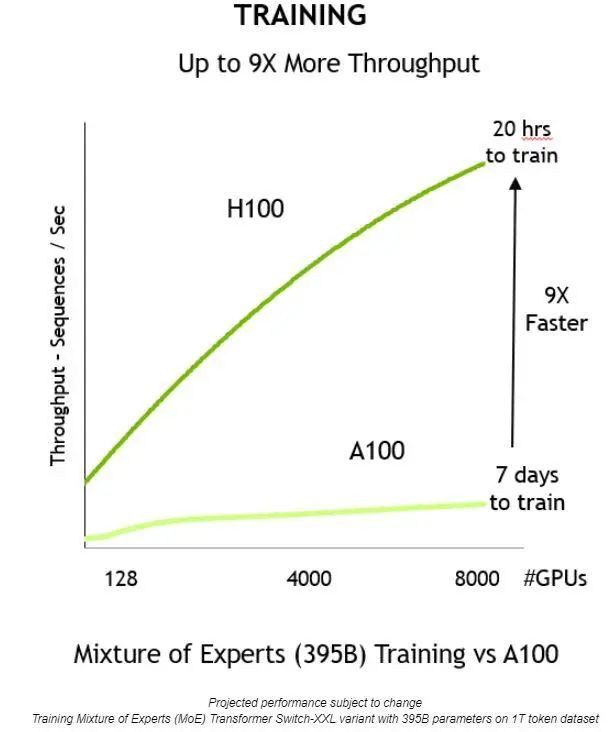
與上一代相比,NVIDIA H100 Tensor Core GPU 提供 9 倍的訓練吞吐量,從而可在合理的時間內訓練大型模型。
Transformer 引擎還可用于推理,無需進行任何數據格式轉換。以前,INT8 是實現出色推理性能的首選精度。但是,它要求經訓練的網絡轉換為 INT8,這是優化流程的一部分,而 NVIDIA TensorRT 推理優化器可輕松實現這一點。
使用以 FP8 精度訓練的模型時,開發者可以完全跳過此轉換步驟,并使用相同的精度執行推理操作。與 INT8 格式的網絡一樣,使用 Transformer 引擎的部署能以更小的內存占用空間運行。
在 Megatron 530B 上,NVIDIA H100 的每 GPU 推理吞吐量比 NVIDIA A100 高 30 倍,響應延遲為 1 秒,這表明它是適用于 AI 部署的上佳平臺:
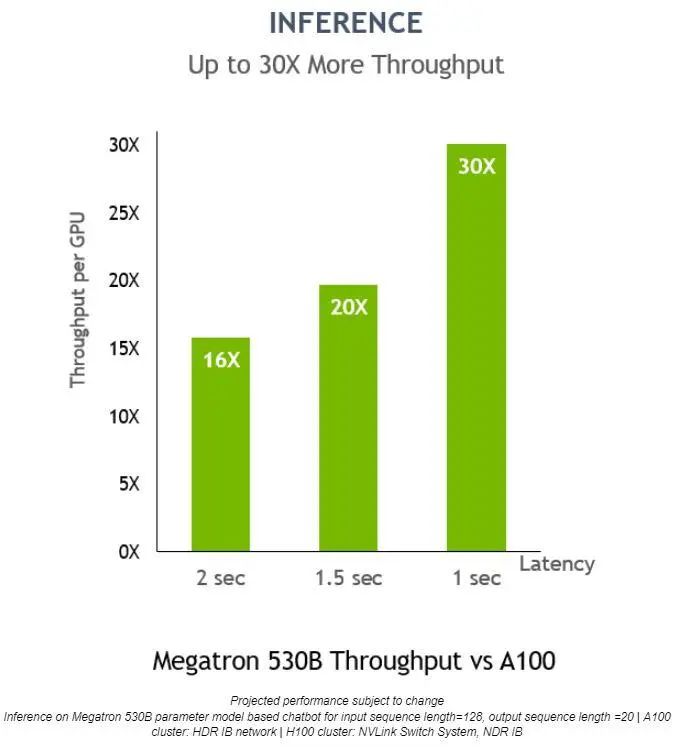
對于低延遲應用,Transformer 引擎還可將推理吞吐量提高 30 倍。
-
AI
+關注
關注
88文章
35002瀏覽量
278705 -
英偉達
+關注
關注
22文章
3940瀏覽量
93544 -
H100
+關注
關注
0文章
33瀏覽量
415
原文標題:GTC22 | H100 Transformer 引擎大幅加速 AI 訓練,在不損失準確性的情況下提供高達 6 倍的性能
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
GPU 維修干貨 | 英偉達 GPU H100 常見故障有哪些?

特朗普要叫停英偉達對華特供版 英偉達H20出口限制 或損失55億美元
新思科技攜手英偉達加速芯片設計,提升芯片電子設計自動化效率

英偉達H100芯片市場降溫
英偉達推出歸一化Transformer,革命性提升LLM訓練速度
英偉達發布AI模型 Llama-3.1-Nemotron-51B AI模型
英特爾發布Gaudi3 AI加速器,押注低成本優勢挑戰市場
亞馬遜云科技宣布Amazon EC2 P5e實例正式可用 由英偉達H200 GPU提供支持
英偉達Blackwell可支持10萬億參數模型AI訓練,實時大語言模型推理
英偉達打造人形機器人訓練平臺,引領AI新紀元
蘋果AI模型訓練新動向:攜手谷歌,未選英偉達






 工商網監
工商網監
評論