") 一種基于亂序語(yǔ)言模型的預(yù)訓(xùn)練模型-PERT
一種基于亂序語(yǔ)言模型的預(yù)訓(xùn)練模型-PERT

寫(xiě)在前面
今天分享給大家一篇哈工大訊飛聯(lián)合實(shí)驗(yàn)室的論文,一種基于亂序語(yǔ)言模型的預(yù)訓(xùn)練模型-PERT,全名《PERT: PRE-TRAINING BERT WITH PERMUTED LANGUAGE MODEL》。該篇論文的核心是,將MLM語(yǔ)言模型的掩碼詞預(yù)測(cè)任務(wù),替換成詞序預(yù)測(cè)任務(wù),也就是在不引入掩碼標(biāo)記[MASK]的情況下自監(jiān)督地學(xué)習(xí)文本語(yǔ)義信息,隨機(jī)將一段文本的部分詞序打亂,然后預(yù)測(cè)被打亂詞語(yǔ)的原始位置。
PERT模型的Github以及對(duì)應(yīng)的開(kāi)源模型其實(shí)年前就出來(lái)了,只是論文沒(méi)有放出。今天一瞬間想起來(lái)去看一眼,這不,論文在3月14號(hào)的時(shí)候掛到了axirv上,今天分享給大家。
paper:https://arxiv.org/pdf/2203.06906.pdf
github:https://github.com/ymcui/PERT
介紹
預(yù)訓(xùn)練語(yǔ)言模型(PLMs)目前在各種自然語(yǔ)言處理任務(wù)中均取得了優(yōu)異的效果。預(yù)訓(xùn)練語(yǔ)言模型主要分為自編碼和自回歸兩種。自編碼PLMs的預(yù)訓(xùn)練任務(wù)通常是掩碼語(yǔ)言模型任務(wù),即在預(yù)訓(xùn)練階段,使用[MASK]標(biāo)記替換原始輸入文本中的一些token,并在詞匯表中恢復(fù)這些被[MASK]的token。
常用預(yù)訓(xùn)練語(yǔ)言模型總結(jié):https://zhuanlan.zhihu.com/p/406512290
那么,自編碼PLMs只能使用掩碼語(yǔ)言模型任務(wù)作為預(yù)訓(xùn)練任務(wù)嗎?我們發(fā)現(xiàn)一個(gè)有趣的現(xiàn)象“在一段文本中隨機(jī)打亂幾個(gè)字并不會(huì)影響我們對(duì)這一段文本的理解”,如下圖所示,乍一看,可能沒(méi)有注意到句子中存在一些亂序詞語(yǔ),并且可以抓住句子的中心意思。該論文探究了是否可以通過(guò)打亂句子中的字詞來(lái)學(xué)習(xí)上下文的文本表征,并提出了一個(gè)新的預(yù)訓(xùn)練任務(wù),即亂序語(yǔ)言模型(PerLM)。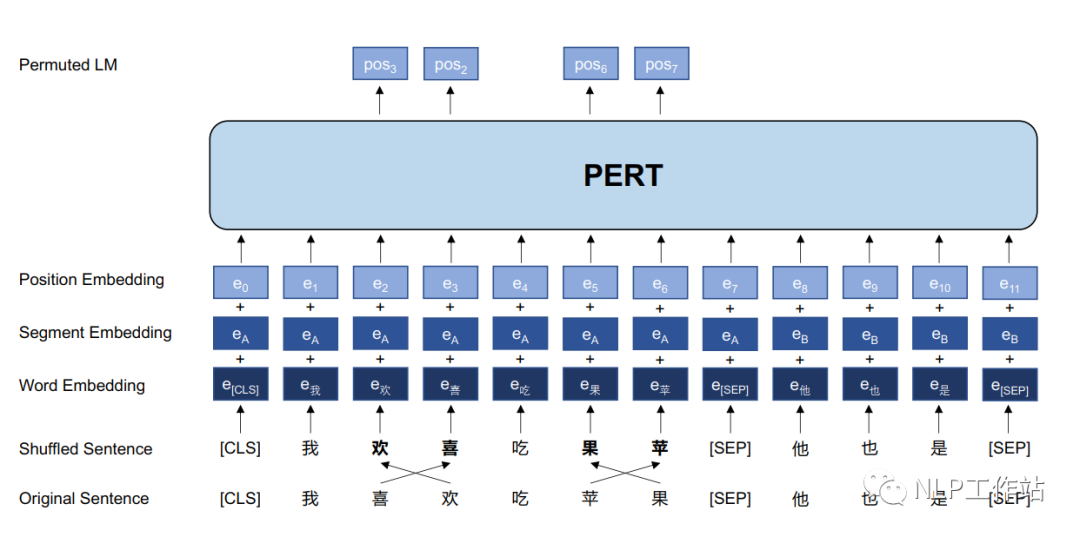
模型
PERT模型結(jié)構(gòu)如上圖所示。PERT模型結(jié)構(gòu)與BERT模型結(jié)構(gòu)相同,僅在模型輸入以及預(yù)訓(xùn)練目標(biāo)上略有不同。
PERT模型的細(xì)節(jié)如下:
- 采用亂序語(yǔ)言模型作為預(yù)訓(xùn)練任務(wù),預(yù)測(cè)目標(biāo)為原始字詞的位置;
- 預(yù)測(cè)空間大小取決于輸入序列長(zhǎng)度,而不是整個(gè)詞表的大小(掩碼語(yǔ)言模型預(yù)測(cè)空間為詞表);
- 不采用NSP任務(wù);
- 通過(guò)全詞屏蔽和N-gram屏蔽策略來(lái)選擇亂序的候選標(biāo)記;
- 亂序的候選標(biāo)記的概率為15%,并且真正打亂順序僅占90%,剩余10%保持不變。
由于亂序語(yǔ)言模型不使用[MASK]標(biāo)記,減輕了預(yù)訓(xùn)練任務(wù)與微調(diào)任務(wù)之間的gap,并由于預(yù)測(cè)空間大小為輸入序列長(zhǎng)度,使得計(jì)算效率高于掩碼語(yǔ)言模型。PERT模型結(jié)構(gòu)與BERT模型一致,因此在下游預(yù)訓(xùn)練時(shí),不需要修改原始BERT模型的任何代碼與腳本。注意,與預(yù)訓(xùn)練階段不同,在微調(diào)階段使用正常的輸入序列,而不是打亂順序的序列。
中文實(shí)驗(yàn)結(jié)果與分析
預(yù)訓(xùn)練參數(shù)
- 數(shù)據(jù):由中文維基百科、百科全書(shū)、社區(qū)問(wèn)答、新聞文章等組成,共5.4B字,大約20G。
- 訓(xùn)練參數(shù):詞表大小為21128,最大序列長(zhǎng)度為512,batch大小為416(base版模型)和128(large版模型),初始學(xué)習(xí)率為1e-4,使用 warmup動(dòng)態(tài)調(diào)節(jié)學(xué)習(xí)率,總訓(xùn)練步數(shù)為2M,采用ADAM優(yōu)化器。
- 訓(xùn)練設(shè)備:一臺(tái)TPU,128G。
機(jī)器閱讀理解MRC任務(wù)
在CMRC2018和DRCD兩個(gè)數(shù)據(jù)集上對(duì)機(jī)器閱讀理解任務(wù)進(jìn)行評(píng)測(cè),結(jié)果如下表所示。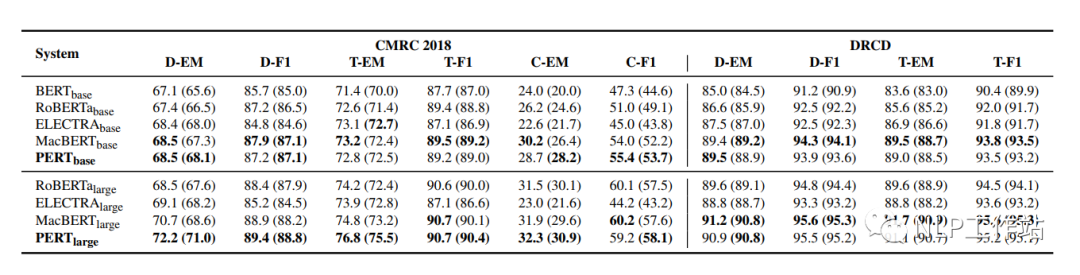
PERT模型相比于MacBERT模型有部分的提高,并且始終優(yōu)于其他模型。
文本分類TC任務(wù)
在XNLI、LCQMC、BQ Corpus、ChnSentiCorp、TNEWS和OCNLI 6個(gè)數(shù)據(jù)集上對(duì)文本分類任務(wù)進(jìn)行評(píng)測(cè),結(jié)果如下表所示。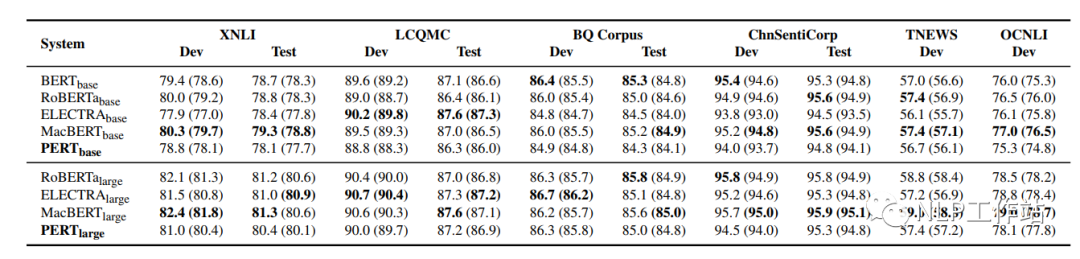
在文本分類任務(wù)上,PERT模型表現(xiàn)不佳。推測(cè)與MRC任務(wù)相比,預(yù)訓(xùn)練中的亂序文本給理解短文本帶來(lái)了困難。
命名實(shí)體識(shí)別NER任務(wù)
在MSRA-NER和People’s Daily兩個(gè)數(shù)據(jù)集上對(duì)命名實(shí)體識(shí)別任務(wù)進(jìn)行評(píng)測(cè),結(jié)果如下表所示。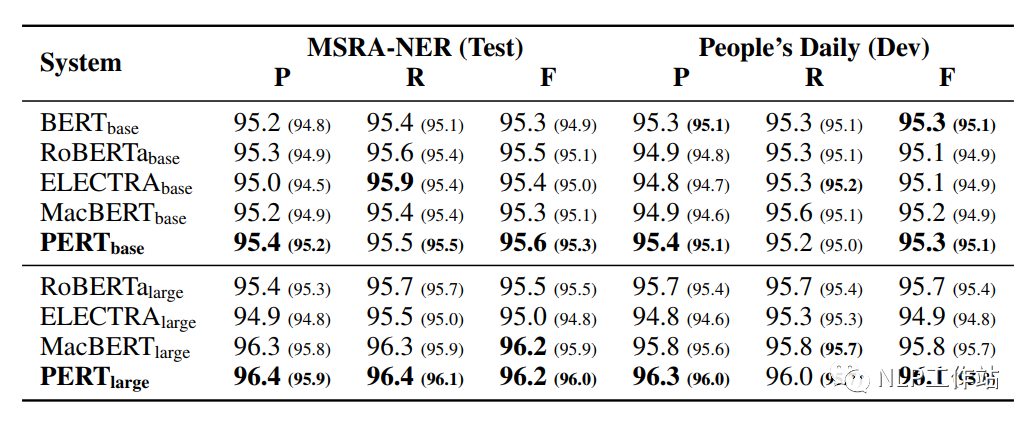
PERT模型相比于其他模型均取得最優(yōu)的效果,表明預(yù)訓(xùn)練中的亂序文在序列標(biāo)記任務(wù)中的良好能力。
對(duì)比機(jī)器閱讀理解、文本分類和命名實(shí)體識(shí)別三個(gè)任務(wù),可以發(fā)現(xiàn),PERT模型在MRC和NER任務(wù)上表現(xiàn)較好,但在TC任務(wù)上表現(xiàn)不佳,這意味著TC任務(wù)對(duì)詞語(yǔ)順序更加敏感,由于TC任務(wù)的輸入文本相對(duì)較短,有些詞語(yǔ)順序的改變會(huì)給輸入文本帶來(lái)完全的意義變化。然而,MRC任務(wù)的輸入文本通常很長(zhǎng),幾個(gè)單詞的排列可能不會(huì)改變整個(gè)文章的敘述流程;并且對(duì)于NER任務(wù),由于命名實(shí)體在整個(gè)輸入文本中只占很小的比例,因此詞語(yǔ)順序改變可能不會(huì)影響NER進(jìn)程。
語(yǔ)法檢查任務(wù)
在Wikipedia、Formal Doc、Customs和Legal 4個(gè)數(shù)據(jù)集上對(duì)文本分類任務(wù)進(jìn)行評(píng)測(cè)語(yǔ)法檢查任務(wù)進(jìn)行評(píng)測(cè),結(jié)果如下表所示。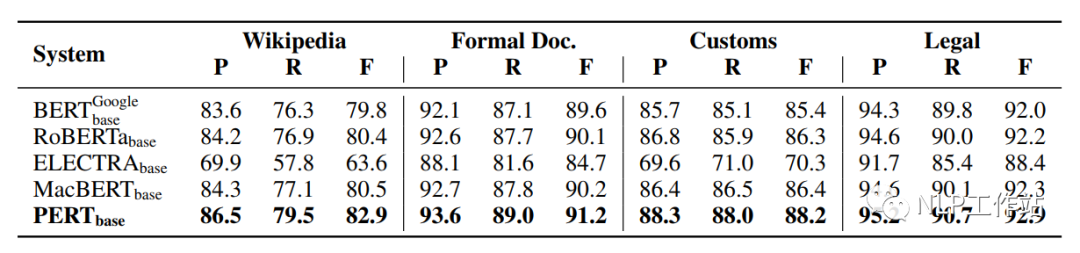
PERT模型相比于其他模型均取得最優(yōu)的效果,這是由于下游任務(wù)與預(yù)訓(xùn)練任務(wù)非常相似導(dǎo)致的。
預(yù)訓(xùn)練的訓(xùn)練步數(shù)對(duì)PERT模型的影響
不同的下游任務(wù)的最佳效果可能出現(xiàn)在不同的預(yù)訓(xùn)練步驟上,如下圖所示。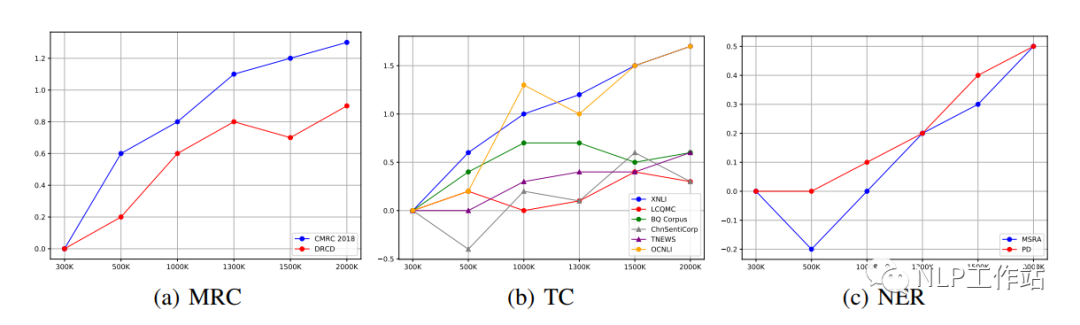
我們發(fā)現(xiàn)對(duì)于MRC和NER任務(wù),隨著預(yù)訓(xùn)練步數(shù)的增加,下游任務(wù)也會(huì)隨之提高。然而,對(duì)于TC任務(wù),不同數(shù)據(jù)的指標(biāo)在不同的步數(shù)上取得最優(yōu)。如果考慮到特定任務(wù)的效果,有必要在早期訓(xùn)練中保存部分模型。
不同的打亂粒度對(duì)PERT模型的影響
不同粒度間的打亂,可以使使輸入文本更具可讀性。通過(guò)在不同粒度內(nèi)亂序輸入文本來(lái)比較性能,如下表所示。
我們發(fā)現(xiàn),在各種打亂粒度中,無(wú)限制亂序的PERT模型在所有任務(wù)中都取得了最優(yōu)的效果;而選擇最小粒度(詞語(yǔ)之間)的模型,效果最差。可能原因是,雖然使用更小的粒度的亂序可以使輸入文本更具可讀性,但是對(duì)預(yù)訓(xùn)練任務(wù)的挑戰(zhàn)性較小,使模型不能學(xué)習(xí)到更好地語(yǔ)義信息。
不同預(yù)測(cè)空間對(duì)PERT模型的影響
將PERT模型使用詞表空間作為預(yù)測(cè)目標(biāo)是否有效?如下表所示。
實(shí)驗(yàn)結(jié)果表明,PERT模型不需要在詞表空間中進(jìn)行預(yù)測(cè),其表現(xiàn)明顯差于在輸入序列上的預(yù)測(cè);并且將兩者結(jié)合的效果也不盡如人意。
預(yù)測(cè)部分序列和預(yù)測(cè)全部序列對(duì)PERT模型的影響
ELECTRA模型的實(shí)驗(yàn)發(fā)現(xiàn)預(yù)測(cè)完全序列的效果比部分序列的更好,因此ELECTRA模型采用RTD任務(wù)對(duì)判別器采用完全序列預(yù)測(cè)。但通過(guò)本論文實(shí)驗(yàn)發(fā)現(xiàn),預(yù)測(cè)完全序列在PERT模型中并沒(méi)有產(chǎn)生更好的效果。表明在預(yù)訓(xùn)練任務(wù)中使用預(yù)測(cè)全部序列并不總是有效的,需要根據(jù)所設(shè)計(jì)的預(yù)訓(xùn)練任務(wù)進(jìn)行調(diào)整。
總結(jié)
PERT模型的預(yù)訓(xùn)練思路還是挺有意思的,并在MRC、NER和WOR任務(wù)上均取得了不錯(cuò)的效果。并且由于結(jié)構(gòu)與BERT模型一致,因此在下游任務(wù)使用時(shí),僅修改預(yù)訓(xùn)練模型加載路徑就實(shí)現(xiàn)了模型替換,也比較方便。當(dāng)打比賽或者做業(yè)務(wù)時(shí)候,可以不妨試一試,說(shuō)不定有奇效。(ps:我在我們自己的MRC數(shù)據(jù)集上做過(guò)實(shí)驗(yàn),效果不錯(cuò)呦!!)
審核編輯 :李倩
-
語(yǔ)言模型
+關(guān)注
關(guān)注
0文章
561瀏覽量
10771 -
自然語(yǔ)言處理
+關(guān)注
關(guān)注
1文章
628瀏覽量
14136
原文標(biāo)題:PERT:一種基于亂序語(yǔ)言模型的預(yù)訓(xùn)練模型
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
用PaddleNLP為GPT-2模型制作FineWeb二進(jìn)制預(yù)訓(xùn)練數(shù)據(jù)集

小白學(xué)大模型:訓(xùn)練大語(yǔ)言模型的深度指南

用PaddleNLP在4060單卡上實(shí)踐大模型預(yù)訓(xùn)練技術(shù)

一文詳解視覺(jué)語(yǔ)言模型

騰訊公布大語(yǔ)言模型訓(xùn)練新專利
【「基于大模型的RAG應(yīng)用開(kāi)發(fā)與優(yōu)化」閱讀體驗(yàn)】+大模型微調(diào)技術(shù)解讀
KerasHub統(tǒng)一、全面的預(yù)訓(xùn)練模型庫(kù)
大語(yǔ)言模型開(kāi)發(fā)框架是什么
什么是大模型、大模型是怎么訓(xùn)練出來(lái)的及大模型作用

寫(xiě)給小白的大模型入門科普
從零開(kāi)始訓(xùn)練一個(gè)大語(yǔ)言模型需要投資多少錢?

直播預(yù)約 |數(shù)據(jù)智能系列講座第4期:預(yù)訓(xùn)練的基礎(chǔ)模型下的持續(xù)學(xué)習(xí)

【《大語(yǔ)言模型應(yīng)用指南》閱讀體驗(yàn)】+ 基礎(chǔ)知識(shí)學(xué)習(xí)
【《大語(yǔ)言模型應(yīng)用指南》閱讀體驗(yàn)】+ 俯瞰全書(shū)
大語(yǔ)言模型的預(yù)訓(xùn)練
- 設(shè)計(jì)技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測(cè)量?jī)x表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無(wú)線
- 接口/總線/驅(qū)動(dòng)
- 處理器/DSP
- EDA/IC設(shè)計(jì)
- 存儲(chǔ)技術(shù)
- 光電顯示
- EMC/EMI設(shè)計(jì)
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實(shí)
- 可穿戴設(shè)備
- 機(jī)器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動(dòng)通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測(cè)
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學(xué)院
- 設(shè)計(jì)資源
- 設(shè)計(jì)技術(shù)
- 電子百科
- 電子視頻
- 元器件知識(shí)
- 工具箱
- VIP會(huì)員
- 最新技術(shù)文章
- 產(chǎn)品地圖
- 品牌地圖
- 社區(qū)
- 小組
- 論壇
- 問(wèn)答
- 評(píng)測(cè)試用
- 企業(yè)服務(wù)
- 產(chǎn)品
- 資料
- 文章
- 方案
- 企業(yè)
- 供應(yīng)鏈服務(wù)
- 硬件開(kāi)發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會(huì)
- 活動(dòng)策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測(cè)驗(yàn)
- 設(shè)計(jì)大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動(dòng)態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報(bào)投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動(dòng)端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長(zhǎng)沙市望城經(jīng)濟(jì)技術(shù)開(kāi)發(fā)區(qū)航空路6號(hào)手機(jī)智能終端產(chǎn)業(yè)園2號(hào)廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
評(píng)論