") PolarDB云原生數(shù)據(jù)庫是如何進行性能優(yōu)化的?
PolarDB云原生數(shù)據(jù)庫是如何進行性能優(yōu)化的?

云數(shù)據(jù)庫實現(xiàn)計算存儲分離,支持計算與存儲的獨立擴展,其用戶還可以享受按量付費等特性。這使得基于云數(shù)據(jù)庫的系統(tǒng)更加高效、靈活。因此,構建并使用云原生數(shù)據(jù)庫的勢頭愈演愈烈。另一方面,云化存儲服務已經(jīng)是云的標準能力,存儲側提供兼容通用的文件接口,并且不對外暴露持久化、容錯處理等復雜細節(jié),其易用性和規(guī)模化帶來的高性價比使得云存儲成為了云上系統(tǒng)的第一選擇。在通用云存儲服務上構建云數(shù)據(jù)庫,無疑是一種既能夠享受規(guī)模化云存儲紅利,又能夠通過可靠云存儲服務實現(xiàn)降低維護成本、加速數(shù)據(jù)庫開發(fā)周期的方案。 然而,考慮到云存儲和本地存儲之間的特性差異,在將本地數(shù)據(jù)庫遷移到云上構建云數(shù)據(jù)庫時,如何有效使用云存儲面臨了許多挑戰(zhàn)。對此,我們在論文里分析了基于B-tree和LSM-tree的存儲引擎在云存儲上部署時面臨的挑戰(zhàn),并提出了一個優(yōu)化框架CloudJump,以希望能夠幫助數(shù)據(jù)庫開發(fā)人員在基于云存儲構建數(shù)據(jù)庫時使系統(tǒng)更為高效。我們以云原生數(shù)據(jù)庫PolarDB為案例,展示了一系列針對性優(yōu)化,并將部分工作擴展應用到基于云存儲的RocksDB上,以此來演示CloudJump的可用性。
背景 我們討論的云存儲主要基于彈性分布式塊存儲,云中其他類型的存儲服務,例如基于對象的存儲,不在本文的討論范圍內(nèi)。共享云存儲(如分布式塊存儲服務加分布式文件系統(tǒng))可以作為多個計算節(jié)點的共享存儲層,提供QoS(服務質量)保證、大容量、彈性和按量付費定價模型。對于大多數(shù)云廠商和云用戶來說,擁有云存儲服務比構建和維護裸機SSD集群更有吸引力。因此,與其為云本機數(shù)據(jù)庫構建和優(yōu)化專用存儲服務,不如利用現(xiàn)有云存儲服務構建云本機數(shù)據(jù)庫,這是一種非常可行的選擇。此外,隨著云存儲服務幾乎實現(xiàn)了標準化,相應的開發(fā)、遷移變得更加快速。
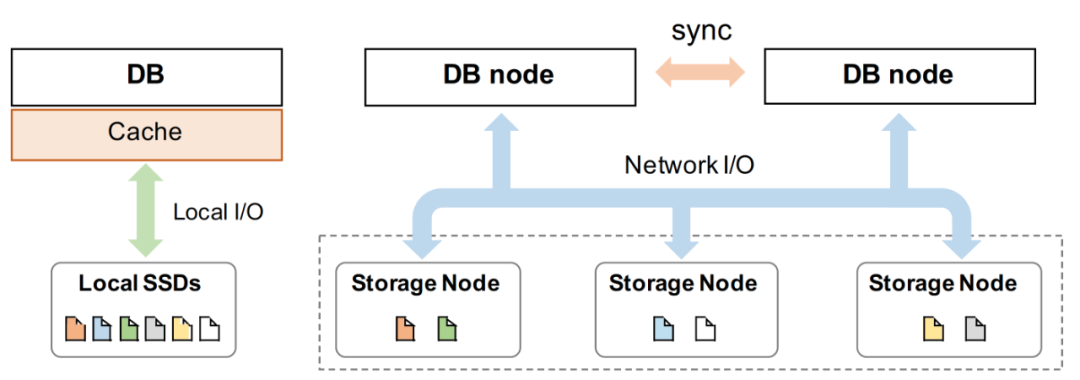
圖1展示了本地數(shù)據(jù)庫(不含備份)與shared-storage云原生數(shù)據(jù)庫的系統(tǒng)結構,AWS Aurora首先引導了這種從本地數(shù)據(jù)庫向shared-storage云原生數(shù)據(jù)庫的遷移。它將數(shù)據(jù)庫分為存儲層和計算層,并可以獨立擴展每一層。為了消除了傳輸數(shù)據(jù)頁中產(chǎn)生的沉重的網(wǎng)絡開銷,它進一步定制了存儲層,在數(shù)據(jù)頁上應用重做日志,從而不再需要在兩層之間傳輸數(shù)據(jù)頁。無疑這種設計在云中提供了一種非標準存儲服務,只能由Aurora的計算層使用。 另一種方案是依賴標準化接口的云存儲服務遷移或構建獲得云數(shù)據(jù)庫,這也是本文的研究目標。前面已經(jīng)提到過,這樣做的優(yōu)勢主要在于的可以實現(xiàn)系統(tǒng)的快速開發(fā)、平滑遷移、收納標準化規(guī)模化存儲服務的原有優(yōu)勢等。此外,特別是在我們項目(PolarDB)的硬件環(huán)境、已有背景下,兼顧服務可靠性和開發(fā)迭代需求,針對進行云存儲服務特性進行性能優(yōu)化是最迫切的第一步。
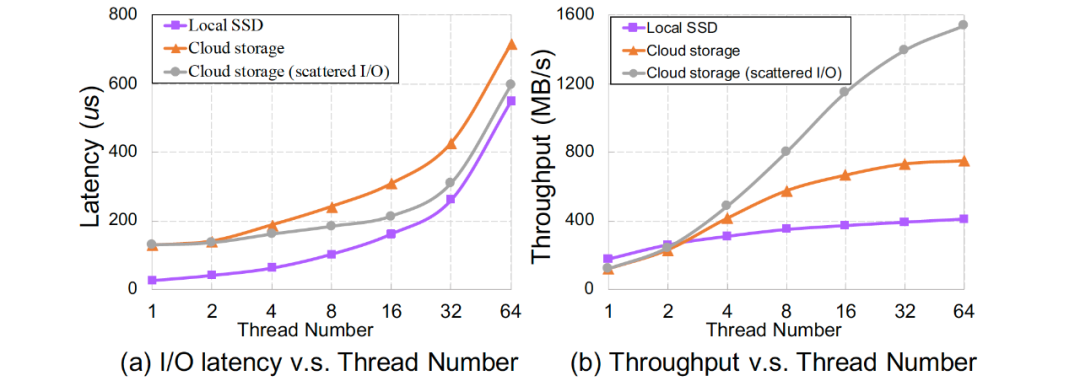
挑戰(zhàn)與分析 云存儲和本地SSD存儲在帶寬、延遲、彈性、容量等方面存在巨大差異,例如圖2展示了在穩(wěn)態(tài)條件下本地SSD與云存儲I/O延時、帶寬與工作線程關系,它們對數(shù)據(jù)庫等設計有著巨大影響。此外,共享存儲的架構特性也會對云存儲帶來影響,如多個節(jié)點之間的數(shù)據(jù)一致性增加了維護cache一致性開銷。
通過系統(tǒng)實驗、總結分析等,我們發(fā)現(xiàn)CloudJump面臨以下技術挑戰(zhàn):
遠程分布式存儲集群的訪問導致云存儲服務的I/O延遲高;
通常聚合I/O帶寬未被充分利用;
在具有本地存儲的單機上運行良好但需要適應云存儲而導致特性改變的傳統(tǒng)設計,例如文件cache緩存;
長鏈路導致各種數(shù)據(jù)庫I/O操作之間的隔離度較低(例如,日志刷寫與大量數(shù)據(jù)I/O的競爭);
云用戶允許且可能使用非常大的單表文件(例如數(shù)十TB)而不進行數(shù)據(jù)切分,這加劇了I/O問題的影響。
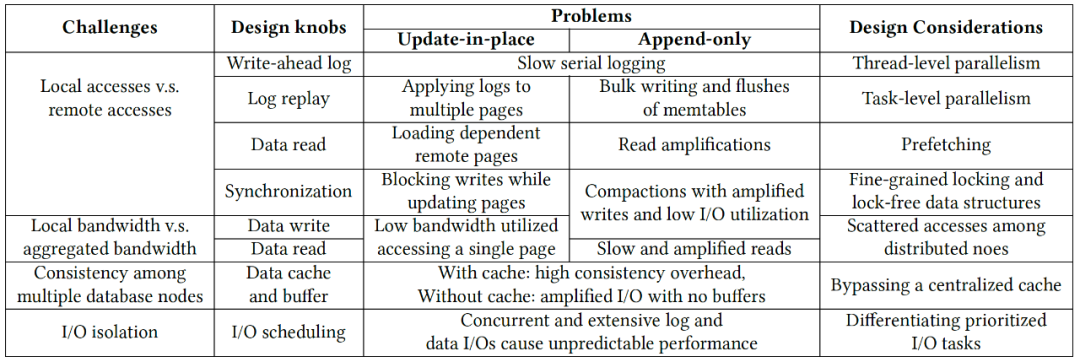
針對不同的數(shù)據(jù)存儲引擎,如基于B-tree和LSM-tree的存儲引擎,這些特性差異會帶來不同的性能差異,表1歸納總結了這些挑戰(zhàn)及其對數(shù)據(jù)庫設計的影響。其中有共性問題,如WAL路徑寫入變慢、共享存儲(分布式文件系統(tǒng))cache一致性代價等;也有個性問題,如B-tree結構在獨占資源情況下做遠程I/O、遠程加劇I/OLSM-tree讀放大影響等。
優(yōu)化原則 CloudJump針對上述挑戰(zhàn),提出7條優(yōu)化準則:
Thread-level Parallelism:例如依據(jù)I/O特性實驗,采用(更)多線程的日志、數(shù)據(jù)I/O線程及異步I/O模型,將數(shù)據(jù)充分打散到多個存儲節(jié)點上。
Task-level Parallelism:例如對集中Log buffer按Page Partition分片,實現(xiàn)并行寫入并基于分片進行并行Recovery。
Reduce remote read and Prefetching:例如通過收集并聚合原分散meta至統(tǒng)一的superblock,將多個I/O合一實現(xiàn)fast validating;通過預讀利用聚合讀帶寬、減少讀任務延時;通過壓縮、filter過濾減少讀取數(shù)據(jù)量。與本地SSD上相比,這些技術在云存儲上更能獲得收益。
Fine-grained Locking and Lock-free Data Structures:云存儲中較長的I/O延遲放大了同步開銷,主要針對Update-in-place系統(tǒng),實現(xiàn)無鎖刷臟、無鎖SMO等。
Scattering among Distributed Nodes:在云存儲中,多個節(jié)點之間的分散訪問可以利用更多的硬件資源,例如將單個大I/O并發(fā)分散至不同存儲節(jié)點 ,充分利用聚合帶寬。
Bypassing Caches:通過Bypassing Caches來避免分布式文件系統(tǒng)的cache coherence,并在DB層面優(yōu)化I/O格式匹配存儲最佳request格式。
Scheduling Prioritized I/O Tasks:由于訪問鏈路更長(如路徑中存在更多的排隊情況),不填I/O請求間的隔離性相對本地存儲更低,因此需要在DB層面對不同I/O進行打標、調度優(yōu)先級,例:優(yōu)先WAL、預讀分級。
實踐案例
實踐案例:PolarDB
PolarDB構建基于具有兼容Posix接口的分布式文件系統(tǒng)PolarFS,與Aurora一樣采用計算存儲分離架構,借助高速RDMA網(wǎng)絡以及最新的塊存儲技術實現(xiàn)超低延遲和高可用能力能力。在PolarDB上,我們做了許多適配于分布式存儲特性、符合CloudJump準則的性能優(yōu)化,大幅提升了云原生數(shù)據(jù)庫PolarDB的性能。
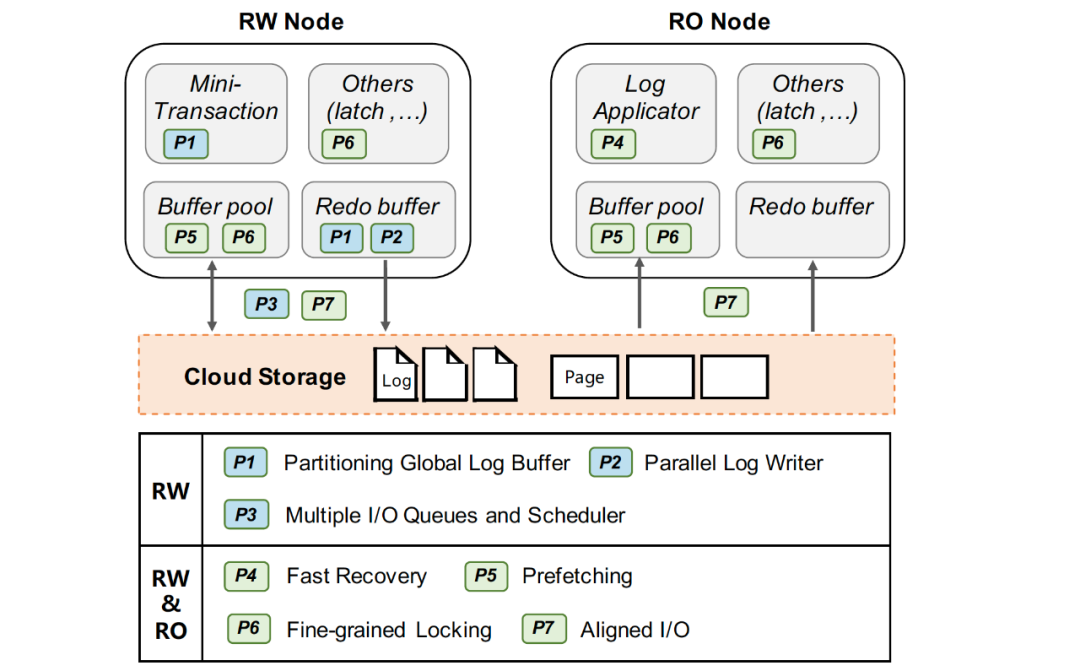
1. WAL寫入優(yōu)化 WAL(Write ahead log)寫入是用于一致性和持久性的關鍵路徑,事務的寫入性能對log I/O的延遲非常敏感。原生InnoDB以MTR(Mini-Transaction)的粒度組織日志,并保有一個全局redo日志緩沖區(qū)。當一個MTR被提交時,它緩存的所有日志記錄被追加到全局日志緩沖區(qū),然后集中的順序刷盤以保證持久化特性。這一傳統(tǒng)集中日志模式在本地盤上工作良好,但使用云存儲時,集中式日志的寫入性能隨著遠程I/O時延變高而下降,進而影響事務寫入性能。基于云存儲的特性,我們提出了兩個優(yōu)化來提升WAL的寫入性能:日志分片和(大)I/O任務并行打散。
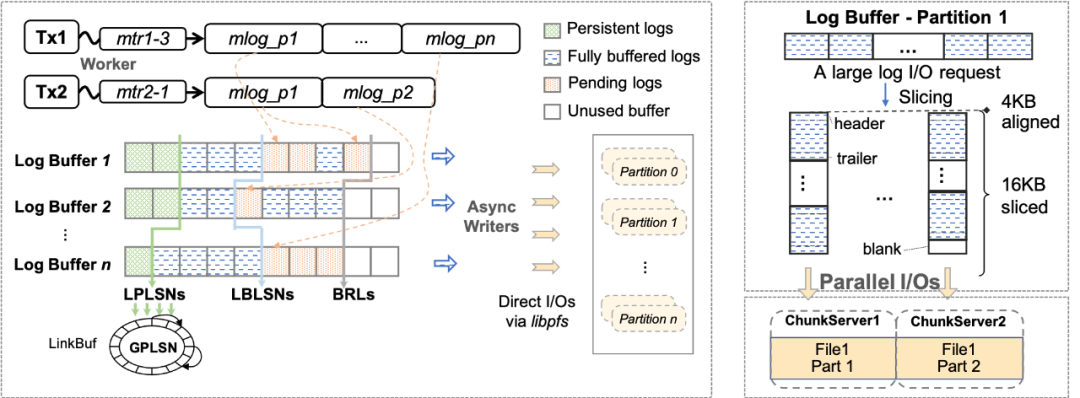
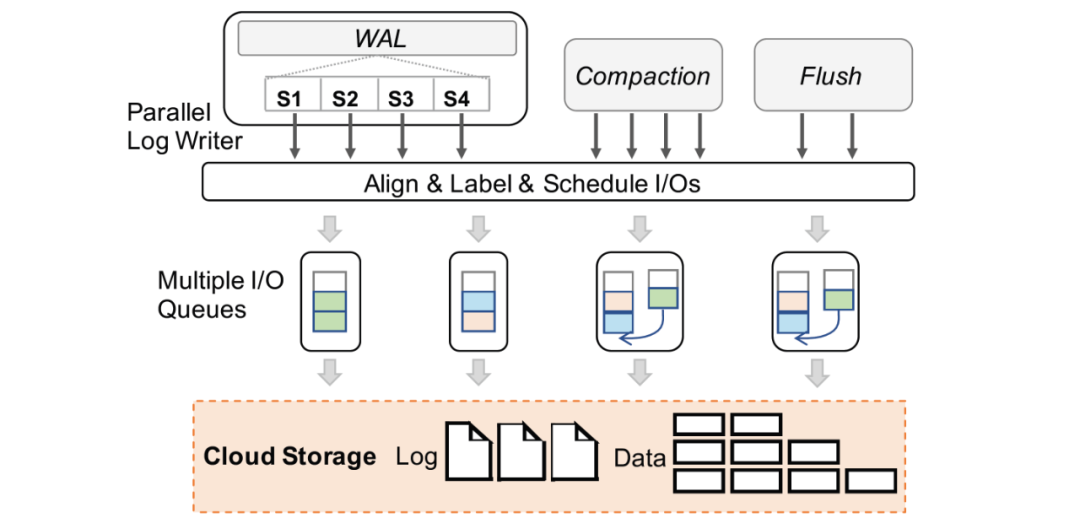
Redo日志分片:InnoDB的redo采用的是Physiological Logging的方式,大部分MTR針對單個的數(shù)據(jù)頁(除部分特殊),頁之間基本相互獨立。如圖5(左),我們將redo日志、redo緩沖區(qū)等按其修改的page進行分片(partition),分別寫入不同的文件中,來支持并發(fā)寫log(以及并發(fā)Recovery,并發(fā)物理復制等),從而在并發(fā)寫友好的分布式文件系統(tǒng)上的獲得寫入性能優(yōu)勢。 I/O任務并行打散:在云存儲中,一個文件由多個chunk組成,根據(jù)chunk的分配策略,不同chunk很可能位于不同的存儲節(jié)點中。我們將每個redo分片(partition)的文件進一步拆分為多個物理分片(split),如圖5(右)所示,對于單個大log I/O任務(如group commit、BLOB record等),log writer會將I/O按lsn切片并且并發(fā)的分發(fā)I/O請求至不同split。通過這種方式,可以將大延時的log I/O任務拆分,并利用分布式存儲高分布寫特性來減少整體I/O時間。 2. 快速恢復 為了實現(xiàn)快速恢復,我們提出了兩個優(yōu)化:快速(啟動)驗證和全并行恢復。
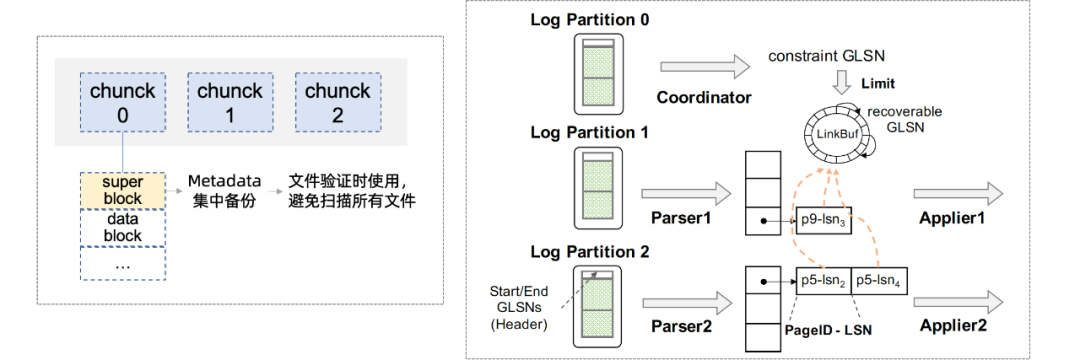
在InnoDB的原有恢復過程中,InnoDB首先在啟動期間會打開所有文件讀取元信息(如文件名、表ID等)并驗證正確性,然后通過ARIES風格的恢復算法重做未checkpoint的數(shù)據(jù)。為了加速啟動,快速驗證方法不會掃描所有文件,而是在數(shù)據(jù)庫的生命周期中記錄和集中必要的元信息,并在創(chuàng)建、修改文件時將必要的元信息集中記錄在一個superblock中,在啟動時僅掃描元數(shù)據(jù)塊文件。因此,減少了啟動掃描過程中的遠程I/O訪問開銷。其次,依賴于Redo日志分片,我們將log file按page拆分成多個文件,在恢復階段(可以進一步劃分為parse、redo、undo三個階段),可以天然的支持并發(fā)parse和redo(undo階段在后臺進行),通過并發(fā)任務充分調動CPU和I/O資源加速恢復。
3. 預讀取
在云存儲環(huán)境下,讀I/O延時大大增加,當用戶任務訪問數(shù)據(jù)發(fā)生cache miss的情況下,而有效的預讀取能夠充分利用聚合讀帶寬來減少讀任務延時。InnoDB中有線性預讀和非線性預讀兩種原生的物理預讀方法,我們進一步引入了邏輯預讀策略(由于無序的插入和更新,索引在物理上不一定是順序的)。例如對于主索引掃描,當任務線程從起始鍵順序掃描索引超過一定閾值時,邏輯預讀會在主索引上按邏輯順序觸發(fā)異步預讀,提前讀取一定量的順序頁。又如對于具有二級索引和非索引列回表操作的掃描,在對二級索引進行掃描同時批量收集相關命中的主鍵,積累一定批數(shù)據(jù)后觸發(fā)異步任務預讀對應主索引數(shù)據(jù)(此時剩余的二級索引掃描可能仍在進行中)。
4. 同步(鎖)優(yōu)化
相關背景可以先查閱《InnoDB btree latch 優(yōu)化歷程》[1]這篇文章。
無鎖刷臟:原生InnoDB在刷臟時需要持有當前page的sx鎖,導致I/O期間當前page的寫入被完全阻塞。而在云存儲上I/O延遲更高,阻塞時間更久。我們采用shadow page的方式,首先對當前page構建內(nèi)存副本,構建好內(nèi)存副本后原有page的sx鎖被釋放,然后用這個shadow page內(nèi)容去做刷臟及相關刷寫信息更新。
SMO加鎖優(yōu)化:在InnoDB 里面, 依然有一個全局的index latch, 由于全局的index latch 存在會導致同一時刻在Btree 中只有一個SMO 能夠發(fā)生, index latch 依然會成為全局的瓶頸點。上述index latch不僅是計算瓶頸,而從另一方面考慮,鎖同步期間index上其他可能I/O操作無法并行,存儲帶寬利用率較低。相關實現(xiàn)可以參考文章《路在腳下, 從BTree 到Polar Index》[2]。
5. 多I/O任務隊列適配
針對云存儲具有I/O隔離性低的挑戰(zhàn),同時為了避免云存儲無法識別DB層存儲內(nèi)核的I/O語義,而造成優(yōu)先級低的I/O請求(如page刷臟、低優(yōu)先級預讀)影響關鍵I/O路徑的性能,在數(shù)據(jù)庫內(nèi)核中提供合理的I/O調度模型是很重要的。在 PolarDB 中,我們在數(shù)據(jù)庫內(nèi)核層為不同類型的I/O請求進行調度,實現(xiàn)根據(jù)當前I/O壓力實現(xiàn)數(shù)據(jù)庫最優(yōu)的性能,每個I/O請求都具有 DB 層的語義標簽,如 WAL 讀/寫,Page 讀/寫。
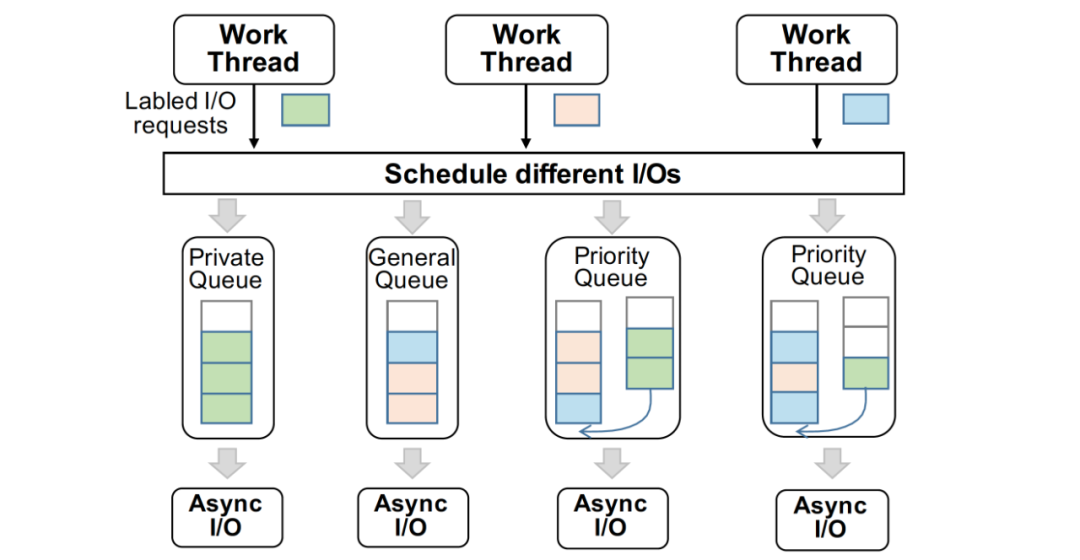
我們?yōu)閿?shù)據(jù)庫的異步I/O請求建立了多個支持并發(fā)寫入的生產(chǎn)者 / 消費者隊列,并且其存在三種不同特性的隊列,分別為 Private 隊列,Priority 隊列,以及 General 隊列,不同隊列的數(shù)量是根據(jù)當前云存儲的I/O能力決定的。
正常情況下,WAL 的寫入只通過其 Private 隊列,當寫入量增大時,其I/O請求也會轉發(fā)至 Priority 隊列,此時 Priority 隊列會優(yōu)先執(zhí)行 WAL 的寫入,并且后續(xù)Page寫入的I/O不會進入 Priority 隊列。基于這種I/O模型,我們保證了一定部分的I/O資源時預留給WAL寫入,保證事務提交的寫入性能,充分利用云存儲的高聚合帶寬。此外,I/O任務隊列的長度和數(shù)目也進行了拓展以一步匹配云存儲高吞吐、大帶寬但時延較高且波動大的特性。
6. 格式化I/O請求
云存儲和本地存儲在I/O格式上具有顯著的不同,例如 Block 大小,I/O請求的發(fā)起方式。在大多數(shù)分布式的云存儲中,在實現(xiàn)多個計算節(jié)點的共享時,為了避免維護計算節(jié)點 cache 一致性的問題,不存在 page cache,此時采用原先本地存儲的I/O格式在云上會造成例如 read-on-write 和邏輯與物理位置映射的問題,造成性能下降。在 PolarDB中,我們?yōu)閃AL I/O和 Page I/O匹配了適應云存儲的請求I/O格式以盡可能降低單個I/O的延時。
WAL I/O對齊:文件是通過固定大小的 block 進行讀寫的。云存儲具有更大的 block size (4-128 KB),傳統(tǒng)的 log 對齊策略不適合云存儲上的 stripe boundary。我們在 log 數(shù)據(jù)進行提交的時候,將I/O請求的長度和偏移與云存儲的 block size進行對齊。
Data I/O對齊:例如當前存在兩種類型的數(shù)據(jù)頁:常規(guī)頁和壓縮頁,常規(guī)頁為16 KB,可以很容易與云存儲的 Block size 進行對齊,但是壓縮頁會造成后續(xù)大量的不對齊I/O。以PolarDB 中對于壓縮頁的對齊為例。首先,我們讀取時保證以最小單位(如PolarFS的4 KB)讀取。而在寫入時,對于所有小于最小訪問單元的壓縮頁數(shù)據(jù),我們會拓展到最小單位再進行寫入,以保證存儲上的頁數(shù)據(jù)都是最小單位對齊的。
去除 Data I/O合并:在本地數(shù)據(jù)庫中,數(shù)據(jù)頁的I/O會被合并來形成大的I/O實現(xiàn)連續(xù)地順序寫入。在云存儲中,并發(fā)地向不同存儲節(jié)點寫入具有更高的性能,因此在云存儲的數(shù)據(jù)庫上,可以無需數(shù)據(jù)頁的I/O合并操作。
受篇幅所限,我們在本文中只簡單介紹所提優(yōu)化方法的大致實現(xiàn)邏輯,具體實現(xiàn)細節(jié)請讀者查閱論文及相關文章。
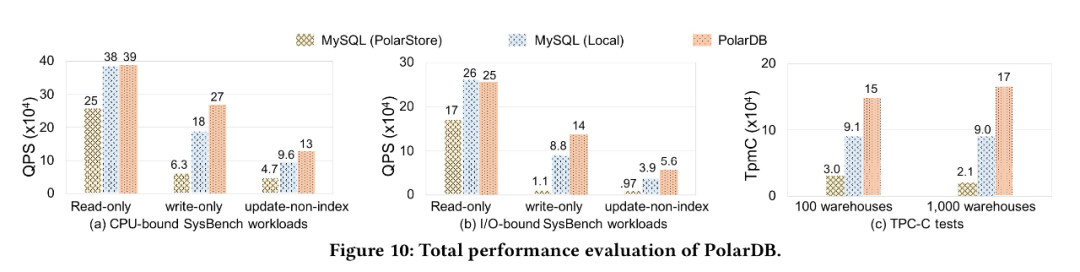
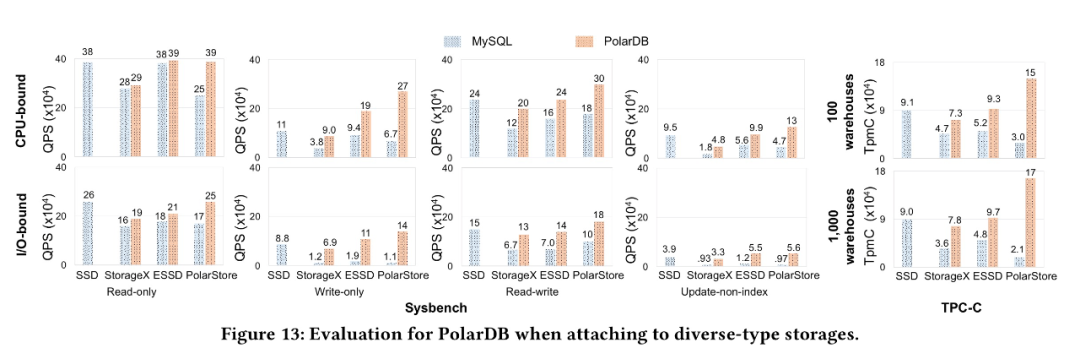
為了驗證我們的優(yōu)化效果, 我們對比了為針對云存儲優(yōu)化的MySQL 分別運行在PolarStore 和 Local Disk, 以及我們優(yōu)化以后的PolarDB, 從下圖可以看到PolarDB 在CPU-bound, IO-bound sysbench, TPCC 等各個場景下都表現(xiàn)除了明顯的性能優(yōu)勢。
同時, 為了證明我們的優(yōu)化效果不僅僅對于我們自己的云存儲PolarStore 有收益, 對于所有的云存儲應該都有收益, 因此我們將針對云存儲優(yōu)化的PolarDB 運行在 StorageX, ESSD 等其他云存儲上, 我們發(fā)現(xiàn)均能獲得非常好的性能提升, 從而說明我們的優(yōu)化對于大部分云存儲都是有非常大的收益
實踐案例:RocksDB
我們還將CloudJump的分析框架和部分優(yōu)化方法拓展到基于云存儲的RocksDB上,同樣獲得了預計的性能收益。
1. Log I/O任務并行打散
RocksDB同樣使用集中WAL來保證進程崩潰的一致性,集中日志收集多個column family的日志記錄并持久化至單個日志文件。考慮到LSM-Tree只需要恢復尾部append-only的數(shù)據(jù)塊,我們采用在上一個案例中提到的log I/O并行打散的方法在log writer中切分批日志并且并行分發(fā)到不同文件分片中。
2. 數(shù)據(jù)訪問加速
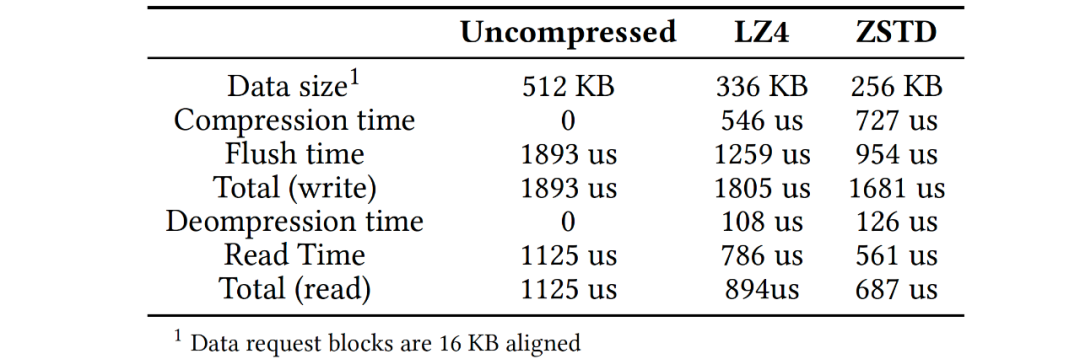
在RocksDB中有許多加速數(shù)據(jù)訪問的技術,主要有prefetching, filtering 和compression機制。考慮到云存儲的特性,這些技術(經(jīng)過適當改造)在云存儲環(huán)境中更有價值。經(jīng)過分析和實驗,我們提出了以下建議:1)預讀機制能加速部分查詢和compaction操作,建議compaction操作開啟預讀并設定合理的預讀I/O任務優(yōu)先級,并將單個預讀操作的大小對齊存儲粒度,對于查詢操作預讀應由用戶場景確定;2)在云存儲上建議開啟bloom filters,并且將filter的meta和常規(guī)數(shù)據(jù)分離,將filter信息并集中管理;3)采用塊壓縮來減小數(shù)據(jù)訪問的整體用時,如下表展示了數(shù)據(jù)量和PolarFS訪問延時,表中存儲基于RDMA,在延遲更高的存儲環(huán)境中,壓縮收益更高,引入壓縮后數(shù)據(jù)訪問的整體延時(特別是讀延時)下降。
3. 多I/O任務隊列及適配
在多核硬件環(huán)境中,我們引入了一個多隊列I/O模型并在RocksDB中拆分I/O任務和工作任務(例如壓縮作業(yè)和刷新作業(yè))。這是因為我們通過調整I/O線程的數(shù)量來控制較好吞吐和延遲關系。由于將I/O任務與后臺刷寫作業(yè)分離,因此無需進一步增加刷寫線程的數(shù)量,刷寫線程只會對齊I/O請求并進行調度分發(fā)。RocksDB本身提供了基于線程角色的優(yōu)先級調度方案,而我們的調度方法這里是基于I/O標簽。
我們根據(jù)云存儲調整I/O請求和數(shù)據(jù)組織(例如block和SST)的大小,并進行更精確的控制,以使SST文件過濾器的塊大小也正確對齊。以PolarFS為例,存儲的最小請求大小為4 KB(表示最小的處理單元),理想的請求大小為16 KB的倍數(shù)(不造成read-on-write),元數(shù)據(jù)存儲粒度為4 MB。SST大小和塊大小分別嚴格對齊存儲粒度和理想請求大小的倍數(shù)。原生RocksDB也有對齊策略,我們在此需要進行存儲參數(shù)適配并且對壓縮數(shù)據(jù)塊也進行對齊。
我們不會向多隊列I/O模型傳遞小于最小請求大小的I/O請求,而是對齊最小I/O大小,并將未對齊的后綴緩存在內(nèi)存中以供后續(xù)對齊使用。其次,我們不會下發(fā)單個大于存儲粒度的I/O請求,而是通過多隊列I/O模型執(zhí)行并行任務(例如一個6 MB的I/O會分散成4 MB加1 MB的兩個任務)。這不僅可以將數(shù)據(jù)盡可能分散在不同的存儲節(jié)點上,還可以最大限度地提高并行性以充分利用帶寬。
4. I/O對齊
在所有日志和數(shù)據(jù)I/O請求排入隊列前,對其的大小和起始offset進行對齊。對于WAL寫入路徑,類似于PolarDB的log I/O對齊。對于數(shù)據(jù)寫入路徑,在采用數(shù)據(jù)壓縮時,LSM樹結構可能會有大量未對齊的數(shù)據(jù)塊。例如要刷寫從1 KB開始的2 KB日志數(shù)據(jù)時,它將從內(nèi)存緩存的數(shù)據(jù)中填充前1 KB(對于append-only結構通過保存尾部數(shù)據(jù)緩存實現(xiàn),這是與update-in-place結構直接拓展原生頁至最小單位的不同之處),并在3-4 KB中附加零,然后從0 KB起始發(fā)送一個4 KB的I/O。
總結
在這項論文工作中,我們分析了云存儲的性能特征,將它們與本地SSD存儲進行了比較,總結了它們對B-tree和LSM-tree類數(shù)據(jù)庫存儲引擎設計的影響,并推導出了一個框架CloudJump來指導本地存儲引擎遷移到云存儲的適配和優(yōu)化。并通過PolarDB, RocksDB 兩個具體Case 展示優(yōu)化帶來的收益。
審核編輯 :李倩
-
數(shù)據(jù)庫
+關注
關注
7文章
3915瀏覽量
66031 -
云存儲
+關注
關注
7文章
777瀏覽量
46725
原文標題:過去5年,PolarDB云原生數(shù)據(jù)庫是如何進行性能優(yōu)化的?
文章出處:【微信號:inf_storage,微信公眾號:數(shù)據(jù)庫和存儲】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
PolarDB×ADB雙擎驅動 華鼎冷鏈打造冷鏈數(shù)據(jù)智能反應堆
云原生AI服務怎么樣
云數(shù)據(jù)庫是哪種數(shù)據(jù)庫類型?
云原生LLMOps平臺作用
鴻蒙原生頁面高性能解決方案上線OpenHarmony社區(qū) 助力打造高性能原生應用
艾體寶與Kubernetes原生數(shù)據(jù)平臺AppsCode達成合作
什么是云原生MLOps平臺
AI時代的數(shù)據(jù)庫技術發(fā)展論壇亮點前瞻
軟通動力榮登2024云原生企業(yè)TOP50榜單
云原生和數(shù)據(jù)庫哪個好一些?
PolarDB-MySQL引擎層的索引前綴壓縮能力的技術實現(xiàn)和效果
數(shù)據(jù)庫數(shù)據(jù)恢復—通過拼接數(shù)據(jù)庫碎片恢復SQLserver數(shù)據(jù)庫

云原生和非云原生哪個好?六大區(qū)別詳細對比
從積木式到裝配式云原生安全
基于DPU與SmartNic的云原生SDN解決方案





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論