 跨語言命名實體識別:無監督多任務多教師蒸餾模型
跨語言命名實體識別:無監督多任務多教師蒸餾模型
前言 這是一篇來自于 ACL 2022 的關于跨語言的 NER 蒸餾模型。主要的過程還是兩大塊:1)Teacher Model 的訓練;2)從 Teacher Model 蒸餾到 Student Model。采用了類似傳統的 Soft 蒸餾方式,其中利用了多任務的方式對 Teacher Model 進行訓練,一個任務是 NER 訓練的任務,另一個是計算句對的相似性任務。整體思路還是采用了序列標注的方法,也是一個不錯的 IDEA。

論文標題:
An Unsupervised Multiple-Task and Multiple-Teacher Model for Cross-lingual Named Entity Recognition
論文鏈接:
https://aclanthology.org/2022.acl-long.14.pdf
模型架構
2.1 Teacher Model
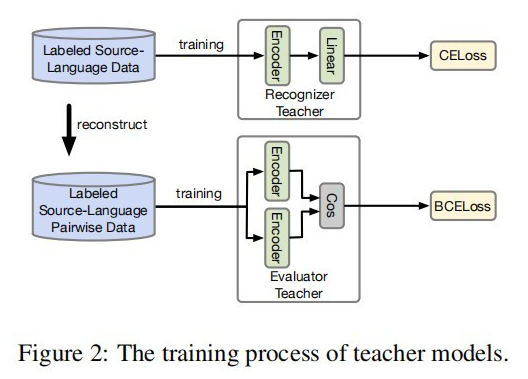
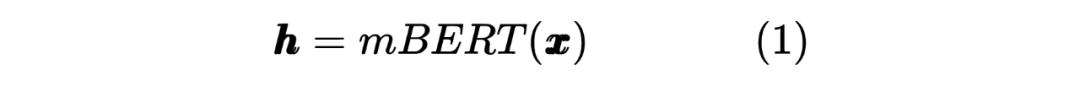
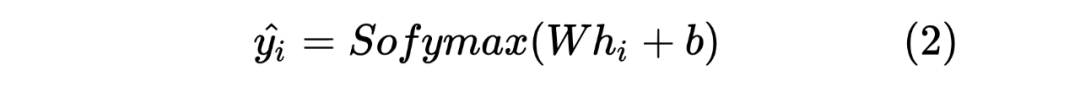
以上就是 Teacher Model 的第一個任務,直接對標注序列進行 NER,并且采用交叉熵損失函數作為 loss_function,計算如下:
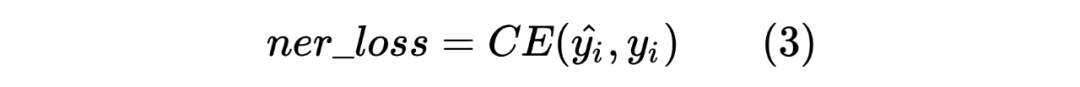
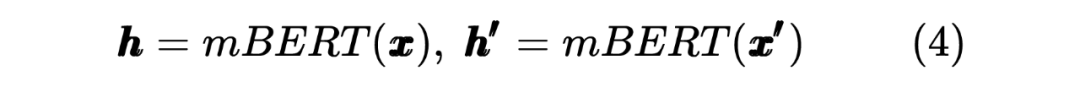
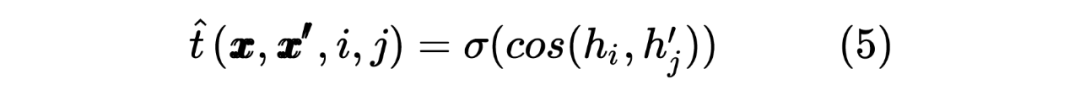
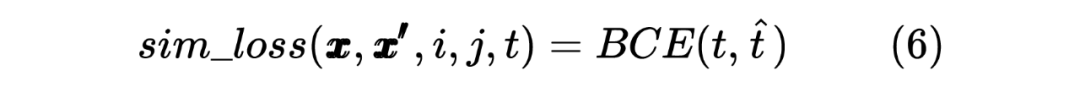
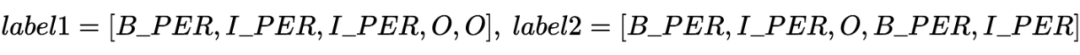
2.2 Student Model Distilled
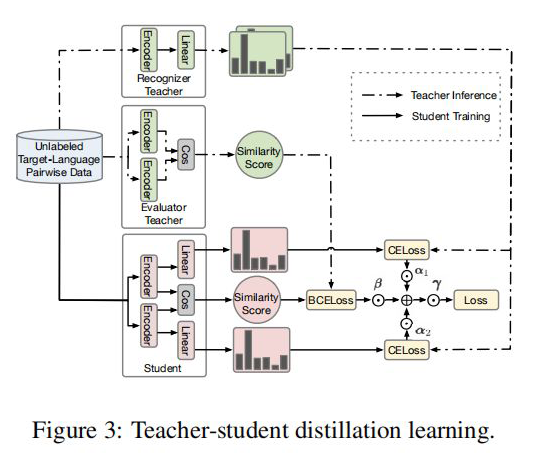
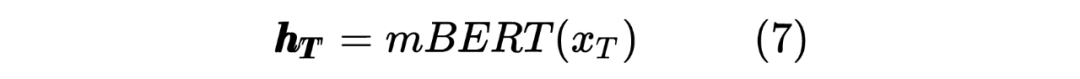
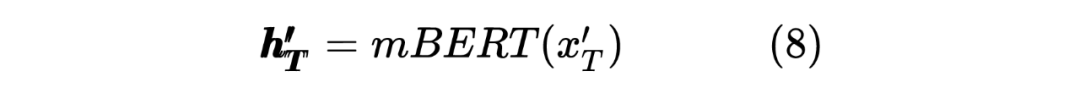
獲得兩個序列的hidden_state后進行一個線性計算,然后利用softmax進行歸一化,得到每個Token預測的標簽,計算如下:
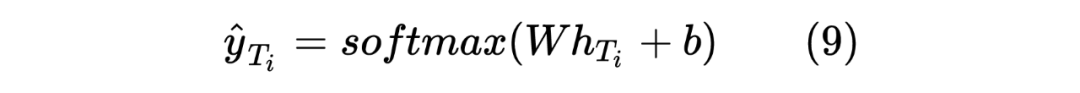
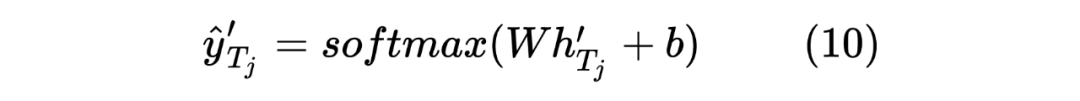
這里也類似 Teacher Model 的計算方式,計算 target 序列間的Token相似度,計算如下所示:
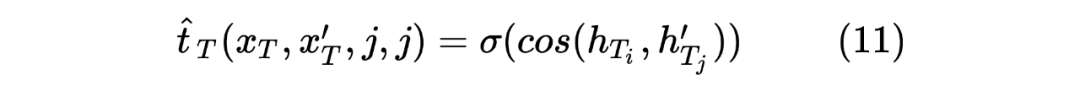
當然,這里做的是蒸餾模型,所以對于輸入到 Student Model 的序列對,也是Teacher Model Inference 預測模型的輸入,通過 Teacher Model 的預測計算得到一個 teacher_ner_logits 和 teacher_similar_logits,將 teacher_ner_logits 分別與 和 通過 CrossEntropyLoss 來計算 TS_ _Loss 和 TS_ _Loss,teacher_similar_logits 與 通過 計算 Similar_Loss,最終將幾個 loss 進行相加作為 DistilldeLoss。
這里作者還對每個 TS_ _Loss,TS_ _Loss 分別賦予了權重 ,對 Similar_Loss 賦予了權重 ,對最終的 DistilldeLoss 賦予權重 ,這樣的權重賦予能夠使得 Student Model 從 Teacher Model 學習到的噪聲減少。最終的 Loss 計算如下所示:
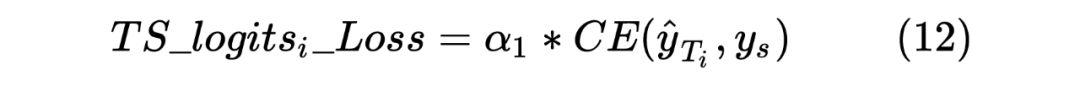
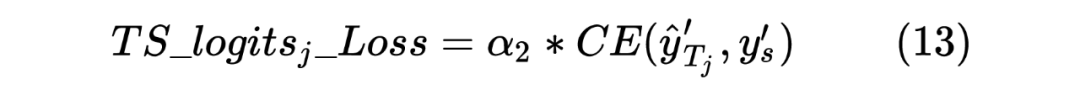
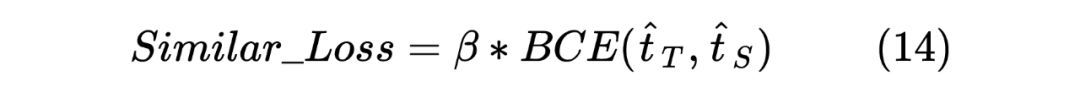
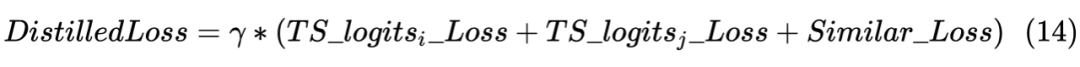
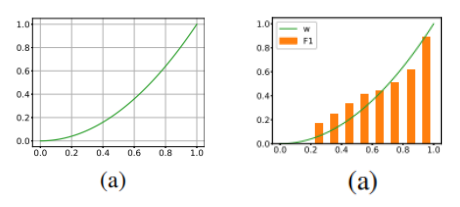
這里的權重 筆者認為是用來控制 Student Model 學習傾向的參數,首先對于 來說,由于 Student Model 輸入的是 Unlabeled 數據,所以在進行蒸餾學習時,需要盡可能使得 Student Model 的輸出的 student_ner_logits 來對齊 Teacher Model 預測輸出的 teacher_ner_logits,由于不知道輸入的無標簽數據的數據分布,所以設置一個權重參數來對整個 Teacher Model 的預測標簽進行加權,將各個無標簽的輸入序列看作一個數據量較少的類別。這里可以參考 在進行數據標簽不平衡時使用權重系數對各個標簽進行加權的操作。而且作者也分析了, 參數是一個隨著 Teacher Model 輸出而遞增的一個參數。如下圖所示:
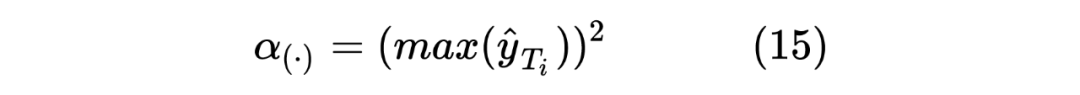
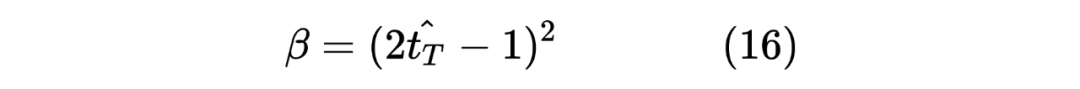
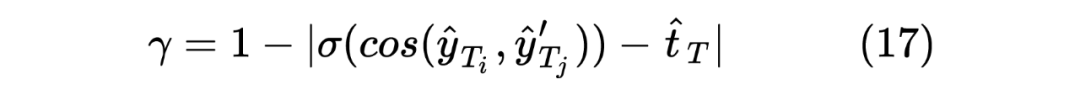
實驗結果
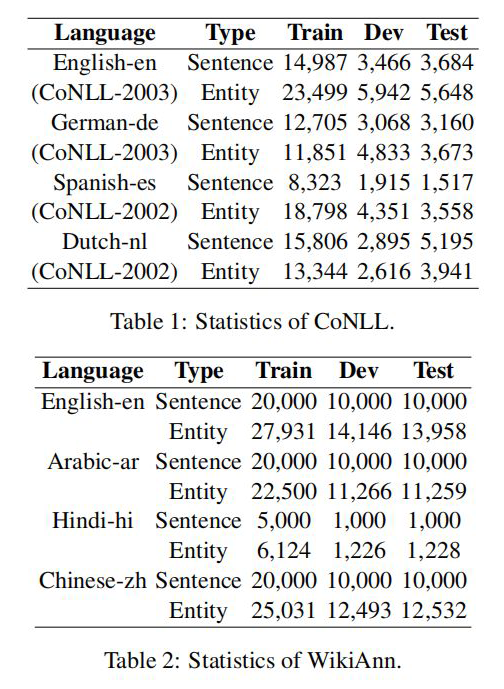
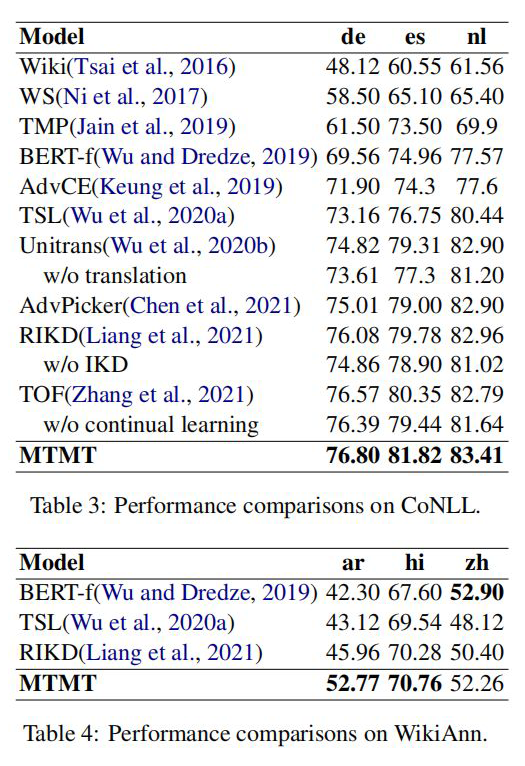
作者分別在 CoNLL 和 WiKiAnn 數據集上進行了實驗,數據使用量如下圖所示:
簡單代碼實現
#!/usr/bin/envpython
#-*-coding:utf-8-*-
#@Time:2022/5/3013:59
#@Author:SinGaln
"""
AnUnsupervisedMultiple-TaskandMultiple-TeacherModelforCross-lingualNamedEntityRecognition
"""
importtorch
importtorch.nnasnn
importtorch.nn.functionalasF
fromtransformersimportBertModel,BertPreTrainedModel,logging
logging.set_verbosity_error()
classTeacherNER(BertPreTrainedModel):
def__init__(self,config,num_labels):
"""
teacher模型是在標簽數據上訓練得到的,
主要分為三個encoder.
:paramconfig:
:paramnum_labels:
"""
super(TeacherNER,self).__init__(config)
self.config=config
self.num_labels=num_labels
self.mbert=BertModel(config=config)
self.fc=nn.Linear(config.hidden_size,num_labels)
defforward(self,batch_token_input_ids,batch_attention_mask,batch_token_type_ids,batch_labels,training=True,
batch_pair_input_ids=None,batch_pair_attention_mask=None,batch_pair_token_type_ids=None,
batch_t=None):
"""
:parambatch_token_input_ids:單句子token序列
:parambatch_attention_mask:單句子attention_mask
:parambatch_token_type_ids:單句子token_type_ids
:parambatch_pair_input_ids:句對token序列
:parambatch_pair_attention_mask:句對attention_mask
:parambatch_pair_token_type_ids:句對token_type_ids
"""
#RecognizerTeacher
single_output=self.mbert(input_ids=batch_token_input_ids,attention_mask=batch_attention_mask,
token_type_ids=batch_token_type_ids).last_hidden_state
single_output=F.softmax(self.fc(single_output),dim=-1)
#EvaluatorTeacher(類似雙塔模型)
pair_output1=self.mbert(input_ids=batch_pair_input_ids[0],attention_mask=batch_pair_attention_mask[0],
token_type_ids=batch_pair_token_type_ids[0]).last_hidden_state
pair_output2=self.mbert(input_ids=batch_pair_input_ids[1],attention_mask=batch_pair_attention_mask[1],
token_type_ids=batch_pair_token_type_ids[1]).last_hidden_state
pair_output=torch.sigmoid(torch.cosine_similarity(pair_output1,pair_output2,dim=-1))#計算兩個輸出的cosine相似度
iftraining:
#計算loss,訓練時采用平均loss作為模型最終的loss
loss1=F.cross_entropy(single_output.view(-1,self.num_labels),batch_labels.view(-1))
loss2=F.binary_cross_entropy(pair_output,batch_t.type(torch.float))
loss=loss1+loss2
returnsingle_output,loss
else:
returnsingle_output,pair_output
classStudentNER(BertPreTrainedModel):
def__init__(self,config,num_labels):
"""
student模型采用的也是一個雙塔結構
:paramconfig:mBert的配置文件
:paramnum_labels:標簽數量
"""
super(StudentNER,self).__init__(config)
self.config=config
self.num_labels=num_labels
self.mbert=BertModel(config=config)
self.fc1=nn.Linear(config.hidden_size,num_labels)
self.fc2=nn.Linear(config.hidden_size,num_labels)
defforward(self,batch_pair_input_ids,batch_pair_attention_mask,batch_pair_token_type_ids,batch_pair_labels,
teacher_logits,teacher_similar):
"""
:parambatch_pair_input_ids:句對token序列
:parambatch_pair_attention_mask:句對attention_mask
:parambatch_pair_token_type_ids:句對token_type_ids
"""
output1=self.mbert(input_ids=batch_pair_input_ids[0],attention_mask=batch_pair_attention_mask[0],
token_type_ids=batch_pair_token_type_ids[0]).last_hidden_state
output2=self.mbert(input_ids=batch_pair_input_ids[1],attention_mask=batch_pair_attention_mask[1],
token_type_ids=batch_pair_token_type_ids[1]).last_hidden_state
soft_output1,soft_output2=self.fc1(output1),self.fc2(output2)
soft_logits1,soft_logits2=F.softmax(soft_output1,dim=-1),F.softmax(soft_output2,dim=-1)
alpha1,alpha2=torch.square(torch.max(input=soft_logits1,dim=-1)[0]).mean(),torch.square(
torch.max(soft_logits2,dim=-1)[0]).mean()
output_similar=torch.sigmoid(torch.cosine_similarity(soft_output1,soft_output2,dim=-1))
soft_similar=torch.sigmoid(torch.cosine_similarity(soft_logits1,soft_logits2,dim=-1))
beta=torch.square(2*output_similar-1).mean()
gamma=1-torch.abs(soft_similar-output_similar).mean()
#計算蒸餾的loss
#teacherlogits與studentlogits1的loss
loss1=alpha1*(F.cross_entropy(soft_logits1,teacher_logits))
#teachersimilar與studentsimilar的loss
loss2=beta*(F.binary_cross_entropy(soft_similar,teacher_similar))
#teacherlogits與studentlogits2的loss
loss3=alpha2*(F.cross_entropy(soft_logits2,teacher_logits))
#finalloss
loss=gamma*(loss1+loss2+loss3).mean()
returnloss
if__name__=="__main__":
fromtransformersimportBertConfig
pretarin_path="./pytorch_mbert_model"
batch_pair1_input_ids=torch.randint(1,100,(2,128))
batch_pair1_attention_mask=torch.ones_like(batch_pair1_input_ids)
batch_pair1_token_type_ids=torch.zeros_like(batch_pair1_input_ids)
batch_labels1=torch.randint(1,10,(2,128))
batch_labels2=torch.randint(1,10,(2,128))
#t(對比兩個序列標簽,相同為1,不同為0)
batch_t=torch.as_tensor(batch_labels1.numpy()==batch_labels2.numpy()).float()
batch_pair2_input_ids=torch.randint(1,100,(2,128))
batch_pair2_attention_mask=torch.ones_like(batch_pair2_input_ids)
batch_pair2_token_type_ids=torch.zeros_like(batch_pair2_input_ids)
batch_all_input_ids,batch_all_attention_mask,batch_all_token_type_ids,batch_all_labels=[],[],[],[]
batch_all_labels.append(batch_labels1)
batch_all_labels.append(batch_labels2)
batch_all_input_ids.append(batch_pair1_input_ids)
batch_all_input_ids.append(batch_pair2_input_ids)
batch_all_attention_mask.append(batch_pair1_attention_mask)
batch_all_attention_mask.append(batch_pair2_attention_mask)
batch_all_token_type_ids.append(batch_pair1_token_type_ids)
batch_all_token_type_ids.append(batch_pair2_token_type_ids)
config=BertConfig.from_pretrained(pretarin_path)
#teacher模型訓練
teacher_model=TeacherNER.from_pretrained(pretarin_path,config=config,num_labels=10)
outputs,loss=teacher_model(batch_token_input_ids=batch_pair1_input_ids,
batch_attention_mask=batch_pair1_attention_mask,
batch_token_type_ids=batch_pair1_token_type_ids,batch_labels=batch_labels1,
batch_pair_input_ids=batch_all_input_ids,
batch_pair_attention_mask=batch_all_attention_mask,
batch_pair_token_type_ids=batch_all_token_type_ids,
training=True,batch_t=batch_t)
#student模型蒸餾
teacher_logits,teacher_similar=teacher_model(batch_token_input_ids=batch_pair1_input_ids,
batch_attention_mask=batch_pair1_attention_mask,
batch_token_type_ids=batch_pair1_token_type_ids,
batch_labels=batch_labels1,
batch_pair_input_ids=batch_all_input_ids,
batch_pair_attention_mask=batch_all_attention_mask,
batch_pair_token_type_ids=batch_all_token_type_ids,
training=False)
student_model=StudentNER.from_pretrained(pretarin_path,config=config,num_labels=10)
loss_all=student_model(batch_pair_input_ids=batch_all_input_ids,
batch_pair_attention_mask=batch_all_attention_mask,
batch_pair_token_type_ids=batch_all_token_type_ids,
batch_pair_labels=batch_all_labels,teacher_logits=teacher_logits,
teacher_similar=teacher_similar)
print(loss_all)
筆者自己實現的一部分代碼,可能不是原論文作者想表達的意思,讀者有疑問的話可以一起討論一下^~^。
審核編輯 :李倩
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
編碼器
+關注
關注
45文章
3785瀏覽量
137512 -
模型
+關注
關注
1文章
3501瀏覽量
50161 -
標簽
+關注
關注
0文章
146瀏覽量
18207
原文標題:ACL2022 | 跨語言命名實體識別:無監督多任務多教師蒸餾模型
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
熱點推薦
自然語言基礎技術之命名實體識別相對全面的介紹
早期的命名實體識別方法基本都是基于規則的。之后由于基于大規模的語料庫的統計方法在自然語言處理各個方面取得不錯的效果之后,一大批機器學習的方法也出現在命名實體類
HanLP分詞命名實體提取詳解
可能詞) 5.極速詞典分詞(速度快,精度一般) 6.用戶自定義詞典 7.標準分詞(HMM-Viterbi) 命名實體識別 1.實體機構名識別(層疊HMM-Viterbi) 2.中國人名
發表于 01-11 14:32
基于結構化感知機的詞性標注與命名實體識別框架
`上周就關于《結構化感知機標注框架的內容》已經分享了一篇《分詞工具Hanlp基于感知機的中文分詞框架》,本篇接上一篇內容,繼續分享詞性標注與命名實體識別框架的內容。詞性標注訓練詞性標注是分詞后緊接著
發表于 04-08 14:57
基于神經網絡結構在命名實體識別中應用的分析與總結
近年來,基于神經網絡的深度學習方法在自然語言處理領域已經取得了不少進展。作為NLP領域的基礎任務—命名實體識別(Named Entity Recognition,NER)也不例外,神經

深度學習:四種利用少量標注數據進行命名實體識別的方法
整理介紹四種利用少量標注數據進行命名實體識別的方法。 面向少量標注數據的NER方法分類 基于規則、統計機器學習和深度學習的方法在通用語料上能取得良好的效果,但在特定領域、小語種等缺乏標注資源的情況下,NER 任務往往得
思必馳中文命名實體識別任務助力AI落地應用
驗階段走向實用化。近期,思必馳語言與知識團隊對中文細粒度命名實體識別任務進行探索,并取得階段性進展:在CLUE數據集Fine-Grain NER評測
新型中文旅游文本命名實體識別設計方案
傳統基于詞向量表示的命名實體識別方法通常忽略了字符語義信息、字符間的位置信息,以及字符和單詞的關聯關系。提出一種基于單詞字符引導注意力網絡( WCGAN)的中文旅游命名實體識別方法,利
發表于 03-11 11:26
?24次下載

知識圖譜與訓練模型相結合和命名實體識別的研究工作
本次將分享ICLR2021中的三篇投遞文章,涉及知識圖譜與訓練模型相結合和命名實體識別(NER)的研究工作。 文章概覽 知識圖譜和語言理解的聯合預訓練(JAKET: Joint
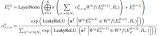

基于字語言模型的中文命名實體識別系統
造成的數據稀缺問題,以及傳統字向量不能解決的一字多義問題,文中使用在大規模無監督數據上預訓練的基于上下文相關的字向量,即利用語言模型生成上下文相關字向量以改進中文NER
發表于 04-08 14:36
?14次下載

基于神經網絡的中文命名實體識別方法
在基于神經網絡的中文命名實體識別過程中,字的向量化表示是重要步驟,而傳統的詞向量表示方法只是將字映射為單一向量,無法表征字的多義性。針對該問題,通過嵌入BERT預訓練語言模型,構建BE
發表于 06-03 11:30
?3次下載
關于邊界檢測增強的中文命名實體識別
引言 命名實體識別(Named Entity Recognition,NER)是自然語言處理領域的一個基礎任務,是信息抽取等許多任務的子





 工商網監
工商網監
評論