") Batch大小不一定是2的n次冪?
Batch大小不一定是2的n次冪?
Batch大小不一定是2的n次冪?
是否選擇2的n次冪在運(yùn)行速度上竟然也相差無(wú)幾?
有沒(méi)有感覺(jué)常識(shí)被顛覆?
這是威斯康星大學(xué)麥迪遜分校助理教授Sebastian Raschka(以下簡(jiǎn)稱R教授)的最新結(jié)論。

在神經(jīng)網(wǎng)絡(luò)訓(xùn)練中,2的n次冪作為Batch大小已經(jīng)成為一個(gè)標(biāo)準(zhǔn)慣例,即64、128、256、512、1024等。
一直有種說(shuō)法,是這樣有助于提高訓(xùn)練效率。
但R教授做了一番研究之后,發(fā)現(xiàn)并非如此。
在介紹他的試驗(yàn)方法之前,首先來(lái)回顧一下這個(gè)慣例究竟是怎么來(lái)的?
2的n次冪從何而來(lái)?
一個(gè)可能的答案是:因?yàn)?a href="http://www.tjjbhg.com/v/tag/132/" target="_blank">CPU和GPU的內(nèi)存架構(gòu)都是由2的n次冪構(gòu)成的。
或者更準(zhǔn)確地說(shuō),根據(jù)內(nèi)存對(duì)齊規(guī)則,cpu在讀取內(nèi)存時(shí)是一塊一塊進(jìn)行讀取的,塊的大小可以是2,4,8,16(總之是2的倍數(shù))。
因此,選取2的n次冪作為batch大小,主要是為了將一個(gè)或多個(gè)批次整齊地安裝在一個(gè)頁(yè)面上,以幫助GPU并行處理。
其次,矩陣乘法和GPU計(jì)算效率之間也存在一定的聯(lián)系。

假設(shè)我們?cè)诰仃囍g有以下矩陣乘法A和B:
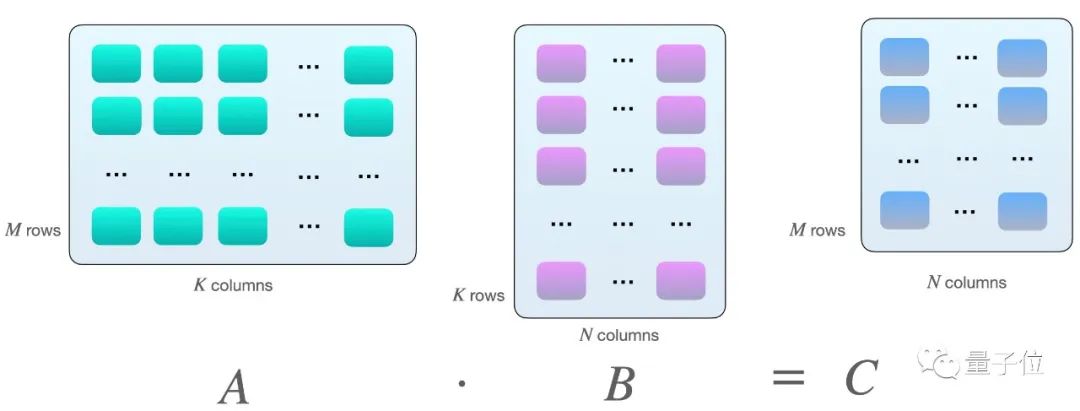
當(dāng)A的行數(shù)等于B的列數(shù)的時(shí)候,兩個(gè)矩陣才能相乘。
其實(shí)就是矩陣A的第一行每個(gè)元素分別與B的第一列相乘再求和,得到C矩陣的第一個(gè)數(shù),然后A矩陣的第一行再與B矩陣的第二列相乘,得到第二個(gè)數(shù),然后是A矩陣的第二行與B矩陣的第一列……
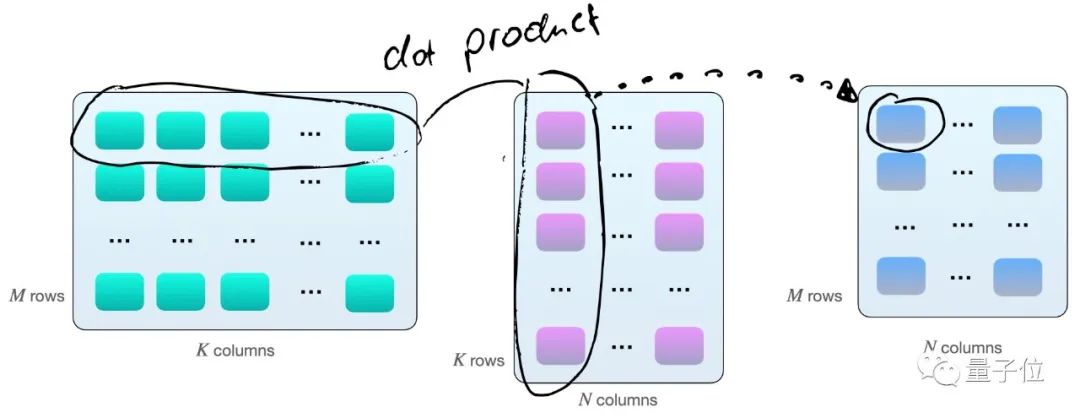
因此,如上圖所示,我們擁有2×M×N×K個(gè)每秒浮點(diǎn)運(yùn)算次數(shù)(FLOPS)。
現(xiàn)在,如果我們使用帶有Tensor Cores的GPU,例如V100時(shí),當(dāng)矩陣尺寸(M,N以及K)與16字節(jié)的倍數(shù)對(duì)齊,在FP16混合精度訓(xùn)練中,8的倍數(shù)的運(yùn)算效率最為理想。
因此,假設(shè)在理論上,batch大小為8倍數(shù)時(shí),對(duì)于具有Tensor Cores和FP16混合精度訓(xùn)練的GPU最有效,那么讓我們調(diào)查一下這一說(shuō)法在實(shí)踐中是否也成立。
不用2的n次冪也不影響速度
為了了解不同的batch數(shù)值對(duì)訓(xùn)練速度的影響,R教授在CIFAR-10上運(yùn)行了一個(gè)簡(jiǎn)單的基準(zhǔn)測(cè)試訓(xùn)練——MobileNetV3(大)——圖像的大小為224×224,以便達(dá)到適當(dāng)?shù)腉PU利用率。
R教授用16位自動(dòng)混合精度訓(xùn)練在V100卡上運(yùn)行訓(xùn)練,該訓(xùn)練能更高效地使用GPU的Tensor Cores。
如果你想自己運(yùn)行,該代碼可在此GitHub存儲(chǔ)庫(kù)中找到(鏈接附在文末)。
該測(cè)試共分為以下三部分:
小批量訓(xùn)練
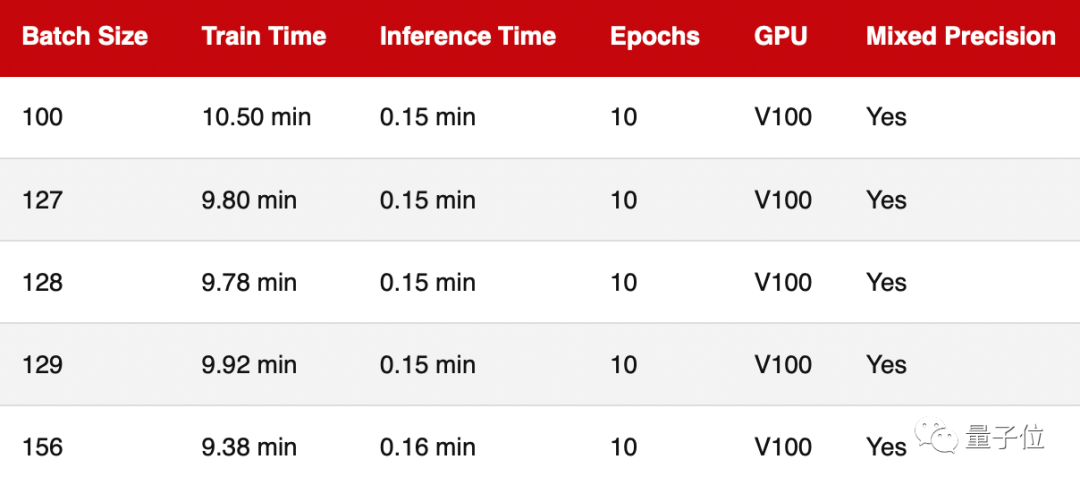
從上圖可以看出,以樣本數(shù)量128為參考點(diǎn),將樣本數(shù)量減少1(127)或增加1(129),的確會(huì)導(dǎo)致訓(xùn)練速度略慢,但這種差異幾乎可以忽略不計(jì)。
而將樣本數(shù)量減少28(100)會(huì)導(dǎo)致訓(xùn)練速度明顯放緩,這可能是因?yàn)槟P同F(xiàn)在需要處理的批次比以前更多(50,000/100=500與50,000/128= 390)。
同樣的原理,當(dāng)我們將樣本數(shù)量增加28(156)時(shí),運(yùn)行速度明顯變快了。
最大批量訓(xùn)練
鑒于MobileNetV3架構(gòu)和輸入映像大小,上一輪中樣本數(shù)量相對(duì)較小,因此GPU利用率約為70%。
為了調(diào)查GPU滿載時(shí)的訓(xùn)練速度,本輪把樣本數(shù)量增加到512,使GPU的計(jì)算利用率接近100%。
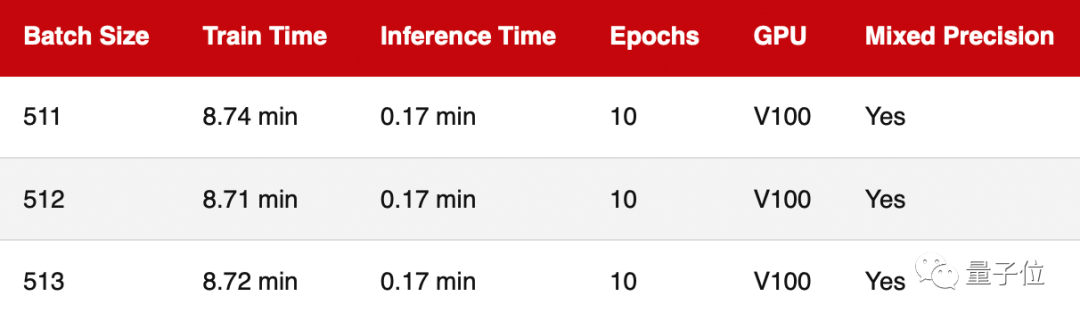
△由于GPU內(nèi)存限制,無(wú)法使用大于515的樣本數(shù)量
可以看出,跟上一輪結(jié)果一樣,不管樣本數(shù)量是否是2的n次冪,訓(xùn)練速度的差異幾乎可以忽略不計(jì)。
多GPU訓(xùn)練
基于前兩輪測(cè)試評(píng)估的都是單個(gè)GPU的訓(xùn)練性能,而如今多個(gè)GPU上的深度神經(jīng)網(wǎng)絡(luò)訓(xùn)練更常見(jiàn)。為此,這輪進(jìn)行的是多GPU培訓(xùn)。
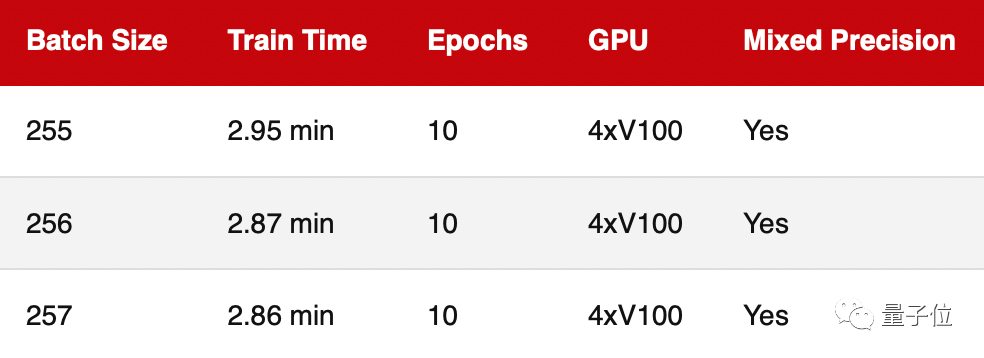
正如我們看到的,2的n次冪(256)的運(yùn)行速度并不比255差太多。
測(cè)試注意事項(xiàng)
在上述3個(gè)基準(zhǔn)測(cè)試中,需要特別聲明的是:
所有基準(zhǔn)測(cè)試的每個(gè)設(shè)置都只運(yùn)行過(guò)一次,理想情況下當(dāng)然是重復(fù)運(yùn)行次數(shù)越多越好,最好還能生成平均和標(biāo)準(zhǔn)偏差,但這并不會(huì)影響到上述結(jié)論。
此外,雖然R教授是在同一臺(tái)機(jī)器上運(yùn)行的所有基準(zhǔn)測(cè)試,但兩次運(yùn)營(yíng)之間沒(méi)有特意相隔很長(zhǎng)時(shí)間,因此,這可能意味著前后兩次運(yùn)行之間的GPU基本溫度可能不同,并可能稍微影響到運(yùn)算時(shí)間。
結(jié)論
可以看出,選擇2的n次冪或8的倍數(shù)作為batch大小在實(shí)踐中不會(huì)產(chǎn)生明顯差異。
然而,由于在實(shí)際使用中已成為約定俗成,選擇2的n次冪作為batch大小,的確可以幫助運(yùn)算更簡(jiǎn)單并且易于管理。
此外,如果你有興趣發(fā)表學(xué)術(shù)研究論文,選擇2的n次冪將使你的論文看上去不那么主觀。
盡管如此,R教授仍然認(rèn)為,batch的最佳大小在很大程度上取決于神經(jīng)網(wǎng)絡(luò)架構(gòu)和損失函數(shù)。
例如,在最近使用相同ResNet架構(gòu)的研究項(xiàng)目中,他發(fā)現(xiàn)batch的最佳大小可以在16到256之間,具體取決于損失函數(shù)。
因此,R教授建議始終把調(diào)整batch大小,作為超參數(shù)優(yōu)化的一部分。
但是,如果你由于內(nèi)存限制而無(wú)法使用512作為batch大小,那么則不必降到256,首先考慮500即可。
作者Sebastian Raschka
Sebastian Raschka,是一名機(jī)器學(xué)習(xí)和 AI 研究員。
他在UW-Madison(威斯康星大學(xué)麥迪遜分校)擔(dān)任統(tǒng)計(jì)學(xué)助理教授,專注于深度學(xué)習(xí)和機(jī)器學(xué)習(xí)研究,同時(shí)也是Lightning AI的首席 AI 教育家。
另外他還寫(xiě)過(guò)一系列用Python和Scikit-learn做機(jī)器學(xué)習(xí)的教材。

基準(zhǔn)測(cè)試代碼鏈接:
https://github.com/rasbt/b3-basic-batchsize-benchmark
參考鏈接:
https://sebastianraschka.com/blog/2022/batch-size-2.html
審核編輯 :李倩
-
矩陣
+關(guān)注
關(guān)注
1文章
434瀏覽量
35098 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8497瀏覽量
134249
原文標(biāo)題:Batch大小不一定是2的n次冪!ML資深學(xué)者最新結(jié)論
文章出處:【微信號(hào):CVer,微信公眾號(hào):CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
Denebola RDK上配置的幀大小與實(shí)際幀大小不一致是怎么回事?
求助,CY3014中CyU3PDmaChannelSetWrapUp函數(shù)的使用以及其他問(wèn)題求解
cyusb3014 slave fifo模式In和Out緩存大小不一樣時(shí),顯示錯(cuò)誤怎么解決?
DLP4500需要使用近紅外光源,如何判斷這個(gè)芯片是否適用?
DLPC3478使用External Pattern Mode如何解決并行口第N次輸入的數(shù)據(jù)將在N+1次時(shí)輸出造成的第1次輸出圖像不能指定的問(wèn)題?
TLK2201的數(shù)據(jù)端口對(duì)應(yīng)不齊是怎么回事?
一文看懂ADC轉(zhuǎn)換過(guò)程





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論