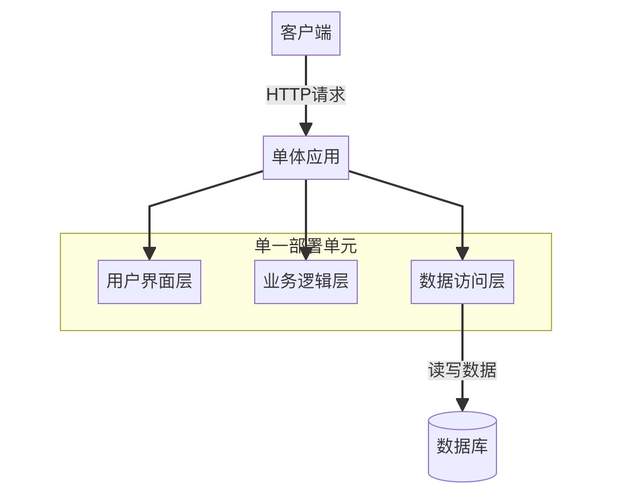
 您需要模塊,而不是微服務
您需要模塊,而不是微服務

架構有時很難——人們不斷提出一些新想法,這些想法很快成為主流的“做事方式”,微服務是最新的趨勢,現在是我們剖析這個想法并找到正在發生的事情的真正根源的時候了。
在微服務 的核心,我們被告知我們會發現…… ...
很多好東西 (TM)!
- “可擴展性”:“代碼可以分解成更小的部分,可以獨立開發、測試、部署和更新。”
- “Focus”:“……開發人員專注于解決業務問題和業務邏輯。”
- “可用性”:“后端數據必須始終可用于各種設備……”
- “簡單性”:“提供了大型企業級應用程序的簡化開發。”
- “響應能力”:“......使分布式應用程序能夠擴展是對不斷變化的事務負載的響應......”
- “可靠性”:“通過提供可在發生故障時繼續運行的復制服務器組來確保沒有單點故障。在發生故障后將正在運行的應用程序恢復到良好狀態。”
這些聽起來都比較熟悉,我想,但是關于這六個引用的有趣部分是兩個來自微服務文獻(博客文章、論文等),兩個來自 20 年前的 EJB 文獻,兩個來自 Oracle,這是四十多年前的技術。在這個行業中,我們傾向于一遍又一遍地重復使用我們的炒作點。
關于微服務炒作,一家公司的博客文章[1]提供了10 個采用微服務的理由:
- 他們推廣大數據最佳實踐。微服務自然適合面向數據管道的架構,該架構符合大數據的收集、攝取、處理和交付方式。數據管道中的每個步驟都以微服務的形式處理一個小任務。
- 它們相對容易構建和維護。它們的單一用途設計意味著它們可以由較小的團隊構建和維護。每個團隊都可以是跨職能的,同時也可以專注于解決方案中的微服務子集。
- 它們支持更高質量的代碼。將整體解決方案模塊化為離散組件有助于應用程序開發團隊一次專注于一小部分。這簡化了整個編碼和測試過程。
- 它們簡化了跨團隊的協調。與通常涉及重量級進程間通信協議的傳統面向服務架構 (SOA) 不同,微服務使用事件流技術來實現更輕松的集成。
- 它們支持實時處理。微服務架構的核心是發布-訂閱框架,支持實時數據處理以提供即時輸出和洞察。
- 它們促進快速增長。微服務使代碼和數據重用模塊化架構,更容易部署更多數據驅動的用例和解決方案以增加業務價值。
- 它們可以實現更多輸出。數據集通常以不同的方式呈現給不同的受眾;微服務簡化了為各種最終用戶提取數據的方式。
- 更容易評估應用程序生命周期中的更新。高級分析環境,包括那些用于機器學習的分析環境,需要一些方法來根據新創建的模型評估現有的計算模型。微服務架構中的 AB 和多變量測試使用戶能夠驗證他們更新的模型。
- 它們使規模成為可能。可伸縮性不僅僅是處理更多容量的能力。這也與所涉及的努力有關。微服務可以更輕松地識別擴展瓶頸,然后在每個微服務級別解決這些瓶頸。
- 許多流行的工具都可用。大數據世界中的各種技術(包括開源社區)在微服務架構中運行良好。Apache Hadoop、Apache Spark、NoSQL 數據庫和許多流分析工具可用于微服務。
讓我們花點時間檢查一下其中的每一個,但這次是根據現有技術:
-
他們推廣大數據最佳實踐。自 70 年代以來,管道和過濾器架構[2]一直是軟件領域的一部分,當時Unixes 提出了幾個想法[3]:
- 讓每個程序做好一件事。要完成一項新工作,請重新構建而不是通過添加新“功能”使舊程序復雜化。
- 期望每個程序的輸出成為另一個未知程序的輸入。不要用無關信息混淆輸出。嚴格避免列式或二進制輸入格式。不要堅持交互式輸入。
-
它們相對容易構建和維護。請參閱上面的 Unix 哲學。
-
它們支持更高質量的代碼。如果一次專注于一小部分有助于提高質量,那么請參閱上面的 Unix 哲學。
-
它們簡化了跨團隊的協調。這個很有趣;它表明“面向服務的體系結構(SOA)……通常涉及重量級進程間通信協議”——比如 JSON over HTTP?或者這是否意味著所有 SOA 都需要 SOAP、WSDL、XML Schema 和 WS-* 規范的完整集合?具有諷刺意味的是,微服務并沒有以任何方式阻止它使用任何這些“重量級”協議,并且一些微服務甚至建議使用 gRPC,這是一種與 IIOP 更相似的二進制協議,來自 CORBA,它是“重量級”協議”的前身...... SOAP、WSDL、XML Schema 和 WS-* 規范的完整集合。
-
它們支持實時處理。實時處理實際上已經存在了很長一段時間,雖然許多此類系統使用發布-訂閱或“事件總線”模型來完成它,但它幾乎不需要微服務來完成。
-
它們促進快速增長。“復用模塊化架構”——我們算過有多少不同的東西都以“復用”為賣點?語言當然已經做到了(OOP、功能語言、過程語言)、庫、框架……有一天我想看到一些大肆宣傳的東西,明確地說“能否重用?我們不關心。”
-
它們可以實現更多輸出。“數據集通常以不同的方式呈現給不同的受眾”——這聽起來很像Crystal Reports[4]的主頁。
-
更容易評估應用程序生命周期中的更新。機器學習和高級分析環境需要“根據新創建的模型評估現有的計算模型”……聽起來像是一大堆動作詞,但背后幾乎沒有實質內容。
-
它們使規模成為可能。多么有趣——EJB、事務性中間件處理(類似 Tuxedo)和大型機也是如此。
-
許多流行的工具都可用。我不認為我必須非常努力地指出工具總是可以用于我們行業的每一次重大炒作——尤其是在炒作扎根一段時間之后。大多數讀者的年齡甚至不足以記住CASE 工具[5],但也許他們會記住UML。
但眼光敏銳的讀者會注意到,上面大約一半的觀點有一個非常共同的主題——創建和維護小的、獨立的代碼和數據“塊”的想法,彼此版本化,使用共同的輸入和輸出以實現更大的系統集成。就好像……
在微服務的核心,我們發現…… ...
模塊!
是的,低級的“模塊”,這個核心概念自 1970 年代以來一直是大多數編程語言的核心。(甚至更早,盡管使用未將模塊作為一流核心概念的舊語言更難處理。)在 CLR(C#、F#、Visual Basic 等)中稱它們為“程序集”, JVM(Java、Kotlin、Clojure、Scala、Groovy 等)上的“JAR”或“包”,或來自您最喜歡的操作系統的動態鏈接庫(Windows 上的 DLL, *nixes 上so的 s 或as,以及當然 macOS 將“框架”隱藏在 /Library 目錄中),但在概念層面上,它們都是模塊。每個都有不同的內部格式,但每個都有相同的基本目的:一個獨立構建、管理、版本化、
考慮模塊的這個工作定義,引用自計算機科學的一篇基礎論文:
“項目工作的明確定義的細分確保了系統模塊化。每個任務形成一個單獨的、不同的程序模塊。在實施時每個模塊及其輸入和輸出都是明確定義的,與其他系統的預期接口沒有混淆模塊。在結帳時獨立測試模塊的完整性;在結帳開始之前同步完成多個任務幾乎沒有調度問題。最后,系統以模塊化方式維護;系統錯誤和缺陷可以追溯到特定的系統模塊,從而限制了詳細錯誤搜索的范圍。”
這來自 David Parnas 的開創性論文“On the Criteria To Be Used in Decomposing Systems into Modules”[6],該論文寫于 1971 年——距撰寫本文時已有 50 多年的歷史。
定義明確的“獨立的、不同的程序模塊”涵蓋了微服務建議的大約一半好處,我們已經這樣做了 50 年。
那么為什么要炒作微服務呢?
因為微服務真的與微服務、服務甚至分布式系統無關。
在微服務的核心,我們應該找到…… ... 組織清晰度!
Amazon 是最早公開討論微服務概念的公司之一,實際上并沒有像他們試圖推動獨立開發團隊的想法那樣努力推動架構原則,其阻礙者很少。等待 DBA 團隊進行架構更改?QA 需要構建來測試以便他們可以發現錯誤?還是我們在等待基礎架構團隊采購服務器?還是 UX 團隊為演示創建原型?
SCHHHLLLUURRRRRRRPPPPpppp...
你聽到的聲音是開發團隊聚集了所有可能(并且經常會)阻止他們前進的依賴項的所有權。
- 這意味著這些團隊是普通 IT 團隊各個部分(分析、開發、設計、測試、數據管理、部署、管理等)的一個小縮影。
- 這確實意味著現在團隊要么必須由各種不同的技能集組成,要么我們必須要求每個團隊成員都具備完整的技能集(所謂的“全棧開發人員”),這意味著雇用這些人們變得更加狡猾。
- 這也意味著現在團隊要為自己的生產中斷負責,這意味著團隊本身現在必須承擔隨叫隨到的責任(以及相應的工資單和隨之而來的法律影響)。
但是,當所有這一切都被駕馭后,這意味著每個團隊都可以獨立地建造他們的藝術品,除了時間和手指在鍵盤上飛舞的速度的物理學限制外,沒有其他限制。
在微服務的核心,我們經常發現...... 分布式計算的謬誤!
對于那些不熟悉這些謬論的人來說,這些謬論是Peter Deutsch在80年代給他在Sun公司的同行們的一次演講中首次提出的。他們在1994年由Ann Wolrath和Jim Waldo撰寫的開創性論文 "A Note on Distributed Computing "中再次出現,它們基本上都說了同樣的話。"使分布式系統正確--性能、可靠性、可擴展性,無論 "正確 "意味著什么--都是困難的。"(松散的轉述)
當我們把系統分解成在單個操作系統節點上運行的內存模塊時,即使在五十年前,跨進程或庫邊界傳遞數據的成本也是可忽略的。然而,當跨越網絡線路傳遞數據時--就像大多數微服務所做的那樣--會給通信增加五到七個數量級的延遲。這不是我們可以通過在網絡上添加更多的節點來 "消除 "的,這實際上使問題變得更糟。
是的,通過將微服務托管在同一臺機器上,通常是將它們加載到運行獨立微服務的容器化鏡像的虛擬機集群中,可以使其中的一些問題變得不那么重要。(如使用Docker Compose或Kubernetes來托管Docker容器的集合)。然而,這樣做會增加虛擬機進程邊界之間的延遲(因為我們必須按照七層模型的規則,在虛擬網絡堆棧中上下移動數據,即使其中一些層被完全模擬),并且仍然會產生在單個節點上運行的可靠性問題。
更糟糕的是,即使我們開始與分布式計算的謬誤作斗爭,我們也開始遇到了一個相關的、但獨立的問題集 :The Fallacies of Enterprise[7]
在微服務的核心,我們需要......
開始重新思考我們真正需要什么!
你是否需要將問題分解成獨立的實體?你可以通過接受托管在Docker容器中的獨立進程來做到這一點,或者你可以通過接受應用服務器中服從標準化API慣例的獨立模塊來做到這一點,或者其他各種選擇。這不是一個需要放棄任何已經建立的技術問題--它可以使用過去20年中任何地方的技術,包括servlets、ASP.NET、Ruby、Python、C++,甚至可能是顫抖的Perl。關鍵是要建立一個共同的架構背板,并有公認的集成和通信慣例,無論你想或需要它是什么。
你是否需要減少你的開發團隊所面臨的依賴性?那就從研究這些依賴性開始,與合作伙伴一起確定哪些依賴性你可以帶入團隊的輪子里。如果企業不想正式打破組織結構圖中 "以技能為中心 "的本體(意味著你有一個 "數據庫 "小組、一個 "基礎設施 "小組和一個 "QA "小組作為 "開發 "小組的同行),那么與高級管理人員合作,至少允許一個 "點線 "報告結構,這樣每個小組都有個人現在被 "矩陣 "在一個團隊中了。
但是,最重要的是,確保這個團隊對他們要建立的東西有一個清晰的愿景,而且他們可以自信地對街上隨便走過的陌生人描述他們的服務/微服務/模塊的核心。
關鍵是要給團隊以方向和目標,給他們完成目標的自主權,并發出完成目標的號角。
(banq注:這篇文章忽視了軟件工程中最重要原則:組織架構決定了軟件架構,當然,最后一句話也是關于組織架構的建設,但是他沒有指出,因為有了團隊建設這些組織架構,才催生了微服務架構,這是一套人與技術組成的有機生態系統)
黑客新聞網友:
1、微服務,雖然經常被當作解決技術問題的賣點,但實際上解決的是組織擴展中的人性問題。 微服務聲稱要解決兩個技術問題:模塊化(關注點的分離、隱藏實現、文件接口和所有這些好東西)和可擴展性(能夠增加計算量、內存和IO到需要它的特定模塊)。
第一個問題,即模塊,可以在語言層面上得到解決。模塊可以做這個工作,這就是這篇博文的重點。
第二個問題,可擴展性,在那些被設計成在分布式環境中運行的語言之外的大多數語言中,很難在語言層面上解決。但是大多數人對它的需求比他們想象的要少得多。通常情況下,數據庫是你的瓶頸,如果你保持你的應用服務器無狀態,你可以只運行大量的數據庫;數據庫最終會成為一個瓶頸,但你可以大量擴展數據庫。
微服務可能有意義的真正原因是:它們使人們在模塊邊界周圍保持誠實。它們使人們:
- 更難保留對持久性內存狀態的訪問,
- 更難駕馭對象圖來依賴他們不應該依賴的東西,
- 更難在沒有關于設計變化和未來證明的對話的情況下,在模塊邊界的兩邊創建復雜變化的PR。
(banq注:以上三點保證不讓人們變成全能上帝,因為如果一個人變成上帝,他的工作產品就很難被替換,不符合模塊化思想,人就應該被困在自己的代碼上下文界限內,這就是代碼所有權,不應該凌駕于多個上下文界限變成上帝)
當組織規模擴大時,團隊的代碼所有權是你需要的,如果只是為了減少開發人員需要做的上下文切換,如果被視為完全可替換的話;擁有一個服務比擁有一個模塊更有說服力,因為團隊將擁有發布時間表和質量門檻。
我不太贊成每個微服務都維護自己的狀態副本,可能還有自己的獨立數據存儲。我認為這通常會在同步方面增加更多的持續復雜性,而不是通過隔離模式來節省。一個更好的規則是一個服務擁有一個表的寫入,而其他服務只能讀取該表,甚至可能不是所有的列或所有的非自有表。狀態同步的問題是分布式應用中最常見的故障模式之一:隊列需要備份,重試 "壞 "事件導致阻塞等等。
2、我只想指出,對于第二個問題(CPU/內存/io的可擴展性),微服務幾乎總是讓事情變得更糟。 做一個RPC必然意味著數據的序列化和反序列化,而且幾乎總是意味著通過套接字發送數據。再加上大多數服務都有一些運行RPC代碼和其他事情(健康檢查、統計數據收集等)的持續開銷,這些開銷通常被捆綁在每個服務中。即使額外的CPU/內存對你來說不是什么大問題,做RPC也會增加延遲,如果你有太多的微服務,延遲的數字會開始真正增加,而且以后很難修復。
而在單個進程中運行代碼的開銷要低得多,因為你不需要轉接網絡層,而且你通常只是在傳遞數據的指針,而不是序列化/反序列化。
在某些情況下,使用微服務確實能使事情的CPU/內存效率更高,但這比人們想象的要少得多。一個真正能提高效率的例子是像地理圍欄服務(想象一下Uber、Doordash等),地理圍欄的定義可能很大,必須存儲在內存中。根據地理圍欄查詢的頻率,讓少量的地理圍欄服務實例在內存中加載地理圍欄定義,而不是讓這個邏輯作為一個模塊被許多工作者加載,可能更有效率。但同樣,像這樣的情況比服務導致的大量臃腫要少得多。
我在Uber工作時,他們開始從單體機過渡到微服務,幾乎普遍將邏輯分割到微服務中,需要配置更多的服務器,這對端到端的延遲時間是災難性的。
(banq注:這位Uber工程師沒有理解第二個問題其實是代碼所有權問題,是和團隊組織架構有關,不是關于技術問題,技術是為獲得代碼所有權好處而付出成本費用)
3、我在亞馬遜工作時,他們開始從單體過渡到微服務,其中最大的勝利是數據和緩存的定位。 所有的目錄數據都被轉移到一個只提供目錄數據的服務中,所以它的緩存為目錄數據進行了優化,在它前面的負載均衡器可以通過一致的散列來優化這個緩存。
這與前端網絡層不同,前者使用一致的散列法將客戶定位到各個網絡服務器上。
對于像訂單歷史或客戶數據這樣的東西,這些服務坐在他們各自的數據庫前面,提供一致的散列和可用性(在當時使用的SQL數據庫前面提供一致的寫通緩存)。
我不會把這些使事情更有效率的領域稱為罕見,而是實際上很常見,它來自于讓你的數據決定你的微服務,而不是讓你的組織決定你的微服務(盡管如果團隊擁有數據,那么他們應該排隊)。
(banq注:數據架構決定微服務架構,很新穎的觀點,其實數據代碼業務,類似于DDD界限上下文決定微服務,界限上下文和組織團隊劃分,這兩個標準也是相互借用的,有的團隊依據業務領域或上下文劃分,但是對于不熟悉的業務,例如亞馬遜這種創新的電商新領域,人們很難做到戰略上提前計劃與預測,大家都是摸著石頭過河,依據數據劃分可能比較有意義)
4、微服務效率較低,但可擴展性更高。
服務器只能變得這么大。如果您的單體應用需要的資源超過單個服務器所能提供的資源,那么您可以將其拆分為微服務,每個微服務都可以獲得自己的強大服務器。然后你可以在微服務前面放一個負載均衡器,并在 N 個強大的服務器上運行它。但這只在 Facebook 規模上很重要。我認為大多數開發人員會對運行高效代碼的單個強大服務器能做的事情感到震驚。
我不同意,在我看來,微服務阻礙了部署和開發的可擴展性--至少我看到大多數企業使用它們的方式。一般來說,他們會把代碼分解到不同的存儲庫中,所以現在你必須運行70個不同的CI/CDS管道來部署70個微服務,而Repo A不知道Repo B對他們的API進行了破壞性的修改。或者lib B拉入了lib D,現在污染了lib A的類路徑,而lib A對lib B有依賴性。通常你需要大規模部署所有的微服務來解決一個關鍵漏洞(想想log4shell)。
解決這個問題的辦法是使用正確的工具,即像Bazel這樣支持單點的構建系統。Bazel很好地解決了這個問題。它只構建/測試/容器化/部署(rules_k8s, rules_docker)需要重建、重新測試、重新容器化和重新部署的東西。構建速度更快,開發人員對一個組織的所有代碼有上帝一樣的可見性(banq注:這個觀點就是把人變成上帝,違背代碼所有權,是很危險的,導致不小心的耦合依賴),可以輕松地搜索整個代碼庫,并保證他們的變化不會破壞其他模塊, 所以你可以用任何最適合它的語言來實現你的服務。它允許你更容易地管理橫向依賴關系,在整個組織的代碼庫中管理版本。
當然,Bazel的學習曲線很陡峭,所以它要像Maven、Gradle等那樣被廣泛采用還需要幾年時間。但在我工作過的銀行里,它可以為他們節省數千萬美元。
另外,git也需要趕上大型代碼庫的速度。我認為Meta最近發布了一個新的源碼控制工具,與git類似,但可以處理大型單體。
5、微服務解決了第三個技術問題,也是我最喜歡的:隔離。
使用單體,您可以向整個單體提供所有秘密,并且一個模塊中的漏洞可以訪問任何其他模塊可用的任何秘密。類似地,導致一個模塊失效的錯誤會導致整個過程失效(考慮到級聯故障時,可能還會導致整個應用程序失效)。在大多數主流語言中,每個模塊(即使是最不重要的依賴樹上的葉節點)都需要進行搜索以尋找潛在的安全性或可靠性問題,因為任何模塊都可能導致整個事情崩潰。這在大多數主流語言的語言級別都沒有解決。Erlang 語言家族通常會解決可靠性問題,但大多數語言都將其放在了一起。
微服務可能有意義的真正原因是它們讓人們在模塊邊界周圍保持誠實。同意。與靜態類型系統一樣,微服務是“軌道”。大多數組織都有以權宜之計走捷徑的人,而帶有 軌道 的系統會抑制這些捷徑(重要的是,它們并不排除它們)。
”
6、模塊化和微服務都解決了擴展問題:
模塊化允許開發擴展。微服務允許運維擴展。
7、微服務的優點在于,無論您的技能和資歷水平如何, 它們都會創建硬邊界。 任何無人監督的初級人員都可能會消除模塊邊界。但他們不能簡單地消除在另一個地方提供服務的硬邊界。
8、在實踐中,與微服務相比,庫和模塊是服務器端編程較不受歡迎的代碼分割解決方案,這是有充分理由的:
- 部署:當所有的東西都以單體形式出現時,就失去了快速和獨立部署代碼的能力。
- 隔離:一個團隊的bug修復會影響很多團隊。
- 運維復雜性:在系統上工作的人必須處理許多團隊的模塊在同一服務中運行這一事實。調試和排除故障變得更加困難。記錄和遙測也往往變得更加復雜。
- 依賴性耦合:每個人都必須使用完全相同的版本,每個人都必須同步升級。你可以用允許依賴性隔離的模塊系統來解決這個問題,但在我看來,這往往會導致其自身的復雜性問題,使之不值得。
- 模塊API的界限:根據我的經驗,開發人員處理服務API比處理庫API要容易得多。API的表面積比較小,而且你需要處理向后兼容和如何處理的問題也比較明顯。與庫的邊界相比,服務的邊界 "作弊 "或破壞封裝的機會也更少。
9、我已經做了很多所謂的微服務的服務開發。 在我看來,這篇文章說得很對:
- 微服務與組織上的限制有很大關系。
- 它與服務的邊界有很大關系。如果服務是相互調用,它們就會耦合。
- 一個服務所做的事情必須被指定,即它接收哪些數據和輸出哪些數據。這些數據可以而且應該是事件。
- 服務應該在隊列、主題、流等方面的消息傳遞的基礎上進行依賴和合作。
- 服務通常是數據充實服務,其中一個服務根據一個事件/數據充實一些數據。
- 你永遠不會同時測試一個以上的服務。
- 服務不應該共享那些在頻繁更新方面具有活力或短命的代碼。
- 征服和劃分。從開發一個小的單體開始,為你所期望的多個服務開發。然后劃分代碼。分開后,每個服務都有自己的實現,而不是在它們之間共享代碼。
- IaaS是很重要的。你應該能夠推送部署,并且服務的設置與所有基礎設施的依賴性。
- 領域的界限是很重要的。圍繞著它們的架構組織你的團隊,以某種能力為基礎。例如,客戶、預訂、開票。每個團隊擁有一個能力和其基礎服務。
- 讓其他團隊有可能讀取你的所有數據。他們可能需要這些數據來解決他們的問題。
- 不要使用kubernetes,除非你不能用云提供商的paas來實現你的愿望。Kubernetes是一頭野獸,會讓你經受考驗。
- 如果你不了解事情是如何溝通、失敗和恢復的,服務將無法解決你的問題。
- 一切最終都是一致性的。直面這個問題的心態需要時間。
10、微服務和模塊化是正交的,并不相同:
模塊化與業務概念相關,微服務與基礎設施概念相關。例如:我可以將模塊 A 部署到微服務 A1 和 A2 中。在這種情況下,A 幾乎是抽象概念。當然,我可以使用 1 個大型服務(單體)部署所有模塊 A、B、C。此外,我可以為所有模塊共享一個微服務 X。
微服務的所有混淆,都是由微服務 = 模塊的誤解造成的。更糟糕的是,我學到的大多數“專家建議”實際上都將領域驅動設計與微服務聯系起來,他們確實沒有關系。微服務對我來說就是規模化:擴展基礎設施。擴大團隊規模(管理理念)。
(banq注:微服務是一個不同于模塊的角度,有業務角度,參考DDD;有數據角度;也有運維角度;也有技術架構角度)
審核編輯 :李倩
-
模塊
+關注
關注
7文章
2787瀏覽量
50239 -
數據處理
+關注
關注
0文章
627瀏覽量
29141 -
微服務
+關注
關注
0文章
145瀏覽量
7732
原文標題:您需要模塊,而不是微服務
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
企業使用NVIDIA NeMo微服務構建AI智能體平臺
微服務器架構幾種典型的基礎框架,你了解嗎?
NVIDIA 發布保障代理式 AI 應用安全的 NIM 微服務
微服務容器化部署好處多嗎?
容器化能替代微服務嗎?兩者有何區別
寶藏級微服務架構工具合集
NVIDIA NIM微服務登陸亞馬遜云科技
SSR與微服務架構的結合應用
微服務架構與容器云的關系與區別
入門級攻略:如何容器化部署微服務?
借助NVIDIA Metropolis微服務構建視覺AI應用
Proxyless的多活流量和微服務治理
NVIDIA NIM微服務帶來巨大優勢
采用OpenUSD和NVIDIA NIM微服務創建精準品牌視覺
全新 NVIDIA NeMo Retriever微服務大幅提升LLM的準確性和吞吐量





 工商網監
工商網監
評論