") BEV+Transformer對(duì)智能駕駛硬件系統(tǒng)有著什么樣的影響?
BEV+Transformer對(duì)智能駕駛硬件系統(tǒng)有著什么樣的影響?

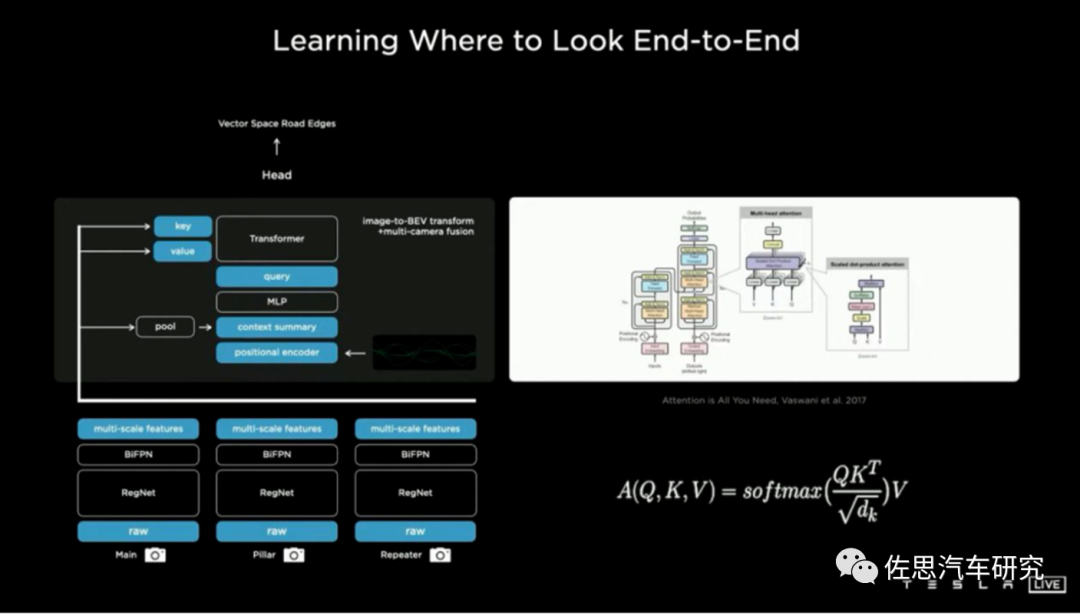
圖片來(lái)源:特斯拉
BEV+Transformer是目前智能駕駛領(lǐng)域最火熱的話(huà)題,沒(méi)有之一,這也是無(wú)人駕駛低迷期唯一的亮點(diǎn),BEV+Transformer徹底終結(jié)了2D直視圖+CNN時(shí)代,BEV+Transformer對(duì)智能駕駛硬件系統(tǒng)有著什么樣的影響?背后的受益者又是誰(shuí)?
先說(shuō)結(jié)論。首先受益者是視覺(jué)系統(tǒng)廠家,車(chē)輛至少要增加4-6個(gè)攝像頭,不過(guò)目前新興造車(chē)企業(yè)都已經(jīng)準(zhǔn)備好了這些硬件基礎(chǔ),此外需要6-8個(gè)加串行芯片,2-3個(gè)解串行芯片,加串行與解串行的市場(chǎng)基本被德州儀器和ADI旗下的美信壟斷,美信獨(dú)占了中高端市場(chǎng),這些芯片價(jià)格隨著像素的上升也大幅度增加,數(shù)量也增加了,最終成本幾乎與主SoC一樣價(jià)格,讓ADI業(yè)績(jī)大漲。
其次是英偉達(dá)這樣的強(qiáng)大數(shù)據(jù)訓(xùn)練系統(tǒng)廠家,Transformer就是暴力美學(xué),參數(shù)量動(dòng)輒十億百億千億,萬(wàn)億也不罕見(jiàn),層數(shù)動(dòng)輒上千層,根本不是老舊數(shù)據(jù)訓(xùn)練中心能支撐的,需要大量購(gòu)買(mǎi)英偉達(dá)或AMD的上萬(wàn)美元級(jí)的訓(xùn)練芯片。以前做訓(xùn)練的RTX3090,現(xiàn)在只能做推理用了。毫無(wú)疑問(wèn)這讓研發(fā)成本暴增。
再次是存儲(chǔ)系統(tǒng),Transformer模型體積驚人,動(dòng)輒GB起,這需要芯片上的L2緩存大增,實(shí)際就是消耗大量的SRAM,對(duì)數(shù)據(jù)訓(xùn)練中心和嵌入式系統(tǒng)來(lái)說(shuō)就是芯片價(jià)格暴漲,如果用不起昂貴的SRAM,數(shù)據(jù)中心這一級(jí)也要用HBM。對(duì)推理的嵌入式系統(tǒng)來(lái)說(shuō),HBM的價(jià)格太高,消費(fèi)級(jí)的汽車(chē)市場(chǎng)是無(wú)法接受的,只能退一步選擇LPDDR5或GDDR5/6,容量要大幅度增加,至少32GB起,成本自然也大幅增加。
最后是數(shù)據(jù)搜集和標(biāo)注,Transformer需要海量訓(xùn)練數(shù)據(jù),越多越好,意味著智能駕駛廠家需要更多的數(shù)據(jù)采集車(chē),數(shù)據(jù)采集設(shè)備,更多的數(shù)據(jù)處理人員,研發(fā)成本暴增。2D直視圖+CNN時(shí)代廠家累積起來(lái)的研發(fā)成果化為烏有,很多事情都要從頭做起,意味著以前的研發(fā)成果貶值嚴(yán)重。最終這一切都轉(zhuǎn)換為消費(fèi)者頭上的成本,成本至少增加300%。
激光雷達(dá)和傳統(tǒng)AI芯片也將受到影響。首先是激光雷達(dá),BEV+Transformer讓純視覺(jué)更加強(qiáng)大,接近以前激光雷達(dá)制造BEV的效果,廠家都一窩蜂地?fù)肀EV+Transformer,冷落激光雷達(dá)。其次是推理用的AI芯片,之前的AI芯片大多是針對(duì)CNN的,對(duì)Transformer的適應(yīng)性會(huì)比較差,畢竟Transformer是源自自然語(yǔ)言處理(NLP)的,數(shù)據(jù)的串行性很顯著,并行性不佳,這需要AI芯片做出對(duì)應(yīng)的改變,并且是硬件上的改變,這可能意味著推倒重來(lái),或者用更強(qiáng)的Host來(lái)對(duì)數(shù)據(jù)整形,也就是標(biāo)量運(yùn)算即CPU要加強(qiáng),Cortex-A55恐怕是無(wú)法勝任的。
再有原本智能駕駛AI專(zhuān)用芯片都特別針對(duì)INT8精度,但Transformer簡(jiǎn)單量化為8位后性能顯著下降,這主要是由于普通的激活函數(shù)量化策略無(wú)法覆蓋全部的取值區(qū)間。參數(shù)越多,量化后的效果就越差。引入BF16非常有必要,而以前設(shè)計(jì)的AI芯片大多沒(méi)考慮BF16。
我們來(lái)簡(jiǎn)單了解一下BEV+Transformer,基于多視角攝像頭的3D目標(biāo)檢測(cè)在鳥(niǎo)瞰圖下的感知(Bird's-eye-viewPerception, BEV Perception)吸引了越來(lái)越多的關(guān)注。一方面,將不同視角在BEV下統(tǒng)一表征是很自然的描述,方便后續(xù)規(guī)劃控制模塊任務(wù);另一方面,BEV下的物體沒(méi)有圖像視角下的尺度(scale)和遮擋(occlusion)問(wèn)題。
目前BEV+Transformer算法對(duì)比都是基于nuScenes數(shù)據(jù)集的,因?yàn)槠溆?xùn)練數(shù)據(jù)最多,在小尺寸的Kitti上,Transformer表現(xiàn)不如CNN。
nuScenes與其他數(shù)據(jù)集的對(duì)比
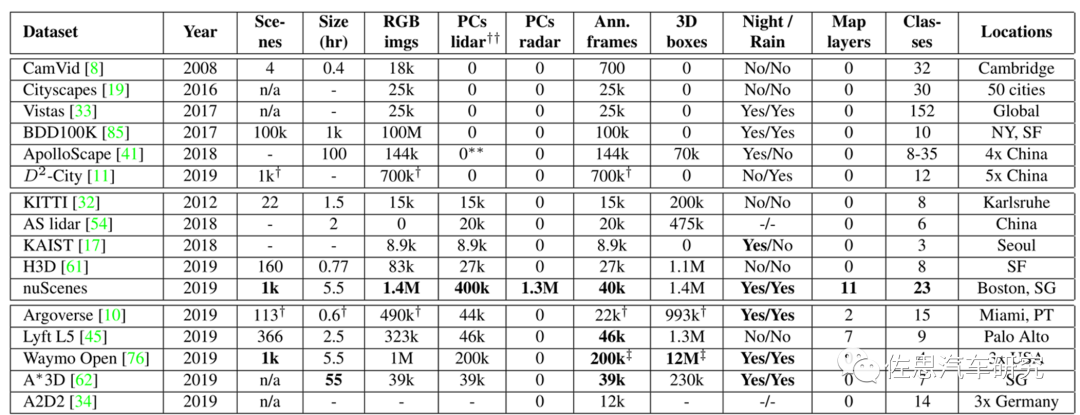
圖片來(lái)源:《nuScenes: A multimodal dataset for autonomous driving》
nuScenes是唯一有毫米波雷達(dá)的數(shù)據(jù)集。論文名稱(chēng)《nuScenes:A multimodal dataset for autonomous driving》,這是智能駕駛領(lǐng)域最具影響力的數(shù)據(jù)集,完成于2019年3月,2020年7月推出nuScenes-lidarseg,nuTonomy提出的激光雷達(dá)點(diǎn)柱算法也是目前最常用的激光雷達(dá)算法。nuScenes-lidarseg則是激光雷達(dá)最完備的測(cè)試數(shù)據(jù)集,包含850個(gè)訓(xùn)練場(chǎng)景,150個(gè)測(cè)試場(chǎng)景,驚人的14億標(biāo)注點(diǎn),4萬(wàn)點(diǎn)云幀,32級(jí)分類(lèi)。nuScenes目前由安波福與現(xiàn)代汽車(chē)的合資公司Motional維護(hù)。
BEV+Transformer基本概念
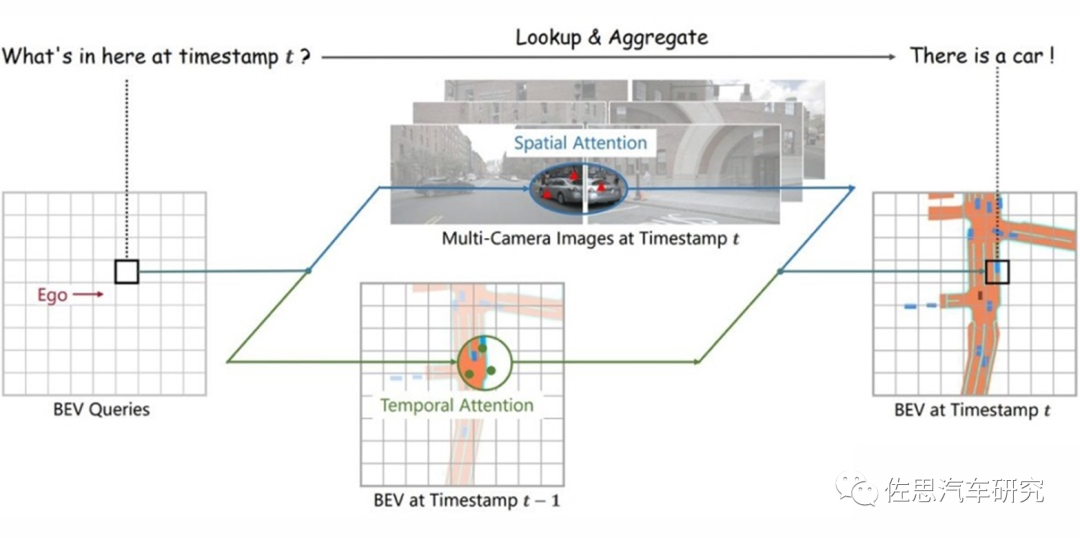
圖片來(lái)源:《BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via SpatiotemporalTransformers》
CNN時(shí)代,完全拋棄了時(shí)間序列,智能駕駛檢測(cè)的是圖片而非視頻,因此在靜止目標(biāo)識(shí)別方面要差很多,也很難定位目標(biāo)的具體位置,因?yàn)橐苿?dòng)目標(biāo)位置是變換的,需要加入時(shí)間序列變量。光流加入了時(shí)間序列變量,但是單目光流法效果很差,因?yàn)楣饬鞫际腔诹Ⅲw雙目或激光雷達(dá)發(fā)展而來(lái)的,特別是立體雙目,做光流尤其合適,奔馳是這方面的頂尖高手,開(kāi)發(fā)了所謂6D視覺(jué),其中光流就是另外3D的構(gòu)成,不僅能檢測(cè)目標(biāo)的速度,還能推斷目標(biāo)的時(shí)間序列位置。
Transformer與CNN最大不同就是加入了時(shí)序信息,而B(niǎo)EV是一個(gè)空間概念,BEV+Transformer就是時(shí)空融合,時(shí)序信息對(duì)于自動(dòng)駕駛感知任務(wù)十分重要,但現(xiàn)階段基于視覺(jué)的3D目標(biāo)檢測(cè)方法并沒(méi)有很好地利用上這一非常重要的信息。時(shí)序信息一方面可以作為空間信息的補(bǔ)充,來(lái)更好地檢測(cè)當(dāng)前時(shí)刻被遮擋的物體或者為定位物體的位置提供更多參考信息。另一方面就是對(duì)靜止目標(biāo)的處理更加快速高效。
對(duì)于每一個(gè)位于(x,y)位置的BEV特征,我們可以計(jì)算其對(duì)應(yīng)現(xiàn)實(shí)世界的坐標(biāo) x',y'。然后我們將BEV query進(jìn)行l(wèi)ift操作,獲取在z軸上的多個(gè)3D points。有了3D points,就能夠通過(guò)相機(jī)內(nèi)外參獲取3Dpoints在view平面上的投影點(diǎn)。受到相機(jī)參數(shù)的限制,每個(gè)BEV query一般只會(huì)在1-2個(gè)view上有有效的投影點(diǎn)。
基于Deformable Attention,我們以這些投影點(diǎn)作為參考點(diǎn),在周?chē)M(jìn)行特征采樣,BEV query使用加權(quán)的采樣特征進(jìn)行更新,從而完成了spatial空間的特征聚合。將BEV特征視為類(lèi)似能夠傳遞序列信息的memory。每一時(shí)刻生成的BEV特征都從上一時(shí)刻的BEV特征獲取了所需的時(shí)序信息,這樣保證能夠動(dòng)態(tài)獲取所需的時(shí)序特征,而非像堆疊不同時(shí)刻BEV特征那樣只能獲取定長(zhǎng)的時(shí)序信息。
Transformer會(huì)瘋狂消耗內(nèi)存,內(nèi)存容量與輸入序列長(zhǎng)度的平方成正比,與批大小成線(xiàn)性比例。一個(gè)vocab Embedding 的shape是(50304, 5120)。而對(duì)于每個(gè)parameter來(lái)說(shuō),其需要存儲(chǔ):來(lái)自于FP32的weight以及Adam的(Embedding也是Adam更新),來(lái)自于前向時(shí)FP16的weight。注意,此處沒(méi)有g(shù)rad的計(jì)算,因?yàn)镋mbedding layer的grad通常占用的很小,不像MatMul一樣。最終結(jié)果是3.6GB,每一層Transformer Encoder Model States消耗約6GB,Activation的batch_size每增加1消耗約1GB,Vocab Embedding Layer模型權(quán)重約消耗3.6GB。這是理論值,實(shí)際值比這大得多。
對(duì)于深度學(xué)習(xí)或者說(shuō)人工智能運(yùn)算,瓶頸就在存儲(chǔ)器,最簡(jiǎn)單的解決辦法就是用HBM3內(nèi)存,HBM就是高寬帶。
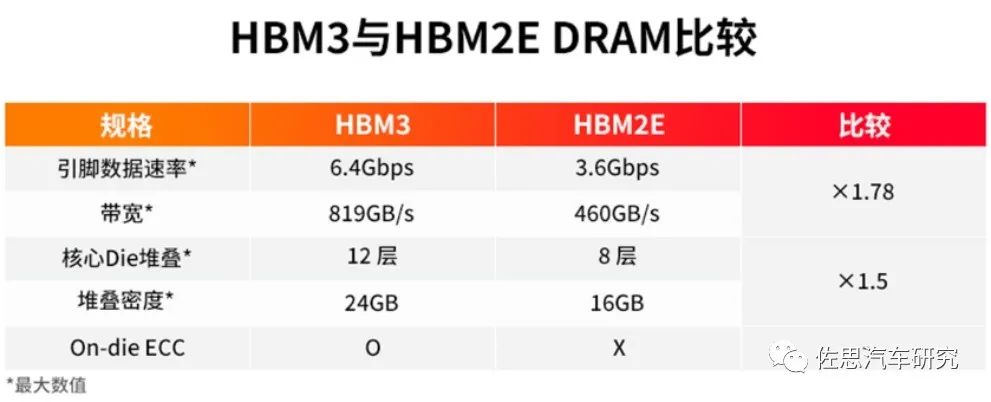
圖片來(lái)源:SK Hynix
高性能AI芯片必用HBM,而HBM有三個(gè)缺點(diǎn),一是價(jià)格昂貴,每GB成本大約20-40美元,至少8GB起售;二是必須使用2.5D封裝,成本進(jìn)一步增加;三是功耗增加不少。
HBM的成本還不是最高的,最高的成本是SRAM,也就是L2緩存,無(wú)論是訓(xùn)練還是推理,都要用到,容量越大越好,它的速度比HBM要高許多,成本要高更多。AI芯片當(dāng)然要用先進(jìn)工藝,臺(tái)積電N4即4納米工藝,這種工藝如果做SRAM并不會(huì)提高密度,4N工藝下每MB的SRAM成本大約40-50美元,也有人估計(jì)是近100美元。
現(xiàn)在我們來(lái)構(gòu)建一套BEV+Transformer,首選至少需要新增6個(gè)攝像頭,為什么不能用360環(huán)視的攝像頭,很簡(jiǎn)單,360環(huán)視用的都是魚(yú)眼鏡頭,水平FOV一般是195度,其有效距離一般不超過(guò)5米,大部分都是在3米甚至2米內(nèi)。做BEV至少需要20米的側(cè)向有效距離。此外,360環(huán)視攝像頭的安裝高度偏低,做BEV,高度越高越好,最好是車(chē)頂。
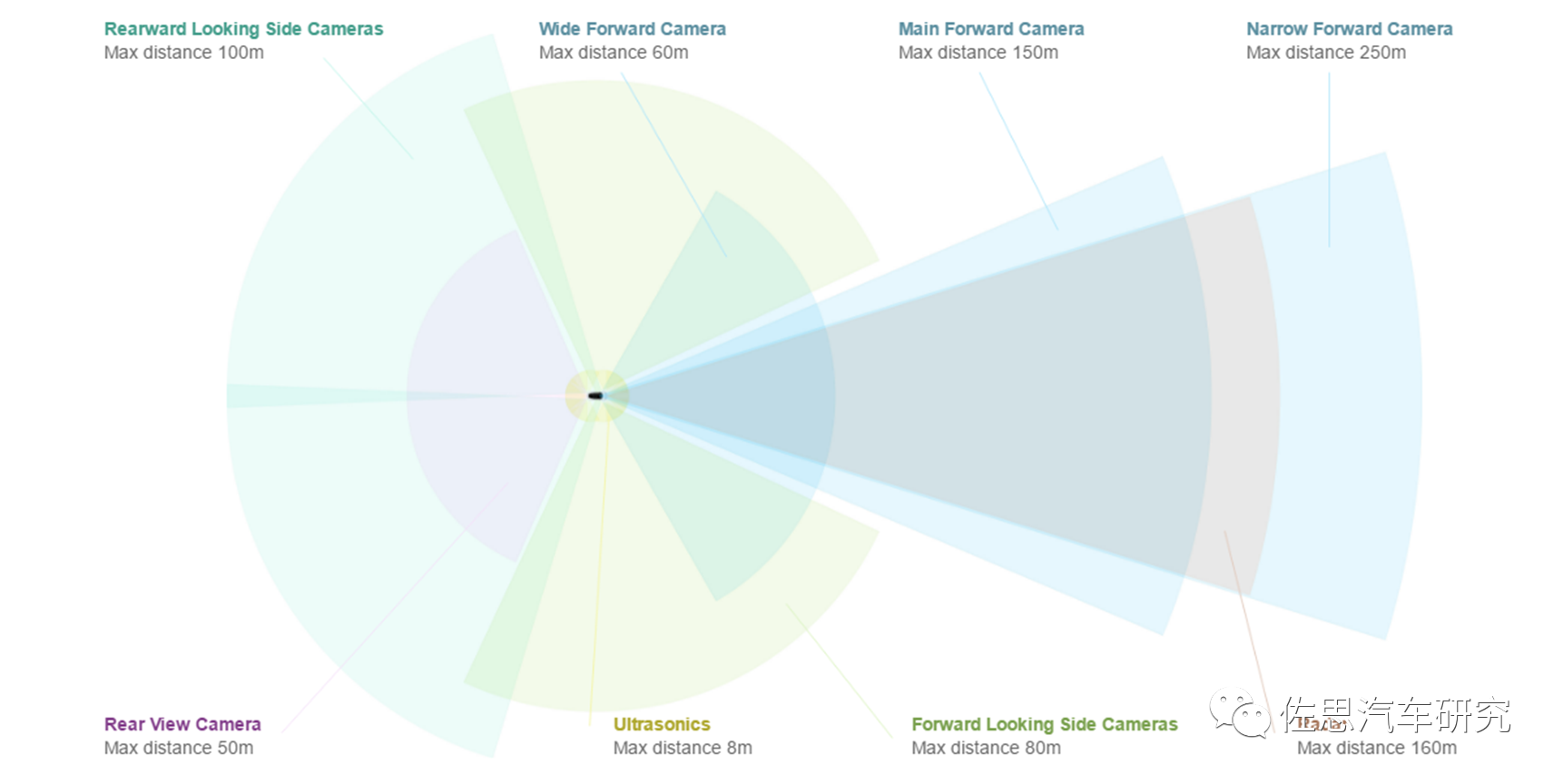
圖片來(lái)源:特斯拉
特斯拉是8個(gè)攝像頭,前面3個(gè),F(xiàn)OV分別是35度、50度、120度,側(cè)方A柱和B柱各2個(gè),前側(cè)攝像頭的FOV據(jù)說(shuō)是90度,后側(cè)攝像頭的FOV推測(cè)是80度,后攝像頭FOV推測(cè)是130度,像素都是130萬(wàn)像素。2023或2024年的HW4.0是7個(gè),前面從三個(gè)變成兩個(gè),35度FOV的攝像頭取消,50度FOV的攝像頭像素增加到536萬(wàn),就是索尼的IMX490做傳感器,其余6個(gè)攝像頭升級(jí)為200萬(wàn)像素。
攝像頭的有效距離與像素?cái)?shù)、安裝高度成正比,與水平FOV成反比。中國(guó)車(chē)特別是新興造車(chē)勢(shì)力一貫采用800萬(wàn)像素。因此800萬(wàn)像素?cái)z像頭6個(gè),像素比較高,F(xiàn)OV就可以寬一點(diǎn),側(cè)向和后向都用120度,前向還是45度或50度。這需要8個(gè)加串行芯片,一般是MAX9295,4個(gè)解串行芯片,一般是MAX9296或MAX96712,MAX96712目前非常火爆,2倍甚至3倍高價(jià)都拿不到貨。光這12個(gè)解串行芯片估計(jì)就要近150美元,差不多1000人民幣。
處理器系統(tǒng),運(yùn)算量巨大,非4個(gè)頂配Orin莫屬,僅此一項(xiàng)大約1200美元。理論上算力足夠了,但實(shí)際瓶頸在存儲(chǔ),需要強(qiáng)大的存儲(chǔ)器,GDDR6或LPDDR5是首選。
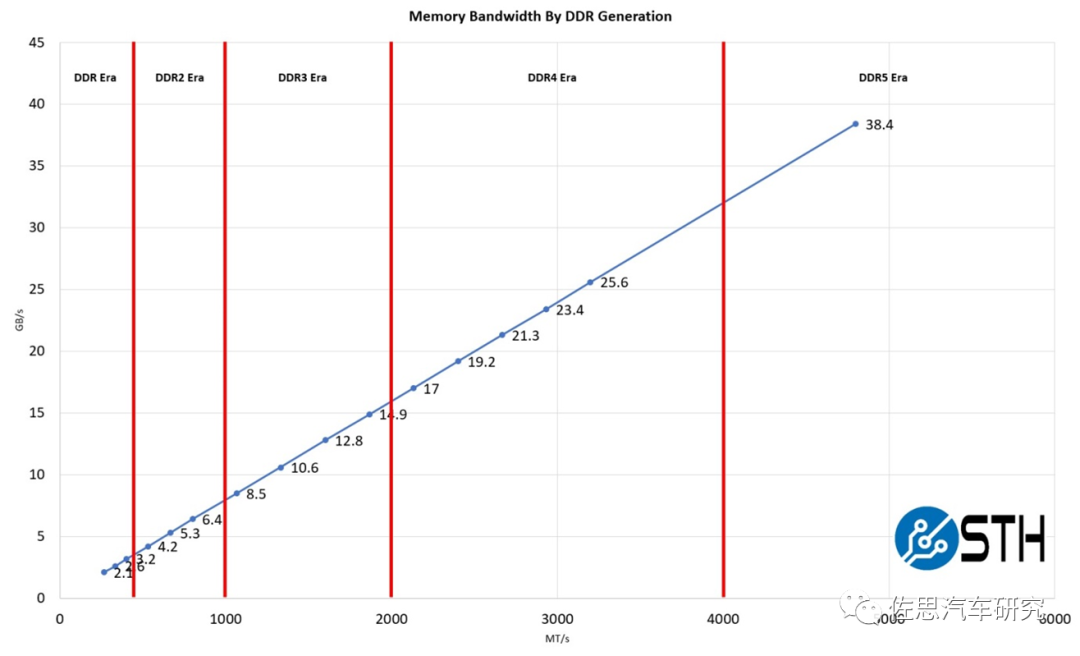
圖片來(lái)源:STH
DDR5性能提升不少,如上圖,英偉達(dá)頂配Orin推薦的是64GB的256bit LPDDR5,帶寬有204.8GB/s。4個(gè)Orin需要256GBLPDDR5,目前48GB LPDDR4報(bào)價(jià)是35美元,256GB LPDDR5估計(jì)要200美元。GDDR6價(jià)格會(huì)更高,估計(jì)要300美元。
BEV+Transformer的根源是特斯拉,特斯拉自然是不用激光雷達(dá)的。迄今為止,研究BEV+Transformer的絕大部分都是純視覺(jué),Waymo、地平線(xiàn)和國(guó)內(nèi)的毫末智行加入了激光雷達(dá)。與攝像頭比,線(xiàn)數(shù)再高的激光雷達(dá)都是稀疏點(diǎn)云數(shù)據(jù),兩者的query特征差別較大,雖然說(shuō)BEV更適合傳感器前融合,但激光雷達(dá)的作用明顯弱化,核心還是攝像頭,純視覺(jué)與加了激光雷達(dá)的傳感器高級(jí)融合,實(shí)際差別不大,這與激光雷達(dá)領(lǐng)域大量使用點(diǎn)柱算法也有關(guān)系,激光雷達(dá)的深度信息完全沒(méi)有發(fā)揮,等于是一個(gè)能在黑夜工作的加強(qiáng)版的攝像頭。反倒是那些8線(xiàn)或16線(xiàn)甚至4線(xiàn)的激光雷達(dá)效果更好。
再來(lái)看AI芯片,目前智能駕駛領(lǐng)域的AI芯片都是以CNN為核心的,基本都是設(shè)計(jì)針對(duì)INT8即整數(shù)8位精度的,在Transformer時(shí)代很難有所作為,需要重新設(shè)計(jì),且重要性下降,與GPU比差距拉大了。最關(guān)鍵一點(diǎn),時(shí)間序列是矢量,Transformer是浮點(diǎn)矢量矩陣乘法累加運(yùn)算,浮點(diǎn)運(yùn)算與整數(shù)運(yùn)算差異巨大,GPU最初就是專(zhuān)門(mén)為浮點(diǎn)運(yùn)算而生的。AI推理專(zhuān)用芯片幾乎都不考慮浮點(diǎn)運(yùn)算。AI芯片做浮點(diǎn)運(yùn)算時(shí),效率會(huì)直線(xiàn)下降。
Swin Transformer的模型結(jié)構(gòu)
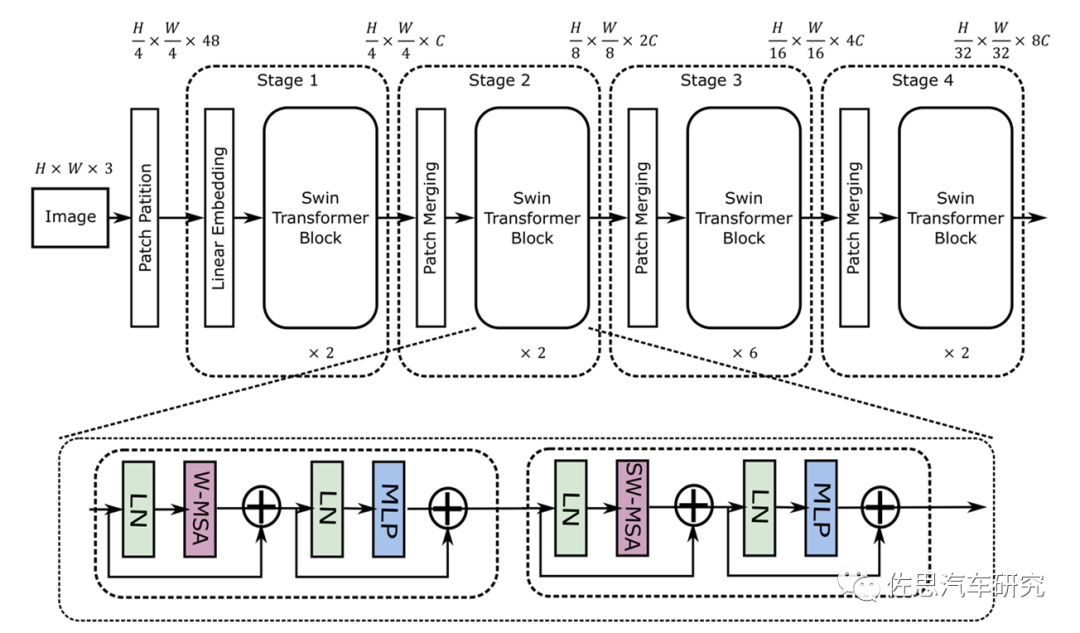
圖片來(lái)源:《MaxViT: Multi-Axis VisionTransformer》
從圖上就能看出其采用了4*4卷積矩陣,而CNN是3*3,這就意味著目前的AI芯片有至少33%的效率下降。再者就是其是矢量與矩陣的乘法,這會(huì)帶來(lái)一定的浮點(diǎn)矢量運(yùn)算。假設(shè)高和寬都為112,窗口大小為7,C為128,那么未優(yōu)化的浮點(diǎn)計(jì)算是:4*112*112*128*128+2*112*112*112*112*128=41GFLOP/s。大部分AI芯片如特斯拉的FSD和谷歌的TPU,未考慮這種浮點(diǎn)運(yùn)算。不過(guò)華為和高通都考慮到了,英偉達(dá)就更不用說(shuō)了,GPU天生就是針對(duì)浮點(diǎn)運(yùn)算的。
英偉達(dá)在新一代GPU中特別增加了Transformer引擎,Transformer引擎的秘訣在于它能夠在訓(xùn)練神經(jīng)網(wǎng)絡(luò)的每個(gè)步驟中動(dòng)態(tài)選擇神經(jīng)網(wǎng)絡(luò)中每一層所需的精度。最不精確的單元,即8位浮點(diǎn),可以加快計(jì)算速度,但如果這是下一層所需的精度,則可以為下一層生成16位或32位和。不過(guò),Hopper更進(jìn)一步。
它的8浮點(diǎn)單元可以使用兩種形式的8位數(shù)字中的任何一種進(jìn)行矩陣數(shù)學(xué)運(yùn)算。標(biāo)準(zhǔn)的16位浮點(diǎn)格式(IEEE 754-2008)需要5位指數(shù)和10位尾數(shù)以及符號(hào)位。為了減少數(shù)據(jù)存儲(chǔ)要求和加速機(jī)器學(xué)習(xí),英偉達(dá)和谷歌更喜歡bfloat-16,它用三位尾數(shù)換取一個(gè)附加指數(shù),使其范圍與32位數(shù)字相同。
bf16是最適合Transformer的格式。英偉達(dá)的Transformer引擎可以協(xié)調(diào)動(dòng)態(tài)范圍和準(zhǔn)確度,比如浮點(diǎn)8位,大動(dòng)態(tài)范圍可以使用5位指數(shù)和2位尾數(shù)(E5M2),或者當(dāng)精度是關(guān)鍵時(shí),可以使用4位指數(shù)和3位尾數(shù)(E4M3)。
CNN的權(quán)重模型通常不超過(guò)20MB,而Transformer則輕松超過(guò)1000MB也就是1GB。以前CNN時(shí)代,AI芯片還可以勉強(qiáng)放下權(quán)重模型,而Transformer時(shí)代則絕無(wú)可能,存儲(chǔ)器的重要性進(jìn)一步上升,AI芯片的地位下降,GPU的優(yōu)勢(shì)更加明顯。
不僅是智能駕駛,所謂AI的發(fā)展方向就是模型體積越來(lái)越龐大,參數(shù)量越來(lái)越多,就像劣幣驅(qū)逐良幣一樣,這樣硬件會(huì)不斷迭代,成本也會(huì)越來(lái)越高。
審核編輯:劉清
-
激光雷達(dá)
+關(guān)注
關(guān)注
971文章
4218瀏覽量
192381 -
SRAM編程
+關(guān)注
關(guān)注
0文章
2瀏覽量
6006 -
HBM
+關(guān)注
關(guān)注
2文章
409瀏覽量
15172 -
LPDDR5
+關(guān)注
關(guān)注
2文章
90瀏覽量
12528 -
智能駕艙
+關(guān)注
關(guān)注
0文章
17瀏覽量
3979
原文標(biāo)題:BEV+Transformer對(duì)無(wú)人駕駛硬件體系的巨大改變
文章出處:【微信號(hào):zuosiqiche,微信公眾號(hào):佐思汽車(chē)研究】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
淺析4D-bev標(biāo)注技術(shù)在自動(dòng)駕駛領(lǐng)域的重要性
什么是物聯(lián)網(wǎng)智能路燈? 智慧路燈是什么?什么樣的智慧路燈更滿(mǎn)足現(xiàn)代需求

ads1198輸出的TESTP-PACE-OUT1,TESTN-PACE-OUT2是什么樣的信號(hào)?
【「具身智能機(jī)器人系統(tǒng)」閱讀體驗(yàn)】2.具身智能機(jī)器人的基礎(chǔ)模塊
《具身智能機(jī)器人系統(tǒng)》第1-6章閱讀心得之具身智能機(jī)器人系統(tǒng)背景知識(shí)與基礎(chǔ)模塊
淺析基于自動(dòng)駕駛的4D-bev標(biāo)注技術(shù)

什么樣的電阻柜用于風(fēng)電光伏項(xiàng)目
自動(dòng)駕駛中一直說(shuō)的BEV+Transformer到底是個(gè)啥?

如何選擇智能駕駛輔助系統(tǒng)
智能駕駛系統(tǒng)的工作原理
IP地址與智能家居能夠碰撞出什么樣的火花呢?
代碼整潔之道-大師眼中的整潔代碼是什么樣

RISC-V適合什么樣的應(yīng)用場(chǎng)景
FPGA在自動(dòng)駕駛領(lǐng)域有哪些優(yōu)勢(shì)?
端到端必然是高階自駕的未來(lái)

- 設(shè)計(jì)技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測(cè)量?jī)x表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無(wú)線(xiàn)
- 接口/總線(xiàn)/驅(qū)動(dòng)
- 處理器/DSP
- EDA/IC設(shè)計(jì)
- 存儲(chǔ)技術(shù)
- 光電顯示
- EMC/EMI設(shè)計(jì)
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車(chē)電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實(shí)
- 可穿戴設(shè)備
- 機(jī)器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動(dòng)通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測(cè)
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專(zhuān)欄推薦
- 學(xué)院
- 設(shè)計(jì)資源
- 設(shè)計(jì)技術(shù)
- 電子百科
- 電子視頻
- 元器件知識(shí)
- 工具箱
- VIP會(huì)員
- 最新技術(shù)文章
- 產(chǎn)品地圖
- 品牌地圖
- 社區(qū)
- 小組
- 論壇
- 問(wèn)答
- 評(píng)測(cè)試用
- 企業(yè)服務(wù)
- 產(chǎn)品
- 資料
- 文章
- 方案
- 企業(yè)
- 供應(yīng)鏈服務(wù)
- 硬件開(kāi)發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線(xiàn)研討會(huì)
- 活動(dòng)策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測(cè)驗(yàn)
- 設(shè)計(jì)大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動(dòng)態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報(bào)投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動(dòng)端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長(zhǎng)沙市望城經(jīng)濟(jì)技術(shù)開(kāi)發(fā)區(qū)航空路6號(hào)手機(jī)智能終端產(chǎn)業(yè)園2號(hào)廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
評(píng)論