 LLaMA論文研讀:小參數+大數據的開放、高效基礎語言模型閱讀筆記
LLaMA論文研讀:小參數+大數據的開放、高效基礎語言模型閱讀筆記
Meta最近提出了LLaMA(開放和高效的基礎語言模型)模型參數包括從7B到65B等多個版本。最值得注意的是,LLaMA-13B的性能優于GPT-3,而體積卻小了10倍以上,LLaMA-65B與Chinchilla-70B和PaLM-540B具有競爭性。
Meta表示,該模型在數以萬億計的token上進行訓練,并表明有可能完全使用公開的數據集來訓練最先進的模型,而不需要求助于專有的和不可獲取的數據集。
特別的,LLaMA-13B在大多數基準上超過了GPT-3(175B),LLaMA-65B與最好的模型Chinchilla-70B和PaLM-540B具有明顯競爭力。
為了了解該工作,本文主要通過研讀該論文,供大家一起參考。
該論文介紹了對模型架構的修改(Vaswani等人,2017),給出了具體的訓練方法,并報告了模型的性能以及在一組標準基準上與其他LLMs進行了比較。
地址:https://github.com/facebookresearch/llama
一、工作簡介與問題的提出
在大量的文本語料庫中訓練的大型語言模型(LLMs)已經顯示出它們能夠從文本指令或少數例子中形成新的任務(Brown等人,2020)。
在將模型擴展到足夠大的規模時,首次出現了這些少見的特性(Kaplan等人,2020年),從而形成了一個專注于進一步擴展這些模型的工作路線(Chowdhery等人,2022年;Rae等人,2021年)。
這些努力都是基于這樣的假設:更多的參數會帶來更好的性能。然而,Hoffmann等人(2022)最近的工作表明,在給定的計算預算下,最好的性能不是由最大的模型實現的,而是由在更多數據上訓練的較小的模型實現的。
Hoff-mann等人(2022)的縮放定律的目標是確定如何在特定的訓練計算預算下最佳地擴展數據集和模型大小。然而,這個目標忽略了推理預算,而推理預算在大規模服務語言模型時變得至關重要。
在這種情況下,給定一個目標性能水平,首選的模型不是訓練速度最快的,而是推理速度最快的,盡管訓練一個大的模型以達到一定的性能水平可能更便宜,但訓練時間較長的小模型最終會在推理中更便宜。
例如,Hoffmann等人(2022年)曾建議在200B的token上訓練一個10B的模型,但研究發現7B的模型的性能甚至在1T的token之后還能繼續提高。
因此,該工作的重點是訓練一系列語言模型,通過對比通常使用的更多的token進行訓練,在不同的推理預算下達到最佳的性能。
該工作得到的模型被稱為LLaMA,參數范圍從7B到65B,與現有的最佳LLM相比,具有競爭力的性能。
盡管LLaMA-13B比GPT-3小10倍,但在大多數基準測試中都超過了GPT-3。這個模型將有助于增強對LLM的訪問和研究,因為它可以在單個GPU上運行。此外,65B參數模型也可以與最好的大型語言模型(如Chinchilla或PaLM-540B)競爭。
特別的,與Chinchilla、PaLM或GPT-3不同的是,該工作只使用公開可用的數據,這使得工作符合開源原則,而大多數現有模型所依賴的數據要么沒有公開可用,要么沒有記錄(例如 "書籍-2TB "或 "社交媒體對話")。
接下來,我們分別從訓練數據等方面進行介紹。
二、預訓練數據的來源與清洗策略
LLaMA的訓練數據集由幾個來源混合而成,涵蓋了各種不同的領域,如下表所示:
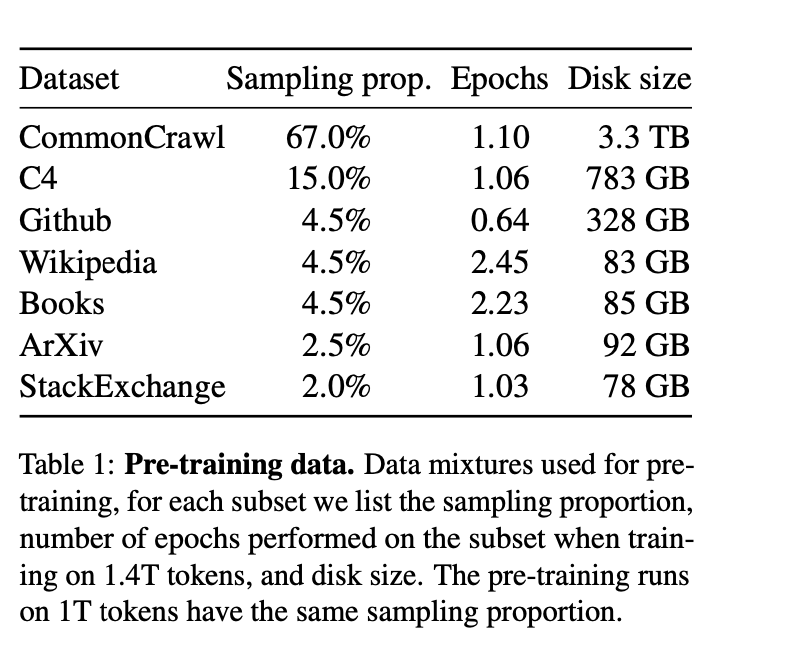
1、英語CommonCrawl,占比67%
由于CommonCraw數據較為雜亂,該工作采用CCNet pipleline的方式(Wenzek等人,2020)預處理了從2017年到2020年的CommonCrawl網頁。
具體的,
該工作首先在行的層面上對數據進行了刪除,用fastText線性分類器進行語言識別,以去除非英語頁面,并用n-gram語言模型過濾低質量內容。
其次,訓練了一個線性模型來對維基百科中用作參考的頁面與隨機抽樣的頁面進行分類,并丟棄了未被歸類為參考的頁面。
2、C4 ,占比15%
在探索性實驗中,該工作觀察到,使用不同的預處理Com-monCrawl數據集可以提高性能。
因此,該工作將公開的C4數據集(Raffel等人,2020)也納入我們的數據。
C4的預處理也包含重復數據刪除和語言識別步驟,其與CCNet的主要區別在于質量過濾,它主要依賴于不存在的標點符號或網頁中的單詞和句子數量等判例。
3、Github,占比4.5%
在代碼方面,該工作使用了谷歌BigQuery上的GitHub公共數據集,并只保留在Apache、BSD和MIT許可下發布的項目。
此外,為了提高數據質量,還用基于行長或字母數字字符比例的啟發式方法過濾了低質量的文件,并用規范的表達式刪除了如標題在內的模板化內容。
最后在文件層面上對結果數據集進行重復計算,并進行精確匹配。
4、維基百科,占比4.5%
該工作添加了2022年6月至8月期間的維基百科轉儲數據,涵蓋20種語言,這些語言使用拉丁字母或西里爾字母,具體是:BG、CA、CS、DA、DE、EN、ES、FR、HR、HU、IT、NL、PL、UP、RO、RU、SL、SR、SV、UK。
此外,該工作對數據進行處理,以刪除超鏈接、評論和其他格式化的模板。
5、GutenbergProject和Books3,占比4.5%
書籍也是重要的語料來源,該工作的訓練數據集包括兩個書籍語料庫:古騰堡計劃(GutenbergProject)和ThePile(Gao等人,2020)的Books3部分,后者是一個可用于訓練大型語言模型的公開數據集。
在數據處理上,該工作在書的層面上進行了去重處理,刪除了內容重疊度超過90%的書。
6、ArXiv,占比2.5%
科研文獻對于提升專業性也有重要作用,該工作對arXiv的Latex文件進行處理,將科學數據添加到預訓練數據集中。
按照Lewkowycz等人(2022年)的做法,該工作刪除了第一節之前的所有內容以及書目。
此外,還刪除了.tex文件中的評論,以及用戶寫的內聯擴展定義和宏,以增加論文之間的一致性。
7、Stack Exchange,占比2%
QA數據對于提升垂直的專業問題也有幫助。
該工作還使用了Stack Exchange的開放數據,Stack Exchange是一個高質量的問題和答案的網站,涵蓋了從計算機科學到化學的不同領域。
具體的,該工作保留了28個最大的網站的數據,從文本中去除HTML標簽,并按分數(從高到低)對答案進行排序。
值得注意的是,我們將所有數字拆分為單個數字,并退回到字節來分解未知的UTF-8字符。
最后,在Tokenizer進行切分方面,該工作我們用bytepairencoding(BPE)算法(Sennrich等人,2015)對數據進行切分,并使用Sentence-Piece(Kudo和Richardson,2018)進行實現。值得注意的是,該將所有數字拆分為單個數字,并退回到字節來分解未知的UTF-8字符。
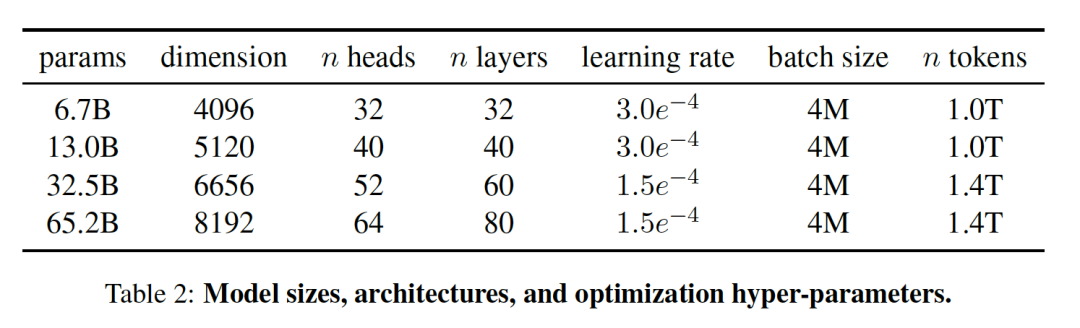
總的來說,我們的整個訓練數據集在切分之后包含了大約1.4T的token,如表2所示。
另外,在數據采樣方面,對于大多數訓練數據,每個token在訓練過程中只采樣一次,但維基百科和圖書領域除外,對這些領域進行了大約兩個epochs。
三、訓練細節:架構選擇以及優化策略
1、架構選擇
在架構選型上,該工作同樣采用是Transformer架構(Vaswani等人,2017),并利用隨后提出的各種改進,在不同的模型中進行使用,如PaLM。這里是與原始架構的主要區別主要包括:
1)Pre-normalization VS GPT3
為了提高訓練的穩定性,我們對每個變換子層的輸入進行規范化,而不是對輸出進行規范化。
并使用Zhang和Sennrich(2019)介紹的RMSNorm歸一化函數。
2)SwiGLU activation function VS PaLM
采用SwiGLU激活函數取代由Shazeer(2020)介紹的ReLU非線性方法,以提高性能。此外,在維度上使用的維度是2/3*4d,而不是PaLM中的4d。
3)Rotary Embeddings VS GPTNeo
在位置編碼上,刪除了絕對位置嵌入,而在網絡的每一層增加了Su等人(2021)介紹的旋轉位置嵌入(RoPE)。
2、Optimizer設計
該模型使用AdamW優化器(Loshchilov和Hutter,2017)進行訓練,超參數設置為β1=0.9,β2=0.95。
此外,使用余弦學習率方式,使最終學習率等于最大學習率的10%,并使用0.1的權重衰減和1.0的梯度剪裁。最并使用2,000個warm up策略,并根據模型的大小改變學習率和批次大小。
3、 模型加速優化
在模型訓練加速方面,該工作進行了一些優化,以提高模型的訓練速度。
首先,該工作使用了一個高效的因果多頭注意力方式的實現,靈感來自Rabe和Staats(2021)以及Dao等人(2022),這個實現可在xformers庫中找到,可以有效減少了內存的使用和計算。
具體原理為通過不存儲注意力權重和不計算由于語言建模任務的因果性質而被掩蓋的鍵/查詢分數來實現的。
其次,為了進一步提高訓練效率,減少了在check point的后向傳遞中重新計算的激活量,在實現上,通過手動實現trasnformer層的后向函數來進行操作。為了充分受益于這種優化,還通過如Korthikanti等人(2022)中采用的方法,進行使用模型和序列并行來減少模型的內存使用。
最后,該工作還盡可能地重疊激活的計算和GPU之間在網絡上的通信。
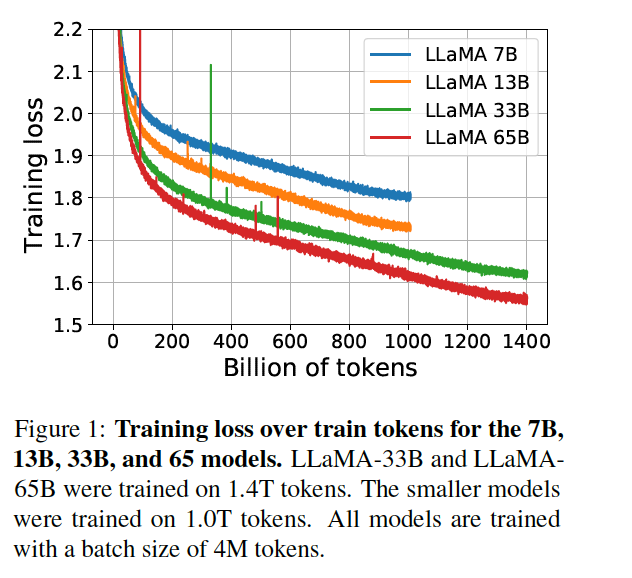
因此,最終的優化性能效果為:當訓練一個65B參數的模型時,代碼在2048A100的GPU上處理大約380個token/秒/GPU,并耗費80GB的內存,這意味著對包含1.4Ttoken的數據集進行訓練大約花費了21天。
四、實驗結果分析:zero shot與few shot性能對比測試
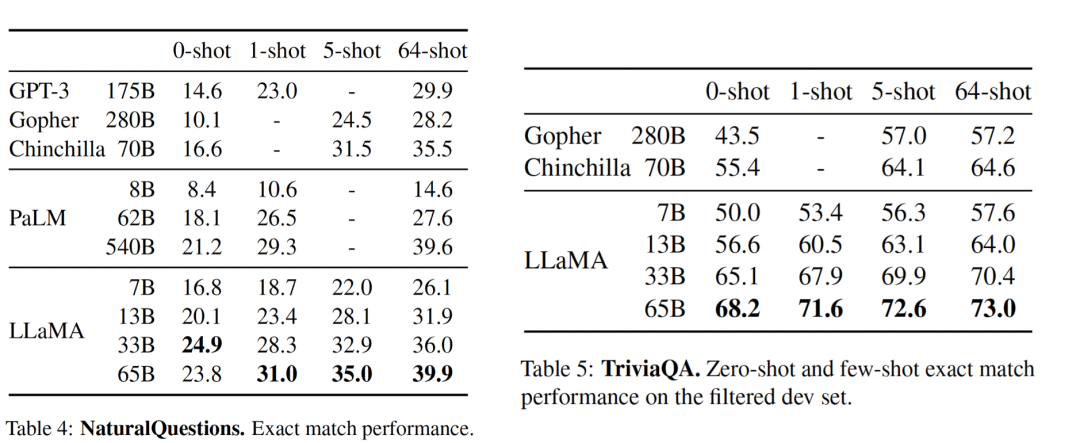
按照以前的工作(Brown等人,2020年),該工作選擇了zero-shot和 few-shot的任務,并報告了總共20個基準的結果,如表4、5所示:
其中:
zero-shot任務指的是提供了任務的文字描述和一個測試例子,該任務要么使用開放式生成提供一個答案,要么對提議的答案進行排序。
Few-shot任務指的是提供任務的幾個例子(1到64個之間)和一個測試例子。該任務將這些文本作為輸入,并生成答案或對不同的選項進行排序。
在模型對比上,將LLaMA與其他基礎模型進行比較,包括:公開的語言模型GPT-3(Brown等人,2020)、Gopher(Rae)和Lauren等人。2020)、Gopher(Raeet al.,2021)、Chinchilla(Hoffmann等,2022)和PaLM(Chowdhery等,2022),以及開源的OPT模型(Zhang等,2022)、GPT-J(Wang和Komatsuzaki,2021)和GPTneo(Black等,2022)。
此外,該工作還簡要比較了LLaMA與OPT-IML(Iyer等人,2022)和Flan-PaLM(Chung等人,2022)等指令微調模型。
1、Common Sense Reasoning評測
該工作選擇了八個標準的常識推理基準:BoolQ(Clark等人,2019),PIQA(Bisk等人,2020),SIQA(Sap等人,2019),HellaSwag(Zellers等人,2019),WinoGrande(Sakaguchiet al.,2021),ARC easy and challenge(Clarket al.,2018)和OpenBookQA(Mihaylov等,2018)。
這些數據集包括Cloze和Winograd style的任務,以及多選題回答。
如表3所示:
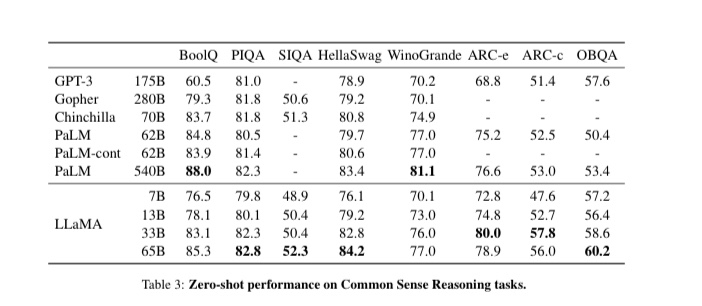
LLaMA-65B在所有報告的基準上都優于Chinchilla-70B,但BoolQ除外。
該模型除了在BoolQ和WinoGrande上,在其他地方都超過了PaLM-540B。
也就是說,LLaMA-13B模型在大多數基準上也超過了GPT-3,盡管它要小10倍。
2、Closed-book Question Answering評測
閉卷答題測評任務指的是閉卷情況下的精確匹配性能,即模型不能訪問包含回答問題的證據的文件。
表4和表5分別展示了NaturalQuestions以及TriviaQA的性能。
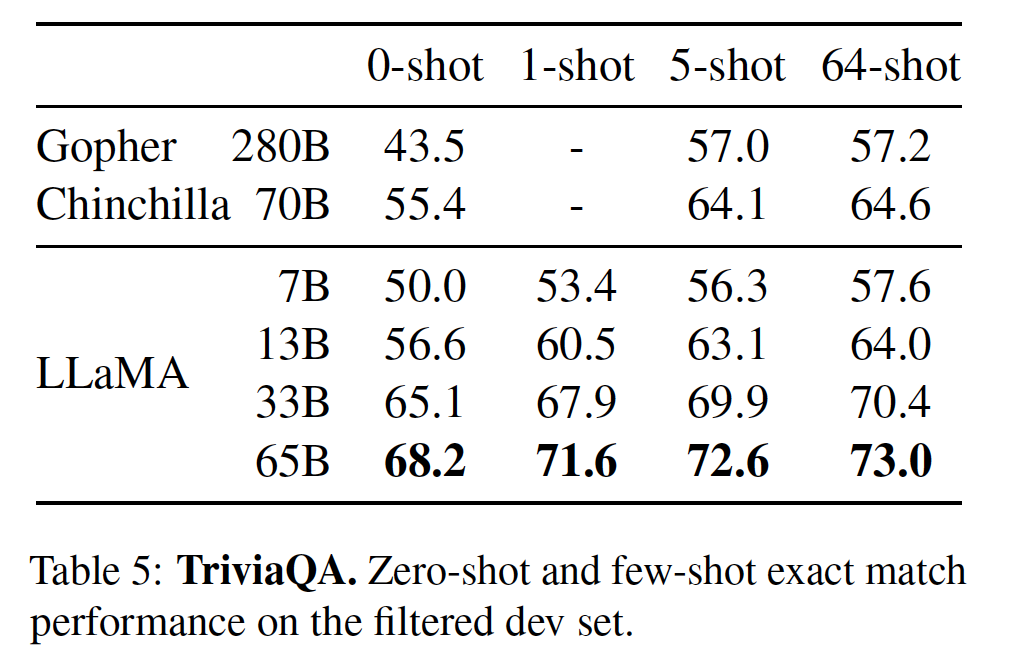
結果發現:
LLaMA-65B在0-sot和少數sot設置中都達到了最先進的性能。更重要的是,LLaMA-13B在這些基準測試中與GPT-3和Chinchilla相比也很有競爭力,盡管其體積小了5-10倍。
在推理過程中,該模型在單個V100 GPU上運行。
3、Reading Comprehension評測
RACE閱讀理解評測指的是從為中國初中和高中學生設計的英語閱讀理解考試,效果如表6所示:
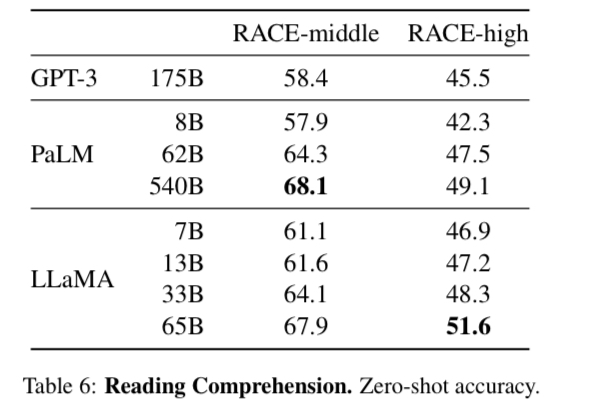
LLaMA-65B與PaLM-540B具有競爭力,LLaMA-13的性能比GPT-3好幾個百分點。
4、Mathematical reasoning評測
為了驗證模型的推理能力,該工作在兩個數學推理基準上MATH(Hendrycks等人,2021)和GSM8k(Cobbe等人,2021)進行了測試。
其中,MATH是一個用LaTeX編寫的12K初中和高中數學問題的數據集。GSM8k是一套初中數學問題。
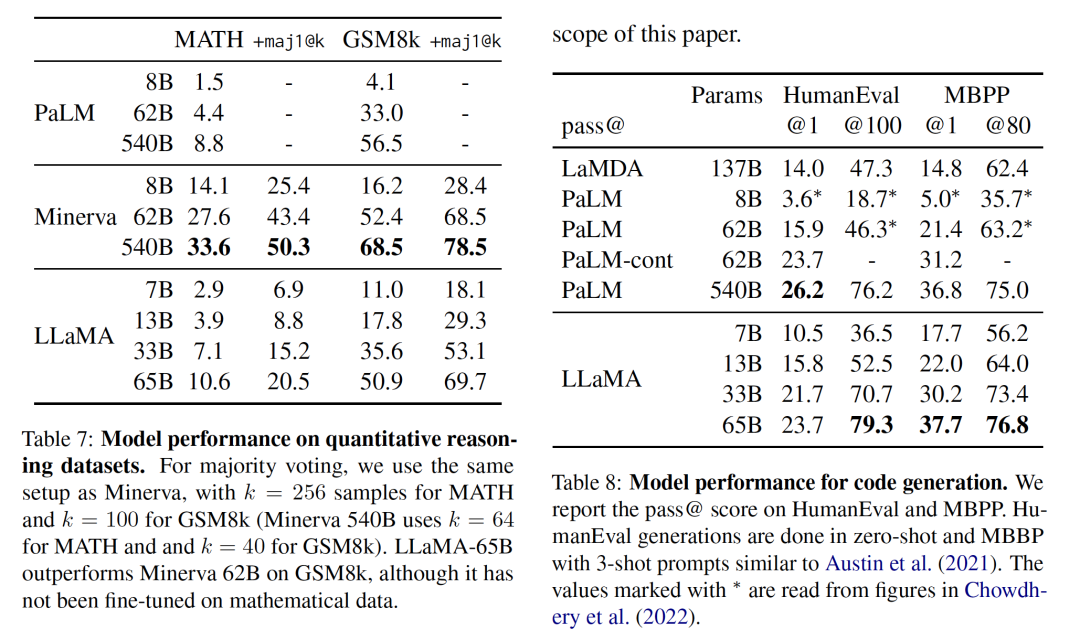
表7顯示了與PaLM和Minerva(Lewkowycz等人,2022)的測試效果。
Minerva是在從ArXiv和Math網頁中提取的38.5B個符號上進行微調的一系列PaLM模型,而PaLM或LaMA都是在數學數據上進行微調的。
指標maj1@k表示對每個問題產生k個樣本并進行多數投票的評價(Wanget al., 2022)。在GSM8k上,可以發現,盡管還沒有在數學數據上進行微調,LLaMA-65B優于Minerva-62B。
5、Code generation評測
該工作在兩個基準上評估了模型從自然語言描述中寫入代碼的能力,包括HumanEval(Chen等人,2021)和MBPP(Austin等人,2021)兩個測評。
其中,在HumanEval測試中,它會收到一個函數簽名,提示被格式化為自然碼,并在docstring中提供文本描述和測試。該模型需要生成一個符合描述并滿足測試案例的Python程序。
表8顯示了當前模型與現有沒有經過代碼微調的語言模型,即PaLM和LaMDA(Thopilan等人,2022)的比較結果,其中:pass@1的結果通過溫度為0.1的采樣,pass@100和pass@80的指標通過溫度為0.8時得到,性能如下:
對于類似的參數數量,LLaMA優于其他通用模型,如LaMDA和PaLM,它們沒有專門針對代碼進行訓練或微調。
LLaMA在HumanEval和MBPP上以13B以上的參數優于LaMDA 137B。
即使它的訓練時間更長,LLaMA 65B也優于PaLM 62B。
6、Massive Multitask Language Understanding評測
由Hendryckset al.(2020)介紹的大規模多任務語言理解基準,或稱MMLU,由涵蓋各種知識領域的多項選擇題組成,包括人文、STEM和社會科學。
該工作在5-shot的環境中進行了模型評估,效果如,表9所示:
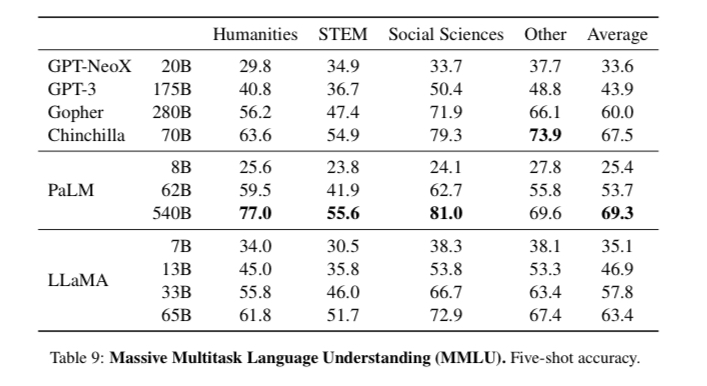
LLaMA-65B在大多數領域都比Chinchilla-70B和PaLM-540B平均落后幾個百分點。
一個潛在的解釋是,該模型在預訓練數據中使用了有限的書籍和學術論文,即ArXiv、Gutenberg和Books3,總共只有177GB,而這些模型是在高達2TB的書籍上訓練的。
因此,Gopher、Chinchilla和PaLM所使用的大量書籍可能也解釋了為什么Gopher在這個基準上優于GPT-3,而在其他基準上卻不相上下。
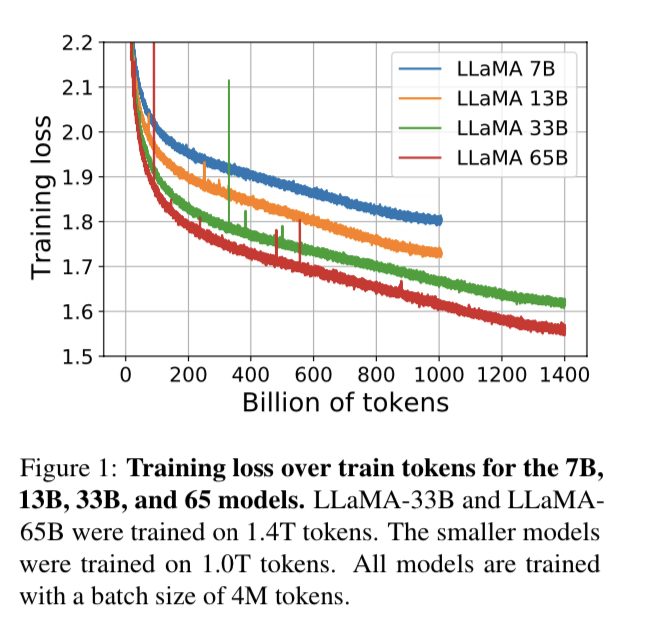
7、Evolution of performance during training評測
此外。該工作還跟蹤了在訓練過程中,模型在一些問題回答和常識性基準上的表現,并如圖1、2所示:
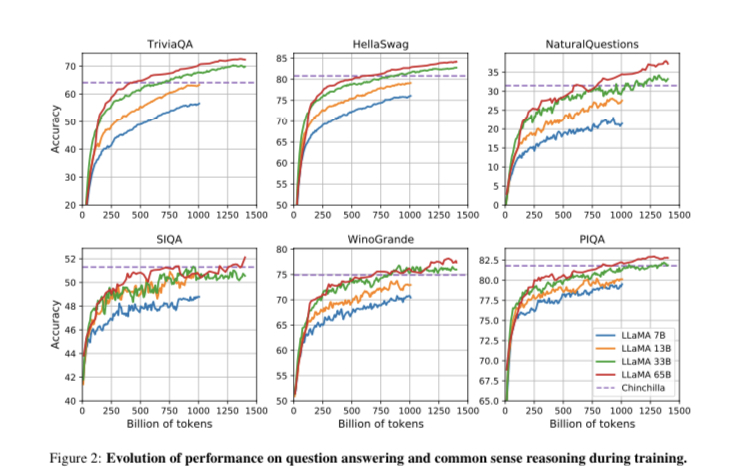
在大多數基準上,性能很快就會提高,并與模型的訓練困惑度相關。
不過,SIQA和WinoGrande很例外,最值得注意的是,在SIQA上,該工作發現很多性能上的差異,這可能表明這個基準并不可靠。
此外,在WinoGrande上,性能與訓練困惑度的相關性不大:LLaMA-33B和LLaMA-65B在訓練期間的性能相似。
五、Instruction Finetuning下帶來的性能測試
Instruction Finetuning的實驗表明:
盡管非微調版本的LLaMA-65B已經能夠遵循基本指令,但非常小的微調就能提高MMLU的性能,并進一步提高模型遵循指令的能力。
由于這不是本文的重點,該工作只進行了一次實驗,在模型上采用與Chung等人(2022)相同的方法訓練一個指令模型,得到LLaMA-I。
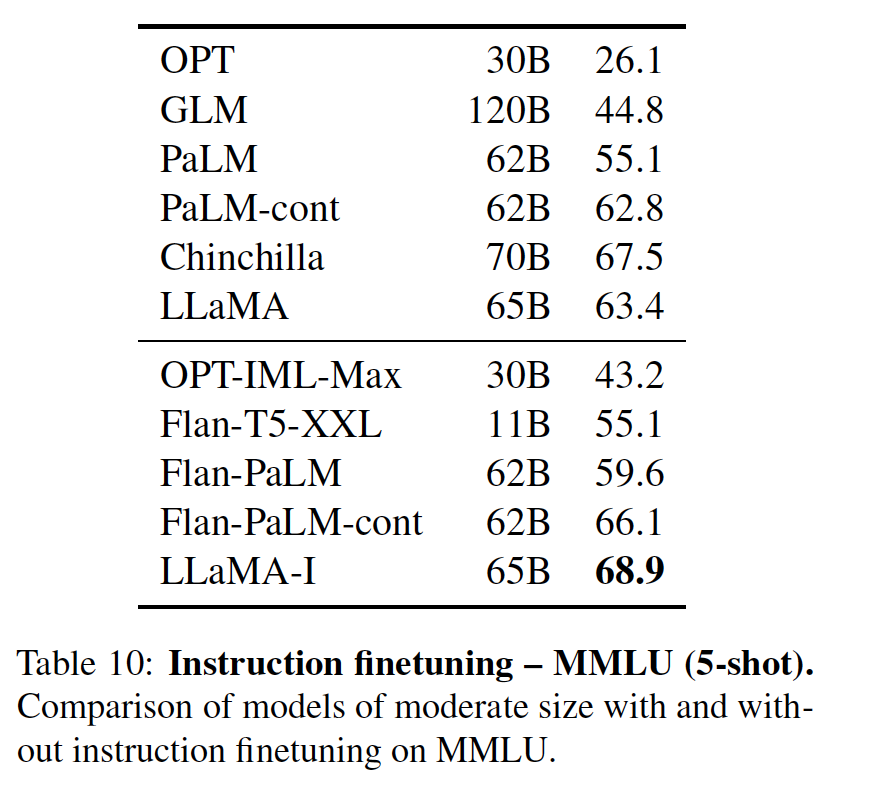
表10顯示了微調模型LLaMA-I在MMLU評測上與現有的中等規模的指令微調模型,即OPT-IML(Iyer等人,2022)和Flan-PaLM系列(Chung等人,2022)的結果。
正如表中所示:
盡管這里使用的指令微調方法很簡單,但該模型在MMLU上達到了68.9%。
LLaMA-I(65B)在MMLU上超過了現有的中等規模的指令微調模型,但離最先進的水平有較大的差距,即GPT代碼-DAVINCI-002在MMLU上的表現為77.4%(數字取自Iyer等人(2022))。
六、Bias, Toxicity and Misinformation上的分析測試
大型語言模型已被證明可以重現和放大訓練數據中存在的偏見(Sheng等人,2019年;Kurita等人,2019年),并產生有毒或攻擊性內容(Gehman等人,2020年)。
由于該模型訓練數據集包含了很大一部分來自網絡的數據,因此,評估模型產生這種內容的可能性是至關重要的。
為了了解LLaMA-65B的潛在危害,該工作在不同的基準上進行評估,這些基準衡量了有毒內容的產生和刻板印象的檢測。
1、RealToxicityPrompts毒性測試
語言模型可以產生有毒的語言,例如,侮辱、仇恨言論或威脅。一個模型可以產生的有毒內容范圍非常大,這使得徹底的評估具有挑戰性。
最近的一些工作(Zhang等人,2022;Hoffmann等人,2022)已經考慮了RealToxicityPrompts基準(Gehman等人,2020)作為他們的模型的毒性指標。
RealToxicityPrompts由模型必須完成的大約10萬個提示組,;然后通過向PerspectiveAPI 3提出請求來自動評估毒性分數。
但由于無法控制第三方PerspectiveAPI使用的流程,因此很難與以前的模型進行比較,所以僅進行了單一模型實驗,每個提示的得分范圍從0(無毒)到1(有毒),結果如表11所示:
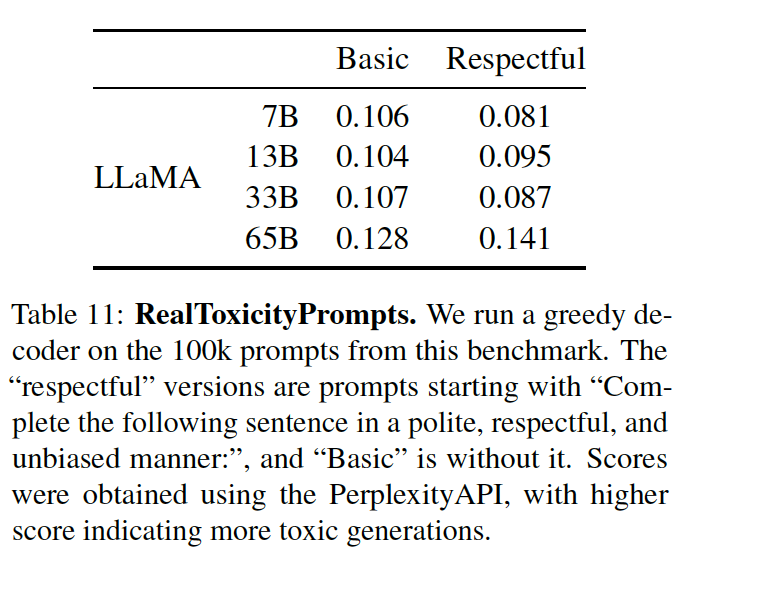
可以看到,毒性隨著模型的大小而增加,特別是對于尊重提示,這在以前的工作中也觀察到了(Zhang等人,2022),但Hoffmann等人(2022)是個明顯的例外,他們沒有看到Chinchilla和Gopher之間的差異。
不過,這可以解釋為較大的模型Gopher的性能比Chinchilla差,這表明毒性和模型大小之間的關系可能只適用于一個模型系列。
2、CrowS-Pairs社會偏見評測
在偏見測試上,該工作在CrowSPairs(Nangia等人,2020)上進行了評估。
這個數據集允許測量9個類別的偏見:性別、宗教、種族/膚色、性取向、年齡、國籍、殘疾、外貌和社會經濟地位。
每個例子都由一個刻板印象和一個反刻板印象組成,該工作在zero-shot場景下使用兩個句子的復雜度來衡量模型對刻板印象句子的偏好。
表12中顯示了該模型與GPT-3和OPT-175B的對比結果:
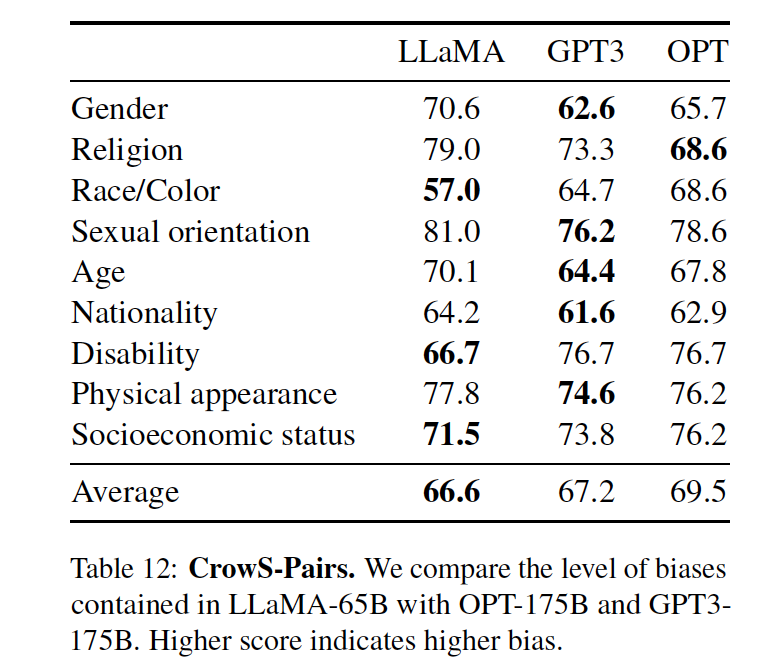
從表中的結果我們發現,該模型與這兩個模型相比,平均來說略勝一籌。
特別的,在宗教類別中特別有偏見(與OPT-175B相比+10),其次是年齡和性別(與最佳模型相比各+6)。
因此,從數據的角度上,可以發展,盡管有多個過濾步驟,預計這些偏見來自CommonCrawl,畢竟數據太雜了。
3、WinoGender性別偏見評測
為了進一步研究該模型在性別類別上的偏差,WinoGenderbenchmark(Rudinger等人,2018)數據集也作為了測評任務。
WinoGender是由Winogradschema構成的,通過確定模型的共同參考解決性能是否受到代詞性別的影響來評估偏見。
更確切地說,每個句子有三個提及:一個 "職業",一個 "參與者 "和一個 "代詞",其中代詞是共同參考職業或參與者。
該任務要求該模型確定共同參照關系,并根據句子的上下文來衡量它是否正確,其目的是揭示與職業相關的社會偏見是否被模型所捕捉。
例如,WinoGender數據集中的一個句子是 "護士通知病人,他的班將在一小時后結束。",后面的 "他的 "是指。然后,我們比較了護士和病人的連續性的困惑,用模型進行共同參考解決。
具體的,該工作評估了使用3個代詞時的表現:"her/her/she","his/him/he "和 "they/them/someone"(不同的選擇對應于代詞的語法功能。
在表13顯示了數據集中包含的三個不同代詞的共同參考得分。
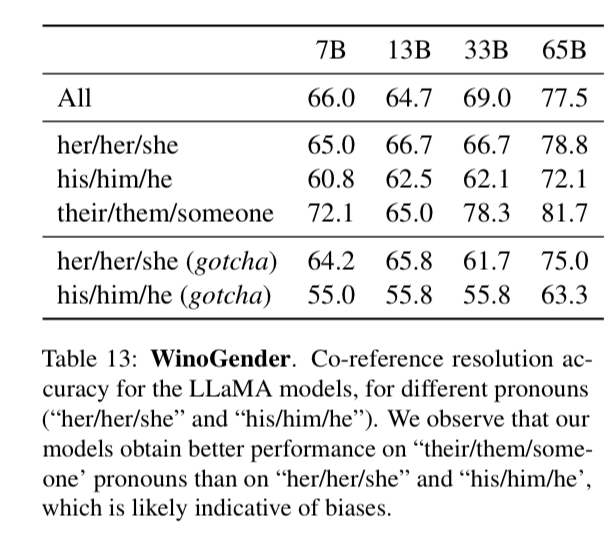
可以看到,該模型在解決 "他們/他們/某人 "代詞的共同參照方面明顯優于 "她/她/他 "和 "他/他/他 "代詞,這在以前的工作中也有類似的觀察(Raeet al., 2021; Hoffmann et al., 2022),這可能是性別偏見的表現。
事實上,在 "她/他 "和 "他/他 "代詞的情況下,模型可能使用職業的多數性別來進行共同參考解析,而不是使用句子的證據。
為了進一步研究這一假設,該工作研究了WinoGender數據庫中 "她/他 "和 "他/他 "代詞的 "疑難 "案例。這些情況對應于代詞與職業的多數性別不匹配的句子,而職業是正確答案。
進一步的,我們發現,LLaMA-65B在有問題的例子上犯了更多的錯誤,清楚地表明它捕捉到了與性別和職業有關的社會偏見。"她/她/她 "和 "他/他 "代詞的性能下降,這表明了與性別無關的偏見。
4、TruthfulQA可信度評測
TruthfulQA(Lin等人,2021)旨在衡量一個模型的真實性,即它識別一個主張是真的能力。
Lin等人(2021)認為 "真實 "的定義是指 "關于現實世界的字面意義上的真實",而不是指在信仰體系或傳統背景下才是真實的主張。這些問題以不同的風格寫成,涵蓋了38個類別,并被設計成對抗性的。
表14顯示了該模型在這兩個問題上的表現,以衡量真實的模型和真實與信息的交集。
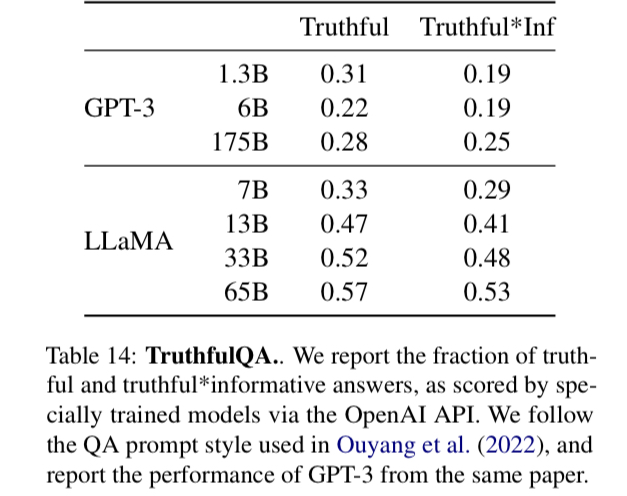
如上表所示:與GPT-3相比,模型在這兩個類別中得分較高,但正確答案的比率仍然很低,這表明我們的模型很可能會產生幻覺的錯誤答案。【這是大模型的一個通病】
七、Carbon footprint:算力強的消耗
為了進一步說明模型在訓練成本上的消耗,表15對總的能源消耗和由此產生的碳足跡進行了分類。
在計算方式上,采用Wu等人(2022)的公式來估計訓練模型所需的瓦特小時,以及碳排放噸數,tCO2eq。
具體的,對于Wh,使用的公式是:Wh=GPU-h×(GPU功耗)×PUE,其中將電源使用效率(PUE)設定為1.1。
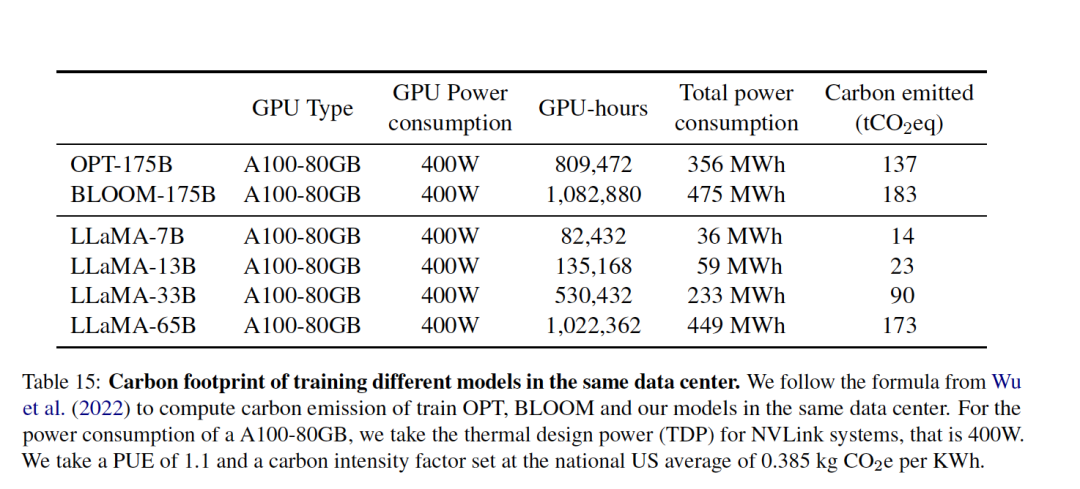
由此產生的碳排放取決于用于訓練網絡的數據中心的位置。
例如:
BLOOM使用的網格排放0.057千克二氧化碳當量/千瓦時,導致27噸二氧化碳當量;
OPT的網格排放0.231千克二氧化碳當量/千瓦時,導致82噸二氧化碳當量。
為了比較這些模型在同一數據中心訓練時的碳排放成本,該工作采用了不考慮數據中心的位置的數據,而使用美國全國平均碳強度系數0.385 kg CO2eq/KWh。
碳排放量的以下公式:tCO2eq = MWh × 0.385,
因此,可以對OPT和BLOOM采用相同的公式進行公平比較。
對于OPT,該工作假設在992個A100-80B上訓練了34天。
而在llama模型的訓練上,使用了2048個A100-80GB,大約5個月的時間的成本,根據假設,開發這些模型將花費約2638兆瓦時,總排放量為1015噸二氧化碳當量。
八、LLaMA在實際場景的效果案例
1、Generations from LLaMA-65B
下面展示了一些用LLaMA-65B(沒有指令微調)獲得的世代的例子。prompt提示用粗體字表示。



3、Generations from LLaMA-I
下圖展示了幾個用LLaMA-I生成的例子,即用Chung等人(2022)的基準和指令數據集微調的LLaMA-65B。



總結
Meta最近提出了LLaMA大規模語言模型,模型參數包括從7B到65B等多個版本,根據論文的描述,其在較小模型參數上,依舊取得了在諸多任務上超越GPT3的效果。
值得注意的是,在多個任務上,LLaMA-13B的性能優于GPT-3,而體積卻小了10倍以上,LLaMA-65B與Chinchilla-70B和PaLM-540B具有競爭性,這樣是否意味著小模型參數使用大規模數據集也是一條可以研究的方向。
與以前的研究不同,該工作通過完全在公開可用的數據上進行訓練,而不求助于專有數據集,是可以達到最先進的性能。
雖然,對于該工作的代碼和權重是否開源,開源的程度如何,需要我們再等等看,但其中對于數據的處理、選擇和加工等環節,可以有一定的參考性,比如CCNet的流程。
感興趣的,可以進一步研究開放的代碼,進一步跟進
審核編輯 :李倩
-
語言模型
+關注
關注
0文章
561瀏覽量
10714 -
數據集
+關注
關注
4文章
1223瀏覽量
25322 -
大數據
+關注
關注
64文章
8953瀏覽量
139704
原文標題:Meta最新語言模型LLaMA論文研讀:小參數+大數據的開放、高效基礎語言模型閱讀筆記
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【飛騰派4G版免費試用】仙女姐姐的嵌入式實驗室之五~LLaMA.cpp及3B“小模型”OpenBuddy-StableLM-3B
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
【大語言模型:原理與工程實踐】大語言模型的預訓練
【《大語言模型應用指南》閱讀體驗】+ 俯瞰全書
【《大語言模型應用指南》閱讀體驗】+ 基礎篇
“伶荔”(Linly) 開源大規模中文語言模型

Meta發布一款可以使用文本提示生成代碼的大型語言模型Code Llama

大語言模型簡介:基于大語言模型模型全家桶Amazon Bedrock
LLaMA 2是什么?LLaMA 2背后的研究工作
Llama 3 語言模型應用
Llama 3 模型與其他AI工具對比
用Ollama輕松搞定Llama 3.2 Vision模型本地部署






 工商網監
工商網監
評論