") 深度學(xué)習(xí)和強(qiáng)化學(xué)習(xí)的重要概念和公式
深度學(xué)習(xí)和強(qiáng)化學(xué)習(xí)的重要概念和公式
神經(jīng)網(wǎng)絡(luò)(Neural Networks)
神經(jīng)網(wǎng)絡(luò)是一類用層構(gòu)建的模型。常用的神經(jīng)網(wǎng)絡(luò)類型包括卷積神經(jīng)網(wǎng)絡(luò)和遞歸神經(jīng)網(wǎng)絡(luò)。
結(jié)構(gòu)
關(guān)于神經(jīng)網(wǎng)絡(luò)架構(gòu)的描述如下圖所示:
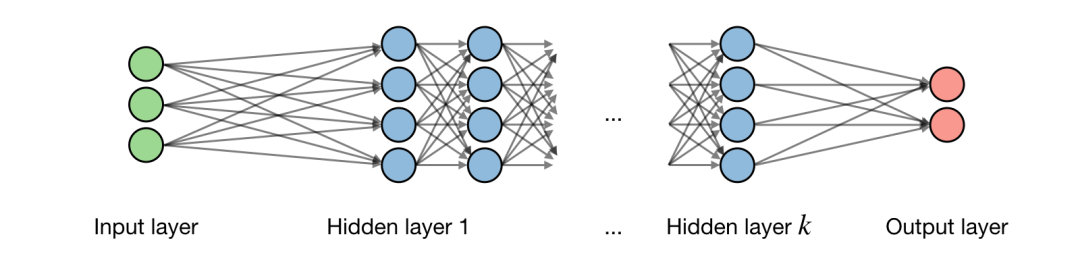
記 為網(wǎng)絡(luò)的第 層, 為一層中隱藏的第 個(gè) 單元,得到:
式中 分別表示權(quán)重,偏移和輸出。
激活函數(shù)
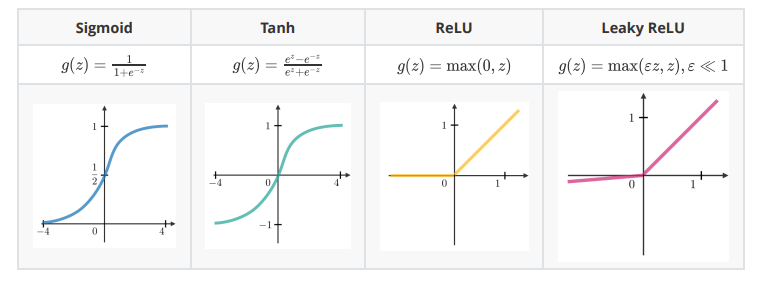
在隱含單元的末端使用激活函數(shù)向模型引入非線性復(fù)雜性。以下是最常見的幾種:
交叉熵?fù)p失(Cross-entropy loss)
在神經(jīng)網(wǎng)絡(luò)中,交叉熵?fù)p失 是常用的,定義如下:
學(xué)習(xí)率(Learning rate)
學(xué)習(xí)率通常記作 ,表示在哪一步權(quán)重得到了更新。這個(gè)可以是固定的,也可以是自適應(yīng)變化的。目前最流行的方法是 Adam,這是一種自適應(yīng)學(xué)習(xí)率的方法。
反向傳播(Backpropagation)
反向傳播是一種通過考慮實(shí)際輸出和期望輸出更新神經(jīng)網(wǎng)絡(luò)權(quán)重的方法。權(quán)重 的導(dǎo)數(shù)用鏈?zhǔn)椒▌t計(jì)算(chain rule),它的形式如下:
因此權(quán)重更新如下:
更新權(quán)重
在神經(jīng)網(wǎng)絡(luò)中,權(quán)重的更新方式如下:
第一步:對(duì)訓(xùn)練數(shù)據(jù)取一批(batch);第二步:進(jìn)行正向傳播以獲得相應(yīng)的損失;第三步:反向傳播損失,得到梯度;第四步:使用梯度更新網(wǎng)絡(luò)的權(quán)重。
丟棄(Dropout)
它是一種通過在神經(jīng)網(wǎng)絡(luò)中刪除單元來防止過度擬合訓(xùn)練數(shù)據(jù)的技術(shù)。實(shí)際應(yīng)用中,單元被刪除的概率是 ,或被保留的概率是 。
卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Networks)
卷積層需求
記 為輸入量大小, 為卷積層神經(jīng)元大小, 為 zero padding 數(shù)量,那么匹配給定體積輸入的神經(jīng)元數(shù)量 為:
批量正則化(Batch normalization)
這一步是超參數(shù)(hyperparameter) 正則化批量 。記 分別為批量值的平均值和方差,正則化表示如下:
它通常用于完全連接或卷積層之后,且在非線性層之前。目的是允許更高的學(xué)習(xí)率,減少初始化的強(qiáng)依賴。
遞歸神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Networks)
門類型(Types of gates)
以下是在我們碰到的典型遞歸神經(jīng)網(wǎng)絡(luò)中存在的不同類型的門:
| 輸入門(Input gate) | 忘記門(Forget gate) | 輸出門(Output gate) | 門(Gate) |
|---|---|---|---|
| 是否寫入神經(jīng)元? | 是否擦出神經(jīng)元? | 是否顯示神經(jīng)元? | 寫入多少 |
長(zhǎng)短期記憶網(wǎng)絡(luò)(LSTM, Long Short-Term Memory)
長(zhǎng)短期記憶網(wǎng)絡(luò)是RNN模型的一種,它通過添加“忘記”門來避免梯度消失問題。
強(qiáng)化學(xué)習(xí)與控制(Reinforcement Learning and Control)
強(qiáng)化學(xué)習(xí)的目標(biāo)是讓代理(agent)學(xué)會(huì)如何在環(huán)境中進(jìn)化。
馬爾科夫決策過程(Markov decision processes)
馬爾科夫決策過程(MDP)是一個(gè)5元組 ,其中:
是一組狀態(tài)。
是一組行為。
是 和 的狀態(tài)轉(zhuǎn)換概率。
是discount系數(shù)。
或者 是算法要最大化的獎(jiǎng)勵(lì)函數(shù)。
策略(Policy)
策略 是一個(gè)映射狀態(tài)到行為的函數(shù) 。
備注:我們說,如果給定一個(gè)狀態(tài) ,我們執(zhí)行一個(gè)給定的策略 ,得到的行為是 。
價(jià)值函數(shù)(Value function)
對(duì)于給定的策略 和狀態(tài) ,我們定義價(jià)值函數(shù)如下 :
貝爾曼方程(Bellman equation)
最優(yōu)貝爾曼方程描述了最優(yōu)策略 的價(jià)值函數(shù) :
備注:對(duì)于給定的狀態(tài) ,我們記最優(yōu)策略 為:
價(jià)值迭代算法(Value iteration algorithm)
算法包含2步:
第一步,初始化價(jià)值:
第二步,基于之前的價(jià)值進(jìn)行迭代:
最大似然估計(jì)(Maximum likelihood estimate)
狀態(tài)轉(zhuǎn)移概率的最大似然估計(jì)如下:
的行為次數(shù)
Q-learning
Q-learning是 一種無模型,公式如下:
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4811瀏覽量
103062 -
算法
+關(guān)注
關(guān)注
23文章
4702瀏覽量
94984 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4374瀏覽量
64423 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5557瀏覽量
122588 -
強(qiáng)化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
269瀏覽量
11536
原文標(biāo)題:全面整理:深度學(xué)習(xí)(ANN,CNN,RNN)和強(qiáng)化學(xué)習(xí)重要概念和公式
文章出處:【微信號(hào):vision263com,微信公眾號(hào):新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
什么是深度強(qiáng)化學(xué)習(xí)?深度強(qiáng)化學(xué)習(xí)算法應(yīng)用分析

深度強(qiáng)化學(xué)習(xí)實(shí)戰(zhàn)
將深度學(xué)習(xí)和強(qiáng)化學(xué)習(xí)相結(jié)合的深度強(qiáng)化學(xué)習(xí)DRL
薩頓科普了強(qiáng)化學(xué)習(xí)、深度強(qiáng)化學(xué)習(xí),并談到了這項(xiàng)技術(shù)的潛力和發(fā)展方向
如何深度強(qiáng)化學(xué)習(xí) 人工智能和深度學(xué)習(xí)的進(jìn)階
深度強(qiáng)化學(xué)習(xí)你知道是什么嗎
深度強(qiáng)化學(xué)習(xí)的筆記資料免費(fèi)下載
深度強(qiáng)化學(xué)習(xí)的概念和工作原理的詳細(xì)資料說明
深度強(qiáng)化學(xué)習(xí)到底是什么?它的工作原理是怎么樣的
DeepMind發(fā)布強(qiáng)化學(xué)習(xí)庫(kù)RLax
模型化深度強(qiáng)化學(xué)習(xí)應(yīng)用研究綜述

基于深度強(qiáng)化學(xué)習(xí)仿真集成的壓邊力控制模型
基于深度強(qiáng)化學(xué)習(xí)的無人機(jī)控制律設(shè)計(jì)方法
《自動(dòng)化學(xué)報(bào)》—多Agent深度強(qiáng)化學(xué)習(xí)綜述

ESP32上的深度強(qiáng)化學(xué)習(xí)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論