 AI大語言模型的原理、演進及算力測算專題報告
AI大語言模型的原理、演進及算力測算專題報告

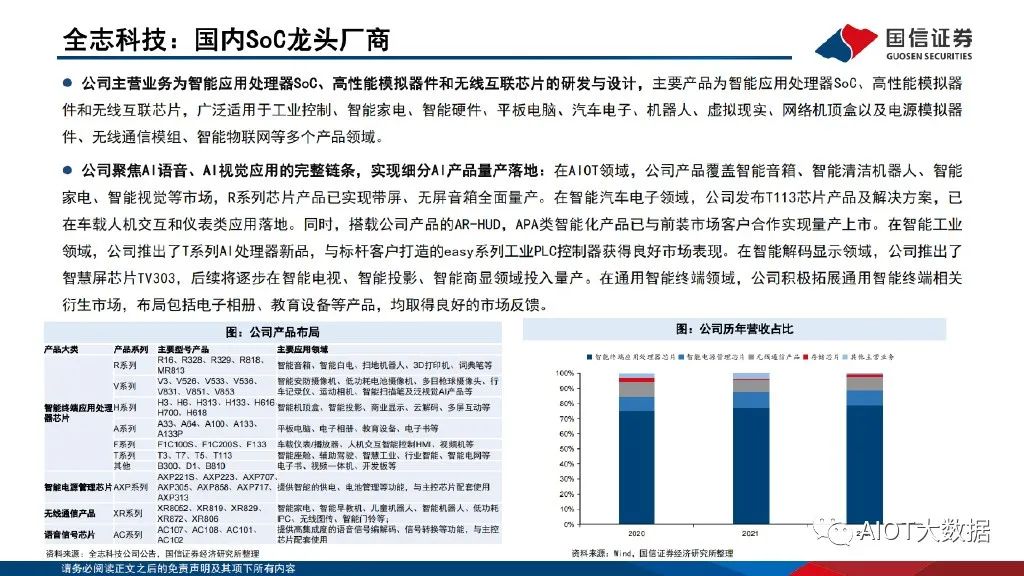
核心觀點:
機器學習中模型及數據規模增加有利于提高深度神經網絡性能。人工智能致力于研究能夠模擬、延伸和擴展人類智能的理論方法及技術,并開發相關應用系統;其最終目標是使計算機能夠模擬人的思維方 式和行為。機器學習是一門專門研究計算機如何模擬或實現人類的學習行為、以獲取新的知識或技能、重新組織已有的知識結構使之不斷改 善自身性能的學科,廣泛應用于數據挖掘、計算機視覺、自然語言處理等領域。深度學習是機器學習的子集,主要由人工神經網絡組成。與 傳統算法及中小型神經網絡相比,大規模的神經網絡及海量的數據支撐將有效提高深度神經網絡的表現性能。
Transformer模型架構是現代大語言模型所采用的基礎架構。Transformer模型是一種非串行的神經網絡架構,最初被用于執行基于上下文的機器翻譯任務。Transformer模型以Encoder-Decoder架構為基 礎,能夠并行處理整個文本序列,同時引入“注意機制”(Attention),使其能夠在文本序列中正向和反向地跟蹤單詞之間的關系,適合在 大規模分布式集群中進行訓練,因此具有能夠并行運算、關注上下文信息、表達能力強等優勢。
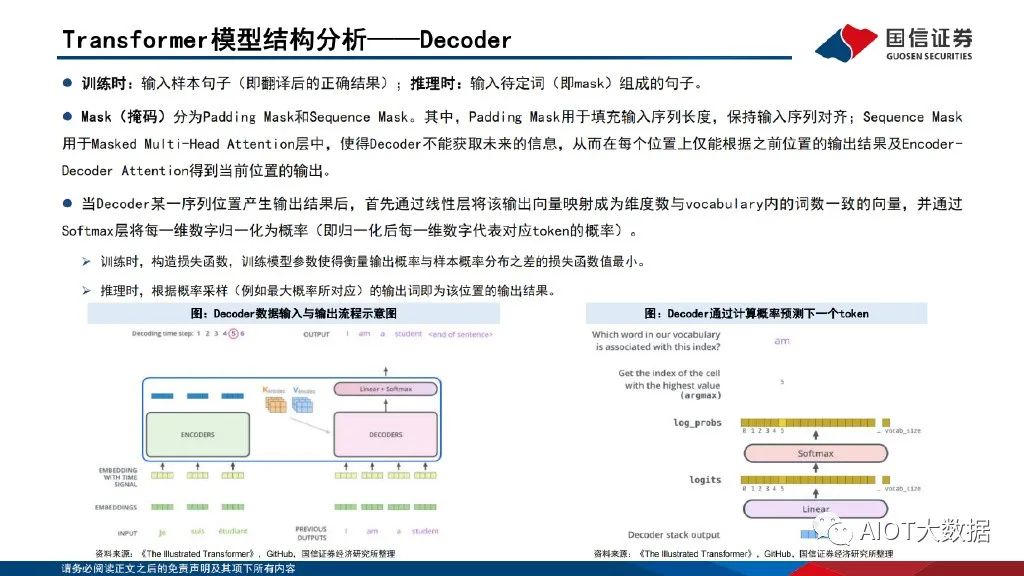
Transformer模型以詞嵌入向量疊加位置編碼 作為輸入,使得輸入序列具有位置上的關聯信息。編碼器(Encoder)由Self-Attention(自注意力層)和 Feed Forward Network(前饋網 絡)兩個子層組成,Attention使得模型不僅關注當前位置的詞語,同時能夠關注上下文的詞語。解碼器(Decoder)通過Encoder-Decoder Attention層,用于解碼時對于輸入端編碼信息的關注;利用掩碼(Mask)機制,對序列中每一位置根據之前位置的輸出結果循環解碼得到當 前位置的輸出結果。
GPT是基于Transformer架構的大語言模型,近年迭代演進迅速。構建語言模型是自然語言處理中最基本和最重要的任務之一。GPT是基于Transformer架構衍生出的生成式預訓練的單向語言模型,通過對大 量語料數據進行無監督學習,從而實現文本生成的目的;在結構上僅采用Transformer架構的Decoder部分。自2018年6月OpenAI發布GPT-1模 型以來,GPT模型迭代演進迅速。GPT-1核心思想是采用“預訓練+微調”的半監督學習方法,服務于單序列文本的生成式任務;GPT-2在預訓 練階段引入多任務學習機制,將多樣化的自然語言處理任務全部轉化為語言模型問題;GPT-3大幅增加了模型參數,更能有效利用上下文信息, 性能得到跨越式提高;GPT-3.5引入人類反饋強化學習機制,通過使用人類反饋的數據集進行監督學習,能夠使得模型輸出與人類意圖一致。
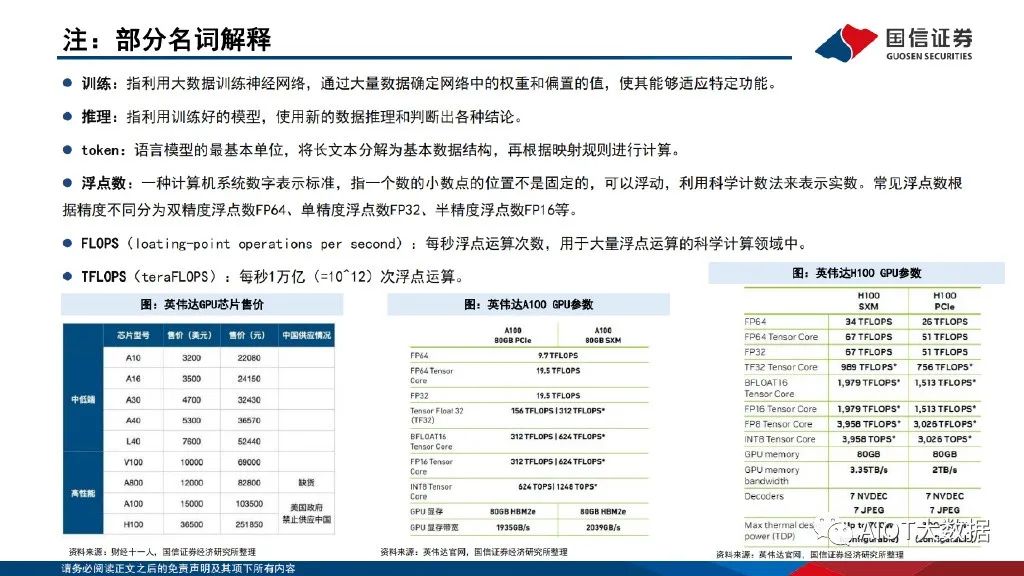
大語言模型的訓練及推理應用對算力需求帶來急劇提升。以GPT-3為例,GPT-3參數量達1750億個,訓練樣本token數達3000億個。考慮采用精度為32位的單精度浮點數數據來訓練模型及進行谷歌級訪 問量推理,假設GPT-3模型每次訓練時間要求在30天完成,對應GPT-3所需運算次數為3.15*10^23FLOPs,所需算力為121.528PFLOPS,以A100 PCle芯片為例,訓練階段需要新增A100 GPU芯片1558顆,價值量約2337萬美元;對應DGX A100服務器195臺,價值量約3880.5萬美元。假設推 理階段按谷歌每日搜索量35億次進行估計,則每日GPT-3需推理token數達7.9萬億個,所需運算次數為4.76*10^24FLOPs,所需算力為 55EFLOPs,則推理階段需要新增A100 GPU芯片70.6萬顆,價值量約105.95億美元;對應DGX A100服務器8.8萬臺,價值量約175.12億美元。
01、人工智能、機器學習與神經網絡簡介
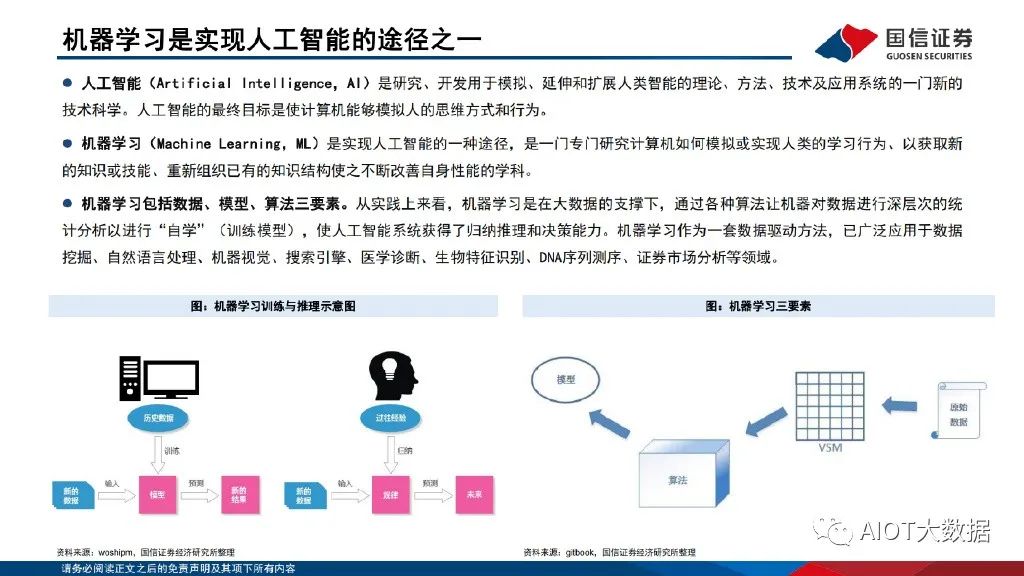
機器學習是實現人工智能的途徑之一
人工智能(Artificial Intelligence,AI)是研究、開發用于模擬、延伸和擴展人類智能的理論、方法、技術及應用系統的一門新的 技術科學。人工智能的最終目標是使計算機能夠模擬人的思維方式和行為。機器學習(Machine Learning,ML)是實現人工智能的一種途徑,是一門專門研究計算機如何模擬或實現人類的學習行為、以獲取新 的知識或技能、重新組織已有的知識結構使之不斷改善自身性能的學科。機器學習包括數據、模型、算法三要素。從實踐上來看,機器學習是在大數據的支撐下,通過各種算法讓機器對數據進行深層次的統 計分析以進行“自學”(訓練模型),使人工智能系統獲得了歸納推理和決策能力。機器學習作為一套數據驅動方法,已廣泛應用于數據 挖掘、自然語言處理、機器視覺、搜索引擎、醫學診斷、生物特征識別、DNA序列測序、證券市場分析等領域。
模型及數據規模增加有利于提高深度神經網絡性能
深度學習(Deep Learning,DL)是機器學習的子集,由人工神經網絡(ANN)組成。深度學習模仿人腦中存在的相似結構, 其學習是通過相互關聯的“神經元”的深層的、多層的“網絡”來進行的。典型的神經網絡從結構上可以分為三層:輸入層、隱藏層、輸出層。其中,輸入層(input layer)是指輸入特征向量;隱藏 層(hidden layer)是指抽象的非線性中間層;輸出層(output layer)是指輸出預測值。深層神經網絡即包含更多隱藏層的神 經網絡。相比于傳統機器學習模型,深度學習神經網絡更能在海量數據上發揮作用。若希望獲得更好的性能,不僅需要訓練一個規模 足夠大的神經網絡(即帶有許多隱藏層的神經網絡,及許多參數及相關性),同時也需要海量的數據支撐。數據的規模及神經網 絡的計算性能,需要有強大的算力作為支撐。
CNN和RNN是常見的神經網絡模型
傳統常見的神經網絡模型包括卷積神經網絡(CNN)和循環神經網絡(RNN)等。其中,卷積神經網絡(Convolutional Neural Network, CNN)多用于計算機視覺、自動駕駛、人臉識別、虛擬現實、醫學領域、人機交互、智能安防等圖像應用;相比于標準神經網絡,CNN能夠 更好地適應高緯度的輸入數據,卷積設計有效減少了模型的參數數量。循環神經網絡(Recurrent Neural Network,RNN)常用于處理序列數據,獲取數據中的時間依賴 性。由于語言都是逐個出現的,同時語言是時序前后相互關聯的數據,因此語言作為最自然表達出來的 序列數據,適合應用RNN進行語音識別、情感分類、機器翻譯、語言生成、命名實體識別等應用。
循環神經網絡(RNN)曾是自然語言處理的首選解決方案。RNN能夠在處理單詞序列時,將處理第一個詞的結果反饋到處理下一個詞的層, 使得模型能夠跟蹤整個句子而非單個單詞。但RNN存在缺點:由于這種串行結構,RNN無法對于長序列文本進行有效處理,甚至可能當初始 單詞過遠時“遺忘”相關信息。
02、Transformer模型結構分析
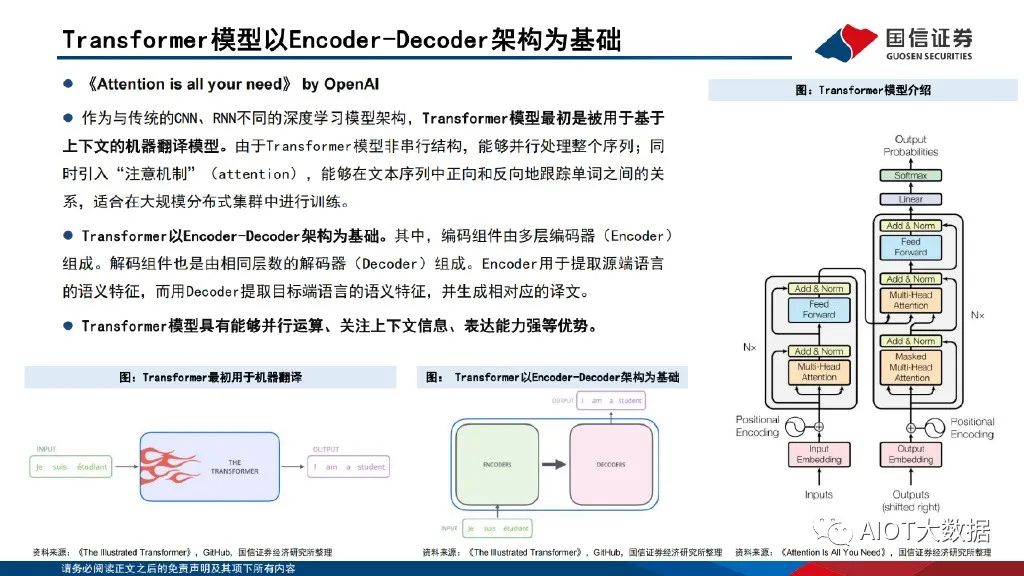
Transformer模型以Encoder-Decoder架構為基礎
《Attention is all your need》 by OpenAI 。作為與傳統的CNN、RNN不同的深度學習模型架構,Transformer模型最初是被用于基于 上下文的機器翻譯模型。由于Transformer模型非串行結構,能夠并行處理整個序列;同 時引入“注意機制”(attention),能夠在文本序列中正向和反向地跟蹤單詞之間的關 系,適合在大規模分布式集群中進行訓練。Transformer以Encoder-Decoder架構為基礎。其中,編碼組件由多層編碼器(Encoder) 組成。解碼組件也是由相同層數的解碼器(Decoder)組成。Encoder用于提取源端語言 的語義特征,而用Decoder提取目標端語言的語義特征,并生成相對應的譯文。Transformer模型具有能夠并行運算、關注上下文信息、表達能力強等優勢。
Transformer模型結構分析——詞嵌入(Embedding)
詞嵌入是NLP最基礎的概念之一,表示來自詞匯表的單詞或者短語被映射成實數向量。最早的詞嵌入模型是word2vec等神經網絡模型, 屬于靜態詞嵌入(不關注上下文)。例如大模型誕生前常用的RNN模型所用的輸入便是預訓練好的詞嵌入。詞向量能夠將語義信息與空間 向量關聯起來(例如經典的詞類比例子:king、queen、man、woman對應詞向量的關系)。詞嵌入產生要素及步驟:Vocabulary:所有的token組成集合。詞向量表:token與詞向量的一一對應關系。詞向量可以由預訓練產生,也可以是模型參數。查表:輸入的token都對應一個固定維度的浮點數向量(詞嵌入向量)。位置編碼:表示序列中詞的順序,具體方法為為每個輸入的詞添加一個位置向量。根據位置編碼對應計算公式,pos表示位置,i表示維度。位置編碼能夠讓模型學習到token之間的相對位置關系。
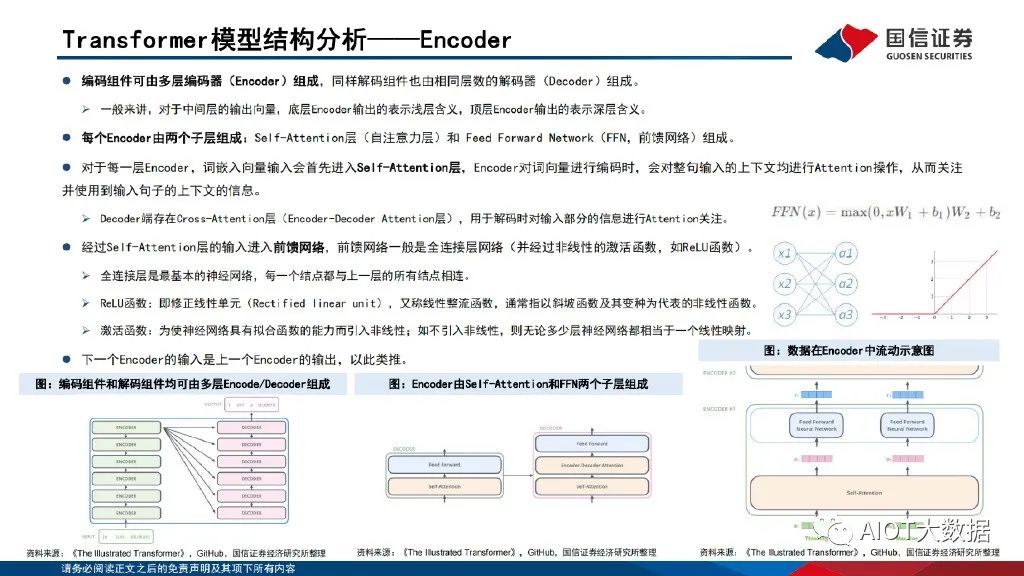
Transformer模型結構分析——Encoder
編碼組件可由多層編碼器(Encoder)組成,同樣解碼組件也由相同層數的解碼器(Decoder)組成。一般來講,對于中間層的輸出向量,底層Encoder輸出的表示淺層含義,頂層Encoder輸出的表示深層含義。每個Encoder由兩個子層組成:Self-Attention層(自注意力層)和 Feed Forward Network(FFN,前饋網絡)組成。對于每一層Encoder,詞嵌入向量輸入會首先進入Self-Attention層,Encoder對詞向量進行編碼時,會對整句輸入的上下文均進行Attention操作,從而關注 并使用到輸入句子的上下文的信息。Decoder端存在Cross-Attention層(Encoder-Decoder Attention層),用于解碼時對輸入部分的信息進行Attention關注。
經過Self-Attention層的輸入進入前饋網絡,前饋網絡一般是全連接層網絡(并經過非線性的激活函數,如ReLU函數)。全連接層是最基本的神經網絡,每一個結點都與上一層的所有結點相連。ReLU函數:即修正線性單元(Rectified linear unit),又稱線性整流函數,通常指以斜坡函數及其變種為代表的非線性函數。激活函數:為使神經網絡具有擬合函數的能力而引入非線性;如不引入非線性,則無論多少層神經網絡都相當于一個線性映射。下一個Encoder的輸入是上一個Encoder的輸出,以此類推。
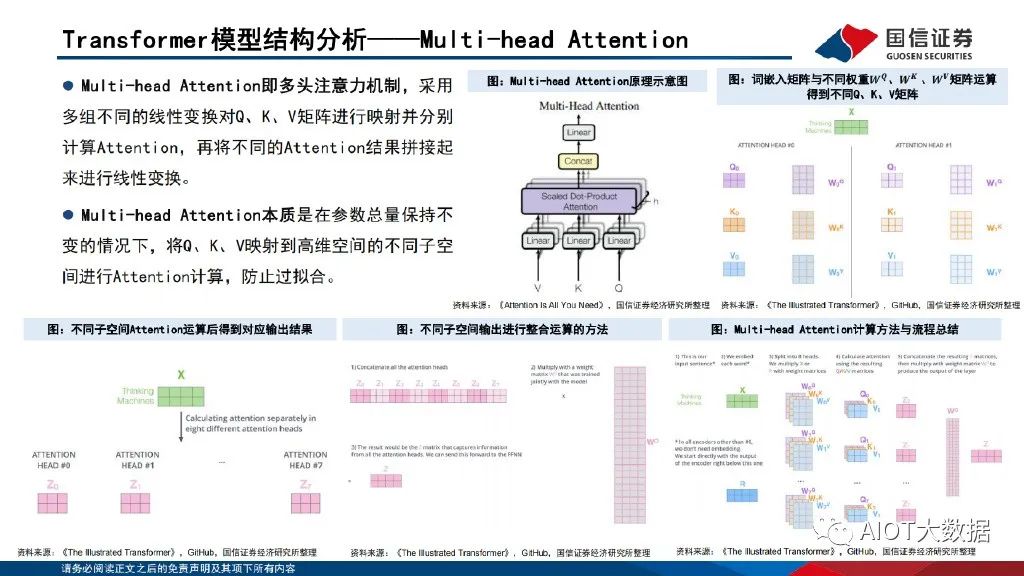
Transformer模型結構分析——Multi-head Attention
Multi-head Attention即多頭注意力機制,采用 多組不同的線性變換對Q、K、V矩陣進行映射并分別 計算Attention,再將不同的Attention結果拼接起 來進行線性變換。Multi-head Attention本質是在參數總量保持不 變的情況下,將Q、K、V映射到高維空間的不同子空 間進行Attention計算,防止過擬合。
03、大規模語言模型算力需求測算(以GPT-3為例)
BERT和GPT是基于Transformer架構的兩種大規模語言模型
構建語言模型(Language Model,LM)是自然語言處理(Natural Language Processing,NLP)中最基本和最 重要的任務之一,自然語言處理基于Transformer架構衍生出了兩種主流大語言模型(Large Language Model, LLM)——BERT和GPT。二者都是無監督預訓練的大語言模型。BERT(Bidirectional Encoder Representations from Transformer)能夠生成深度雙向語言表征,是采用帶 有掩碼(mask)的大語言模型,類似于完形填空,根據上下文預測空缺處的詞語。結構上,BERT僅采用Transformer 架構的Encoder部分。
GPT(Generative Pre-training Transformer)是生成式預訓練的單向語言模型。通過對大量語料數據進行無 監督學習,從而實現文本生成的目的。結構上,GPT僅采用Transformer架構的Decoder部分。自2018年6月起OpenAI發布GPT-1模型以來,GPT更新換代持續提升模型及參數規模。隨著OpenAI于2022年11月30 日發布ChatGPT引爆AI領域,海內外科技公司紛紛宣布發布大語言模型。用戶爆發式增長對大語言模型的算力需求帶 來挑戰。
GPT-1:預訓練+微調的半監督學習模型
《Improving Language Understanding by Generative Pre-Training》 by OpenAI。GPT-1是生成式預訓練模型,核心思想是“預訓練+微調”的半監督學習方法,目標是服務于單序列文本的生成式任務。生成式:表示模型建模的是一段句子出現的概率,可以分解為基于語言序列前序已出現單詞條件下后一單詞出現的條件概率之乘積。四大常見應用:分類、蘊含、相似、選擇,分類:每段文本具有對應標號,將文本按標 號進行分類 ,蘊含:給出一段文本和假設,判斷該段文本 中是否蘊含該假設,相似:判斷兩段文本是否相似(用于搜索、 查詢、去重等) ,選擇:對有多個選項的問題進行回答。
GPT-2:強調多任務的預訓練模型
《Language Models are Unsupervised Multitask Learners》 by OpenAI,預訓練+微調的范式只能對于特定自然語言處理任務(例如問答、機器翻譯、閱讀理解、提取摘要等)使用特定的數據集 進行有監督學習,單一領域數據集缺乏對多種任務訓練的普適性。GPT-2在預訓練階段便引入多任務學習機制,通過加入各種NLP 任務所需要的數據集,在盡可能多的領域和上下文中收集屬于對 應任務的自然語言。由此得到的GPT-2模型可以以zero-shot的方 式被直接應用于下游任務,而無需進行有監督的精調。GPT-2將多樣化的的NLP任務全部轉化為語言模型問題。語言提 供了一種靈活的方式來將任務,輸入和輸出全部指定為一段文本。對文本的生成式建模就是對特定任務進行有監督學習。
GPT-3:能夠舉一反三的大語言模型
《Language Models are Few-Shot Learners》 by OpenAI。相比GPT-2,GPT-3大幅增加了模型參數。GPT-3是具有1750億個參數的自回歸語言模型,更能有效利用上下文 信息。對于特定的下游任務,GPT-3無需進行任何梯度更新或微調,僅需通過與模型交互并提供少量范例即可。特點:1、模型規模急劇增加(使得模型性能提升迅猛);2、實現few-shot learning。in-context learning:對模型進行引導,使其明白應輸出什么內容。Q:你喜歡吃蘋果嗎?A1:我喜歡吃。A2:蘋果是什么?A3:今天天氣真好。A4:Do you like eating apples? 采用prompt提示語:漢譯英:你喜歡吃蘋果嗎?請回答:你喜歡吃蘋果嗎?
GPT-3模型對GPU與AI服務器需求展望
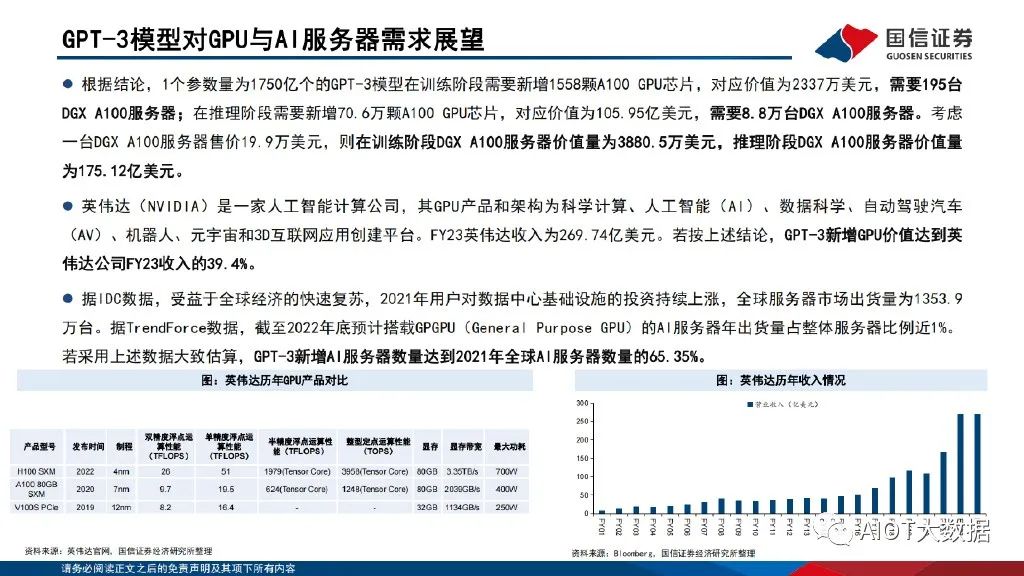
根據結論,1個參數量為1750億個的GPT-3模型在訓練階段需要新增1558顆A100 GPU芯片,對應價值為2337萬美元,需要195臺 DGX A100服務器;在推理階段需要新增70.6萬顆A100 GPU芯片,對應價值為105.95億美元,需要8.8萬臺DGX A100服務器。考慮 一臺DGX A100服務器售價19.9萬美元,則在訓練階段DGX A100服務器價值量為3880.5萬美元,推理階段DGX A100服務器價值量 為175.12億美元。英偉達(Nvidia)是一家人工智能計算公司,其GPU產品和架構為科學計算、人工智能(AI)、數據科學、自動駕駛汽車 (AV)、機器人、元宇宙和3D互聯網應用創建平臺。FY23英偉達收入為269.74億美元。若按上述結論,GPT-3新增GPU價值達到英 偉達公司FY23收入的39.4%。
據IDC數據,受益于全球經濟的快速復蘇,2021年用戶對數據中心基礎設施的投資持續上漲,全球服務器市場出貨量為1353.9 萬臺。據TrendForce數據,截至2022年底預計搭載GPGPU(General Purpose GPU)的AI服務器年出貨量占整體服務器比例近1%。若采用上述數據大致估算,GPT-3新增AI服務器數量達到2021年全球AI服務器數量的65.35%。
報告節選:
















審核編輯 :李倩
-
神經網絡
+關注
關注
42文章
4814瀏覽量
103426 -
AI
+關注
關注
88文章
34998瀏覽量
278683 -
語言模型
+關注
關注
0文章
561瀏覽量
10771 -
機器學習
+關注
關注
66文章
8500瀏覽量
134502
原文標題:AI大語言模型的原理、演進及算力測算專題報告
文章出處:【微信號:AIOT大數據,微信公眾號:AIOT大數據】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
算力網絡的“神經突觸”:AI互聯技術如何重構分布式訓練范式

明晚開播 | 數據智能系列講座第6期:大模型革命背后的算力架構創新

RAKsmart高性能服務器集群:驅動AI大語言模型開發的算力引擎
DeepSeek推動AI算力需求:800G光模塊的關鍵作用
存力接棒算力,慧榮科技以主控技術突破AI存儲極限

中興通訊在AI算力領域的創新實踐與深度思考
AI 算力報告來了!2025中國AI算力市場將達 259 億美元


中國算力大會召開,業界首個算力高質量評估體系發布






 工商網監
工商網監
評論