") Meta開源I-JEPA,“類人”AI模型
Meta開源I-JEPA,“類人”AI模型
Meta宣布推出一個全新的AI 模型Image Joint Embedding Predictive Architecture (I-JEPA),可通過對圖像的自我監(jiān)督學(xué)習(xí)來學(xué)習(xí)世界的抽象表征,實現(xiàn)比現(xiàn)有模型更準(zhǔn)確地分析和完成未完成的圖像。
目前相關(guān)的訓(xùn)練代碼和模型已開源,I-JEPA 論文則計劃在下周的 CVPR 2023 上發(fā)表。
根據(jù)介紹,I-JEPA 結(jié)合了 Meta 首席 AI 科學(xué)家 Yann LeCun 所提倡的類人推理方式,幫助避免 AI 生成圖像常見的一些錯誤,比如多出的手指。
I-JEPA 在多項計算機視覺任務(wù)上表現(xiàn)出色,且計算效率比其他廣泛使用的計算機視覺模型高得多。
I-JEPA 學(xué)習(xí)的表征也可以用于許多不同的應(yīng)用程序,而無需進行大量微調(diào)。
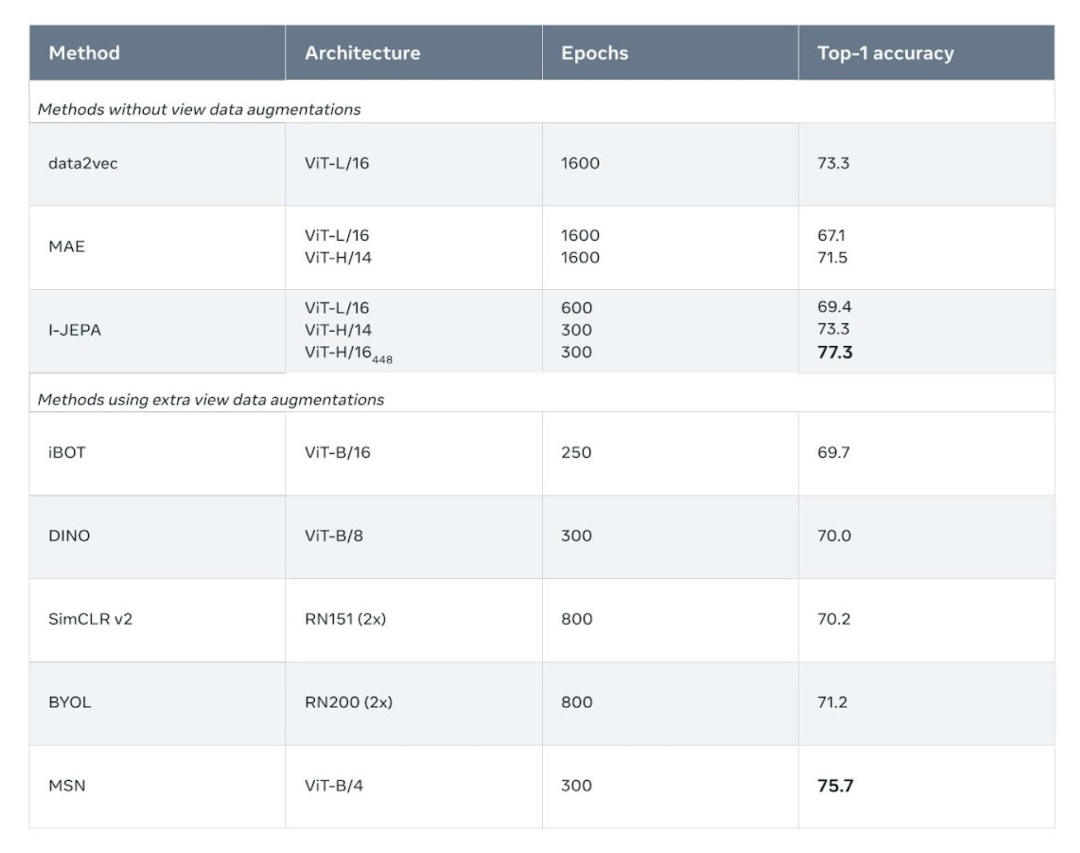
例如,項目團隊在 72 小時內(nèi)使用 16 個 A100 GPU 訓(xùn)練了一個 632M 參數(shù)的視覺轉(zhuǎn)換器模型,I-JEPA 在 ImageNet 上的 low-shot 分類中性能表現(xiàn)最優(yōu),每個類只有 12 個標(biāo)記示例。
其他方法通常需要 2 到 10 倍的 GPU 時間,并且在用相同數(shù)量的數(shù)據(jù)進行訓(xùn)練時錯誤率更高。 I-JEPA 背后的想法是以更類似于人類一般理解的抽象表示來預(yù)測缺失的信息。
I-JEPA 使用抽象的預(yù)測目標(biāo),潛在地消除了不必要的 pixel-level 細節(jié),從而使模型學(xué)習(xí)更多語義特征。
另一個引導(dǎo) I-JEPA 產(chǎn)生語義表征的核心設(shè)計選擇是多塊掩碼策略。
具體來說,項目團隊證明了使用信息豐富的(空間分布的)上下文來預(yù)測包含語義信息(具有足夠大的規(guī)模)的大塊的重要性。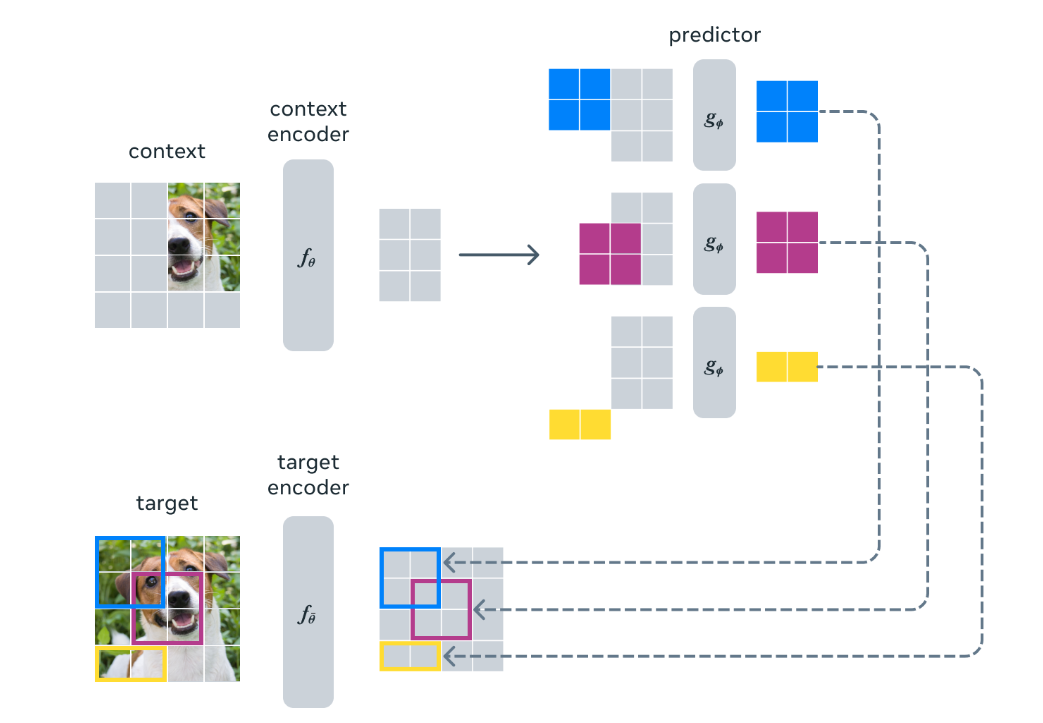
I-JEPA 中的預(yù)測器可以看作是一個原始的(和受限的)世界模型,它能夠從部分可觀察的上下文中模擬靜態(tài)圖像中的空間不確定性。
更重要的是,這個世界模型是語義的,因為它預(yù)測圖像中不可見區(qū)域的高級信息,而不是 pixel-level 細節(jié)。
為了解模型捕獲的內(nèi)容,團隊還訓(xùn)練了一個隨機解碼器,將 I-JEPA 預(yù)測的表征映射回像素空間。
這種定性評估表明該模型正確地捕獲了位置不確定性并生成了具有正確姿勢的高級對象部分(例如,狗的頭、狼的前腿)。
簡而言之,I-JEPA 能夠?qū)W習(xí)對象部分的高級表示,而不會丟棄它們在圖像中的局部位置信息。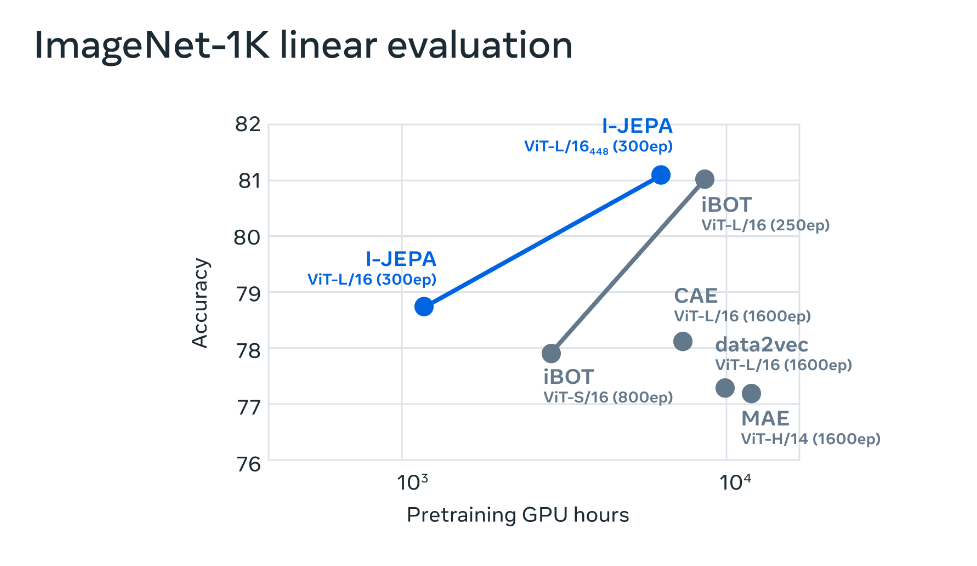
審核編輯:劉清
-
轉(zhuǎn)換器
+關(guān)注
關(guān)注
27文章
8987瀏覽量
151082 -
gpu
+關(guān)注
關(guān)注
28文章
4923瀏覽量
130830 -
計算機視覺
+關(guān)注
關(guān)注
9文章
1706瀏覽量
46628
原文標(biāo)題:Meta開源I-JEPA,“類人” AI 模型
文章出處:【微信號:OSC開源社區(qū),微信公眾號:OSC開源社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
大象機器人攜手進迭時空推出 RISC-V 全棧開源六軸機械臂產(chǎn)品
AI開源模型庫有什么用
Meta重磅發(fā)布Llama 3.3 70B:開源AI模型的新里程碑





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論