") 幻方量化發(fā)布了國(guó)內(nèi)首個(gè)開(kāi)源MoE大模型—DeepSeekMoE
幻方量化發(fā)布了國(guó)內(nèi)首個(gè)開(kāi)源MoE大模型—DeepSeekMoE

幻方量化旗下組織深度求索發(fā)布了國(guó)內(nèi)首個(gè)開(kāi)源 MoE 大模型 ——DeepSeekMoE,全新架構(gòu),免費(fèi)商用。
今年 4 月,幻方量化發(fā)布公告稱,公司將集中資源和力量,全力投身到服務(wù)于全人類(lèi)共同利益的人工智能技術(shù)之中,成立新的獨(dú)立研究組織,探索 AGI 的本質(zhì)。幻方將這個(gè)新組織命名為 “深度求索 (DeepSeek)”。
DeepSeekMoE 的模型、代碼、論文均已同步發(fā)布。
模型下載:https://huggingface.co/deepseek-ai
微調(diào)代碼:https://github.com/deepseek-ai/DeepSeek-MoE
技術(shù)報(bào)告:https://github.com/deepseek-ai/DeepSeek-MoE/blob/main/DeepSeekMoE.pdf
據(jù)介紹,DeepSeekMoE 的多尺度(2B->16B->145B)模型效果均領(lǐng)先:
DeepSeekMoE-2B 可接近 MoE 模型的理論上限2B Dense 模型性能(即相同 Attention/FFN 參數(shù)配比的 2B Dense 模型),僅用了 17.5% 計(jì)算量
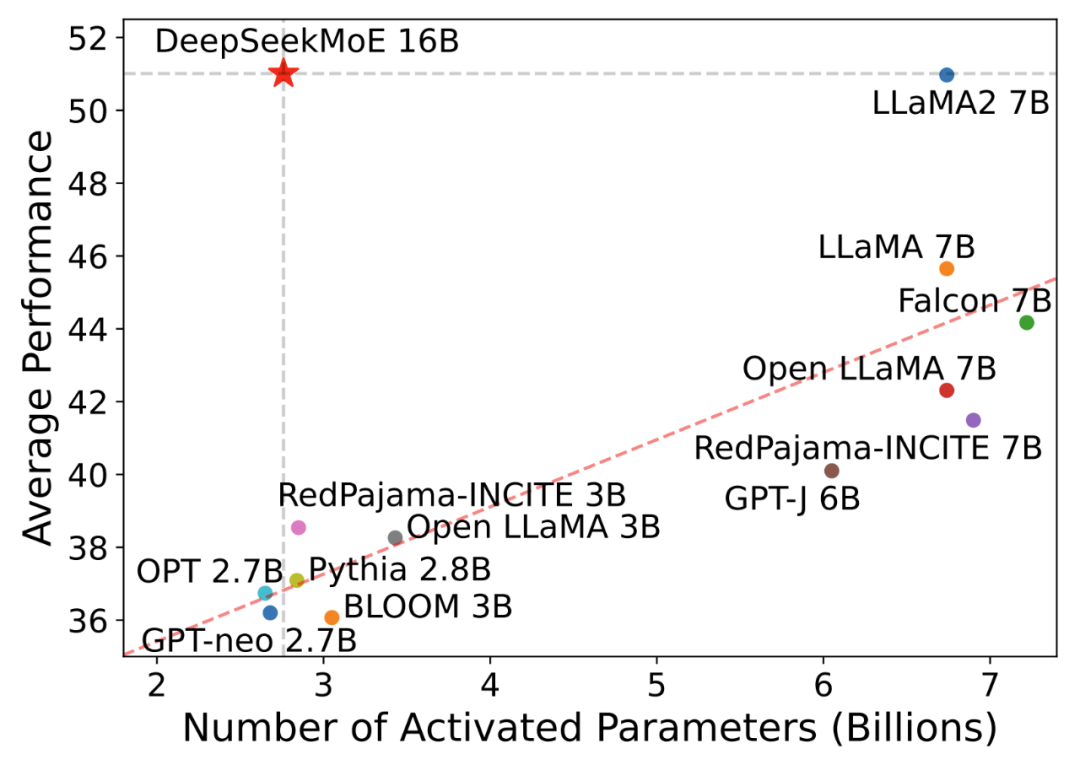
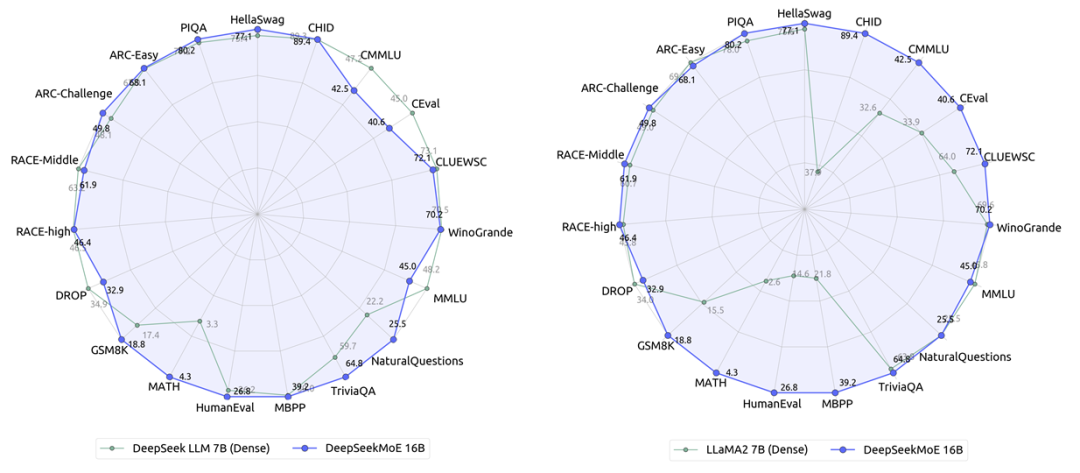
DeepSeekMoE-16B 性能比肩 LLaMA2 7B 的同時(shí),僅用了 40% 計(jì)算量,也是本次主力開(kāi)源模型,40G 顯存可單卡部署
DeepSeekMoE-145B 上的早期實(shí)驗(yàn)進(jìn)一步證明該 MoE 架構(gòu)明顯領(lǐng)先于 Google 的 MoE 架構(gòu) GShard,僅用 28.5%(甚至 18.2%)計(jì)算量即可匹配 67B Dense 模型的性能
混合專(zhuān)家模型 (Mixed Expert Models,簡(jiǎn)稱 MoEs)是用于提高大語(yǔ)言模型效率和準(zhǔn)確度的技術(shù)。這種方法的核心是將復(fù)雜任務(wù)劃分為更小、更易管理的子任務(wù),每個(gè)子任務(wù)由專(zhuān)門(mén)的小型模型或 “專(zhuān)家” 負(fù)責(zé),然后根據(jù)輸入數(shù)據(jù)的特性選擇性地激活這些 “專(zhuān)家”。 MoE 核心組成:
專(zhuān)家 (Experts):訓(xùn)練有素的小型神經(jīng)網(wǎng)絡(luò),擅長(zhǎng)特定領(lǐng)域。每個(gè)專(zhuān)家通常專(zhuān)注于處理一種特定類(lèi)型的數(shù)據(jù)或任務(wù)。專(zhuān)家的設(shè)計(jì)可以是多種形式,如完全連接的網(wǎng)絡(luò)、卷積網(wǎng)絡(luò)等。
門(mén)控機(jī)制 (Gating Mechanism):MoE 架構(gòu)決策者,這是一個(gè)智能路由系統(tǒng),負(fù)責(zé)決定哪些專(zhuān)家應(yīng)該被激活來(lái)處理當(dāng)前的輸入數(shù)據(jù)。門(mén)控機(jī)制基于輸入數(shù)據(jù)的特性,動(dòng)態(tài)地將數(shù)據(jù)分配給不同的專(zhuān)家。
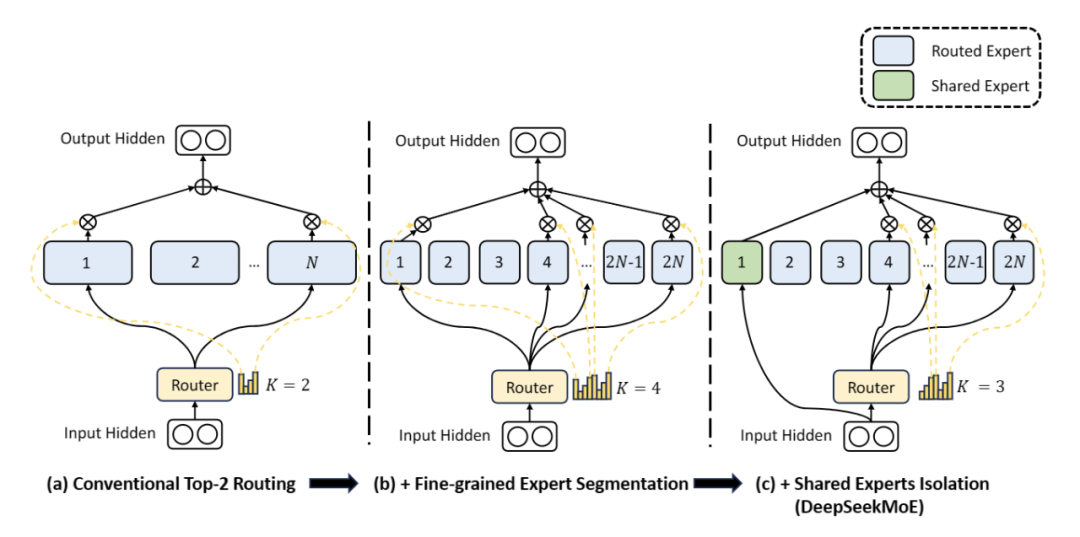
官方稱 DeepSeekMoE 是自研的全新 MoE 框架,主要包含兩大創(chuàng)新:
細(xì)粒度專(zhuān)家劃分:不同于傳統(tǒng) MoE 直接從與標(biāo)準(zhǔn) FFN 大小相同的 N 個(gè)專(zhuān)家里選擇激活 K 個(gè)專(zhuān)家(如 Mistral 7B8 采取 8 個(gè)專(zhuān)家選 2 專(zhuān)家),DeepSeekMoE把 N 個(gè)專(zhuān)家粒度劃分更細(xì),在保證激活參數(shù)量不變的情況下,從 mN 個(gè)專(zhuān)家中選擇激活 mK 個(gè)專(zhuān)家(如 DeepSeekMoE 16B 采取 64 個(gè)專(zhuān)家選 8 個(gè)專(zhuān)家),如此可以更加靈活地組合多個(gè)專(zhuān)家
共享專(zhuān)家分離:DeepSeekMoE 把激活專(zhuān)家區(qū)分為共享專(zhuān)家(Shared Expert)和獨(dú)立路由專(zhuān)家(Routed Expert),此舉有利于將共享和通用的知識(shí)壓縮進(jìn)公共參數(shù),減少獨(dú)立路由專(zhuān)家參數(shù)之間的知識(shí)冗余
審核編輯:劉清
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4812瀏覽量
103299 -
智能路由
+關(guān)注
關(guān)注
0文章
9瀏覽量
7201 -
卷積網(wǎng)絡(luò)
+關(guān)注
關(guān)注
0文章
43瀏覽量
2487 -
DeepSeek
+關(guān)注
關(guān)注
1文章
793瀏覽量
1594
原文標(biāo)題:幻方量化開(kāi)源國(guó)內(nèi)首個(gè)MoE大模型,全新架構(gòu)、免費(fèi)商用
文章出處:【微信號(hào):OSC開(kāi)源社區(qū),微信公眾號(hào):OSC開(kāi)源社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
華為正式開(kāi)源盤(pán)古7B稠密和72B混合專(zhuān)家模型
瑞芯微模型量化文件構(gòu)建
上新:小米首個(gè)推理大模型開(kāi)源 馬斯克:下周推出Grok 3.5
英偉達(dá)GROOT N1 全球首個(gè)開(kāi)源人形機(jī)器人基礎(chǔ)模型
DeepSeek扔的第二枚開(kāi)源王炸是什么

Meta組建四大專(zhuān)研小組,深入探索DeepSeek模型
字節(jié)跳動(dòng)發(fā)布豆包大模型1.5 Pro
獵戶星空發(fā)布Orion-MoE 8×7B大模型及AI數(shù)據(jù)寶AirDS
騰訊發(fā)布開(kāi)源MoE大語(yǔ)言模型Hunyuan-Large
全球首個(gè)開(kāi)源AI標(biāo)準(zhǔn)正式發(fā)布
Meta發(fā)布Llama 3.2量化版模型
深開(kāi)鴻聯(lián)合深天使發(fā)布國(guó)內(nèi)首個(gè)開(kāi)源鴻蒙產(chǎn)業(yè)加速營(yíng)

深開(kāi)鴻聯(lián)合中軟國(guó)際、粵科金融集團(tuán)發(fā)布國(guó)內(nèi)首個(gè)開(kāi)源鴻蒙創(chuàng)業(yè)投資基金
深開(kāi)鴻聯(lián)合深天使發(fā)布國(guó)內(nèi)首個(gè)開(kāi)源鴻蒙產(chǎn)業(yè)加速營(yíng)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論