 構建大規模Simulink模型的標準化最佳實踐
構建大規模Simulink模型的標準化最佳實踐
| 作者 Brad Hieb 和 Erick Saldana Sanvicente,MathWorks
(本文采用了機器翻譯)
隨著系統規模和復雜性的增長,工程團隊面臨著一系列在小規模上不存在的全新挑戰。
規模的大幅擴大幾乎總是需要方法的轉變,不僅是范圍上的,而且是種類上的。此原則也適用于使用基于模型的設計處理 Simulink 模型時。如果不遵循最佳實踐,從簡單的概念驗證模型過渡到具有數十萬個塊的大規模模型時,一系列問題開始出現,包括模型架構、數據管理、接口、文件管理和仿真性能不佳的問題。這些大型模型的構成要素可能很小,通常由不同的個人、團隊甚至部門開發。當有標準化并且遵循最佳實踐時,這些模型可以順利擴大規模。
本文介紹了一組最佳實踐,用于解決在 Simulink 中處理大型復雜模型時經常遇到的挑戰。由于這個主題本身相當廣泛,這里的目標不是提供詳細的規定性指導,而是介紹每種最佳實踐的基礎知識以及可供探索的其他資源的鏈接,以便更深入地了解如何應用它。
使用模型引用進行模型組件化
當我們與客戶合作時,經常會看到大型模型缺乏有意義的組件化。團隊從一個簡單的模型開始測試想法;隨著時間的推移,新的元素或特性被添加,所有的工作都在一個單一的、整體的模型文件
中完成,而這個模型文件很快就會變得難以處理。在 Simulink 中,有幾種方法可以組件化大型模型,最佳方法將取決于所考慮的具體用例。例如,如果一個團隊只是想直觀地組織一組塊或組件,他們可能會選擇模型內虛擬子系統。對于想要創建廣泛使用且不經常更改的實用程序的其他團隊來說,鏈接子系統(或庫)是一個更好的選擇。如果目標是開發或仿真一個組件作為獨立模型,那么模型參考是最好的方法。
對于大規模模型來說,模型引用也是組件化的關鍵。原因之一是 Simulink 中的模型引用使團隊能夠將組件作為獨立模型并行開發。每個組件都具有完整的功能且可仿真,并保存在自己的 SLX 文件中,因此每個團隊都可以獨立工作而不會干擾其他團隊的工作 - 當整個設計都捕獲在一個文件中時,這幾乎是不可能做到的。同樣重要的是,這些獨立的參考模型可以放置在更大的模型內,以便于集成(圖 1)。該架構可以使用參考模型的緩存實例和增量構建來減少構建時間。它還允許使用加速器和快速加速器模式,下面關于性能的部分將詳細介紹。
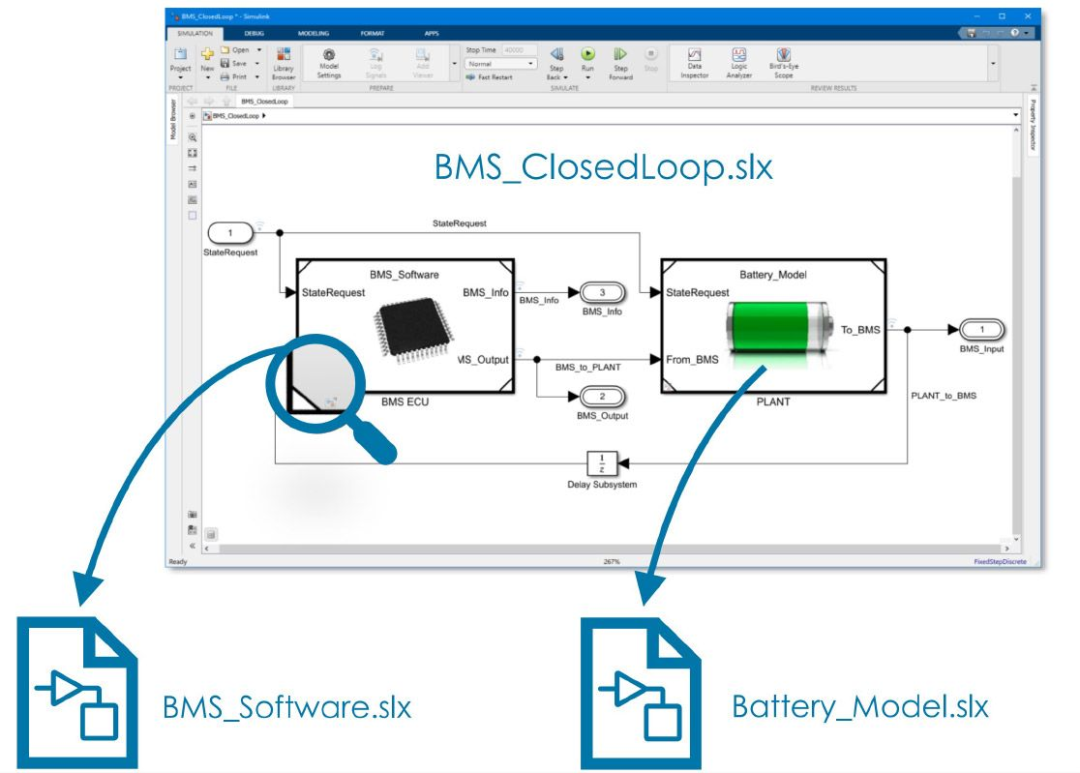
圖 1. 模型 BMS_Software 和 Battery_Model 可以獨立開發,然后放置(或引用)在 BMS_ClosedLoop 模型。
使用模型引用進行模型組件化
讓我們重新考慮一下導致組件化問題的相同場景:一個團隊從一個簡單的模型開始作為早期的概念證明,然后隨著時間的推移不斷對其進行完善。對于一個簡單的模型,許多工程師會將變量、參數和其他數據存儲在基礎工作區。這種方法適用于非正式工作流程、快速參數調整、快速原型設計、單一開發人員工程或需要參數普遍可見性的用例。然而,隨著模型范圍和復雜性的增加,依賴基礎工作區進行數據管理會帶來一些缺點。例如,由于每次工程師關閉會話時基礎工作區都會被清除,因此必須手動保存為 MATLAB 代碼 (.m) 或 MATLAB 文件 (.mat)。
數據字典比基礎工作區更適合管理涉及大型模型、分布式開發或范圍數據的工程數據。出現這種情況的原因有幾個(見圖2)。第一是數據持久化。數據以特定的文件格式保存在數據字典 (.sldd) 文件中,使團隊能夠獨立于模型和基礎工作區定義、管理和更新數據。其次,團隊可以將數據分成多個字典,以進一步改善數據組織。第三,數據字典在變更跟蹤工作流中運行良好,團隊可以查看進行了哪些更改、何時進行更改以及由誰進行更改,甚至可以在需要時恢復到早期版本。
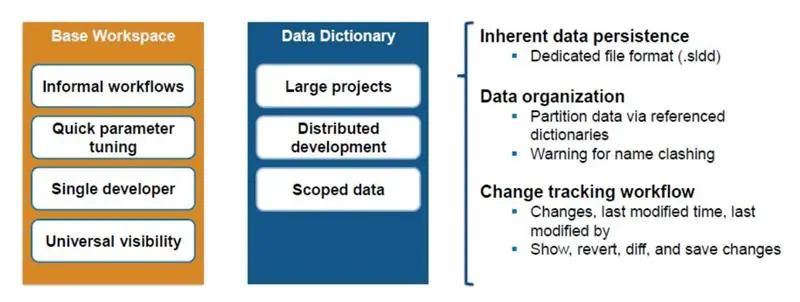
圖 2. 處理大型模型時數據字典的優勢。
這里需要注意的是,使用基礎工作區和數據字典之間的選擇并不是全有或全無的。這兩種方法可以共存,因此團隊可以隨著時間的推移逐漸從基礎工作區遷移到一個或多個數據字典。
簡化與總線的接口
在組件化、分層模型中連接子系統時,最初可能看起來最直接的方法是針對從一個組件傳遞到另一個組件的每個元素使用單獨的信號線。當然,這適用于簡單的界面,但這種方法很快就會導致模型變得比必要的更復雜、更混亂、更難管理。
在 Simulink 中,總線可以通過用一條線表示一組信號(或元素)來簡化界面并減少混亂,就像幾根電線捆綁在一起一樣。通過一個簡單的例子很容易看出它的價值。考慮一個用于識別電池系統中異常情況的故障檢測組件。該組件有 11 種不同的輸入,包括最大和最小電池電壓、最大和最小電池溫度、接觸器狀態、電池組電壓和電流以及電流限制。雖然創建具有 11 個獨立輸入端口的組件是可能的,但將輸入分成邏輯組并為每個組使用一個總線更為清晰。例如,由于電池電壓和電池溫度信號均來自同一組件且彼此相關,因此將它們分組為單個四元件總線是有意義的(圖 3)。顯然,這是一個相對簡單的例子,但它說明了如何使用總線來簡化組件接口,而且更廣泛地說,簡化復雜模型。
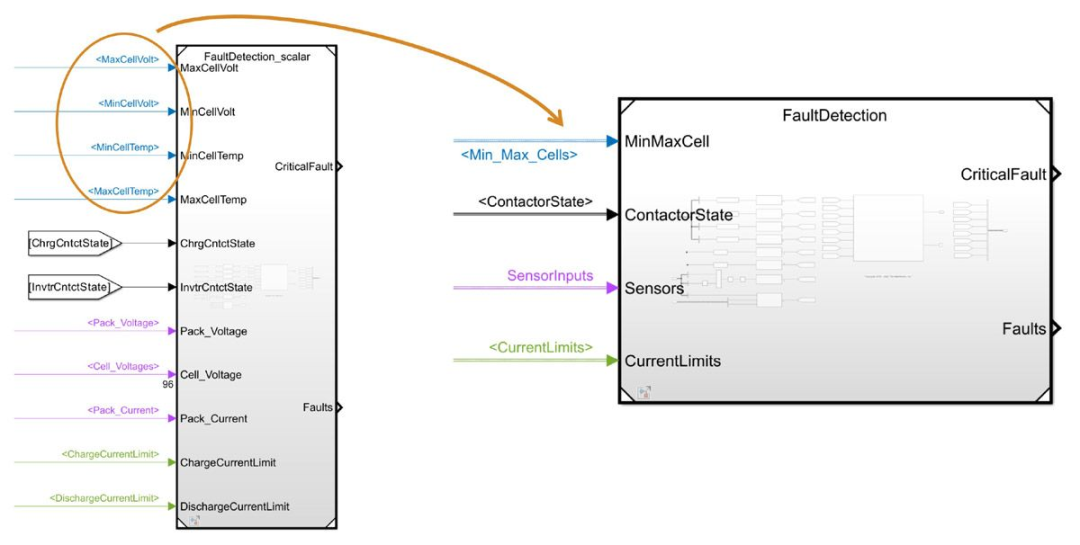
圖 3. 故障檢測組件已更新,使用總線而不是單獨的信號作為輸入。
利用工程改善文件管理
遵循迄今為止概述的最佳實踐的一個副作用是必須管理的文件數量增加。當整個設計都采用單一模型時,團隊需要管理的文件集相對較小,但當積極采用組件化和數據字典時,文件集就會迅速增長。如果沒有文件管理策略,文件的激增就會帶來問題。
在 Simulink 中工作時,團隊可以使用工程來幫助自動化文件管理活動,這樣他們就有更多時間花在建模、仿真和其他高價值活動上。例如,在設置工程時,團隊將指定工程路徑中的文件夾。當工程打開時,這些文件夾會被添加到搜索路徑中(當工程關閉時,這些文件夾會被刪除),以確保工程的所有用戶都可以訪問其中的文件。團隊還可以指定用于自動設置項目環境的啟動文件,以及通過撤銷設置步驟(例如)來清理環境的關閉文件。此外,可以配置工程以在啟動時打開常用文件并為常用任務創建快捷方式。
工程還可以幫助團隊避免常見的錯誤。例如,在復雜的模型層次結構中,兩個同名的模型文件存在于不同的目錄中是很常見的。當使用工程時,工程師將看到以下警告:檢測到影子文件。此外,當工程關閉時,系統會提示工程師保存任何未保存的更改,以幫助避免工作丟失。
最后,工程有助于簡化源代碼控制,其中刷新、提交、推送、拉取、獲取等常見操作以及其他常見操作可直接從用戶界面訪問(圖 4)。
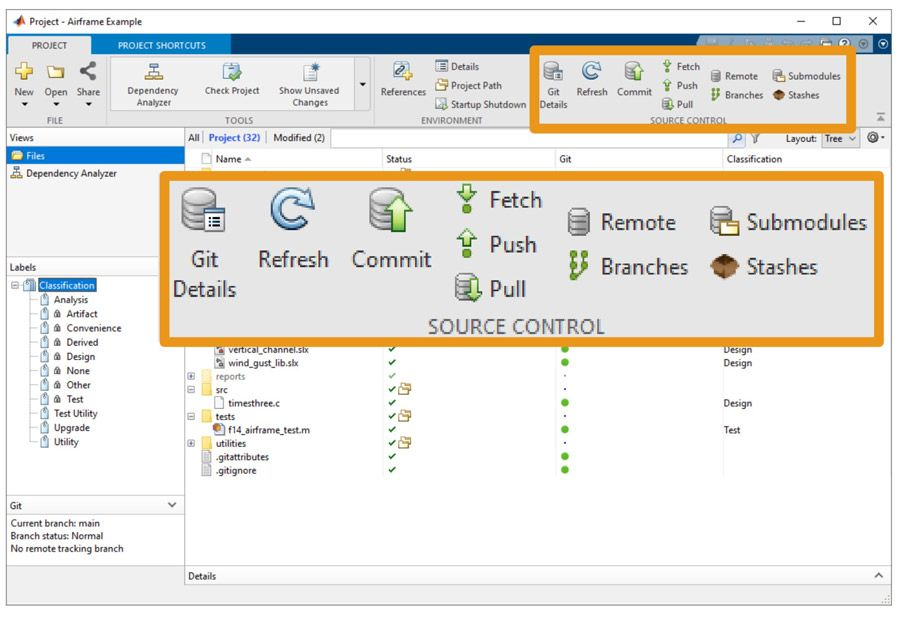
圖 4. 源代碼控制操作可直接從工程選項卡的源代碼控制部分找到。
優化仿真性能
到目前為止我們所介紹的最佳實踐主要集中于大型模型的結構及其相關的數據和文件。在與實施了這些最佳實踐的客戶的對話中,我們經常被問及如何提高仿真性能:“現在我們有了更好的方法來構建大型模型,我們如何才能讓它們仿真得更快呢?”
有多種工具可用于提高仿真性能。作為第一步,我們建議性能顧問,它運行一系列檢查來識別可能減慢仿真速度的配置設置。接下來,對于任何包含初始化 MATLAB 代碼的模型(例如,在回調中),運行 MATLAB 探查器來確定 MATLAB 花費時間最多的地方是個不錯的主意。Simulink 探查器評估模型執行時間并識別可能導致仿真性能不佳的問題。最后,對于使用可變步長求解器的團隊,我們建議運行求解器探查工具來分析求解器行為,以識別潛在問題(例如求解器重置或極小的時間步長),并提供解決這些問題的建議。有關每種工具的指南,包括如何使用以及何時使用,請參閱排除故障并提高仿真性能指南(見表)。
已將大型模型組件化的團隊可以使用加速器模式或快速加速器模式加速仿真,此種模式用生成的代碼替換 Simulink 仿真中通常使用的解釋代碼。在模型初始化期間, Simulink 會檢查緩存中是否存在已生成代碼的組件。這種增量構建過程極大地減少了具有許多組件的大型模型的初始化時間,因為只有自上次仿真以來發生變化的組件才需要重建(并添加到緩存中)。
減少初始化時間的另一種方法是使用快速重啟。當團隊執行多次仿真運行而沒有對模型進行任何結構性更改時,快速重啟可以通過執行仿真而無需編譯模型并每次終止仿真來加快該過程。相反,在第一次仿真時,模型被編譯和初始化,然后在每次后續仿真中捕獲模型操作點的快照(圖 5)。
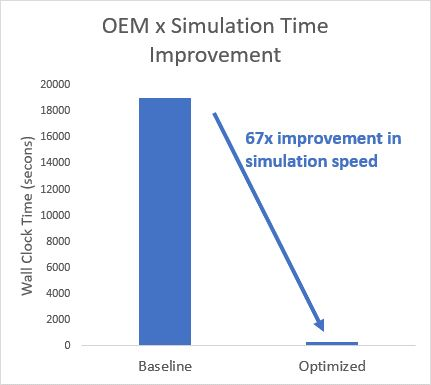
圖 5. 優化模型以實現更快的仿真。
總之,當工程團隊應對擴展 Simulink 模型的復雜性時,遵循最佳實踐變得至關重要。本文概述了模型組件化、數據管理和性能優化的基本策略,強調了結構化方法對模型開發的重要性。通過利用性能顧問、MATLAB 探查器和求解器探查工具等工具,團隊可以增強仿真性能并提高生產力。這些實踐確保大型模型仍然可管理、高效且適應性強。隨著基于模型的設計領域不斷發展,這些指南將幫助團隊構建強大的模型,以滿足日益復雜的工程挑戰的需求。為了進一步探索,我們鼓勵讀者參與本文重點介紹的額外資源和培訓機會。
本文的內容基于我們在 MathWorks 北美汽車會議上發表的演講,題為“從組件到復雜系統構建大型模型的最佳實踐”(請可以點擊“閱讀原文”觀看此英語演講)。
正如我們一開始所說的,這是一個龐大的話題,無法在一篇文章或一次演講中詳盡地涵蓋。歡迎您報名我們 2025 年 5 月在上海和北京召開的 MATLAB EXPO 中國用戶大會,關注我們的建模、仿真、測試和實現分會場與汽車專場分會場演講,或者來現場與我們的專家進行面對面的交流。
-
matlab
+關注
關注
188文章
2998瀏覽量
233415 -
Simulink
+關注
關注
22文章
540瀏覽量
63710 -
模型
+關注
關注
1文章
3499瀏覽量
50083
原文標題:構建大規模 Simulink 模型的標準化最佳實踐
文章出處:【微信號:MATLAB,微信公眾號:MATLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
名單公布!【書籍評測活動NO.30】大規模語言模型:從理論到實踐
【大規模語言模型:從理論到實踐】- 每日進步一點點
EPON標準化進展
大規模特征構建實踐總結
EPON技術的標準化與測試
NVIDIA聯合構建大規模模擬和訓練 AI 模型
部署Linux的最佳實踐探索
使用Ansible構建虛擬機部署Linux的最佳實踐
大規模語言模型的基本概念、發展歷程和構建流程






 工商網監
工商網監
評論