 RISC-V架構下的編譯器自動向量化
RISC-V架構下的編譯器自動向量化
進迭時空專注于研發基于RISC-V的高性能新AI CPU,對于充分發揮CPU核的性能而言,編譯器是不可或缺的一環,而在AI時代,毫無疑問向量算力將發揮越來越重要的作用。進迭時空非常重視RISC-V高性能算力生態的建設,正投入編譯器自動向量化優化等多項關鍵技術,全面助力RISC-V的高性能發展。
RISC-V 向量設計
SpacemiT
在現代CPU中,向量支持是算力的一個重要組成部分。1996年Intel就推出了針對多媒體應用程序設計的SIMD指令集MMX,隨后又逐步引入了SSE、AVX、AVX2、AVX-512,Arm也引入了NEON指令集支持,并在armv8版本中將NEON定義為默認支持,后續又引入了長度可變的SVE。
對于新興的RISC-V架構, 同樣也有vector擴展支持。RISC-V Vector Extension(下文簡稱RVV)是 RISC-V 指令集架構(ISA)中的一種擴展,專門設計用于高效的向量處理。RVV 為RISC-V 指令集架構引入了強大的向量處理能力,旨在通過向量化計算提高多種應用程序的計算性能。
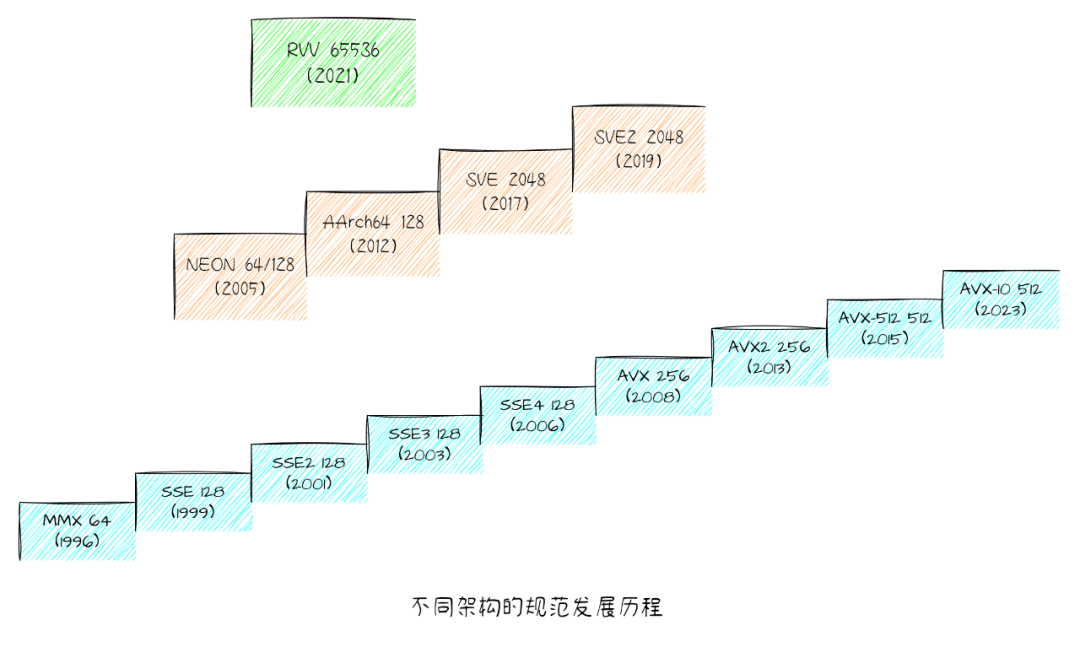
吸收了其他架構的經驗,RISC-V發現傳統的SIMD指令設計并不夠好,不同的寬度引入不同的SIMD指令,使得整個指令集越來越龐大和復雜。RISC-V的發明人Patterson教授在《SIMD Instructions Considered Harmful》一文中闡述了這一觀點。
最終RVV的設計更類似于SVE,是可變長的向量,而且非常靈活,可在運行時動態設置寄存器大小,分組,寬度,以及掩碼操作等,可以做到同一份二進制文件在不同VLEN的硬件上都能充分發揮硬件性能。
其靈活的設計和易于編程的特性,使其在現代計算任務中具有明顯的優勢,并為未來的計算需求提供了良好的支持。隨著 RISC-V 生態系統的發展,RVV 有望在更多應用中發揮重要作用。
自動向量化
SpacemiT
如何利用向量算力,一種方式是軟件開發者直接調用向量的編程接口,另一種方式是直接編寫標量代碼通過編譯器實現自動向量化,這兩種方式各有優劣,都不可或缺。
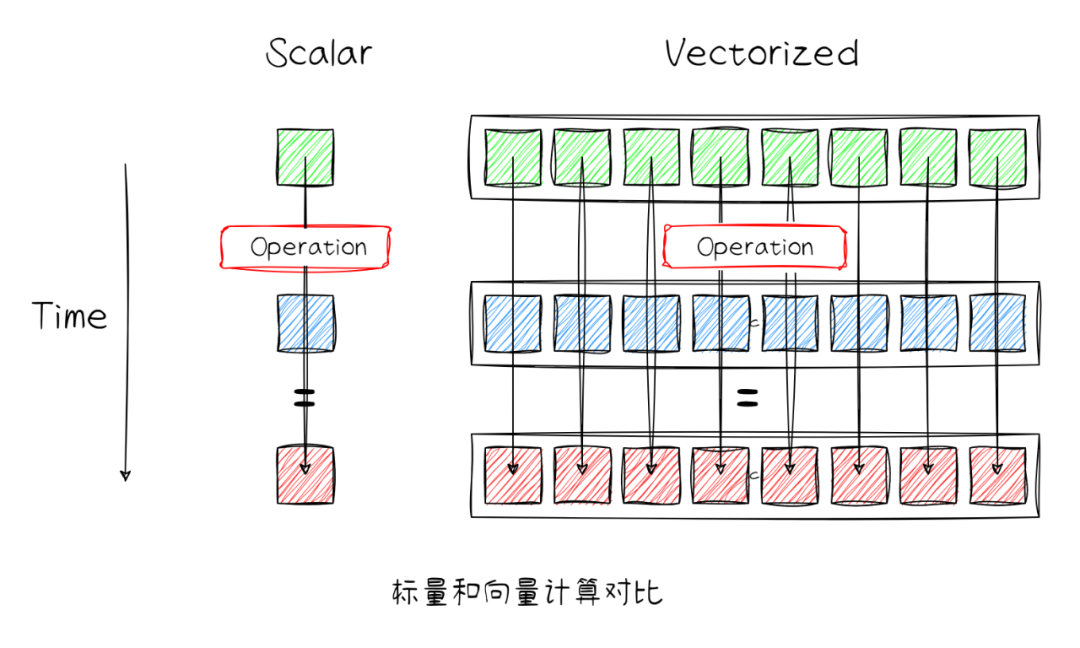
向量化(Vectorization)是一種編程和編譯優化技術,自動向量化的本質是編譯器識別程序中的循環或者基本塊,將多個標量操作組合在一起,利用編譯器數據流/控制流等分析技術自動生成SIMD/向量指令的過程,以此達到提高數據并行,加快數據計算的目的。
由于其在科學計算、圖像處理、機器學習和數字信號處理等領域具有廣泛的應用,使得業界對向量化這項技術一直有持續的關注和投入,主要是因為是自動向量化可以帶來很多優勢:
性能提升:自動向量化利用硬件架構提供的SIMD/Vector指令,減少了迭代循環的開銷,且提高數據并行處理的能力,對計算密集或者數據規模大的場景會帶來極大的性能優勢。
降低編程的復雜性:開發者不需要手動編寫復雜的向量化代碼,交給編譯器自動分析、優化和生成向量代碼。
兼容性和可移植性:通過自動向量化,開發者可以編寫標準的標量代碼運行在不同的平臺,編譯器會根據目標平臺特性生成可在對應平臺上執行的向量代碼。
自動向量化實現
SpacemiT
自動向量化工具
目前LLVM框架下支持的自動向量化工具有 SLP Vectorize 和 Loop Vectorize。
SLP Vectorize(superword-level parallelism)
SLP向量化關注單次迭代間的向量化機會,在基本塊中搜集相似的標量指令,通過將相似標量指令合并為向量指令的方式,來實現向量化。如下程序可以通過構造向量(a1, a2)和 (b1, b2),完成向量化算術運算。
void foo(int a1, int a2, int b1, int b2, int *A) { A[0] = a1*(a1 + b1); A[1] = a2*(a2 + b2); A[2] = a1*(a1 + b1); A[3] = a2*(a2 + b2); }
Loop Vectorize
循環向量化關注循環迭代間的向量化機會,將多次迭代處理的數據利用更寬的位寬寄存器存儲,使其一次能夠完成多次循環迭代的數據處理,此后每次循環迭代的下標步長將擴寬成SIMD的位寬/向量元素的位寬。
for (int i = 0; i < n; i++) { ? A[i] = B[i] + C[i] } -----> Transform for (int i = 0; i < n; i = i + step) { ? // 結合tail Folding 機制 和 Loop unroll 完成自動向量化的過程 ? for (int j = i; j < min(n, i + step); j++) { ? ? A[j] = B[j] + C[j]; ? } }
Loop Vectorize 優化介紹
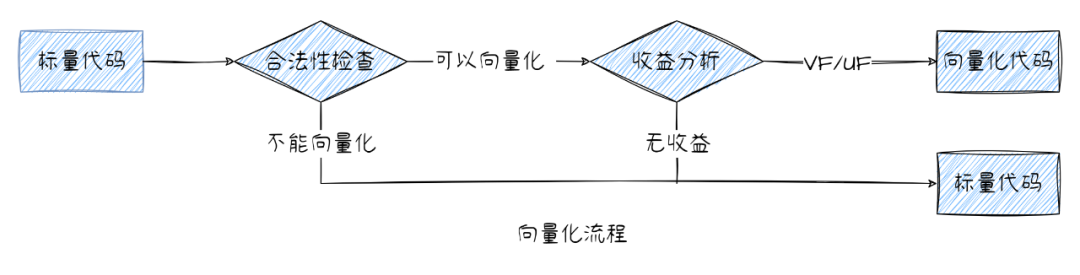
循環中的標量代碼是否可以向量化,主要涉及到以下三個階段:
檢查當前循環是否可以向量化,對其合法性進行校驗;
在滿足合法性校驗的前提下,利用代價模型分析向量化的代碼是否具有收益;
確定向量化代碼可以帶來收益,完成標量代碼轉換為向量代碼,并更新當前循環控制流。
下文會對Loop Vectorize 進行簡要介紹(更多細節可以查閱文末的參考文檔):
Loop Vectorize VPlan 架構介紹
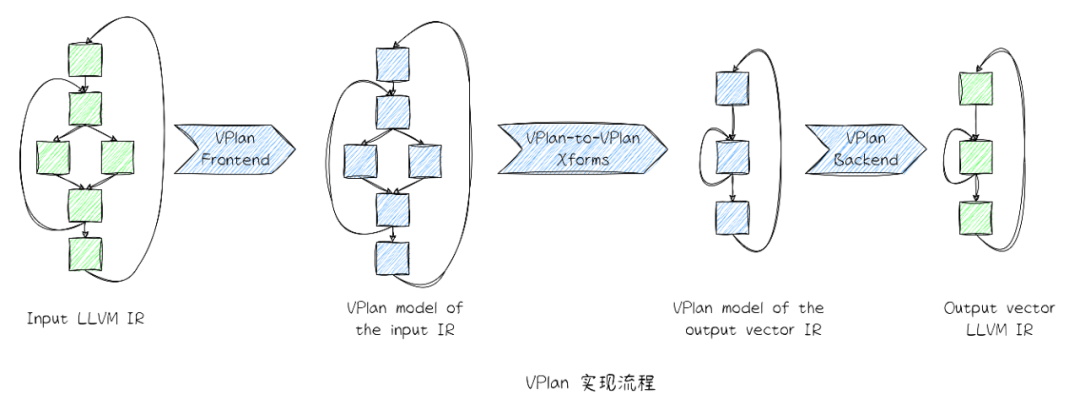
VPlan 是LLVM Loop Vectorize 基礎設施的重要組成部分, 其主要是為編譯器在Loop Vectorize 分析中獲取到的所有向量化因子(VF)進行建模和評估,根據代價模型,選擇成本最優的向量化模型,并進行轉換,其存儲了所有可能的向量化候選者代碼,使得Loop Vectorize 實現更模塊化,也增強了其可擴展性,為復雜控制流和內存訪問循環提供了更多向量化的機會。
整個LLVM Loop Vectorize是基于VPlan架構實現的。其在輸入和輸出中間加了一層VPlan層,將IR層面的轉換和分析隔離,可以有效地簡化數據流的分析,僅需更新VPlan IR to Output IR 的控制流信息(增加了產生向量化的代碼的機會),主要有以下流程:
Input IR to VPReciple IR:通過合法性分析 + TTI 對應的目標平臺后端提供的代價模型獲取最優VF,并將結果存儲到VPlan中,完成首次VPlan model 的構建,此時無需更新控制流。
VPlan-to-VPlan Transform Pipeline:在獲取VPlan 之后,針對一些場景做優化,例如冗余Recipe 刪除、簡化Vector Region 實現(循環條件或者循環歸納變量的優化)和插入EVL等。
VPRecipe IR to Output IR:利用VPTransformState中提供的信息存儲和吐出Output IR,生成真正的vectorizing code,此時需要重新調整循環結構并更新控制流。
Loop Vectorize 實現方式
LLVM 在Loop Vectorize 中的實現主要有以下兩種方式:Vector Length Specific 和 Vector Length Agnostic 。下文會重點講解這兩個方案的優劣勢并通過如下用例展示效果。
void vp_add(int *restrict a, int *restrict b, int *restrict c, int N) { for (int i = 0; i < N; i++) { ? ?a[i] = b[i] + c[i]; ?}}
Vector Length Specific (VLS)
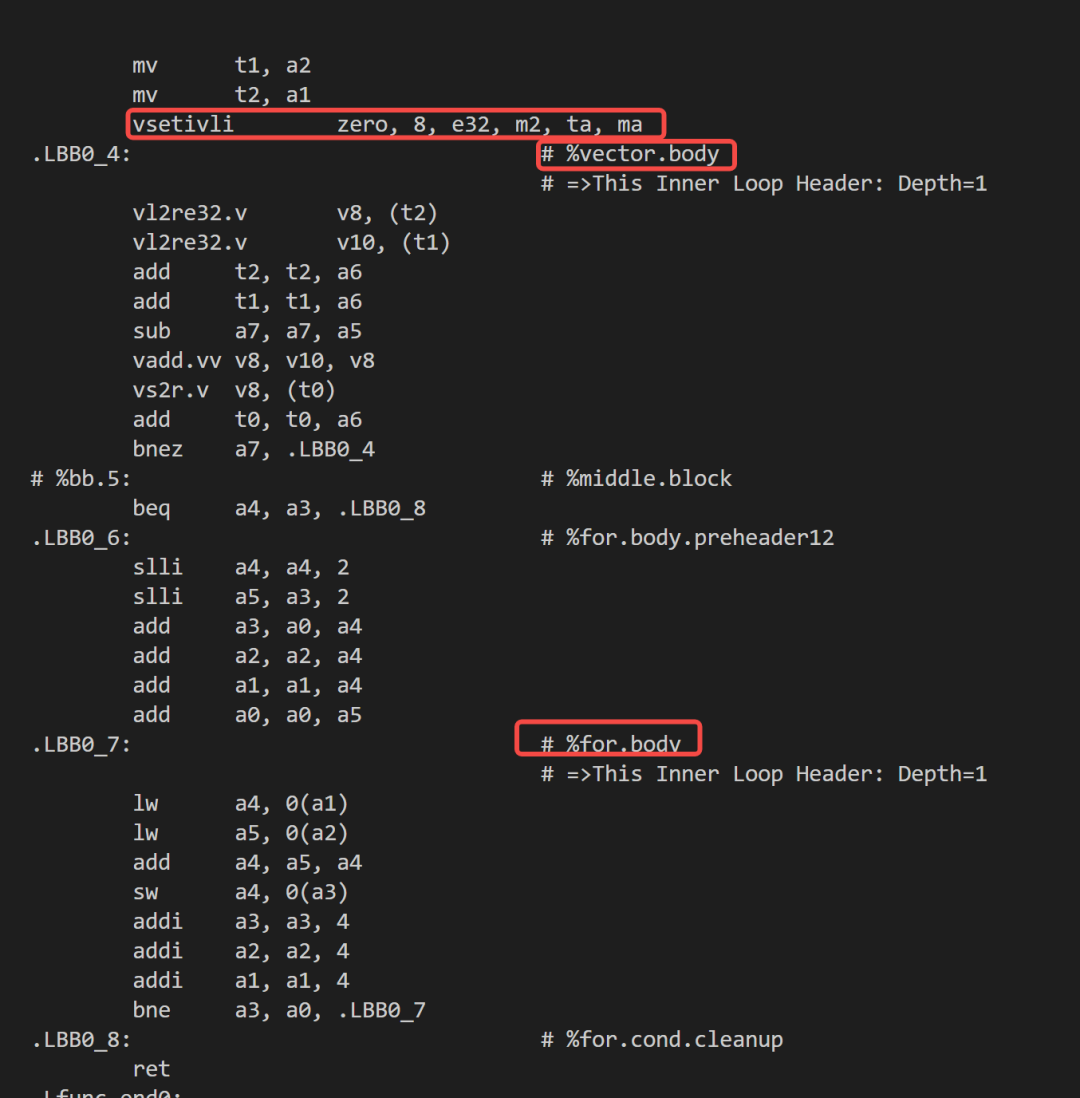
編譯器在Loop Vectorize優化階段直接利用硬件的向量寄存器位寬進行向量化。如果當前存在尾部元素沒辦法填滿向量寄存器,則使用標量的方式處理尾部元素。
優勢:
目前,Loop Vectorize架構已經實現且無需特殊的 IR-Level Express。
劣勢:
需要單獨處理循環尾序。
沒充分利用RVV Scalable的特性,其生成的二進制只能在指定的VLEN 架構上運行。
編譯選項
clang --target=riscv64 -march=rv64imav -mllvm -riscv-v-vector-bits-min=128 -mllvm -riscv-v-vector-bits-max=128 -O3 -S xxx.c -o xxx.s
匯編效果
注:用于向量配置的 vsetivli 指令是位于向量循環 .LBB0_4 的外部。在向量循環結束后,還需要一個額外的標量循環 .LBB0_7 處理尾部元素。
Vector Length Agnostic(VLA)
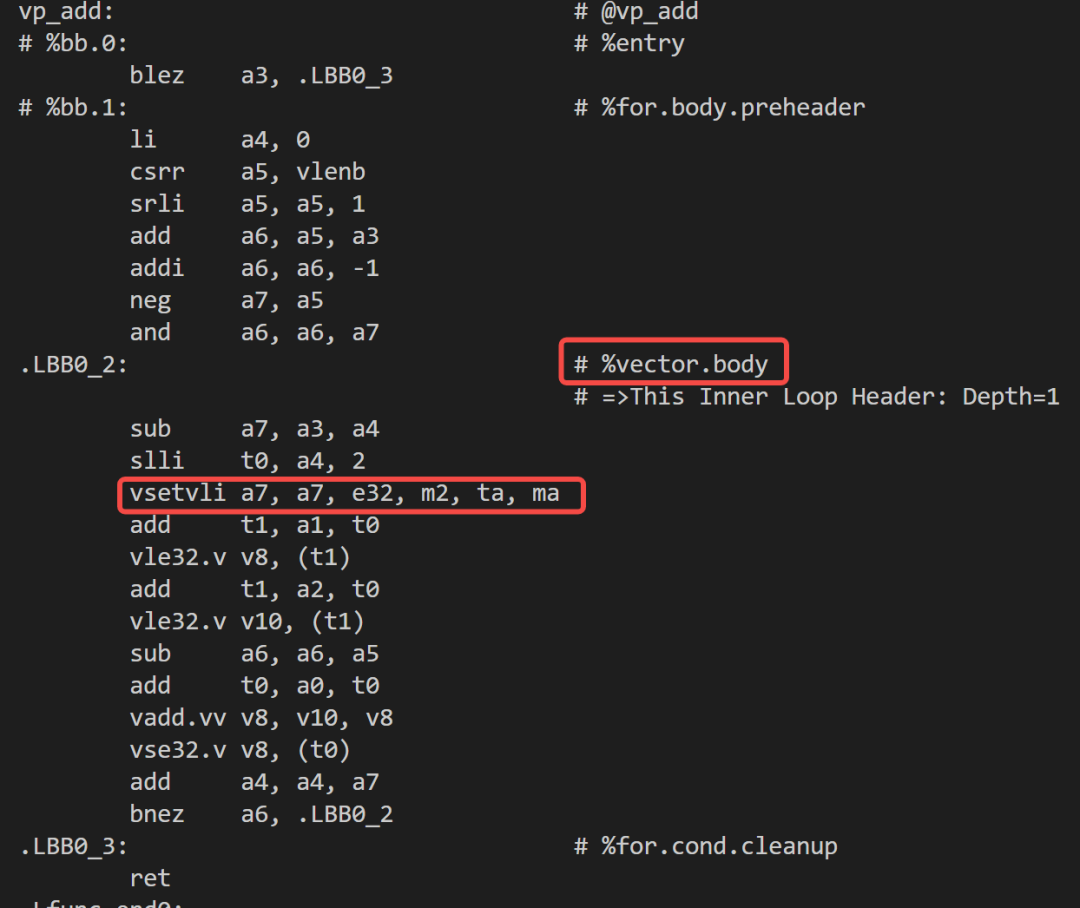
最近幾年,LLVM 引入了 Vector Predication IR (VP IR),其VP IR中攜帶的參數Mask 和 EVL(Explicit Vector Length)為獨立于目標平臺的各個架構提供了豐富的predicated vector instructions。當前,編譯器在Loop Vectorize優化階段的VLA 方案也是使用VP IR作為IR-Level Express完成的。編譯器在循環迭代中,將所有 vector instructions 替換為predicated vector instructions,并使用EVL設置每次迭代需要處理的向量元素長度(RISC-V 架構會在后續Lowering階段翻譯成RVV vsetvli/vsetvl/vsetivli 指令)。
優勢:
充分利用RVV 的Scalable 特性,其生成的二進制可以在任何VLEN架構上運行。
無需單獨處理循環尾序和條件分支。
劣勢:
需要特殊的 IR-Level Express(不過目前RVV VP的設計和慢慢趨于穩定,積極推進了Loop Vectorize在此方案的實現)。
所有的vector instructions都帶有predicate標識,且CFG也是,這對于分支預測率比較高或者條件分支執行的概率很低的場景,可能會帶來負向性能收益。
編譯選項
clang --target=riscv64 -march=rv64imav -mllvm -force-tail-folding-style=data-with-evl -mllvm -prefer-predicate-over-epilogue=predicate-dont-vectorize -O3 -S xxx.c -o xxx.s
匯編效果
注:用于向量配置的 vsetvli 是位于向量循環.LBB0_2的內部,每次都會動態設置處理的元素個數,達到的效果是向量循環之后整個函數就結束了,無需再有額外的代碼處理尾部元素。
未來的重點工作方向
SpacemiT
進迭時空當前已經發布的K1芯片全面支持RISC-V Vector 1.0,其VLEN為256,后續也將推出具有更長VLEN的CPU核,進一步強化向量算力。從整個RISC-V生態考慮,靈活使用RVV相關特性,兼容程序在不同向量位寬配置的硬件上運行,將更有利于RISC-V向量算力的廣泛應用。
目前,社區在積極投入基于VLA的開發實現上,進迭時空也在投入和跟蹤社區向量化的開發貢獻工作中。以下是Loop Vectorize優化中使能VLA比較關鍵的幾個PATCH:
https://github.com/llvm/llvm-project/pull/76172
https://github.com/llvm/llvm-project/pull/93854
https://github.com/llvm/llvm-project/pull/90184
https://github.com/llvm/llvm-project/pull/110412
https://github.com/llvm/llvm-project/pull/108351
目前,自動向量化支持還有不少待完善的地方,基于社區最新分支,進迭時空會側重下面的一些工作,且代碼會陸續開源貢獻給社區。
Loop Vectorize 優化:Recipe transform to EVLRecipe 的構建、逐步移除 Legal Cost Model,完善VPlan-based Cost Model、VPlan-to-VPlan transforms等
RISC-V 后端代價模型完善
Vector Predicate Lowering到后端的一些通用優化
結語
SpacemiT
進迭時空是一家基于新一代RISC-V架構的計算生態企業,布局高性能RISC-V CPU核、AI-CPU核、AI CPU芯片、軟件系統等全棧計算技術,提供端到端的計算系統解決方案。
RISC-V是一個開源架構,其成功離不開繁榮的開源生態,秉承開源理念,我們的一些工作取自開源,也要回饋開源。進迭時空將持續投入包括編譯器在內的RISC-V生態建設,融入RISC-V的全球發展,攜手上下游的合作伙伴一起以RISC-V架構數智未來。
-
編譯器
+關注
關注
1文章
1657瀏覽量
49939 -
RISC-V
+關注
關注
46文章
2508瀏覽量
48356
發布評論請先 登錄
晶心科技推出突破性的RISC-V 27系列處理器及向量擴展指令處理器
CPU優化技術之自動向量化實例
關于RISC-V學習路線圖推薦
學習RISC-V入門 基于RISC-V架構的開源處理器及SoC研究
科普RISC-V生態架構(認識RISC-V)
RISC-V架構簡介
安卓支持RISC-V架構的技術剖析
算能重磅發布行業首款服務器級RISC-V CPU算豐SG2042,助力RISC-V邁向高性能計算
Arm Fortran編譯器開發人員和參考指南
方舟編譯器官發布對 RISC-V 后端的支持
CPU優化技術-NEON自動向量化
開源硬件系列09期:RISC-V架構指令集與編譯器技術

HighTec C/C++編譯器支持Andes晶心科技RISC-V IP
HighTec C/C++編譯器套件全面支持芯來RISC-V IP





 工商網監
工商網監
評論