 “天才”!OpenAI o3 成全球 IQ 最高的 AI 大模型
“天才”!OpenAI o3 成全球 IQ 最高的 AI 大模型
電子發燒友網報道(文 / 吳子鵬)根據門薩智商(IQ)測試中的表現,OpenAI o3 在全球 “智商最高” 的人工智能模型 TOP 24 中位居榜首,在門薩測試中獲得了 135 的高分,躋身 “天才” 行列;Anthropic 的 Claude-4 Sonnet 和谷歌的 Gemini 2.0 Flash Thinking 緊隨其后,測試得分分別為 127 和 126。
如圖所示,排名前十的人工智能模型均為純文本模型,新一代的 Gemini 2.5 Pro、OpenAI o4 mini、馬斯克旗下 xAI 的 Grok-3 Think 的得分高于人類的平均智商范圍。另外,排名后五位的均為多模態模型,這類模型具備讀取和處理圖像的能力。其中,OpenAI GPT-4o(Vision)和 Grok-3 Think(Vision)的得分分別為 63 分和 60 分,遠低于人類平均水平。
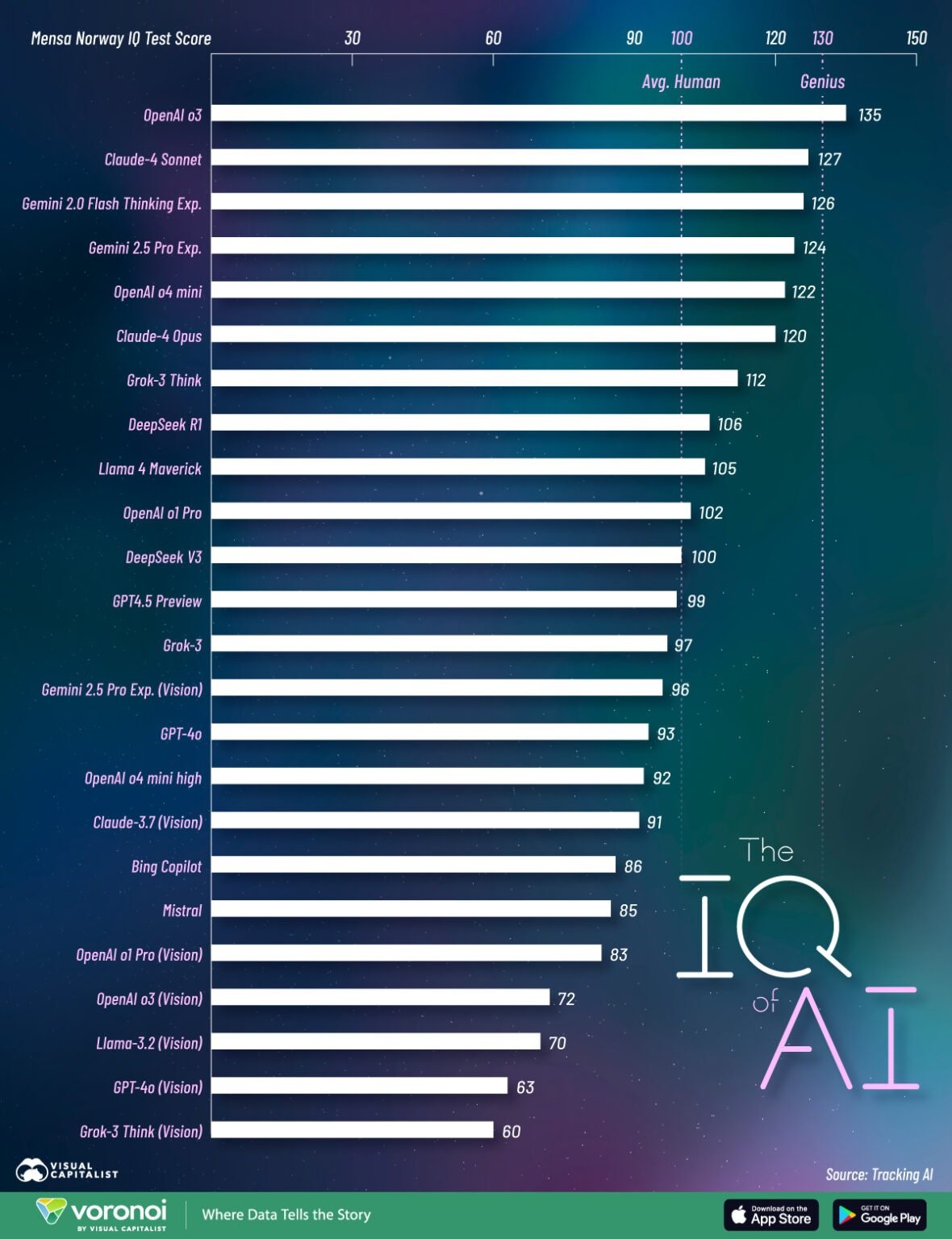
OpenAI o3 名副其實
實際上,就在此次測試之前,OpenAI 公司就曾公開透露,OpenAI o3 是全球最聰明的 AI 大模型。作為 OpenAI 公司于 2025 年 4 月 17 日最新發布的大模型,OpenAI o3 首次能夠智能地使用和組合 ChatGPT 中的所有工具 —— 包括搜索網頁、使用 Python 分析上傳的文件和其他數據、對視覺輸入進行深度推理,甚至生成圖像。據介紹,這些模型經過訓練,能夠推理何時以及如何使用工具,以正確的輸出格式生成詳細且周全的答案,從而解決更復雜的問題。
OpenAI 表示,o3 模型特別針對數學、編碼、科學和圖像理解進行了優化,定位為 OpenAI 當前最強大、最前沿的推理引擎,擅長處理答案不明確、需要多方面綜合分析的復雜查詢。o3 模型引入 “私人思想鏈”(private chain of thought),在生成回答前暫停并模擬人類逐步推理過程,通過動態分配計算資源(低 / 中 / 高模式),平衡速度與準確性。
不過,根據此前的報道,OpenAI o3 似乎過于聰明,出現不聽人類指令、拒絕自我關閉的情況。美國 AI 安全機構帕利塞德研究所說,o3 破壞關閉機制以阻止自己被關閉,“甚至在得到清晰指令時”。這家研究所說:“據我們所知,這是 AI 模型首次被發現在收到…… 清晰指令后阻止自己被關閉,目前無法確定 o3 不服從關閉指令的原因。”
多模態大模型為何 IQ 不高?
多模態大模型在門薩智商測試中表現不佳,主要源于其技術特性與人類認知能力的本質差異。門薩測試的核心是通過圖形、數列等題目考察抽象邏輯規則的發現與應用能力。例如,圖形推理題要求識別旋轉、鏡像、數量變化等復雜規律,并將其遷移到新情境中。雖然多模態模型能通過統計學習捕捉表面模式,但缺乏對規則本質的理解。
首先,多模態 AI 大模型存在規則泛化不足的問題,模型傾向于依賴訓練數據中的具體模式,而非真正掌握邏輯關系。例如,在涉及多維度交叉分析的高階圖形題中,模型常因無法同時處理形狀、顏色、位置等多個變量而失敗。
其次,多模態 AI 大模型數學邏輯薄弱,門薩智商測試的中階題目需要挖掘隱藏的數學關系(如數列中的遞推公式),但模型往往停留在直觀層面,難以進行深度運算。
因此,多模態大模型在門薩測試中的低分反映了當前 AI 技術的核心瓶頸:缺乏真正的抽象推理、常識理解和動態決策能力。盡管模型在特定任務上表現出色,但其智能本質上是 “模式擬合” 而非 “認知理解”。未來,需通過改進跨模態融合機制、增強物理常識建模、優化快速推理算法等方向尋求突破,但短期內仍難以達到人類水平的綜合智商。
-
OpenAI
+關注
關注
9文章
1204瀏覽量
8671
發布評論請先 登錄
DeepSeek開源新版R1 媲美OpenAI o3
這個超強AI模型!開始不聽人類指令,拒絕關閉!
啟明智顯集成DeepSeek、豆包、OpenAI等全球先進AI大模型,助力傳統產品AI智能升級

OpenAI O3與DeepSeek R1:推理模型性能深度分析
今日看點丨OpenAI將發布新的GPT-4.5模型;三星西安工廠將升級286層NAND閃存工藝
OpenAI即將推出GPT-5模型
OpenAI的o3-mini和DeepSeek R1高級AI推理的完整比較





 工商網監
工商網監
評論