") 沐曦MXMACA軟件平臺(tái)在大模型訓(xùn)練方面的優(yōu)化效果
沐曦MXMACA軟件平臺(tái)在大模型訓(xùn)練方面的優(yōu)化效果

作者:王順飛
沐曦PDE部門
在如今的人工智能浪潮中,大規(guī)模語言模型(上百億乃至千億參數(shù))正迅速改變著我們的工作和生活。然而,訓(xùn)練這些龐大的模型往往面臨“算力不足、顯存不夠用、通信太慢”等諸多挑戰(zhàn)。為了讓大模型的訓(xùn)練過程更順暢、更高效,沐曦MXMACA軟件平臺(tái)(簡(jiǎn)稱 MXMACA)具有無縫兼容CUDA的能力,科學(xué)兼容Megatron-LM[1]的絕大多數(shù)特性。此外,MXMACA進(jìn)行多方面的優(yōu)化,幫助科研人員和工程師能夠快速在沐曦硬件環(huán)境中完成各類前沿模型的訓(xùn)練。下面,我們將從幾個(gè)關(guān)鍵角度介紹MXMACA在大模型訓(xùn)練方面的改進(jìn)思路和優(yōu)化效果,讓更多的讀者輕松了解“大模型訓(xùn)練背后的那些事”。
1為什么要優(yōu)化大模型訓(xùn)練?
通常,大模型采用「張量并行(Tensor Parallel, TP)+ 流水線并行(Pipeline Parallel, PP)+ 數(shù)據(jù)并行(Data Parallel, DP)+ 序列并行(Sequence Parallel, SP + 專家并行(Expert Parallel,EP)+ 上下文并行(Context Parallel, CP))」的多維并行策略,讓成百上千張 GPU 同時(shí)參與訓(xùn)練。然而,隨著模型參數(shù)量飆升(DeepSeek V3為6710億參數(shù)),單靠原版 Megatron-LM 往往會(huì)遇到以下幾個(gè)難題:
1MoE模型負(fù)載均衡訓(xùn)練困境
MoE 模型訓(xùn)練會(huì)出現(xiàn)「熱門專家」被過度調(diào)用而導(dǎo)致計(jì)算和顯存極不均勻,拖慢訓(xùn)練速度且易導(dǎo)致顯存溢出。此外,跨節(jié)點(diǎn)的 AlltoAll 通信占據(jù)了較多的訓(xùn)練時(shí)間。
2計(jì)算與通信資源競(jìng)爭(zhēng)
在分布式訓(xùn)練中,過細(xì)的模型切分雖然可以提升計(jì)算并行度,但往往會(huì)大幅增加跨節(jié)點(diǎn)通信開銷。特別是在計(jì)算與通信需要共享硬件資源的原生并行架構(gòu)中,計(jì)算操作和通信操作會(huì)相互競(jìng)爭(zhēng)有限的帶寬和計(jì)算單元,這種資源爭(zhēng)用問題常常導(dǎo)致實(shí)際并行效率低于理論預(yù)期。
3顯存(GPU內(nèi)存)吃緊
大模型需要存儲(chǔ)很多“中間計(jì)算結(jié)果”(比如激活值、梯度、優(yōu)化器狀態(tài))和大量參數(shù),當(dāng)模型規(guī)模上升時(shí),很容易出現(xiàn)“顯存不夠用”的狀況,導(dǎo)致訓(xùn)練中斷,進(jìn)而影響效率。
4集群訓(xùn)練挑戰(zhàn)
當(dāng)你用成百上千塊 GPU 訓(xùn)練一個(gè)模型時(shí),如何把每一種并行方式合理組合,才能既不爆顯存又能讓計(jì)算滿載?靠人工一遍遍嘗試,不但耗時(shí),還容易錯(cuò)過更優(yōu)的組合。集群訓(xùn)練如何減少因故障導(dǎo)致的中斷和資源浪費(fèi),如何快速定位慢節(jié)點(diǎn),都是集群訓(xùn)練常遇的挑戰(zhàn)。
5低效算子瓶頸
大模型訓(xùn)練常受限于某些關(guān)鍵算子的低效實(shí)現(xiàn),這些顯存訪問密集型算子是拉低模型MFU的一個(gè)重要因素。
為了解決這些痛點(diǎn),我們結(jié)合沐曦曦云C系列GPU的硬件特點(diǎn),做了多方面的“落地優(yōu)化”。既保留了框架的靈活性,也在常見疑難場(chǎng)景中提供了“一鍵開關(guān)”式的配置。下面我們將從 MoE 優(yōu)化、計(jì)算通信并行、顯存優(yōu)化、自動(dòng)調(diào)優(yōu)與集群訓(xùn)練、算子融合等幾個(gè)重點(diǎn)模塊,逐一展開。
2MoE優(yōu)化:讓混合專家訓(xùn)練更從容
Mixture-of-Experts(MoE)是日益流行的混合專家模型,通過路由讓tokens選擇相應(yīng)的專家計(jì)算,能夠顯著提升模型容量與表達(dá)能力。然而,同時(shí)也帶來了專家之間負(fù)載不均、顯存爆炸等挑戰(zhàn)。MXMACA 針對(duì) MoE 提供了多種優(yōu)化策略,幫助你在顯存和吞吐之間找到更好的平衡。
2.1“冷熱專家”優(yōu)化:削峰填谷式通信減負(fù)
問題背景
在MoE 模型訓(xùn)練初期,某些專家會(huì)被大量 token 路由(“熱門”),而其他專家?guī)缀蹰e置。這導(dǎo)致頻繁且不均勻的 AlltoAll 通信:熱門專家所在的顯卡要不斷從多臺(tái)顯卡拉數(shù)據(jù),通信開銷巨大。
優(yōu)化方法
本地備份熱門專家:在模型剛開始訓(xùn)練時(shí),把被訪問最頻繁的幾位“熱門專家”在本地多復(fù)制一份,這樣熱門專家的計(jì)算就可以留在本地完成,減少跨節(jié)點(diǎn)通信。
在訓(xùn)練后期,當(dāng)各個(gè)專家訪問次數(shù)趨于均衡時(shí),再把本地備份關(guān)閉,恢復(fù)普通通信模式。
通俗比喻
想象一個(gè)在線商店,某款商品突然在一兩個(gè)城市爆火,下單量激增。如果所有訂單都要從遠(yuǎn)在總部的倉(cāng)庫發(fā)貨,就會(huì)出現(xiàn)“配送中心爆倉(cāng)、快遞車來回奔波”導(dǎo)致遲遲配送不到顧客手中。優(yōu)化方式就好比在每個(gè)城市中心先存放幾箱這款熱銷商品,顧客下單之后直接從本地倉(cāng)庫發(fā)貨,大大縮短配送路徑。等到熱度消退、全國(guó)范圍內(nèi)需求趨于均衡時(shí),再把多余的本地庫存退回到總部或取消本地備貨。一句話:把“最暢銷的那幾件”臨時(shí)放到客戶附近供他們隨時(shí)取,就能避免每次都從很遠(yuǎn)的倉(cāng)庫拉貨。
優(yōu)化效果
減少跨節(jié)點(diǎn)通信:熱門專家不用每次都“喊話”遠(yuǎn)端節(jié)點(diǎn);
性能提升:訓(xùn)練吞吐量提高約 8%;
顯存可控:因?yàn)橹唤o幾個(gè)熱門專家多留一份,所以額外顯存開銷有限。
2.2MoE自適應(yīng)重計(jì)算:“分工不均”與節(jié)點(diǎn)溢出
問題背景
在 MoE 前向(Forward)/反向(Backward)時(shí),Batch 內(nèi)的某些 token 會(huì)被路由到熱門專家(Expert),導(dǎo)致該專家對(duì)應(yīng)的 GPU 需要處理大量激活,占用顯存陡增,容易 OOM(Out-Of-Memory)。尤其是在訓(xùn)練早期,token 分配波動(dòng)較大,很難預(yù)先調(diào)好“重計(jì)算參數(shù)”。
優(yōu)化方法
動(dòng)態(tài)偵測(cè):在每個(gè)訓(xùn)練 Step 之前,先統(tǒng)計(jì)當(dāng)前各個(gè)“專家并行 Rank”所分配到的 token 總數(shù)量;
閾值觸發(fā):若某個(gè) Rank 分配到的 token 數(shù)量超過預(yù)設(shè)閾值,則自動(dòng)開啟重計(jì)算邏輯;否則保持常規(guī)計(jì)算;
智能開關(guān):對(duì)不同的moe dispatcher采用不同的重計(jì)算方式。
通俗比喻
當(dāng)你和同事們分?jǐn)偘釚|西時(shí),如果A同事拿了特大箱子,其他人手都空著。這時(shí),你會(huì)讓A暫時(shí)把一些東西放地上(重新計(jì)算),等到他搬完一部分再回來挑起;等到大家分工均勻了,就恢復(fù)正常搬運(yùn)。這樣既能讓大家都忙起來,也避免了某個(gè)人因超負(fù)荷工作而累倒。
優(yōu)化效果
提升性能:只有在必要情況下才啟動(dòng)重計(jì)算,大部分時(shí)間都能用最快的方式跑;
更穩(wěn)定:即使訓(xùn)練初期數(shù)據(jù)分配不均,也不會(huì)因OOM而中斷訓(xùn)練。
2.3DualPipeV:“雙向流水線”
問題背景
DeepSeek提出的DualPipe[2]方案需要在流水線并行(Pipeline Parallel)中為模型參數(shù)保留兩份拷貝,這對(duì)顯存要求極高,且在 Bubble 較大的場(chǎng)景下并行效率有限。
優(yōu)化方法
DualPipeV將模型在 PP 維度拆分為前半段(PP0- PPN/2-1)與后半段(PPN/2- PPN-1):
前半段按照PP順序(PP0- PPN/2-1),看做一個(gè)完整模型布置到所有節(jié)點(diǎn)上;
后半段按照PP逆序(PPN-1- PPN/2),看做一個(gè)完整模型布置到所有節(jié)點(diǎn)上。
兩組之間交替發(fā)送激活與梯度,充分減少空閑等待時(shí)間。這樣,只需在每張顯卡上保留一份參數(shù)拷貝,同時(shí)保持較高的流水線并行度。

圖1 DualPipeV示例圖
來源:https://github.com/deepseek-ai/DualPipe
通俗比喻
就像工廠生產(chǎn)線:如果把生產(chǎn)過程切成兩半,整個(gè)流水線是一個(gè)V字型,每組工人在處理前半個(gè)流水線的一道工序的同時(shí),負(fù)責(zé)后半個(gè)流水線的一道工序。當(dāng)其中一道工序需要等待時(shí),可以處理另一道工序,甚至可以雙管齊下,兩側(cè)工序同時(shí)進(jìn)行。
優(yōu)化效果
顯存降低:相比傳統(tǒng)Dualpipe,僅需保存一份參數(shù)拷貝,顯存降低約 20%;
吞吐提升:減少流水線階段之間的空閑(氣泡),整體訓(xùn)練速度提升可達(dá) 10% 以上。
2.4MoE多級(jí)內(nèi)存優(yōu)化:“分層卸載”
問題背景
除了前面提到的“某些專家突然超載”情況,整個(gè)專家(MoE)網(wǎng)絡(luò)里還有很多“子環(huán)節(jié)”、各種小運(yùn)算(例如:激活函數(shù)、向量重排、共享專家算子等),在顯存吃緊的時(shí)候,也需要“分級(jí)”來處理。
優(yōu)化方法
把專家里最“耗顯存”的幾個(gè)步驟,分成幾個(gè)層級(jí):
輕量級(jí)重計(jì)算:只對(duì)激活函數(shù)、向量重排、router路由這些小環(huán)節(jié)做重計(jì)算;
中度重計(jì)算:在上面基礎(chǔ)上,選擇專家內(nèi)部的某些全連接層和共享專家(Shared Expert)做重計(jì)算。
全量重計(jì)算:MoE模型部分全量做重計(jì)算。
多層級(jí)重計(jì)算,可以將顯存浪費(fèi)降到最低,同時(shí)盡可能保持訓(xùn)練速度。
通俗比喻
想象訓(xùn)練MoE模型像在沙漠探險(xiǎn)。 顯存是珍貴的駱駝運(yùn)力(負(fù)重能力)。輕量: 只背少量必需品(省運(yùn)力,稍慢)。中度: 選擇性背大件(平衡運(yùn)力與速度)。全量: 所有裝備現(xiàn)用現(xiàn)造(運(yùn)力最省,行動(dòng)最慢)。分層選擇,用最小速度代價(jià)換最大運(yùn)力空間。
優(yōu)化效果
更靈活:根據(jù)顯存緊張程度,采用不同層級(jí)的內(nèi)存優(yōu)化方法;
損失更小:做最合適的顯存優(yōu)化,讓性能損失最低。
在顯存緊張的思路下,多級(jí)內(nèi)存優(yōu)化相較于不優(yōu)化時(shí)能節(jié)省 12% 左右的顯存峰值,而整體訓(xùn)練速度僅損失3% 左右,為中小集群訓(xùn)練帶來顯著價(jià)值。
2.5MoE Batch GEMM:讓專家計(jì)算“匯成批”一次到位
問題背景
在 MoE模型 中,不同專家收到的輸入token數(shù)量往往不同,這導(dǎo)致每個(gè)專家要做的矩陣乘法(GEMM)大小不一。GPU 在處理大小不一的矩陣運(yùn)算時(shí),可以采用groupgemm提升算力利用率,但相對(duì)于均勻計(jì)算,效率還是有所降低。
優(yōu)化方法
把輸入長(zhǎng)度 “對(duì)齊”:在進(jìn)入專家前,給“超量輸入”專家丟棄一些數(shù)據(jù), 給“少量輸入”的專家補(bǔ)上一些“空白”數(shù)據(jù),這樣讓所有專家的輸入長(zhǎng)度一致;
然后把所有專家的矩陣乘法合并到一個(gè)“批量(Batch)GEMM”操作里一次性完成,充分利用 GPU 的并行能力。
通俗比喻
想象你有好幾批貨,大小差異很大,不利于裝入標(biāo)準(zhǔn)箱進(jìn)行一次性搬運(yùn)。這時(shí)讓較大的貨物,拿去一部分,較小的貨物,添加一部分,就可以一次性把好幾個(gè)標(biāo)準(zhǔn)箱同時(shí)裝車,搬運(yùn)效率更高。
優(yōu)化效果
大幅提升 GPU 利用率:在實(shí)驗(yàn)中,可提升專家計(jì)算效率約 15%;
略微精度影響:因?yàn)?Batch GEMM 會(huì)做少量的tokens丟棄,對(duì)精度有少量影響。但從長(zhǎng)期訓(xùn)練看,模型loss誤差在1%以內(nèi),對(duì)整體模型效果幾乎沒有影響。
3計(jì)算與通信并行:讓“傳輸”更無縫
在大規(guī)模并行訓(xùn)練中,“算”與“傳”往往會(huì)發(fā)生沖突:當(dāng) GPU 在做大矩陣計(jì)算時(shí),卻要停下來做 AllReduce/AlltoAll等通信,結(jié)果就是一邊算,一邊等。或者在已有的“算”與“傳”并行場(chǎng)景中,兩者發(fā)生硬件資源競(jìng)爭(zhēng),導(dǎo)致性能相互影響。MXMACA 主要通過 SDMA、通算融合算子等手段,盡量讓“算”與“傳”不再相互干擾。
3.1SDMA通信并行:讓設(shè)備側(cè)“專屬搬運(yùn)工”來接手
問題背景
在計(jì)算通信并行場(chǎng)景中,由于GPU核心既承擔(dān)計(jì)算任務(wù),又承擔(dān)通信任務(wù)(如AllGather、ReduceScatter),容易導(dǎo)致資源競(jìng)爭(zhēng),使得通信與計(jì)算互相拖慢。
優(yōu)化方法
沐曦C系列 GPU 內(nèi)置了 SDMA引擎,可以讓顯卡側(cè)在節(jié)點(diǎn)內(nèi)專門負(fù)責(zé)高速數(shù)據(jù)傳輸。
節(jié)點(diǎn)間使用CPU和網(wǎng)卡來實(shí)現(xiàn)通信傳輸。
通信最大程度減少對(duì)GPU的使用,可以有效減輕互相搶資源的情況。
通俗比喻
SDMA通信引擎的實(shí)現(xiàn),就好像生產(chǎn)車間里出現(xiàn)了“自動(dòng)小推車”,一臺(tái)機(jī)器算完半成品后,直接把它放到小推車上,小推車負(fù)責(zé)自動(dòng)把零件送到下一個(gè)工作臺(tái);原來那臺(tái)機(jī)器不用為送貨而分?jǐn)偩Α?/p>
優(yōu)化效果
減少“算”和“傳”互相搶資源:其結(jié)果是訓(xùn)練速度能提高約 4%~8%;
簡(jiǎn)單易用:只需在訓(xùn)練時(shí)打開相應(yīng)開關(guān),SDMA 就自動(dòng)接管通信。
3.2Tensor Parallel Overlap(TP Overlap):計(jì)算與通信融合
問題背景
在 TP(張量并行)切分場(chǎng)景下,計(jì)算與通信的依賴關(guān)系難以打通:
有依賴關(guān)系的算子(如 GEMM → ReduceScatter),無法并行;
無依賴關(guān)系的算子(如部分 Compute + Allgather),則會(huì)與計(jì)算搶占 GPU 資源。
優(yōu)化方法
GEMM+ReduceScatter/AllGather 融合:
將 GEMM 計(jì)算與通信算子寫入同一個(gè) CUDA Kernel 中,直接將 GEMM 結(jié)果遠(yuǎn)寫到其他 GPU,省去了顯存讀寫與 kernel 啟動(dòng)開銷。同時(shí)實(shí)現(xiàn)了通信和計(jì)算細(xì)粒度切分,使細(xì)粒度間的計(jì)算和通信任務(wù)不存在依賴關(guān)系,從而并行執(zhí)行。
2.無依賴算子 SDMA 傳輸:
對(duì)于無依賴關(guān)系的通信算子(如BWD中部分AllGather或者ReduceScatter),使用SDMA完成,從而避免與Compute算子爭(zhēng)奪內(nèi)存帶寬和算力資源。
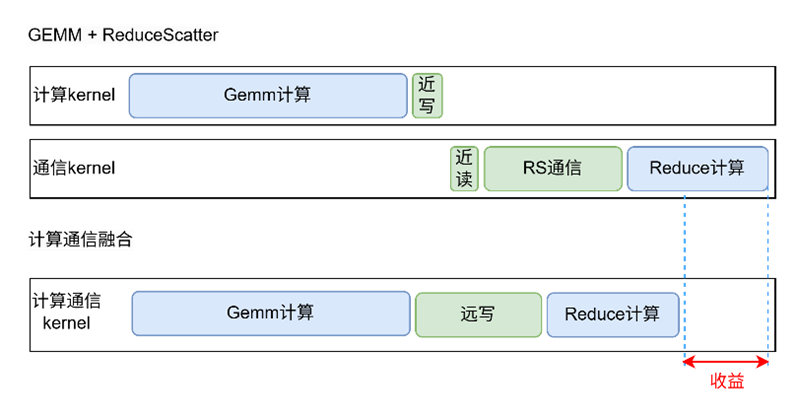
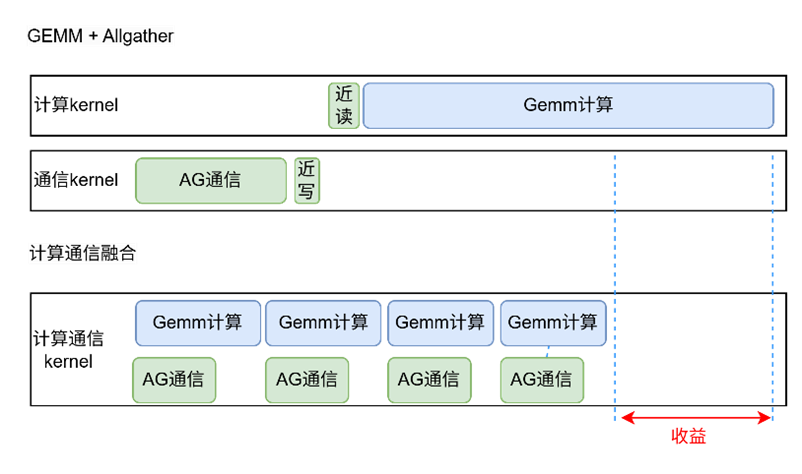
圖2 TP overlap融合算子示例圖
通俗比喻
好比生產(chǎn)線上的半成品不再“先放到貨架,再由叉車搬去下一個(gè)工序”;而是在同一個(gè)環(huán)節(jié)里邊加工邊傳送,讓“傳送”像流水一樣跟著“加工”一起走,省掉了中途的反復(fù)搬運(yùn)。顯卡就像流水線上的工人,既動(dòng)手加工又順手交接,效率顯著提升。
優(yōu)化效果
GEMM+RS/AG 融合使得通信開銷降低 20% 左右,顯存占用更友好;
與 SDMA 聯(lián)合使用時(shí),在通信瓶頸明顯的場(chǎng)景,可帶來5%~10%的整體訓(xùn)練加速;
由于通信與計(jì)算沖突減少,GPU 利用率相比原生 Megatron-LM 提升 7%~10%。
3.3MoE Comm Overlap:讓 MoE 通信與專家計(jì)算并行
問題背景
在原生Megatron-LM的MoE 中,單層 Transformer 里前向會(huì)有兩個(gè) AlltoAll,反向也有兩個(gè)AlltoAll。這些通信操作往往與專家(Expert)計(jì)算串行執(zhí)行,導(dǎo)致并行度嚴(yán)重不足。
優(yōu)化方法
通過將 MoE 層劃分為多個(gè)子單元,實(shí)現(xiàn) AlltoAll 通信與專家計(jì)算的高度并行:
將其中兩個(gè) AlltoAll 與 Shared Expert 的前向和反向計(jì)算并行;
另外的AlltoAll與D/W分離后的專家計(jì)算并行。
理論上可達(dá) 75% 的全 Overlap 率,相比原生Overlap水平大幅提升。
通俗比喻
MoE Comm Overlap,相當(dāng)于原始MoE計(jì)算和通信都在一條路上,現(xiàn)在增加了一條路,通過計(jì)算通信分解,讓AlltoAll通信單獨(dú)走一條路,大大減少來回等待。
優(yōu)化效果
在 DeepSeek V3中,MoE Comm Overlap 使得AlltoAll通信與計(jì)算并行度提升約 3 倍:
單層 AlltoAll Overlap 達(dá)到 75% 理論并行度;
整體 MoE 訓(xùn)練吞吐率提升 8%~10%;
訓(xùn)練中每個(gè)迭代的 Loss 相對(duì)誤差低于 1%,沒有明顯精度損失。
4顯存優(yōu)化:多維度“榨干”硬件潛力
訓(xùn)練時(shí)的顯存就像錢包里的空間,裝不下就會(huì)“爆卡”。 MXMACA提供了一系列顯存優(yōu)化策略,從 Granular Activation Offload到Granular Recompute,多管齊下幫你“花最少的錢,裝最多的東西”,讓有限的顯存能撐起更大規(guī)模的訓(xùn)練任務(wù)。
4.1細(xì)粒度激活offload:只“偷工”不“減質(zhì)”
問題背景
在流水線并行中,不同階段(Pipeline Stage)需要存儲(chǔ)的“中間激活數(shù)據(jù)”數(shù)量并不一樣。有些階段需要保留很多激活,有些階段只需要少量。若直接把所有激活都卸載到主機(jī)內(nèi)存,勢(shì)必增加大量數(shù)據(jù)傳輸,很難與計(jì)算相互掩蓋,拖慢訓(xùn)練。
優(yōu)化方法
區(qū)分階段卸載需求:只把第一個(gè)stage的激活卸載到主機(jī)內(nèi)存,讓后面幾個(gè)stage保留在顯存里;
或者根據(jù)實(shí)際顯存壓力,對(duì)某幾層激活做卸載,而其他層保留在顯存中;
這樣在需要時(shí)再把它們提前拉回來,不用每一層都卸載,占用帶寬和時(shí)間最小。
通俗比喻
就像搬家時(shí),你把最重的家具先搬到小車上存放,但把沙發(fā)、床這些需要馬上用的常駐在家里。等到后面空間還緊張,再逐個(gè)決定把哪幾個(gè)“沒那么急”的物件先運(yùn)出去。這樣既不占用車的所有空間,也避免了一次性搬空再慢慢拉回來的低效。
優(yōu)化效果
減少不必要的卸載/加載:最大限度保留訓(xùn)練速度,相對(duì)于普通重計(jì)算方法,在LLaMA2-70B訓(xùn)練上可以提升約6%的性能;
顯存更靈活使用:即使顯存并不充裕,也能讓大模型跑起來。
4.2
細(xì)粒度重計(jì)算:對(duì)輕量計(jì)算分層重計(jì)算
問題背景
重計(jì)算在顯存緊張時(shí)非常有效,但如果把所有計(jì)算都重算一遍(全量重計(jì)算),會(huì)讓整體訓(xùn)練速度大幅下降。很多時(shí)候,僅把“輕量”的那部分(例如歸一化層或激活函數(shù))重算,就能騰出不少顯存,又影響不大。
優(yōu)化方法
Norm 重計(jì)算:只把歸一化層(LayerNorm)相關(guān)的中間結(jié)果釋放顯存,反向時(shí)再重算。
激活函數(shù)重計(jì)算:只把激活函數(shù)(如 GELU、Swiglu 等)的中間結(jié)果釋放顯存,反向時(shí)再重算。
不均勻細(xì)粒度:對(duì)不同的PP stage,因?yàn)轱@存壓力不同,使用的重計(jì)算方法和重計(jì)算力度也可以不同。
我們可以根據(jù)實(shí)際顯存壓力和性能需求,把“Norm 重算”和“激活重算”與傳統(tǒng)的“全量重算”靈活組合。例如:在某些階段只做 Norm 重計(jì)算,其他階段保持全量;或者只做激活重計(jì)算……總之,以最小代價(jià)解決顯存不足問題。
通俗比喻
該比喻和細(xì)粒度激活卸載類似。
優(yōu)化效果
顯存騰得更多:相同“省顯存”目標(biāo)下,比起全量重計(jì)算,速度更快;
靈活組合:既能滿足“極限省顯存”場(chǎng)景,也能兼顧訓(xùn)練速度。
5自動(dòng)搜索與集群訓(xùn)練:
邁向“零調(diào)優(yōu)”時(shí)代
當(dāng)訓(xùn)練規(guī)模從數(shù)十張GPU擴(kuò)展到成百上千張GPU 時(shí),手動(dòng)在多維并行維度上逐個(gè)嘗試,幾乎是不可能在有限時(shí)間里搞定的工作。MXMACA 通過“Auto Search”引擎和“DLRover”[4]兩大工具,實(shí)現(xiàn)了自動(dòng)化調(diào)優(yōu)與容錯(cuò)加速,讓你更專注于算法設(shè)計(jì)與數(shù)據(jù)準(zhǔn)備,而非配置參數(shù)。
5.1Auto Search:一鍵找到最佳并行方案
問題背景
在 Megatron-LM 里,你可能同時(shí)考慮張量并行(Tensor Parallel)、流水線并行(Pipeline Parallel)、數(shù)據(jù)并行(Data Parallel)、專家并行(MoE Parallel)等維度。不同組合下,顯存占用和性能差別巨大,要人工一一嘗試,既浪費(fèi)時(shí)間,也容易錯(cuò)過更優(yōu)解。
優(yōu)化方法
MXMACA 引入一套基于算子、顯存與通信三大模塊的自動(dòng)調(diào)優(yōu)(Auto Search)引擎:
構(gòu)建性能模型:
對(duì)常見算子(GEMM、AllReduce、AlltoAll、Offload、Recompute 等)進(jìn)行微基準(zhǔn)測(cè)試;
對(duì)不同顯存策略(Recompute、Offload等)下的單節(jié)點(diǎn)性能進(jìn)行采樣;
對(duì)常見網(wǎng)絡(luò)拓?fù)洌?D Mesh、MetaLink等)下通信性能進(jìn)行建模。
2.全局搜索與預(yù)測(cè):
基于先驗(yàn)遍歷TP/PP/EP等切分空間,自動(dòng)枚舉候選配置;
結(jié)合性能模型,快速估算各候選切分配置在多節(jié)點(diǎn)下的 TGS(Token per GPU per Second)與顯存占用;
打分排序后,輸出 Top-k 最優(yōu)配置。
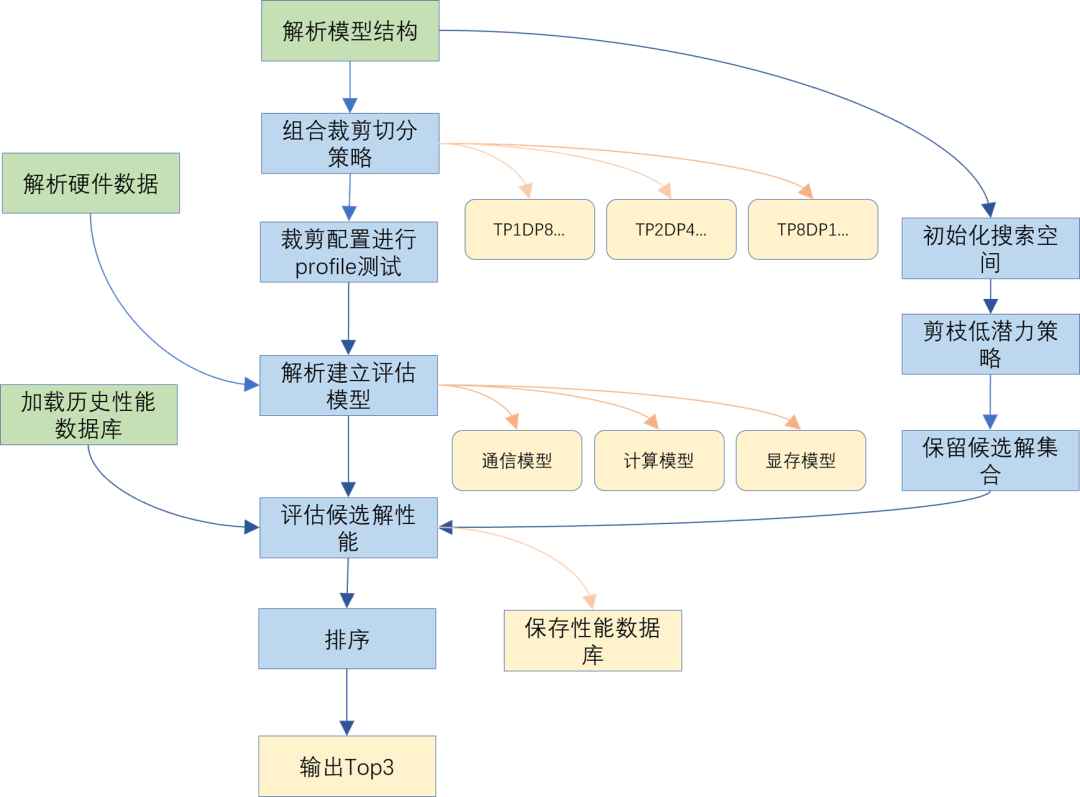
圖3 Auto Search自動(dòng)搜索圖
通俗比喻
就像你要組織一次大規(guī)模搬家,有幾百個(gè)箱子、幾十輛卡車,各卡車載重不同、路況也不同。傳統(tǒng)做法是“卡車 A 多裝點(diǎn)、卡車 B 少裝點(diǎn)、卡車C 跑好點(diǎn)……”人工來回摸索。Auto Search 就是提前用模型測(cè)算好哪幾種裝載方案最經(jīng)濟(jì),給你一個(gè)“前五優(yōu)選”,你只需要挑個(gè)最方便的兌現(xiàn)即可。
優(yōu)化效果
省時(shí)省力:從“試錯(cuò)式”調(diào)參變成“一次性推薦”;
效果可靠:背后有數(shù)據(jù)模型支撐,不會(huì)輕易被主觀偏差誤導(dǎo);
靈活可擴(kuò)展:適用于不同規(guī)模的集群、不同目標(biāo)(更省顯存或更高吞吐)。
5.2DLRoverFlash Checkpoint(“閃電”持久化)
問題背景
大型分布式訓(xùn)練任務(wù)常因節(jié)點(diǎn)故障或網(wǎng)絡(luò)抖動(dòng)導(dǎo)致中斷,因?yàn)楣收蠈?dǎo)致的集群空閑和回滾訓(xùn)練,都會(huì)導(dǎo)致集群資源的浪費(fèi)。另一方面,在訓(xùn)練過程中,往往需要向存儲(chǔ)介質(zhì)一次性寫入數(shù)百上千 GB 數(shù)據(jù),耗時(shí)數(shù)分鐘甚至十幾分鐘,影響迭代效率。
優(yōu)化方法
借助DLRover Flash Checkpoint 機(jī)制,將訓(xùn)練狀態(tài)(包括模型權(quán)重、優(yōu)化器狀態(tài)、學(xué)習(xí)率調(diào)度狀態(tài)等)先寫入CPU,再異步持久化到分布式文件系統(tǒng)。主要優(yōu)勢(shì)有:
異步寫入:
前端將 Checkpoint 數(shù)據(jù)同步寫入CPU即可返回,訓(xùn)練阻塞時(shí)間降至最短,達(dá)到秒級(jí);
后端異步從CPU將模型數(shù)據(jù)寫入文件系統(tǒng),充分利用 CPU 與網(wǎng)絡(luò)帶寬。
2.故障恢復(fù):
若節(jié)點(diǎn)瞬時(shí)宕機(jī),DLRover 可瞬間將CPU內(nèi)存模型數(shù)據(jù)強(qiáng)制落盤,不會(huì)出現(xiàn) Checkpoint 丟失;
對(duì)于非完整節(jié)點(diǎn)宕機(jī),在模型數(shù)據(jù)落盤后,會(huì)從冗余節(jié)點(diǎn)中選取節(jié)點(diǎn)替換故障節(jié)點(diǎn),并自動(dòng)拉起訓(xùn)練。
通俗比喻
就像你在寫文檔時(shí),Word 會(huì)自動(dòng)把內(nèi)容先存在緩存里,然后后臺(tái)再慢慢寫到硬盤;如果電腦突然關(guān)機(jī),緩存里最后的內(nèi)容會(huì)被緊急落盤,下次打開就能直接恢復(fù)到緩存時(shí)的狀態(tài)。
優(yōu)化效果
在千卡級(jí)別集群上,DLRover Flash Checkpoint 將大小1T左右的 Checkpoint 寫盤時(shí)間從 10 分鐘縮減到 10秒以內(nèi);節(jié)省85%因?yàn)榧汗收蠈?dǎo)致的訓(xùn)練回滾和空閑時(shí)間。
5.3慢節(jié)點(diǎn)檢測(cè):迅速找出與剖析“拖后腿”的那臺(tái)
問題背景
在大集群訓(xùn)練中,某臺(tái)機(jī)器網(wǎng)絡(luò)帶寬突然變差、某塊顯卡溫度過高降頻、或者其他硬件異常等等,都會(huì)讓那臺(tái)節(jié)點(diǎn)訓(xùn)練速度變慢。可一旦出現(xiàn)“1 臺(tái)慢”,整個(gè)訓(xùn)練“隊(duì)伍”就會(huì)被拖慢,因?yàn)榇蠹倚枰却?/p>
優(yōu)化方法
內(nèi)置 MCTX(MXMACA Tools Extension):在訓(xùn)練中,自動(dòng)給“前向”“反向”“通信”“優(yōu)化”等各環(huán)節(jié)加上“埋點(diǎn)”,記錄耗時(shí)、網(wǎng)絡(luò)延遲等細(xì)節(jié)。
分層級(jí)別監(jiān)測(cè):可只看最關(guān)鍵的“前向/反向/優(yōu)化耗時(shí)”(Level 0),也可以看更細(xì)的“每個(gè)算子、每次通信操作耗時(shí)”(Level 1/Level 2),精度高到看到“某個(gè)節(jié)點(diǎn)的 AlltoAll 通信慢了 20%”。
自動(dòng)告警與定位:一旦發(fā)現(xiàn)某個(gè)節(jié)點(diǎn)在某個(gè)環(huán)節(jié)耗時(shí)顯著高于平均值,就會(huì)報(bào)告給用戶,幫助工程師迅速定位到“哪臺(tái)機(jī)器的哪一步出了問題”。
通俗比喻
就像車隊(duì)比賽時(shí),攝影機(jī)會(huì)記錄每輛車的圈速、過彎情況、進(jìn)站時(shí)間等。一旦發(fā)現(xiàn)某輛車某圈速度比別人慢,就立即發(fā)出提示,幫助車隊(duì)找出“哪里出現(xiàn)了瓶頸”(比如輪胎不行、油壓不穩(wěn)、駕駛員操作問題等),及時(shí)修正,保持整體隊(duì)速。
優(yōu)化效果
極大節(jié)省排查時(shí)間:不用手動(dòng)遠(yuǎn)程登錄到每臺(tái)機(jī)器一遍遍看日志;
精確定位瓶頸:從整體到算子級(jí)別都可監(jiān)測(cè),找到“問題根源”;
訓(xùn)練更穩(wěn)定:及時(shí)剔除或修復(fù)“慢節(jié)點(diǎn)”,維持整個(gè)集群的高速運(yùn)行。
6其他輔助優(yōu)化手段:
從小細(xì)節(jié)中獲取額外收益
除了上面提到的幾個(gè)核心方向,MXMACA 還在算子融合、并行調(diào)度等細(xì)節(jié)方面做了許多打磨,讓整體訓(xùn)練更順滑。下面簡(jiǎn)要介紹兩項(xiàng)常見的補(bǔ)充優(yōu)化。
6.1算子融合(Flash Fusion):把“小動(dòng)作”合并成“大動(dòng)作
問題背景
模型里有很多很常見但“零碎”(Memory bound)的操作,比如 “加偏置再激活再 Dropout 再相加” 這一連串動(dòng)作,如果每一步都拆成單獨(dú)算子去執(zhí)行,就會(huì)大量占用顯存帶寬和啟動(dòng)內(nèi)核的開銷。
優(yōu)化方法
算子分析:分析模型中存在的高頻且memory bound的小算子,提取連續(xù)小算子操作的pattern。
算子融合:對(duì)連續(xù)小算子操作設(shè)計(jì)融合算子,盡量減少中間內(nèi)存讀寫與 Kernel 啟動(dòng)次數(shù)。
支持的融合模式包括:Swiglu (Bias Swiglu)、Repeat GQA、Bias-GELU、BDA (Bias+Dropout+Add)、RoPE、MoE-Permute/Unpermute/Router 等。
通俗比喻
想象你去餐廳吃套餐,原本你要點(diǎn)“炸雞”“薯?xiàng)l”“飲料”“沙拉”四樣,如果每次都是廚師分散地一個(gè)一個(gè)做,出餐就會(huì)慢很多;而“套餐”把它們組合成一個(gè)連貫流程,一次性煎炸加熱、打包好,效率便會(huì)高不少。
優(yōu)化效果
在DeepSeek V3 模型訓(xùn)練中,啟用 Flash Fusion 后可帶來 5%以上的性能提升,且降低了顯存占用。
6.2Zero Bubble:零氣泡流水線
問題背景
在 Pipeline Parallel(PP)中,1F1B的模型調(diào)度方式,容易產(chǎn)生“泡沫”(Bubble),即GPU閑置等待的時(shí)間,影響資源利用率。這種現(xiàn)象隨著PP的增大,或者Global Batch Size(GBS)的減小,愈加嚴(yán)重。
優(yōu)化方法
借鑒 Zero-Bubble Pipeline Parallelism[3]的思想,MXMACA集成了ZBH1(Zero Bubble H1)方案:
將傳統(tǒng) PP 中的 Bubble 率降至1/3;
不增加第1個(gè)PP Stage的顯存;
適用于 GBS較小、Bubble顯著且顯存受限的場(chǎng)景。
通俗比喻
就像一條生產(chǎn)線,原本上下游有時(shí)會(huì)錯(cuò)拍,有時(shí)會(huì)輪到機(jī)器沒料可做。Zero Bubble 就是優(yōu)化排產(chǎn)計(jì)劃,讓前后幾道工序更均勻銜接,減少待料時(shí)間。不需要給第一道工序額外加機(jī)器(顯存),卻能讓整體產(chǎn)量更高。
優(yōu)化效果
提升流水線利用率:實(shí)測(cè)在一些場(chǎng)景下可讓顯卡吞吐率提升 8%~12%;
顯存壓力不增加:Zero Bubble 并不需要給第一個(gè) Stage 多分配顯存,只要合理調(diào)整微批次順序就能降低氣泡,同時(shí)不引入額外顯存開銷;
適合顯存不足時(shí)使用:當(dāng)顯存比較緊張,無法開啟更高級(jí)的虛擬流水時(shí),Zero Bubble依然能帶來效率提升。
6.3Empty Transformer Layers:空層補(bǔ)齊
問題背景
在啟用VPP時(shí),若模型總層數(shù)與 PP Stage 數(shù)量不再為整除關(guān)系(如質(zhì)數(shù)層),常會(huì)出現(xiàn)無法均勻拆分為每 VPP Stage 保持相同層數(shù)的瓶頸。例如,61 層模型切為PP = 8 時(shí),每個(gè) Stage 無法平均分配層數(shù);又比如 15 層模型切為PP = 3 時(shí),每個(gè) Stage 均為5層,質(zhì)數(shù)層無法進(jìn)一步采用VPP切分。
優(yōu)化方法
MXMACA 提供“空層插入”(Empty Layer) 功能:
虛擬將模型層數(shù)擴(kuò)充至滿足 VPP 階段拆分需求的最小整數(shù);
在指定位置插入“空 Transformer 層”,該層僅作占位,無實(shí)際計(jì)算,保證每個(gè) PP Stage 擁有相同的 VPP Stage 數(shù)目;
額外的資源開銷僅為極少量 Metadata,無顯著顯存/計(jì)算損耗。
優(yōu)化效果
實(shí)測(cè)在 PP=8、VPP=2 場(chǎng)景下,經(jīng)過空層補(bǔ)齊的 61→64 層模型,與直接使用不均勻 PP 相比,訓(xùn)練速度提升 6% 以上。
7MXMACA大模型訓(xùn)練優(yōu)化:
極致算力,一觸即發(fā)
通過一系列“計(jì)算通信并行”、“專家模型優(yōu)化”、“顯存優(yōu)化”、“自動(dòng)調(diào)優(yōu)與集群訓(xùn)練工具”等手段,MXMACA 成功讓 Megatron-LM 在沐曦硬件環(huán)境中實(shí)現(xiàn)了如下優(yōu)勢(shì):
1更少顯存×更高性能
同等硬件條件下,訓(xùn)練時(shí)所需顯存可節(jié)省 10%~30%;
同時(shí),整體訓(xùn)練速度較原生 Megatron-LM 提升20%左右。
2更低門檻×更易部署
對(duì)非專業(yè)研發(fā)人員也非常友好:只需在訓(xùn)練腳本里打開“省顯存模式”“通信并行模式”“自動(dòng)調(diào)優(yōu)模式”等開關(guān),無需手動(dòng)調(diào)命令行參數(shù);
Auto Search 能在幾分鐘內(nèi)給出最優(yōu)并行配置,不必再費(fèi)心一個(gè)維度一個(gè)維度去嘗試。
3更高穩(wěn)定性×更強(qiáng)容錯(cuò)性
DLRover Flash Checkpoint 能讓訓(xùn)練中斷后分鐘級(jí)別就恢復(fù),而不會(huì)造成集群數(shù)小時(shí)空閑;
MCTX 監(jiān)測(cè)可自動(dòng)提示“哪臺(tái)GPU慢了”“卡在計(jì)算還是卡在通信”,幫助團(tuán)隊(duì)迅速定位并解決問題。
4豐富擴(kuò)展性×持續(xù)迭代
除了剛才講到的這些優(yōu)化,MXMACA 還在持續(xù)對(duì) DeepSpeed、PaddlePaddle、Colossal-AI 等其他主流訓(xùn)練框架做兼容與優(yōu)化;
未來也會(huì)陸續(xù)增加對(duì)新算子的融合、更多底層硬件特性的深度利用,讓大模型訓(xùn)練更“省心、更高效”。
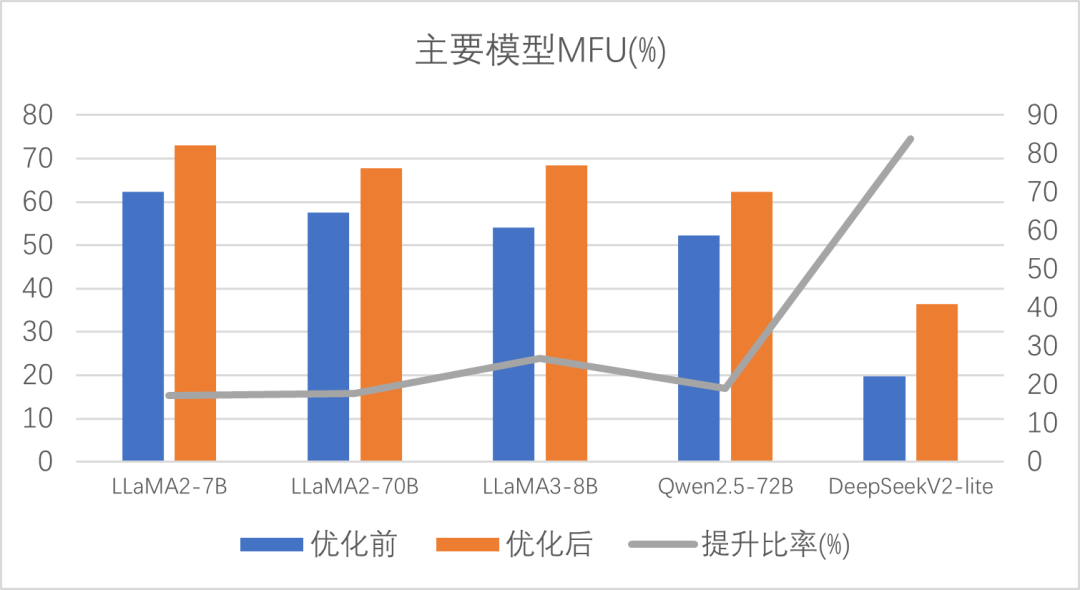
圖4 主要模型優(yōu)化前后性能及提升比率
8總結(jié):讓大模型訓(xùn)練也能“大眾化”
希望在有限硬件條件下訓(xùn)練上百億大模型
想快速配置集群并行,不想一遍遍試命令行參數(shù)
想讓訓(xùn)練過程有更強(qiáng)的容錯(cuò)、斷點(diǎn)續(xù)訓(xùn)能力
想站在“技術(shù)巨人”肩膀上,用最少的工程成本跑出最大價(jià)值
那么不妨試試 MXMACA 提供的這些優(yōu)化能力(https://developer.metax-tech.com/softnova/docker)。未來,我們也會(huì)持續(xù)迭代、不斷打磨各種新功能,助力更多團(tuán)隊(duì)、更多應(yīng)用場(chǎng)景,讓“大模型訓(xùn)練”真正實(shí)現(xiàn)“大眾化”、變得“人人可跑、人人可用”。
-
人工智能
+關(guān)注
關(guān)注
1806文章
48940瀏覽量
248343 -
沐曦
+關(guān)注
關(guān)注
0文章
33瀏覽量
1408 -
大模型
+關(guān)注
關(guān)注
2文章
3105瀏覽量
4000
原文標(biāo)題:【智算芯聞】沐曦MXMACA軟件平臺(tái):讓大模型訓(xùn)練更簡(jiǎn)單、更高效
文章出處:【微信號(hào):沐曦MetaX,微信公眾號(hào):沐曦MetaX】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
沐曦集成電路完成PreA+輪融資
沐曦首款異構(gòu)GPU芯片MXN100實(shí)現(xiàn)各類應(yīng)用場(chǎng)景和業(yè)務(wù)模型的快速遷移
沐曦與上海聯(lián)通簽署戰(zhàn)略合作協(xié)議
沐曦人工智能推理GPU曦思N100的應(yīng)用優(yōu)勢(shì)
沐曦基于曦云C500發(fā)布國(guó)產(chǎn)首臺(tái)GPU千億參數(shù)大模型訓(xùn)推一體機(jī)
完成適配!曦云C500在智譜AI升級(jí)版大模型上充分兼容、高效穩(wěn)定運(yùn)行
眸瑞科技與沐曦集成電路聯(lián)合發(fā)布首個(gè)AI模型“貼圖超分”技術(shù)
沐曦首次將AI超分成功應(yīng)用到3D模型領(lǐng)域
沐曦攜手合作伙伴共同成立“影視行業(yè)數(shù)字渲染國(guó)產(chǎn)技術(shù)示范中心”
沐曦攜人工智能推理GPU曦思N系列亮相世界計(jì)算大會(huì)
沐曦攜手富春云打造國(guó)產(chǎn)GPU華北核心算力節(jié)點(diǎn)
谷歌模型訓(xùn)練軟件有哪些?谷歌模型訓(xùn)練軟件哪個(gè)好?
澎峰科技計(jì)算軟件棧與沐曦GPU完成適配和互認(rèn)證
澎峰科技與沐曦完成聯(lián)合測(cè)試,實(shí)現(xiàn)全面兼容
Gitee AI 聯(lián)合沐曦首發(fā)全套 DeepSeek R1 千問蒸餾模型,全免費(fèi)體驗(yàn)!





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論