 電子發(fā)燒友App
電子發(fā)燒友App


【開(kāi)篇就白給?】
對(duì)大家熟悉的Cortex-M處理起來(lái)說(shuō),無(wú)論是強(qiáng)調(diào)極致資源和低功耗的Cortex-M0、還是頻率達(dá)到上GHz且能與某些應(yīng)用處理器掰一掰手腕的Cortex-M7,都不會(huì)缺席了SysTick的身影。 正因?yàn)镾ysTick是官方欽定的“不可或缺”的“基礎(chǔ)設(shè)施”,無(wú)論是RTOS系統(tǒng)還是裸機(jī)應(yīng)用,幾乎所有的嵌入式固件都會(huì)用到它。在這一背景下,如果我告訴你,有一個(gè)基于C語(yǔ)言的模塊,提供以下功能:
精確測(cè)量系統(tǒng)性能
精確測(cè)量函數(shù)執(zhí)行時(shí)間
精確測(cè)量中斷響應(yīng)延遲
提供精確到us級(jí)的阻塞或非阻塞的延時(shí)服務(wù)
改善偽隨機(jī)數(shù)的隨機(jī)數(shù)特性
提供系統(tǒng)時(shí)間戳
……
使用了SysTick卻不會(huì)占用SysTick;
或者說(shuō)提供以上功能的同時(shí),用戶的原有的SysTick應(yīng)用(比如RTOS調(diào)度器或是普通的應(yīng)用延時(shí))絲毫不會(huì)受到影響;
再直白點(diǎn)說(shuō):以上功能都是白送的,每個(gè)Cortex-M處理器都能立即享有,且不受到芯片型號(hào)的影響,
你是不是要直呼:“真就白給?”
是的!作為一個(gè)在Github上開(kāi)源的C語(yǔ)言模塊,它真就白給!
【請(qǐng)張嘴……啊~】
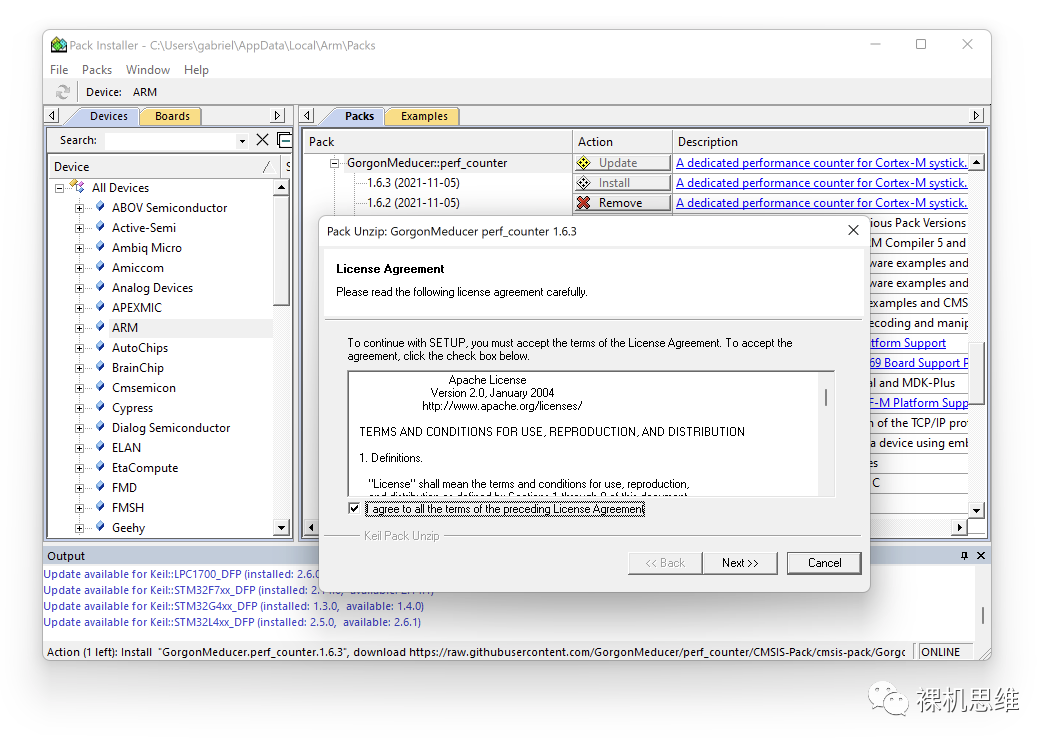
perf_counter版本一路進(jìn)化,從加入對(duì)GCC、IAR的支持、通過(guò)Library簡(jiǎn)化用戶部署以來(lái),從版本1.6.1開(kāi)始更是把模塊的部署做到了極致的簡(jiǎn)化: ? 這次,你只要從下面的鏈接“一次性”的下載 CMSIS-Pack,就可以在MDK環(huán)境中實(shí)現(xiàn)傻瓜式的部署: ? https://raw.githubusercontent.com/GorgonMeducer/perf_counter/CMSIS-Pack/cmsis-pack/GorgonMeducer.perf_counter.1.9.9.pack ? 也可以向公眾號(hào)發(fā)送?perf_counter?進(jìn)行下載。 ? 下載后,雙擊pack文件進(jìn)行無(wú)腦安裝:
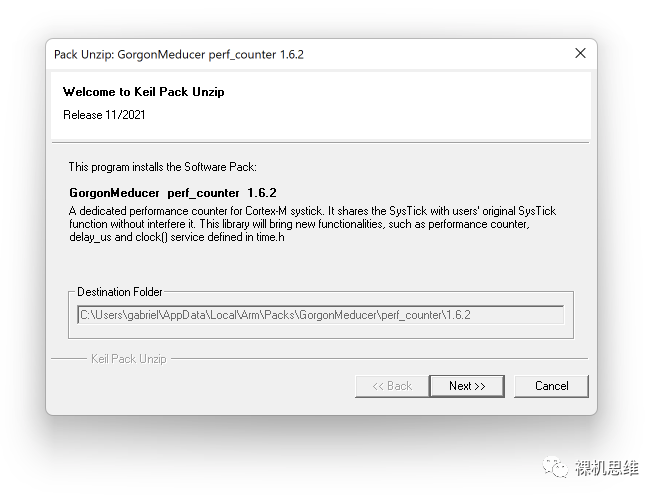
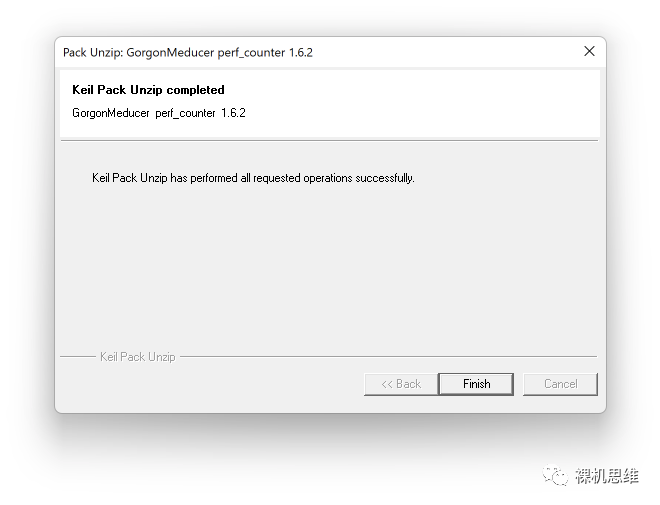
在確認(rèn)了開(kāi)原許可Apache 2.0的條款后,一路Next,直到單擊Finish,完成整個(gè)安裝過(guò)程:
一般來(lái)說(shuō),部署會(huì)非常順利,但如果出現(xiàn)了安裝錯(cuò)誤,比如下面這種:
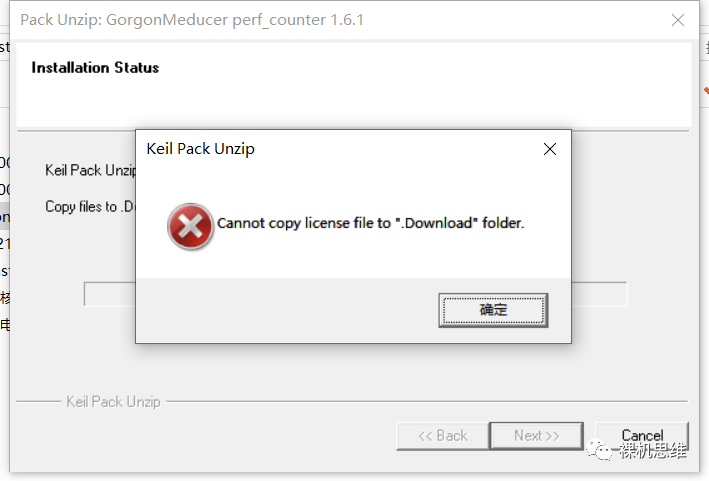
則很可能是您所使用的MDK版本太低導(dǎo)致的——是時(shí)候更新下MDK啦。
當(dāng)我們想在任何已有工程中部署perf_counter時(shí),只需要單擊MDK工具欄上如下圖所示的圖標(biāo):

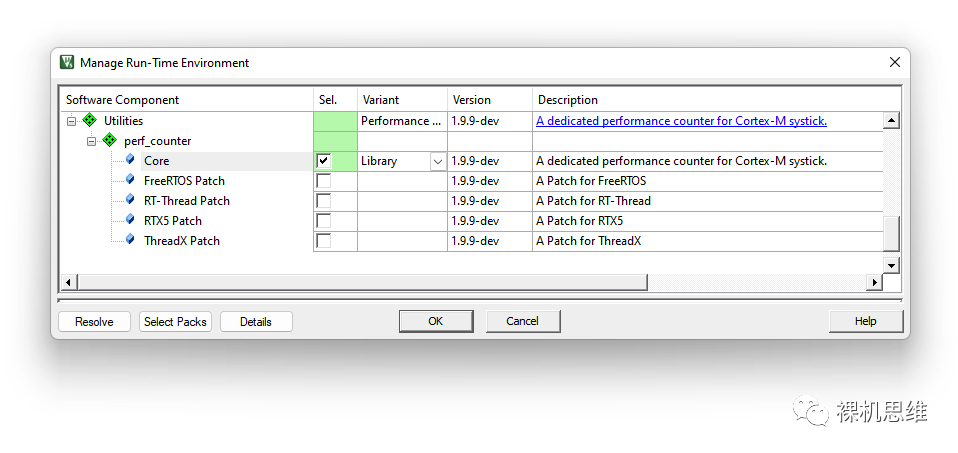
打開(kāi)RTE配置窗口:
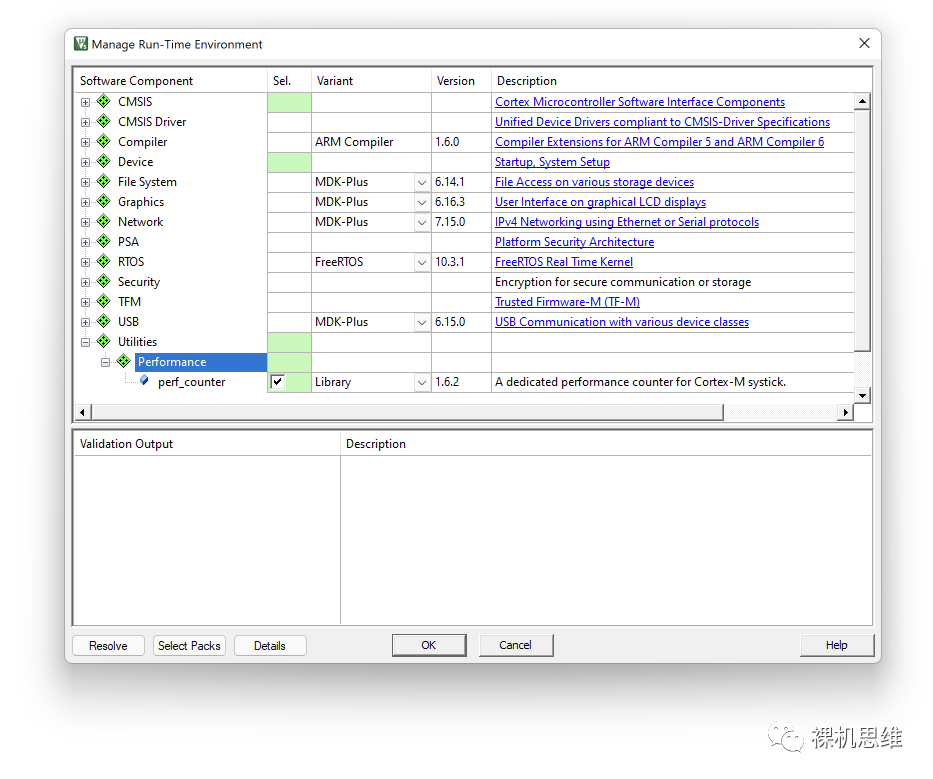
我們會(huì)注意到,在列表的末端出現(xiàn)了一個(gè)Utilities條目,依次展開(kāi)后勾選Performance下的perf_counter——默認(rèn)情況下系統(tǒng)會(huì)自動(dòng)選擇以庫(kù)的形式來(lái)實(shí)現(xiàn)模塊的部署——這也是我吐血推薦的方式,因?yàn)樗∪チ瞬槐匾木幾g麻煩。
單擊OK按鈕后,我們會(huì)發(fā)現(xiàn)Utilities已經(jīng)被加入到了工程管理器中,而perf_counter.lib也已經(jīng)成功的部署到了目標(biāo)工程中:
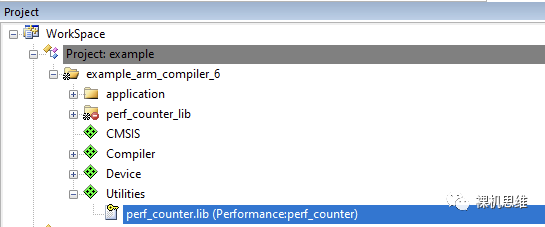
看過(guò)我往期文章《【教程】如何用GCC“零匯編”白嫖MDK》的小伙伴一定知道,MDK也可以使用GCC作為編譯器。perf_counter也將這種情況考慮在內(nèi)——當(dāng)用戶實(shí)際使用的是GCC時(shí),對(duì)應(yīng)的 libperf_counter_gcc.a(而不是arm compiler 5或arm compielr 6下的perf_counter.lib)會(huì)被加入到工程中。
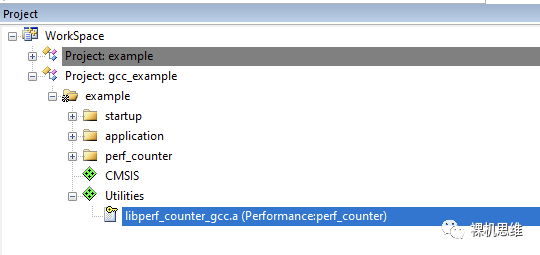
GCC環(huán)境下使用perf_counter略微有一些注意事項(xiàng),由于在文章《【教程】如何用GCC“零匯編”白嫖MDK》的末尾已經(jīng)有過(guò)非常詳盡的介紹,這里就不再贅述了。
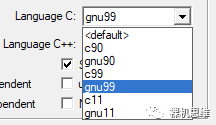
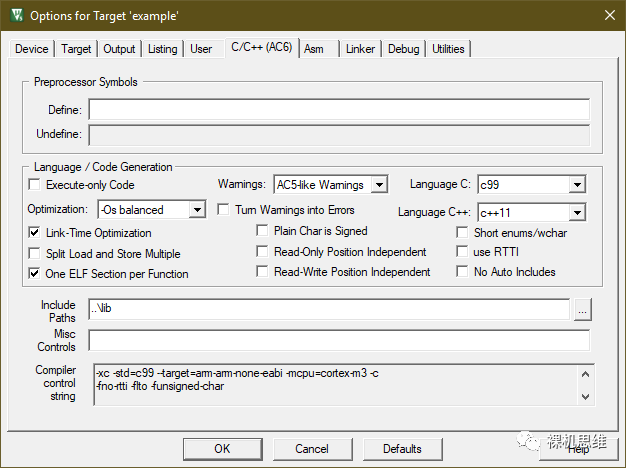
當(dāng)我們?cè)贛DK環(huán)境下使用Arm Compiler 6作為編譯器時(shí),需要打開(kāi)對(duì)GNU擴(kuò)展和C99(極其以上)語(yǔ)言標(biāo)準(zhǔn)的支持,具體方法如下圖所示:在Language C標(biāo)準(zhǔn)下拉列表中選擇帶有g(shù)nu前綴的選項(xiàng)——如果沒(méi)有什么特別的顧慮,推薦直接拉滿——使用gnu11即可。
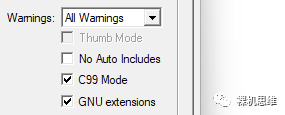
如果你使用的是較老的Arm Compiler 5,則應(yīng)該同時(shí)勾選C99 Mode和GNU extensions兩個(gè)選項(xiàng)。找不到上述兩個(gè)選項(xiàng)的小伙伴,應(yīng)該認(rèn)真考慮升級(jí)你們的MDK版本了。
【一鍵終結(jié)甜咸之爭(zhēng)?】
雖然在RTE中,perf_counter推薦并默認(rèn)使用library的方式來(lái)部署, ?  ? 但考慮到總有小伙伴對(duì)黑盒子有莫名的恐懼:
? 但考慮到總有小伙伴對(duì)黑盒子有莫名的恐懼:
“……往往要親眼看著黃酒從罎子裏舀出,看過(guò)壺子底裏有水沒(méi)有,又親看將壺子放在熱水裏,然後放心……” https://zh.m.wikisource.org/zh/%E5%AD%94%E4%B9%99%E5%B7%B1
因此,perf_counter貼心的提供了以Source源代碼來(lái)進(jìn)行部署的方式:

此時(shí),相關(guān)的perf_counter.c和systick_wrapper_ual.s會(huì)取代原本的庫(kù)文件加入到編譯中:
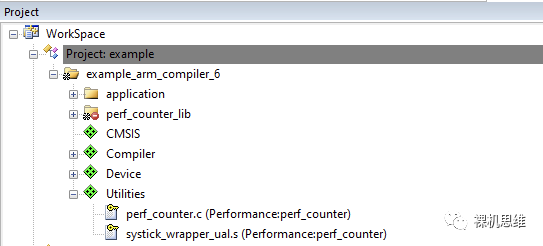
當(dāng)然,使用Source方式來(lái)編譯也是有代價(jià)的,即perf_counter的源代碼對(duì)CMSIS有依賴——當(dāng)你的工程中并未在RTE配置界面中勾選CMSIS-CORE,就會(huì)出現(xiàn)類(lèi)似下圖所示的黃色警告信息:“Additional software components required”。
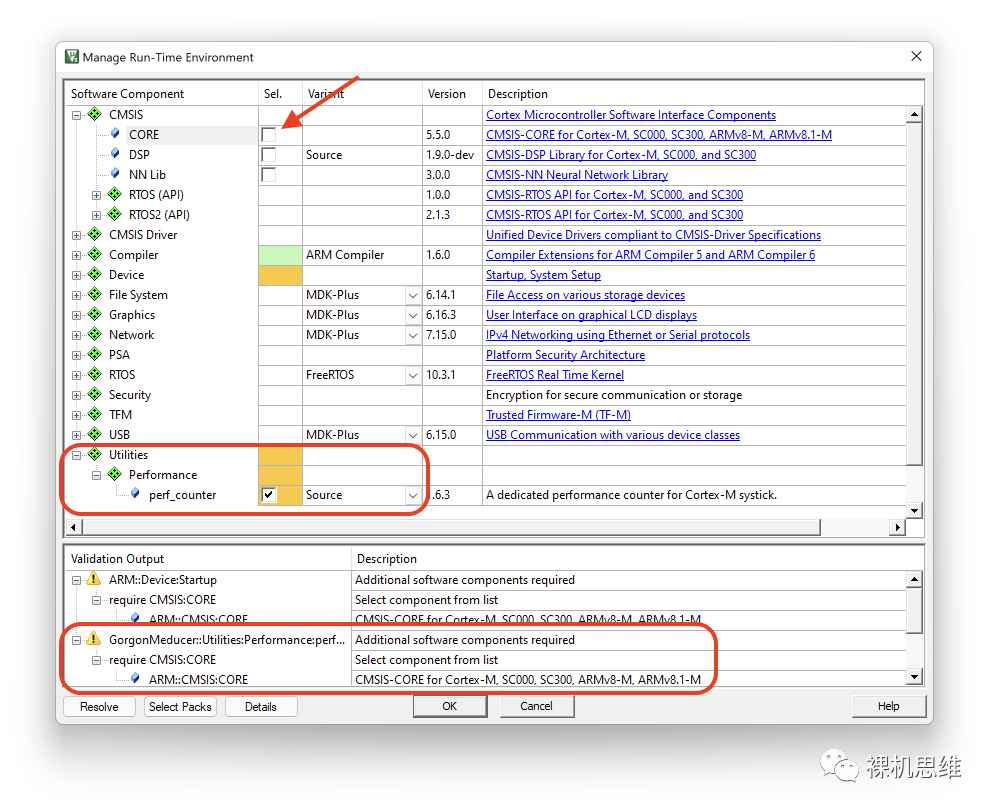
此時(shí),你可以簡(jiǎn)單的單擊Resolve按鈕來(lái)解決問(wèn)題——你會(huì)發(fā)現(xiàn),所謂的解決方案就是RTE自動(dòng)把Source模式依賴的CMSIS-CORE幫你勾選上了而已:
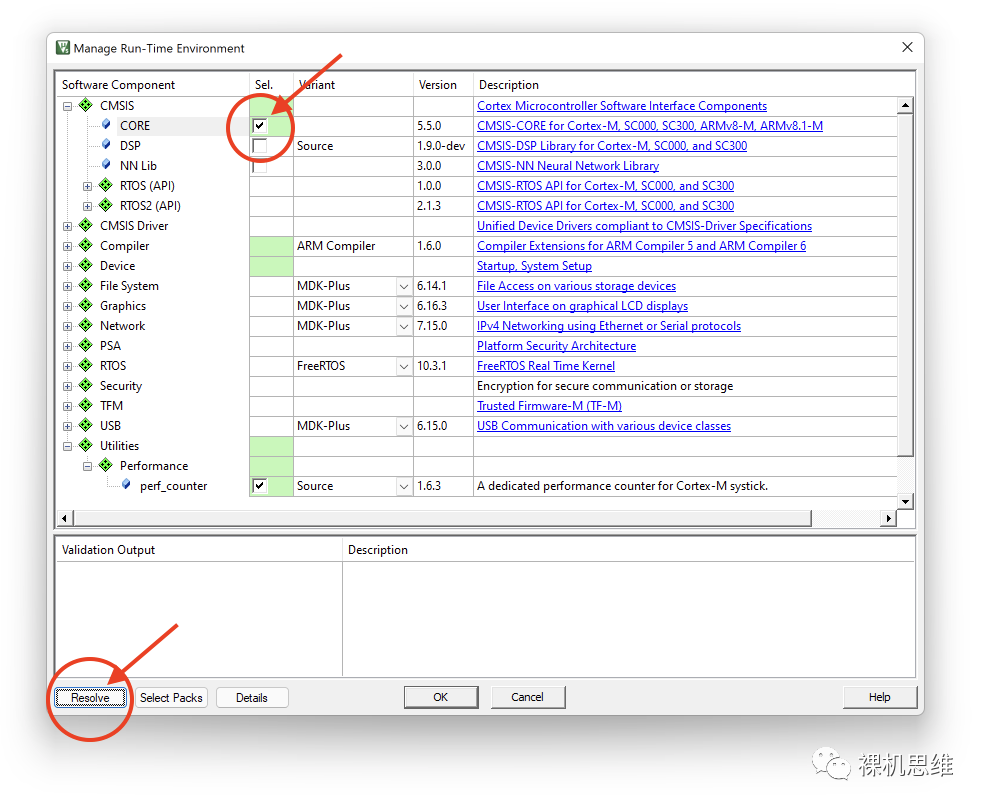
如果你對(duì)此并無(wú)異議,則問(wèn)題圓滿解決;如果你的系統(tǒng)中存在別的版本的CMSIS(比如很多正點(diǎn)原子、野火、以及CubeMX生成的工程都很可能會(huì)攜帶不經(jīng)由RTE配置界面來(lái)管理的CMSIS),則很有可能出現(xiàn)CMSIS版本沖突——而關(guān)于沖突的解決方案,則稍微復(fù)雜一些——你可以參考我的文章《CMSIS玩家的“陰間成就”指南》來(lái)實(shí)現(xiàn)某種取舍……又或者……
還是推薦你繼續(xù)使用Library模式吧,畢竟它對(duì)CMSIS沒(méi)有任何依賴。
【一鍵更新的……嵌入式軟件模塊?】
一旦你安裝了perf_counter任何一個(gè)版本的pack,都會(huì)在MDK的pack-installer中留下痕跡:
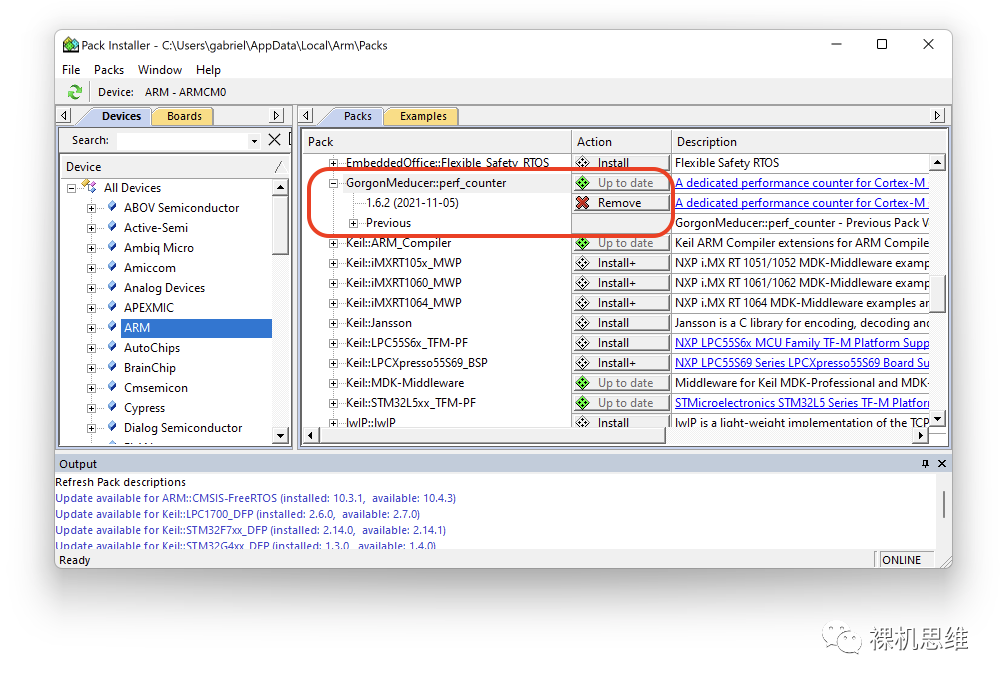
此時(shí),只要通過(guò)菜單 Pcak->Check For Update,我們就能實(shí)時(shí)的查詢?perf_counter是否存在最新版本:
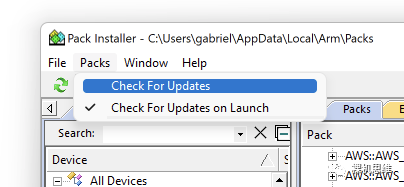
如果Pack-Installer真的從github上發(fā)現(xiàn)了更新,就會(huì)以黃色Update的圖標(biāo)來(lái)告知我們:
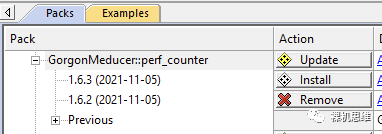
此時(shí),單擊Update按鈕,即可安裝最新版本:
那么,如何才能鼓勵(lì)博主多多更新、加入更多更好的功能呢?
當(dāng)然還是要靠有能力科學(xué)上網(wǎng)的小伙伴多多Star呀!
https://github.com/GorgonMeducer/perf_counter.git
【庫(kù)的初始化和注意事項(xiàng)】
關(guān)于頭文件
在任何需要使用perf_counter的C語(yǔ)言源文件中,我們需要首先加入對(duì)頭文件的引用:
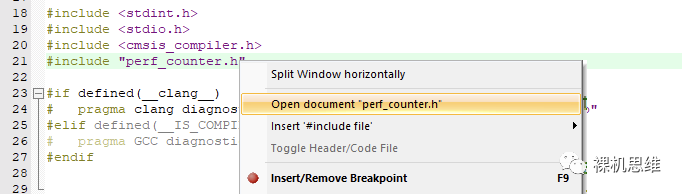
#include?"perf_counter.h"
需要注意的是,通過(guò)RTE方式部署的perf_counter并不會(huì)在工程管理器中引入?perf_counter.h?以供用戶查看。想要查看perf_counter.h查找可用API的小伙伴,可以“簡(jiǎn)單的”在上述代碼行上單擊右鍵,從彈出菜單中選擇“Open document 'perf_counter'”?來(lái)實(shí)現(xiàn)對(duì)頭文件的訪問(wèn)。
關(guān)于庫(kù)的初始化
一般來(lái)說(shuō),用戶會(huì)在某一個(gè)地方,比如?main()?函數(shù)內(nèi)完成對(duì)CPU工作頻率的配置,我們應(yīng)該在完成這一工作之后確保全局變量?SystemCoreClock?被正確的更新——保存當(dāng)前CPU的工作頻率,比如:
extern?uint32_t?SystemCoreClock;
void?main(void)
{
????SystemCoreClockUpdate();????//!?更新CPU工作頻率
????SystemCoreClock?=?72000000ul?//!?假設(shè)更新后的系統(tǒng)頻率是 72MHz
????...
}
一般來(lái)說(shuō),你的芯片工程如果本身都是基于較新的CMSIS框架而創(chuàng)建的,你的啟動(dòng)文件中已經(jīng)為你定義好了全局變量?SystemCoreClock——當(dāng)然,凡事都有例外,如果你在編譯的時(shí)候報(bào)告找不到變量?SystemCoreClock?或者說(shuō)“Undefined symbol __SystemCoreClock” 之類(lèi)的,你自己定義一下就好了,比如:
uint32_t?SystemCoreClock;
void?main(void)
{
????SystemCoreClockUpdate();????//!?更新CPU工作頻率
????SystemCoreClock?=?72000000ul?//!?假設(shè)更新后的系統(tǒng)頻率是 72MHz
????...
}
在這以后,我們需要對(duì)?perf_counter?庫(kù)進(jìn)行初始化。這里分兩種情況:
1、用戶自己的應(yīng)用里完全沒(méi)有使用SysTick。此時(shí),在編譯時(shí),我們多半會(huì)看到類(lèi)似如下的錯(cuò)誤提示:

Error: L6218E: Undefined symbol $Super$$SysTick_Handler (referred from systick_wrapper_ual.o).
對(duì)于這種情況,我們需要在任意的C文件中添加一個(gè)SysTick中斷處理程序:
#include "perf_counter.h" ... __attribute__((used))????//!然后我們?cè)?main()?函數(shù)里初始化?perf_counter?服務(wù):
#include?... void?main(void) { ????SystemCoreClock?=?72000000ul?//!?假設(shè)更新后的系統(tǒng)頻率是 72MHz ????init_cycle_counter(false); ????... } 需要特別注意的是:由于用戶并沒(méi)有自己初始化?SysTick,因此我們需要將這一情況告知?perf_counter?庫(kù)——由它來(lái)完成對(duì)?SysTick?的初始化——這里傳遞?false?給函數(shù)?init_cycle_counter()?就是這個(gè)功能。如果由perf_counter 庫(kù)自己來(lái)初始化SysTick,它會(huì)為了自己功能更可靠將 SysTick的溢出值(LOAD寄存器)設(shè)置為最大值(0x00FFFFFF)。
2、用戶自己的應(yīng)用里使用了SysTick,擁有自己的初始化過(guò)程。對(duì)于這種情況,我們需要確保一件事情:即,SysTick的CTRL寄存器的 BIT2(SysTick_CTRL_CLKSOURCE_Msk)是否被置位了——如果其值是1,說(shuō)明SysTick使用了跟CPU一樣的工作頻率,那么SysTick的測(cè)量結(jié)果就是CPU的周期數(shù);如果其值是0,說(shuō)明SysTick使用了來(lái)自于別處的時(shí)鐘源,這個(gè)時(shí)鐘源具體頻率是多少就只能看芯片手冊(cè)了(比如STM32就喜歡將系統(tǒng)頻率做 1/8 分頻后提供給SysTick作為時(shí)鐘源),此時(shí)SysTick測(cè)量出來(lái)的結(jié)果就不是CPU的周期數(shù)。
在確保了?CTRL?寄存器的?BIT2?被正確置位,并且SysTick中斷被使能(置位?BIT1,SysTick_CTRL_TICKINT_Msk?)后,我們可以簡(jiǎn)單的通過(guò)?init_cycle_counter()?函數(shù)告訴perf_counter模塊:SysTick?被用戶占用了——這里傳遞 true 就實(shí)現(xiàn)這一功能。
#include... void main(void) { SystemCoreClock = 72000000ul //! 假設(shè)更新后的系統(tǒng)頻率是 72MHz init_cycle_counter(true); ... } 關(guān)于Library的匹配問(wèn)題
perf_counter.lib?庫(kù)在編譯的時(shí)候,開(kāi)啟了?Short enums/wchar(分別對(duì)應(yīng)命令行的?-fshort-enums -fshort-wchar)。這么做其實(shí)沒(méi)什么特別的原因,但如果你的工程使用了不同的配置,例如:
下圖的工程配置中,沒(méi)有勾選 "Short enums/wchar"
你一定會(huì)看到這樣的編譯錯(cuò)誤:
.Outexample.axf: Error: L6242E: Cannot link object perf_counter.o as its attributes are incompatible with the image attributes.
... wchart-16 clashes with wchart-32. ... packed-enum clashes with enum_is_int.既然知道了原因,解決方法就很簡(jiǎn)單,要么在工程配置中勾選上這一選項(xiàng);要么使用源代碼編譯的模式。
【時(shí)間類(lèi)服務(wù)】
微秒級(jí)阻塞延時(shí)
perf_counter提供了一個(gè)us級(jí)阻塞延時(shí)函數(shù)?delay_us(),它的函數(shù)原型如下:
extern void delay_us(int32_t iUs);實(shí)際上,由于函數(shù)調(diào)用的開(kāi)銷(xiāo),delay_us在時(shí)間判斷上會(huì)存在一個(gè)“不積累”的誤差——根據(jù)優(yōu)化等級(jí)的不同,其具體CPU周期數(shù)存在差異,如果我們以Library方式進(jìn)行部署時(shí),這一誤差大約在+/-25個(gè)CPU周期左右——這一信息實(shí)際上告訴我們:
在使用Library的情況下,當(dāng)你的CPU頻率超過(guò)50MHz時(shí),delay_us()?可以提供最小<1us的延時(shí)誤差;
當(dāng)你的系統(tǒng)頻率不滿足上述條件時(shí),以系統(tǒng)頻率 12MHz為參考,則可以認(rèn)為delay_us誤差為不積累的 +/- 2us。
具體評(píng)估方法,請(qǐng)參考我往期的文章《【實(shí)時(shí)性迷思】CPU究竟跑的有多快?》,這里就不做贅述。
全局系統(tǒng)時(shí)間
perf_counter提供了API函數(shù)get_system_ticks(),用于方便用戶獲取自?SysTick啟動(dòng)以來(lái)系統(tǒng)已經(jīng)經(jīng)歷過(guò)的總周期數(shù),其函數(shù)原型如下:
__attribute__((nothrow)) extern int64_t get_system_ticks(void);可以看到,其返回值是一個(gè) 64位的有符號(hào)整數(shù),即便拋開(kāi)符號(hào)位,也基本可以確信:無(wú)論芯片頻率如何,在人類(lèi)滅絕之前,不會(huì)發(fā)生溢出問(wèn)題。
此外,從版本v1.9.9開(kāi)始,我們還可以從 perf_counter 中找到另外兩個(gè)有用的函數(shù):get_system_us() 和 get_system_ms()。 比如,這里的?get_system_ms()?可以告訴我們從SysTick啟動(dòng)以來(lái)(一般大約可以等效為從系統(tǒng)復(fù)位開(kāi)始)已經(jīng)過(guò)去了多少毫秒。是不是特別方便?
非阻塞式多重延時(shí)
在狀態(tài)機(jī)中,非阻塞式的延時(shí)往往是必不可少的功能,包括但不限于:
機(jī)構(gòu)控制的延時(shí);
電路的時(shí)序控制;
通信協(xié)議的超時(shí)處理;
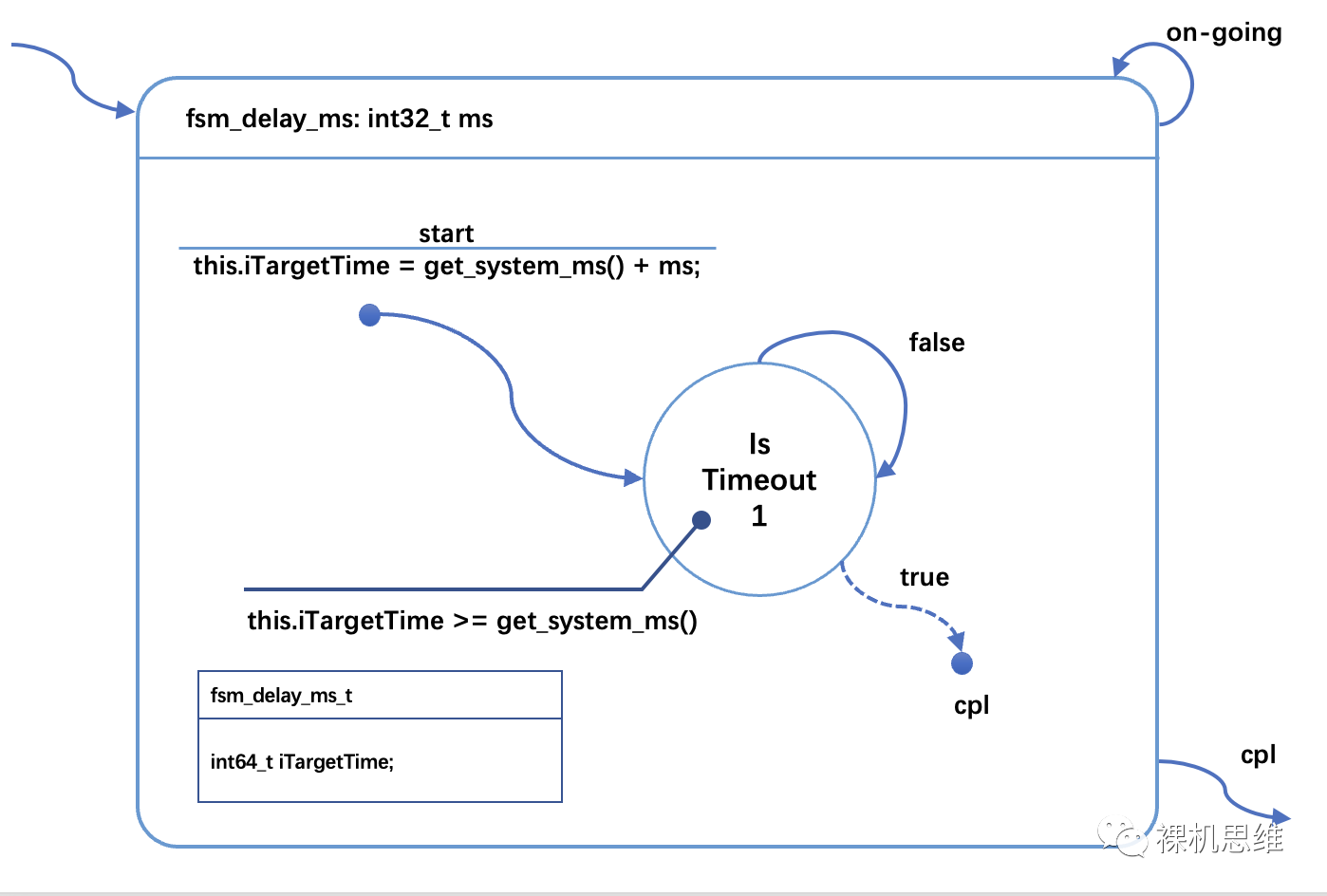
下圖就是一個(gè)支持多實(shí)例的非阻塞延時(shí)的狀態(tài)機(jī),即便你沒(méi)有看過(guò)我的狀態(tài)機(jī)系列文章,對(duì)應(yīng)的邏輯應(yīng)該也算是淺顯易懂。
這里的核心思想是:
在延時(shí)的開(kāi)始時(shí)刻,通過(guò)??get_system_ms()?來(lái)獲取當(dāng)前的系統(tǒng)時(shí)間戳;
計(jì)算目標(biāo)時(shí)刻的系統(tǒng)時(shí)間戳并保存在狀態(tài)機(jī)類(lèi)中(保存在 iTargetTime里);
在隨后的狀態(tài)中以非阻塞的方式輪詢?get_system_ms()?以檢查約定的時(shí)間是否已經(jīng)到來(lái)。
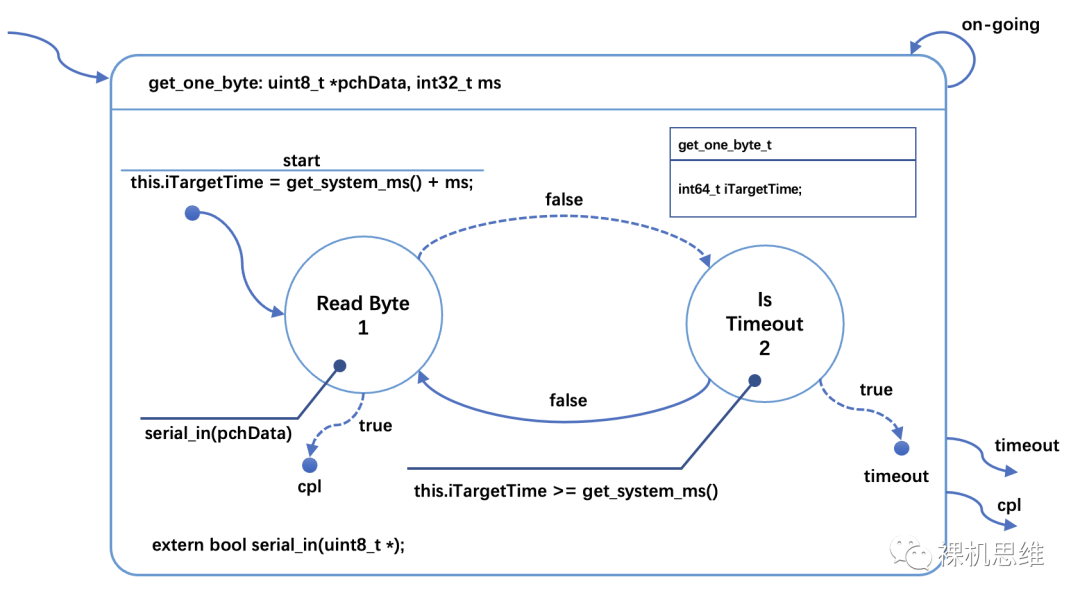
下面的狀態(tài)圖展示了如何在執(zhí)行某些動(dòng)作(或者子狀態(tài)機(jī))的同時(shí),進(jìn)行超時(shí)判斷:
這里值得注意的細(xì)節(jié)是:
在延時(shí)的開(kāi)始時(shí)刻,通過(guò)?get_system_ms()?來(lái)獲取當(dāng)前的系統(tǒng)時(shí)間戳;
計(jì)算目標(biāo)時(shí)刻的系統(tǒng)時(shí)間戳并保存在狀態(tài)機(jī)類(lèi)中(保存在 iTargetTime里);
在讀取字符失敗時(shí),通過(guò)對(duì)比當(dāng)前的系統(tǒng)時(shí)間戳來(lái)判斷是否超時(shí)。
具體狀態(tài)圖的解讀和翻譯方式,還不熟悉的小伙伴可以單擊這里來(lái)閱讀狀態(tài)機(jī)系列文章,這里就不再贅述。
隨機(jī)數(shù)發(fā)生
幾乎所有的C語(yǔ)言教程都在介紹過(guò)隨機(jī)數(shù)的發(fā)生,比如:
#include?由于rand()實(shí)際上是一個(gè)偽隨機(jī)數(shù)發(fā)生器,因此為了達(dá)到理想的效果,無(wú)一例外的,所有教材都推薦使用時(shí)間作為隨機(jī)數(shù)的種子。借助 get_system_ticks() 的幫助,我們的偽隨機(jī)發(fā)生函數(shù)幾乎可以肯定的是距離真正的隨機(jī)數(shù)發(fā)生器更近了一步:#include? int?main?(void)? { int i, n; time_t t; n = 5; /* Intializes random number generator */ srand((unsigned) time(&t)); /* Print 5 random numbers from 0 to 49 */ for( i = 0 ; i < n ; i++ ) { printf("%d ", rand() % 50); } ???return(0); } #include?"perf_counter.h" #include?srand((unsigned)get_system_ticks()); 【嵌入式C語(yǔ)言擴(kuò)展】
perf_counter除了提供一些與系統(tǒng)性能測(cè)量和時(shí)間有關(guān)的服務(wù)歪,還額外對(duì)嵌入C語(yǔ)言做了一定的擴(kuò)展,有興趣的小伙伴不妨試一試。
全局中斷屏蔽 __IRQ_SAFE
perf_counter?提供了一個(gè)關(guān)鍵字?__IRQ_SAFE,它可以在執(zhí)行緊隨其后一條語(yǔ)句、或是緊隨其后的花括號(hào)內(nèi)的代碼片斷時(shí),暫時(shí)性的關(guān)閉全局中斷響應(yīng),并在完成對(duì)應(yīng)操作后恢復(fù)原樣。??
//!?執(zhí)行?緊隨其后的printf語(yǔ)句時(shí),暫時(shí)性的屏蔽全局中斷 __IRQ_SAFE?printf("hellow world!"); //!?執(zhí)行花括號(hào)內(nèi)的代碼時(shí),暫時(shí)性的屏蔽全局中斷 __IRQ_SAFE { ... } //! 想提前結(jié)束時(shí),可以用continue; __IRQ_SAFE?{ ????... ????if?(某些條件) { ????????//!?我們需要提前結(jié)束 ????????continue; ????} ????//!?條件性跳過(guò)的操作 ????... }__IRQ_SAFE在使用時(shí),有以下注意事項(xiàng):
它只能用于函數(shù)內(nèi)部,不可以用來(lái)修飾函數(shù)或者變量;
它支持嵌套
編譯器類(lèi)型檢測(cè)
有些小伙伴在進(jìn)行軟件開(kāi)發(fā)時(shí),可能會(huì)因?yàn)檫@樣或者那樣的原因,需要能夠穩(wěn)定可靠的檢測(cè)出當(dāng)前所使用的編譯器,比如?Arm Compiler 5、Arm Compiler 6、GCC等等。
perf_counter?提供了一系列統(tǒng)一格式的宏,有效的解決了上述問(wèn)題。它們是:
__IS_COMPILER_ARM_COMPILER_5__ __IS_COMPILER_ARM_COMPILER_6__ __IS_COMPILER_GCC__ __IS_COMPILER_LLVM__ __IS_COMPILER_IAR__這些宏僅會(huì)在檢測(cè)到對(duì)應(yīng)編譯器時(shí)被定義。一個(gè)典型的用法如下:
#if defined(__IS_COMPILER_IAR__) __attribute__((constructor)) #else __attribute__((constructor(255))) #endif void __perf_counter_init(void) { init_cycle_counter(true); }這里,__attribute__((constructor))?的作用在于告訴編譯器“請(qǐng)?jiān)趫?zhí)行main函數(shù)前執(zhí)行被它修飾的函數(shù)”。這是一個(gè)GCC擴(kuò)展,為大部分編譯器廣泛接受和支持,但由于IAR的在語(yǔ)法上并不支持存在多個(gè)函數(shù)時(shí)排隊(duì)用的序號(hào),因此需要與其它編譯器區(qū)別處理。
預(yù)編譯膠水宏
很多場(chǎng)景下,我們需要在預(yù)編譯時(shí)刻對(duì)多個(gè)“文本片斷”進(jìn)行“粘合”,以生成新的名稱,比如宏、枚舉、變量名、函數(shù)名等等。 ? 一般來(lái)說(shuō),我們都見(jiàn)過(guò)類(lèi)似如下的做法:
#define?TPASTE(a,b)????a##b但這里其實(shí)存在一些問(wèn)題,這類(lèi)問(wèn)題在我的文章《【為宏正名】本應(yīng)寫(xiě)入教科書(shū)的“世界設(shè)定”》中有詳細(xì)講解,這里就不再贅述。單純從功能上來(lái)講,TPASTE只能完成2個(gè)名稱的“粘合”,如果是多個(gè)呢?如果要粘合的名稱數(shù)量不去定呢?perf_counter就提供了這樣一個(gè)解決方案?CONNECT(),并具有以下優(yōu)勢(shì):
黏合的數(shù)量可以是變化的
最大支持黏合9個(gè)片斷
比如,我們想生成一個(gè)安全的臨時(shí)名稱,則可以試著將代碼所在行號(hào)__LINE__、下劃線以及用戶指定的后綴黏合在一起:
#define?SAFE_NAME(__NAME)???? ????CONNECT(__,__LINE__,_,__NAME)比如,下面的代碼:
#define?measure_time(...)??????????????????????????????????? ????({ ????????int64_t?SAFE_NAME(StartTime)?=?get_system_ticks(); ????????__VA_ARGS__; ????????get_system_ticks()?-?SAFE_NAME(StartTime);???????? ???? }) ???? int32_t?iCycleUsed = measure_time( ????printf("Hello world! "); ????);假設(shè)measure_time所在的行號(hào)為123,則實(shí)際對(duì)應(yīng)的代碼為:
int32_t iCycleUsed = ????({?????????????????????????????????????????????????????? ????????int64_t?__123_StartTime?=?get_system_ticks(); ????????__VA_ARGS__;???????????????????????????????????????? ????????get_system_ticks()?-?__123_StartTime;???????? });該代碼的作用是測(cè)量?measure_time()的圓括號(hào)內(nèi)的代碼塊所用時(shí)間,并作為表達(dá)式的值返回。這里用到了GCC的一個(gè)被稱為“Statements and Declarations in Expressions”的語(yǔ)法擴(kuò)展,感興趣的小伙伴可以參考下面的鏈接:
https://gcc.gnu.org/onlinedocs/gcc/Statement-Exprs.html#Statement-Exprs
數(shù)組元素枚舉器
C語(yǔ)言中,我們時(shí)常要使用for語(yǔ)句來(lái)實(shí)現(xiàn)對(duì)數(shù)據(jù)元素的訪問(wèn),比如,下面的代碼:
static volatile int16_t s_iADCBuffer[ADC_BUFFER_SIZE]; int16_t?get_average_voltage(void) { ????int32_t?nTotal?= 0; ????for?(int32_t?n?=?0;?n?在這個(gè)簡(jiǎn)單的例子中,for循環(huán)的作用就是枚舉數(shù)組?s_iADCBuffer?中的每一個(gè)元素。很多高級(jí)語(yǔ)言(甚至是Linux內(nèi)核代碼),都引入了專(zhuān)門(mén)的?foreach?關(guān)鍵字來(lái)實(shí)現(xiàn)這樣的數(shù)據(jù)枚舉功能,perf_counter也不能免俗,其語(yǔ)法為:
foreach?(<數(shù)組元素的類(lèi)型>,<數(shù)組名稱>) { ????... }借助?foreach?的幫助,上述代碼可以被簡(jiǎn)化為:
static volatile int16_t s_iADCBuffer[ADC_BUFFER_SIZE]; int16_t get_average_voltage(void) { int32_t nTotal = 0; foreach (volatile int16_t, s_iADCBuffer) { ????????nTotal?+=?*_; } return nTotal / ADC_BUFFER_SIZE; }注意,這里"_"是一個(gè)指向枚舉過(guò)程中當(dāng)前元素的指針,簡(jiǎn)單說(shuō),它等效于前面代碼中的 "(s_iADCBuffer+n)",由于是指針,因此在使用是需要用 “*_”來(lái)獲取元素的內(nèi)容。使用"_"來(lái)指代循環(huán)體內(nèi)的當(dāng)前元素,借鑒于腳本語(yǔ)言perl。如果你非常討厭這種用法,覺(jué)得不知所云,那么也可以使用下面的方法:static volatile int16_t s_iADCBuffer[ADC_BUFFER_SIZE]; int16_t get_average_voltage(void) { int32_t nTotal = 0; ????foreach?(volatile?int16_t,?s_iADCBuffer,?piItem)?{ ????????nTotal?+=?*piItem; } return nTotal / ADC_BUFFER_SIZE; }注意到:foreach在原有2個(gè)參數(shù)的基礎(chǔ)上引入了第三個(gè)參數(shù)?piItem,這里的用法實(shí)際為:foreach?(<數(shù)組元素的類(lèi)型>,<數(shù)組名稱>,<枚舉元素名稱>) { ????... }換句話說(shuō),用戶可以通過(guò)第三個(gè)參數(shù)指定枚舉元素的變量名稱了,是不是一下就清晰了很多?
【如何測(cè)量代碼片斷占用了多少CPU資源】
支持嵌套的 __cycleof__()
很多時(shí)候,我們會(huì)關(guān)心某一段代碼或者函數(shù)究竟用了多少CPU周期,比如,我們寫(xiě)了一個(gè)算法,你很擔(dān)心“這個(gè)算法究竟使用了多少CPU資源”,為了解決這個(gè)問(wèn)題,我們需要用到如下的公式: ? CPU資源占用(百分比) =? ????(函數(shù)運(yùn)行所需的時(shí)間)?(算法運(yùn)行間隔的最小值) ???? 100% ? 對(duì)于【函數(shù)運(yùn)行所需的時(shí)間】和【算法運(yùn)行間隔的最小值】來(lái)說(shuō),雖然它們都是時(shí)間單位,但考慮到CPU的頻率是給定的(不變的),因此,這里的時(shí)間單位在乘以CPU的工作頻率后都可以被換算為CPU的周期數(shù)。舉例來(lái)說(shuō),假如【算法運(yùn)行間隔的最小值】是 20ms、CPU的頻率是72MHz,那么對(duì)應(yīng)的周期數(shù)就是 72000000?* (20ms / 1000ms) = 1440000 個(gè)周期。看來(lái)上述公式中唯一需要我們實(shí)際測(cè)量的就是【函數(shù)運(yùn)行所需的周期數(shù)】了。 ?
perf_counter?提供了一個(gè)非常簡(jiǎn)單的運(yùn)算符:__cycleof__()。假設(shè)我們要測(cè)量的代碼片斷如下:
my_algorithm_step_a(); my_algorithm_step_b(); ... my_algorithm_step_c(); ...則我們可以輕松的通過(guò)__cycleof__()運(yùn)算來(lái)測(cè)量結(jié)果:... __cycleof__("my?algorithm")?{ my_algorithm_step_a(); my_algorithm_step_b(); ... my_algorithm_step_c(); } ...如果你的系統(tǒng)支持?printf(),則可以看到類(lèi)似如下的輸出結(jié)果:??
帶入上述公式: 525139 /?14400000 * 100% ≈?36.5% ? 就計(jì)算出這個(gè)算法占用了大約?36.5%?的CPU資源,值得說(shuō)明的是,從原理上看,這一方式對(duì)裸機(jī)和RTOS同樣有效哦。 ?
有的小伙伴很快會(huì)說(shuō),我的系統(tǒng)并不允許我調(diào)用printf,那我還可以使用?__cycleof__()?么?當(dāng)然了!就繼續(xù)以上述代碼為例子:
int32_t?nCycleUsed?=?0; ... __cycleof__("my algorithm", { nCycleUsed = _; }) { my_algorithm_step_a(); my_algorithm_step_b(); ... my_algorithm_step_c(); } ...這里的代碼所實(shí)現(xiàn)的功能是:測(cè)量了用戶函數(shù)?my_algorithm_step_xxx()?所使用的周期數(shù):
測(cè)量的結(jié)果被轉(zhuǎn)存到了一個(gè)叫做?nCycleUsed?的變量中;
__cycleof__()?將不會(huì)調(diào)用?printf()?進(jìn)行任何內(nèi)容輸出。
我相信很多小伙伴會(huì)揉了揉眼睛、仔細(xì)看了又看,然后回過(guò)頭來(lái)滿頭問(wèn)號(hào): ? ? ? 這是C語(yǔ)言? 這是什么語(yǔ)法? ? 不要懷疑,這就是C語(yǔ)言,只不過(guò)使用了一點(diǎn)GCC的語(yǔ)法擴(kuò)展(感興趣的小伙伴可以復(fù)制這里的連接?https://gcc.gnu.org/onlinedocs/gcc/Statement-Exprs.html#Statement-Exprs),考慮到本文只介紹?perf_counter?如何使用,而對(duì)其如何實(shí)現(xiàn)的并不關(guān)心,我們不妨略過(guò)GCC擴(kuò)展語(yǔ)法的部分,專(zhuān)門(mén)來(lái)看看上述代碼的使用細(xì)節(jié): ?
首先,為了方便大家觀察,我們先忽略圓括號(hào)內(nèi)的部分:
__cycleof__(...)?{ my_algorithm_step_a(); my_algorithm_step_b(); ... my_algorithm_step_c(); } ...可以發(fā)現(xiàn),這里跟此前并沒(méi)有什么不同:花括號(hào)包圍的部分就是我們要測(cè)量的代碼片斷; ?接下來(lái),我們專(zhuān)門(mén)來(lái)看__cycleof__()?圓括號(hào)中的部分:
int32_t?nCycleUsed?=?0; __cycleof__("my algorithm", { nCycleUsed = _; ????}) { ... } ...容易發(fā)現(xiàn),如果以“,” 為分隔符,那么實(shí)際傳遞給?__cycleof__()?的是兩個(gè)部分: ? 1、標(biāo)注測(cè)量名稱的字符串"my algorithm"2、一段用花括號(hào)括起來(lái)的代碼片斷:{nCycleUsed = _;}其中,nCycleUsed?是一個(gè)事先已經(jīng)初始化好的變量。 ? 這里,對(duì)于表示測(cè)量名稱的字符串"my algorithm",在這一用法下在最終的編譯結(jié)果里并不會(huì)占用任何RAM或者是ROM,但作為語(yǔ)法結(jié)構(gòu)是必須的。 ? 對(duì)于花括號(hào)所囊括的代碼片段來(lái)說(shuō),實(shí)際上在這個(gè)花括號(hào)里,你幾乎可以為所欲為:你可以寫(xiě)任意數(shù)量的代碼
你可以調(diào)用函數(shù)
你可以定義變量(當(dāng)然這里定義變量肯定就是局部變量了)
但我們一般要做的事情其實(shí)是通過(guò)__cycleof__()?所定義的一個(gè)局部變量"_"來(lái)獲取測(cè)量結(jié)果——這也是下面代碼的本意:
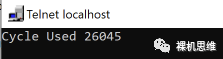
nCycleUsed = _;需要說(shuō)明的是,這個(gè)局部變量"_"生命周期僅限于這個(gè)花括號(hào)中,因此不會(huì)影響 __cycleof__() 整個(gè)結(jié)構(gòu)之外的部分——或者說(shuō),下述代碼是沒(méi)有意義的: ?int32_t nCycleUsed = 0; ... __cycleof__("my algorithm", { nCycleUsed = _; }) { my_algorithm_step_a(); my_algorithm_step_b(); ... my_algorithm_step_c(); } printf("Cycle Used %d", _);編譯器會(huì)毫不客氣的告訴你 "_" 是一個(gè)未定義的變量,反之如果你這么做:int32_t nCycleUsed = 0; ... __cycleof__("my algorithm", { nCycleUsed = _; printf("Cycle Used %d", _); }) { my_algorithm_step_a(); my_algorithm_step_b(); ... my_algorithm_step_c(); }則會(huì)看到你心怡的輸出結(jié)果:
系統(tǒng)時(shí)間戳 get_system_ticks()?
如果你對(duì)上述例子的等效形式(展開(kāi)形式)感到非常好奇,其實(shí)大可不必,上述代碼在“邏輯上等效”于如下的形式: ?
int32_t nCycleUsed = 0;
do { ????int64_t?_?=?get_system_ticks(); { my_algorithm_step_a(); my_algorithm_step_b(); ... my_algorithm_step_c(); } _ = get_system_ticks() - _; ????//!?我們添加的代碼 nCycleUsed = _; printf("Cycle Used %d", _); }?while(0);是不是突然就沒(méi)有那么神秘了?通過(guò)“邏輯等效”的形式展開(kāi),我們很容易發(fā)現(xiàn)一些有趣的內(nèi)容: ?起核心作用的是一個(gè)叫做?get_system_ticks()?的函數(shù)。實(shí)際上它返回的是從復(fù)位后 SysTick被使能至今所經(jīng)歷的 CPU 周期數(shù)——由于它是int64_t 的類(lèi)型,因此不用擔(dān)心超過(guò) SysTick 24位計(jì)數(shù)器的量程,也不用擔(dān)心人類(lèi)歷史范圍內(nèi)會(huì)發(fā)生溢出的可能。?知道這一點(diǎn)后,聰明的小伙伴就可以自己整活兒了。
由于 "_"?是一個(gè)局部變量,因此可以判斷?__cycleof__() 是支持嵌套的。
需要特別說(shuō)明的是,get_system_tick()?函數(shù)自己也是有CPU時(shí)鐘開(kāi)銷(xiāo)的,所以如果要獲得較為精確的結(jié)果,推薦通過(guò)下面的方法來(lái)獲取校準(zhǔn)值:
static?int64_t?s_lPerfCalib; void?calib_perf_counter(void)?{ int64_t lTemp = get_system_tick(); s_lPerfCalib = get_system_tick() - lTemp; } int64_t?get_perf_counter_calib(void) { ????return s_lPerfCalib; }具體如何使用,這里就不再贅述了。連續(xù)計(jì)時(shí)模式
為了方便某些特殊場(chǎng)合的測(cè)試需求,perf_counter還通過(guò)start_cycle_counter()?和?stop_cycle_counter()?的組合提供了類(lèi)似體育老師所使用秒表的連續(xù)計(jì)時(shí)功能,即:起跑后可以分別記錄每一個(gè)學(xué)生所用的時(shí)間。具體表現(xiàn)為
int32_t nCycles = 0; start_cycle_counter();???? //!值得強(qiáng)調(diào)的是雖然?start_cycle_counter()?和?stop_cycle_counter()?有?start?和?stop?的字樣,但這只有邏輯上的意義而并不會(huì)真正的干擾?SysTick?的功能(也就是不會(huì)開(kāi)啟或者關(guān)閉?SysTick)。這也是這個(gè)庫(kù)敢于聲稱自己不會(huì)影響用戶已有的?SysTick?功能的原因。
【對(duì)RTOS的支持】
雖然 perf_counter 本身可以直接在大部分RTOS環(huán)境下直接使用,但在額外插件的加持下,perf_counter 還可以提供額外的功能,比如:
刨去任務(wù)調(diào)度的干擾,測(cè)量線程內(nèi)指定代碼所用的時(shí)間周期數(shù)。(詳情請(qǐng)參考文章《實(shí)時(shí)性迷思(5)——實(shí)戰(zhàn)RTOS多任務(wù)性能分析》)
對(duì)跨越多個(gè)線程的算法進(jìn)行精確的性能測(cè)量(詳情請(qǐng)參考文章《實(shí)時(shí)性迷(6)——如何進(jìn)行跨任務(wù)性能分析》)
要獲得上述功能,在MDK環(huán)境下只需要勾選對(duì)應(yīng)補(bǔ)丁即可(一些具體注意事項(xiàng)請(qǐng)參考文章《實(shí)時(shí)性迷思(5)——實(shí)戰(zhàn)RTOS多任務(wù)性能分析》),非常方便。
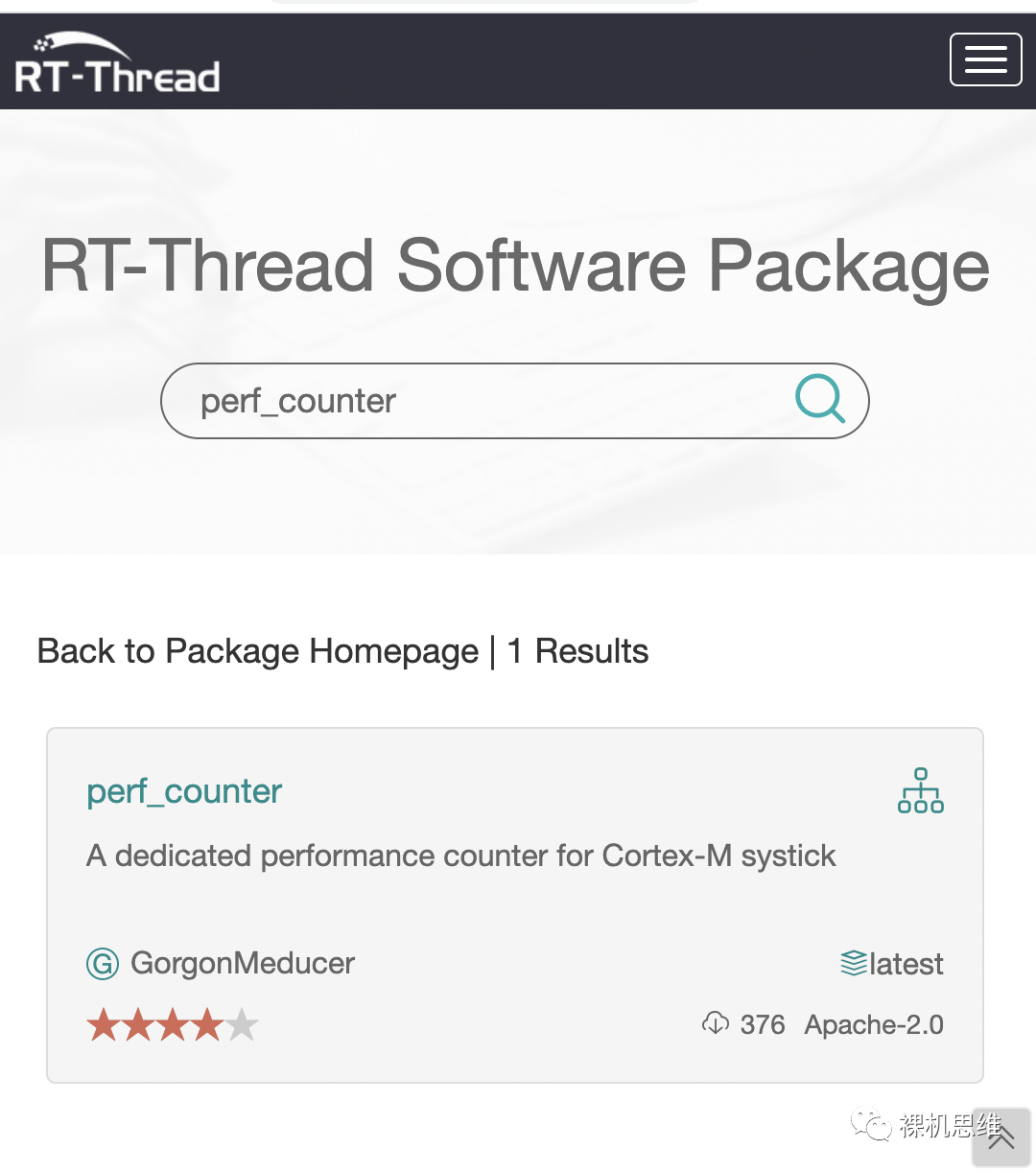
如果你是RT-Thread的用戶,還可以通過(guò)官方的包管理器直接獲取最新的版本:
【說(shuō)在后面的話】
perf_counter 最初誕生于我的日常工作——當(dāng)我發(fā)現(xiàn)我需要重復(fù)的在不同工程間復(fù)制性能測(cè)試相關(guān)的代碼時(shí),制作一個(gè)模塊來(lái)節(jié)省我的時(shí)間就成了偷懶的最好理由。 中文互聯(lián)網(wǎng)上,在嵌入式項(xiàng)目中對(duì)系統(tǒng)性能進(jìn)行測(cè)量其實(shí)并不是什么熱門(mén)話題,在日常應(yīng)用開(kāi)發(fā)中,相比定量分析,大家可能更喜歡一拍腦袋的純憑感覺(jué)來(lái)評(píng)價(jià)系統(tǒng)的性能。我在文章《【實(shí)時(shí)性迷思】CPU究竟跑的有多快?》已經(jīng)對(duì)此做了吐槽。相比之下,如何實(shí)現(xiàn) us 級(jí)別的延時(shí)則更為流行一些。看到不少人用DWT之類(lèi)限定于某幾個(gè)處理器的不推薦用戶使用的調(diào)試類(lèi)外設(shè)作為延時(shí),看到手中明明有更好的、且通用的方案,我實(shí)在不敢獨(dú)享——這也成了perf_counter成為github上一個(gè)開(kāi)源項(xiàng)目的契機(jī)。 ? 相比最初那簡(jiǎn)陋的代碼,到現(xiàn)在最新的 v1.9.9版,我很難抑制內(nèi)心的那種自我感動(dòng)。感謝大家的支持——是你們的Star支撐著我一路對(duì)項(xiàng)目的持續(xù)更新。謝謝! ? ? ?
編輯:黃飛
?









 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論