 電子發(fā)燒友App
電子發(fā)燒友App


蝶形運(yùn)算,2點(diǎn)DFT運(yùn)算稱為蝶形運(yùn)算,而整個(gè)FFT就是由若干級(jí)迭代的蝶形運(yùn)算組成,而且這種算法采用塬位運(yùn)算,故只需N個(gè)存儲(chǔ)單元2. ∑∑(2)式(2)是FFT基4頻域抽取算法的基本運(yùn)算單元,一般稱為蝶形運(yùn)算。
1. 2點(diǎn)DFT運(yùn)算稱為蝶形運(yùn)算,而整個(gè)FFT就是由若干級(jí)迭代的蝶形運(yùn)算組成,而且這種算法采用塬位運(yùn)算,故只需N個(gè)存儲(chǔ)單元2. ∑∑(2)式(2)是FFT基4頻域抽取算法的基本運(yùn)算單元,一般稱為蝶形運(yùn)算。下一步再將X(4m+i),i=0,1,2,3分解成4個(gè)N42序列,迭代r次后完成計(jì)算,整個(gè)算法的復(fù)雜度減少為O(Nlog4N)
第一列蝶形運(yùn)算只有一種類型:系數(shù),參加運(yùn)算的兩個(gè)數(shù)據(jù)點(diǎn)間距為1。第二列有兩種類型的蝶形運(yùn)算:系數(shù)分別為 ,參加蝶形運(yùn)算的兩個(gè)數(shù)據(jù)點(diǎn)的間距等于2。第叁列有4種類型的蝶形運(yùn)算:系數(shù)分別是 ,參加蝶形運(yùn)算的兩個(gè)數(shù)據(jù)點(diǎn)的間距等于4。可見,每一列的蝶形類型比前一列增加一倍,參加蝶形運(yùn)算的兩個(gè)數(shù)據(jù)點(diǎn)的間距也增大一倍,最后一列系數(shù)用得最多,為4個(gè),即 ,而前一列只用到它偶序號(hào)的那一半,即,
第一列只有一個(gè)系數(shù),即。上訴結(jié)論可以推廣到N=的一般情況,規(guī)律是第一列只有一種類型的蝶形運(yùn)算,系數(shù)是 ,以后每列的蝶形類型,比前一列增加一倍,到第是N/2個(gè)蝶形類型,系數(shù)是,共N/2個(gè)。由后向前每推進(jìn)一列,則用上述系數(shù)中偶數(shù)序號(hào)的那一半,例如第列的系數(shù)則為參加蝶形運(yùn)算的兩個(gè)數(shù)據(jù)點(diǎn)的間距,則是最末一級(jí)最大,其值為N/2,向前每推進(jìn)一列,間距減少一半。
FFT(快速傅里葉變換)作為數(shù)字信號(hào)處理領(lǐng)域的核心算法之一。蝶形運(yùn)算單元是FFT設(shè)計(jì)的核心單元。本文研究基24FFT蝶形運(yùn)算單元芯片設(shè)計(jì)。基于TSMC(***集成電路制造公司)0.18LmCMOS標(biāo)準(zhǔn)單元庫的半定制ASIC(專用集成電路)設(shè)計(jì),采用自頂向下、以關(guān)鍵模塊為設(shè)計(jì)對(duì)象的設(shè)計(jì)方法,使用VerilogHDL描述系統(tǒng),在Modelsim、DesignCompiler和ASTRO等EDA(電子設(shè)計(jì)自動(dòng)化)工具中完成
基4FFT蝶形運(yùn)算單元的設(shè)計(jì)
蝶形運(yùn)算單元是FFT處理器的核心單元,蝶形運(yùn)算單元結(jié)構(gòu)的穩(wěn)定性和運(yùn)算的準(zhǔn)確性直接影響到FFT處理器的性能。分析基4FFT的特點(diǎn),綜合考慮面積、性能、功耗各個(gè)方面的因素,設(shè)計(jì)出結(jié)合流水線技術(shù)和并行結(jié)構(gòu)的蝶形運(yùn)算單元。
蝶形運(yùn)算單元結(jié)構(gòu)設(shè)計(jì)
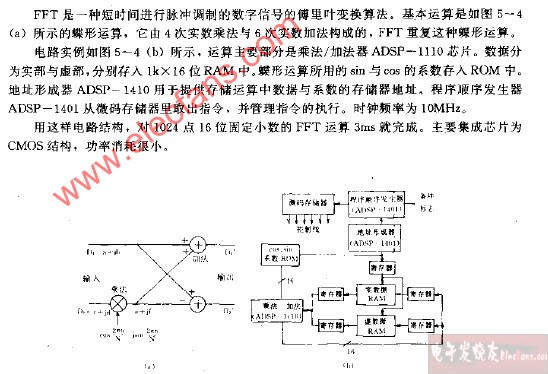
基24FFT中蝶形運(yùn)算單元的處理結(jié)構(gòu)見圖

傳統(tǒng)的基4算法是用3個(gè)復(fù)數(shù)乘法器和12個(gè)復(fù)數(shù)加法器構(gòu)成,每次復(fù)數(shù)乘法器由4個(gè)實(shí)數(shù)乘法器和2個(gè)實(shí)數(shù)加法實(shí)現(xiàn),每個(gè)復(fù)數(shù)加法由2個(gè)實(shí)數(shù)加法器實(shí)現(xiàn)。如此將基24算法的計(jì)算結(jié)構(gòu)直接映射至硬件需消耗大量的邏輯資源(12個(gè)實(shí)數(shù)乘法器和22個(gè)實(shí)數(shù)加法器)。
經(jīng)過重新排列如下:


觀察xc和uc,Xc和Uc,yc和zc,Yc和Zc這4組表達(dá)式,可以發(fā)現(xiàn)其對(duì)應(yīng)的實(shí)部和虛部括號(hào)內(nèi)的內(nèi)容相同,因此可以將流水線方式與并行結(jié)構(gòu)的思想巧妙結(jié)合起來,用4個(gè)循環(huán)序列對(duì)各寄存器進(jìn)行嚴(yán)格的時(shí)序控制,只用1個(gè)實(shí)數(shù)乘法器來實(shí)現(xiàn)一次復(fù)數(shù)乘法器,對(duì)應(yīng)3個(gè)不同的復(fù)數(shù)乘法用3個(gè)實(shí)數(shù)乘法并行進(jìn)行;加法器也并行進(jìn)行循環(huán)使用。因此,完成一個(gè)基4FFT蝶形運(yùn)算單元僅需要3個(gè)實(shí)數(shù)乘法以及6個(gè)實(shí)數(shù)加法,相比傳統(tǒng)基24FFT蝶形運(yùn)算單元,可節(jié)省75%的乘法器邏輯資源和72.7%的加法器邏輯資源。
蝶形運(yùn)算單元的結(jié)構(gòu)如圖2所示

數(shù)據(jù)切換單元
流水線技術(shù)與并行結(jié)構(gòu)相結(jié)合的方法可以提高設(shè)計(jì)的靈活性,減小核心單元的面積,提高芯片運(yùn)行的速度。流水線技術(shù)與并行結(jié)構(gòu)相結(jié)合必須在時(shí)序的嚴(yán)格控制下執(zhí)行。
數(shù)據(jù)切換單元由狀態(tài)機(jī)組成,以蝶形運(yùn)算單元的第1級(jí)數(shù)據(jù)切換單元為例。每組數(shù)據(jù)輸入乘法器分為4個(gè)狀態(tài)(分別為A、B、C、D)。狀態(tài)A輸入乘數(shù)的實(shí)部和旋轉(zhuǎn)因子的實(shí)部;狀態(tài)B輸入乘數(shù)的實(shí)部和旋轉(zhuǎn)因子的虛部;狀態(tài)C輸入乘數(shù)的虛部和旋轉(zhuǎn)因子的實(shí)部;狀態(tài)D輸入乘數(shù)的虛部和旋轉(zhuǎn)因子的虛部。其他3級(jí)數(shù)據(jù)切換單元根據(jù)前一級(jí)運(yùn)算結(jié)構(gòu)輸出以此類推得到。每一級(jí)的具體結(jié)果以及步驟見表1。完成4級(jí)運(yùn)算后,并行輸出結(jié)果的實(shí)部和虛部

浮點(diǎn)乘法器的設(shè)計(jì)
本設(shè)計(jì)中浮點(diǎn)數(shù)乘法器需完成2個(gè)IEEE754單精度浮點(diǎn)數(shù)之間的乘法,包括3個(gè)部分尾數(shù)乘法、指數(shù)加法和符號(hào)處理。浮點(diǎn)乘法器結(jié)構(gòu)見圖3

乘法的處理可分為3個(gè)步驟:
a)對(duì)輸入數(shù)據(jù)進(jìn)行預(yù)處理,即判斷輸入中是否有0,同時(shí)將輸入數(shù)據(jù)的符號(hào)位、指數(shù)部分以及尾數(shù)部分拆開分別處理,符號(hào)位寄存,指數(shù)部分相加,尾數(shù)部分預(yù)處理;
b)將23位尾數(shù)和1位隱含位/10構(gòu)成的24位有效數(shù)送入定點(diǎn)乘法器進(jìn)行運(yùn)算,并寄存預(yù)處理單元的其他輸出數(shù)據(jù);
c)接收定點(diǎn)乘法運(yùn)算結(jié)果以及相關(guān)寄存器輸出,將最終結(jié)果規(guī)格化為IEEE754標(biāo)準(zhǔn)單精度浮點(diǎn)格式。
24位定點(diǎn)乘法器采用了經(jīng)典的陣列式結(jié)構(gòu)結(jié)合改進(jìn)Booth算法的樹形結(jié)構(gòu)。陣列式定點(diǎn)乘法器結(jié)構(gòu)規(guī)整,適合于流水線處理,但是流水線深度過深,初始時(shí)延過長,硬件資源消耗過大。
改進(jìn)的Booth算法將24位定點(diǎn)乘法運(yùn)算的部分積由24個(gè)壓縮至13個(gè),降低硬件開銷,減少流水線級(jí)數(shù)。利用改進(jìn)的Booth算法設(shè)計(jì)一種華萊士樹形結(jié)構(gòu),如圖4所示。

用3級(jí)4B2壓縮器將13個(gè)部分積逐級(jí)壓縮到2個(gè),級(jí)間插入寄存器實(shí)現(xiàn)全流水,壓縮后的2個(gè)部分積用快數(shù)加法器相加得到最終結(jié)果。4B2壓縮器的邏輯結(jié)構(gòu)見圖5,由4B2壓縮單元級(jí)聯(lián)組成。

對(duì)并行的全加器進(jìn)行邏輯化簡(jiǎn)可以得到4B2壓縮單元,其邏輯表達(dá)式如下:

利用改進(jìn)后的結(jié)構(gòu)設(shè)計(jì)的定點(diǎn)乘法器流水線深度只有7級(jí),降低了硬件成本,減小了流水線的初始延時(shí),提高了系統(tǒng)的性能。
浮點(diǎn)乘法器的改進(jìn)
分析4B2壓縮器的邏輯表達(dá)式,可以發(fā)現(xiàn)當(dāng)輸入的a1,a2,a3,a4相同的時(shí)候,輸出的Cout相同;當(dāng)輸入的a1,a2,a3,a4以及Cin相同時(shí),輸出的S和C都相同。
再分析Booth算法。Booth編碼是針對(duì)有符號(hào)數(shù)的乘法,需要將符號(hào)位擴(kuò)展并且移位;2個(gè)24bit定點(diǎn)數(shù)相乘,得到1個(gè)48bit的乘積,因此產(chǎn)生的部分積有2bit~24bit不等的相同符號(hào)位。
在華萊士樹形結(jié)構(gòu)中,Booth算法得到的13個(gè)48bit的部分積相加,只需要將其中的25bit相加,其他23bit可以通過分析直接得到和位和進(jìn)位。每個(gè)乘法器節(jié)省了70個(gè)4B2壓縮器,減少了關(guān)鍵路徑時(shí)間,提高了乘法器的執(zhí)行速度。
浮點(diǎn)加法器設(shè)計(jì)
浮點(diǎn)加法器包括數(shù)據(jù)預(yù)處理電路、26bit加法器以及浮點(diǎn)數(shù)格式化處理,采用流水線技術(shù),見圖6。

浮點(diǎn)加法的處理步驟如下:
a)數(shù)據(jù)預(yù)處理部分,包括判零電路,如果其中一個(gè)加數(shù)為0,那么加法輸出結(jié)果應(yīng)該等于另一個(gè)加數(shù);指數(shù)對(duì)齊;尾數(shù)移位實(shí)現(xiàn)尾數(shù)補(bǔ)齊和隱藏位/10擴(kuò)展以及符號(hào)位擴(kuò)展。
b)運(yùn)用進(jìn)位保留和進(jìn)位傳遞相結(jié)合的26bit加法器。
c)將最終結(jié)果再格式化為IEEE754標(biāo)準(zhǔn)單精度浮點(diǎn)格式。
26bit定點(diǎn)加法器是浮點(diǎn)加法器的核心加法單元,本設(shè)計(jì)采用了超前進(jìn)位和進(jìn)位保留相結(jié)合的方法,見圖7。超前進(jìn)位加法器的特點(diǎn)是各級(jí)進(jìn)位信號(hào)同時(shí)產(chǎn)生,大大減少了進(jìn)位產(chǎn)生的時(shí)間,一般不超過4bi,t故將26bit分成6個(gè)3bit塊和2個(gè)4bit塊。其中,AF_3、AF_4采用超前進(jìn)位加法器,26bit進(jìn)位選擇加法器僅用2級(jí)流水線就能達(dá)到所需性能要求。

浮點(diǎn)加法器的改進(jìn)
在滿足時(shí)序的情況下,分析26bit快速加法器。超前進(jìn)位加法器適用于不超過4bit的數(shù)據(jù),進(jìn)位保留加法器是以面積換速度。如果采用兩級(jí)流水線完成26bit加法器,時(shí)序上一定滿足,但是卻以24個(gè)AF_3和8個(gè)AF_4為代價(jià)。基于面積和時(shí)序的折衷優(yōu)化,我們采用以下框圖完成26bit加法器。只需要12個(gè)AF_3和4個(gè)AF_4即可完成26bit進(jìn)位選擇加法器。
邏輯綜合
在蝶形運(yùn)算單元結(jié)構(gòu)完成之后,采用VerilogHDL對(duì)整個(gè)系統(tǒng)進(jìn)行了RTL級(jí)描述和邏輯綜合及功能驗(yàn)證。本文基于TSMC0.18LmCMOS標(biāo)準(zhǔn)單元庫,使用Synopsys的DesignCompiler進(jìn)行邏輯綜合,使用Modsim進(jìn)行仿真,并且與MATLAB計(jì)算結(jié)果進(jìn)行對(duì)比。
邏輯綜合
設(shè)計(jì)目標(biāo)為200MHz時(shí)鐘,設(shè)定20%裕量,因此約束時(shí)鐘為4ns,具體約束條件如下:時(shí)鐘周期4ns,時(shí)間抖動(dòng)和歪斜0.1ns,線負(fù)載模型tsmc18_wl120,輸入輸出延時(shí)0.8ns,滿足時(shí)序的情況下面積最小化。
綜合完成后結(jié)果如圖8所示。

蝶形運(yùn)算單元邏輯綜合報(bào)告顯示關(guān)鍵路徑延時(shí)3.4ns《4ns,所以slack為正。總單元面積1.12mm2,總的動(dòng)態(tài)功耗為376.9mW。
基24FFT蝶形運(yùn)算單元使用TSMC0.18LmCMOS標(biāo)準(zhǔn)單元庫,能穩(wěn)定工作在200MHz的時(shí)鐘頻率。采用改進(jìn)的基24FFT蝶形結(jié)構(gòu)圖,將乘法器節(jié)省75%,加法器節(jié)省72.7%;采用改進(jìn)的浮點(diǎn)乘法器和浮點(diǎn)加法器,使蝶形運(yùn)算單元的面積節(jié)省了1.64萬門。
此蝶形運(yùn)算單元在滿足200MHz的前提下,面積和功耗得到很大改善。對(duì)于N點(diǎn)FFT需要log4N級(jí)、每級(jí)N/4次蝶形運(yùn)算,假設(shè)每級(jí)數(shù)據(jù)需要10點(diǎn)預(yù)存,數(shù)據(jù)輸入輸出需要1024@2個(gè)時(shí)鐘,完成1024點(diǎn)運(yùn)算的時(shí)間[(1024/4+10)@log41024+1024@2]@5ns=16.89ns。
可見,使用該蝶形運(yùn)算單元構(gòu)成FFT處理器在性能上處于領(lǐng)先地位。






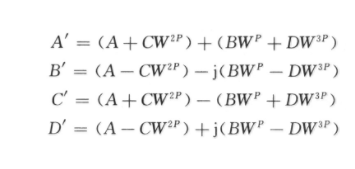
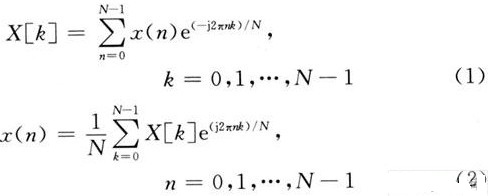





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論