 電子發(fā)燒友App
電子發(fā)燒友App


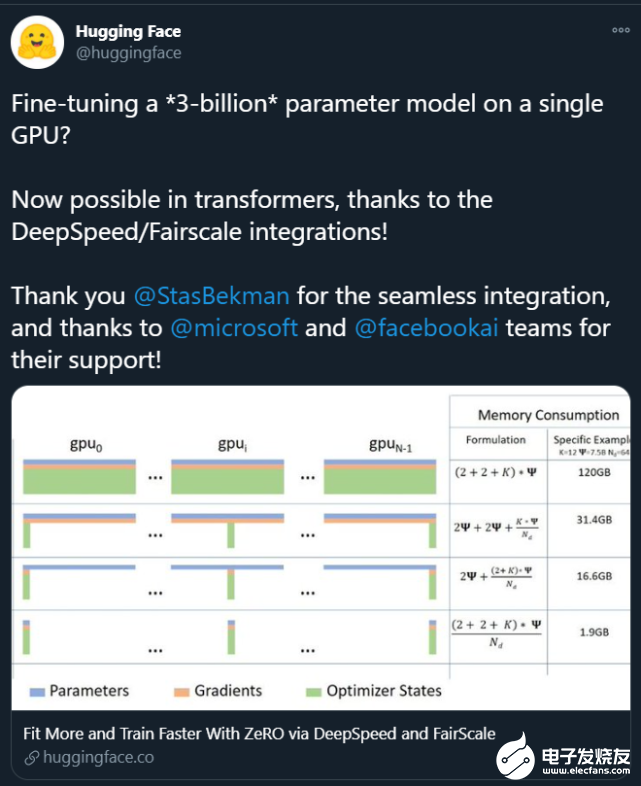
深度學(xué)習模型和數(shù)據(jù)集的規(guī)模增長速度已經(jīng)讓 GPU 算力也開始捉襟見肘,如果你的 GPU 連一個樣本都容不下,你要如何訓(xùn)練大批量模型?通過本文介紹的方法,我們可以在訓(xùn)練批量甚至單個訓(xùn)練樣本大于 GPU 內(nèi)存時,在單個或多個 GPU 服務(wù)器上訓(xùn)練模型。
分布式計算
2018 年的大部分時間我都在試圖訓(xùn)練神經(jīng)網(wǎng)絡(luò)時克服 GPU 極限。無論是在含有 1.5 億個參數(shù)的語言模型(如 OpenAI 的大型生成預(yù)訓(xùn)練 Transformer 或最近類似的 BERT 模型)還是饋入 3000 萬個元素輸入的元學(xué)習神經(jīng)網(wǎng)絡(luò)(如我們在一篇 ICLR 論文《Meta-Learning a Dynamical Language Model》中提到的模型),我都只能在 GPU 上處理很少的訓(xùn)練樣本。
但在多數(shù)情況下,隨機梯度下降算法需要很大批量才能得出不錯的結(jié)果。
如果你的 GPU 只能處理很少的樣本,你要如何訓(xùn)練大批量模型?
有幾個工具、技巧可以幫助你解決上述問題。在本文中,我將自己用過、學(xué)過的東西整理出來供大家參考。
在這篇文章中,我將主要討論 PyTorch 框架。有部分工具尚未包括在 PyTorch(1.0 版本)中,因此我也寫了自定義代碼。
我們將著重探討以下問題:
在訓(xùn)練批量甚至單個訓(xùn)練樣本大于 GPU 內(nèi)存,要如何在單個或多個 GPU 服務(wù)器上訓(xùn)練模型;
如何盡可能高效地利用多 GPU 機器;
在分布式設(shè)備上使用多個機器的最簡單訓(xùn)練方法。
在一個或多個 GPU 上訓(xùn)練大批量模型
你建的模型不錯,在這個簡潔的任務(wù)中可能成為新的 SOTA,但每次嘗試在一個批量處理更多樣本時,你都會得到一個 CUDA RuntimeError:內(nèi)存不足。
這位網(wǎng)友指出了你的問題!
但你很確定將批量加倍可以優(yōu)化結(jié)果。
你要怎么做呢?
這個問題有一個簡單的解決方法:梯度累積。

梯度下降優(yōu)化算法的五個步驟。
與之對等的 PyTorch 代碼也可以寫成以下五行:
predictions = model(inputs) # Forward pass
loss = loss_function(predictions, labels) # Compute loss function
loss.backward() # Backward pass
optimizer.step() # Optimizer step
predictions = model(inputs) # Forward pass with new parameters
在 loss.backward() 運算期間,為每個參數(shù)計算梯度,并將其存儲在與每個參數(shù)相關(guān)聯(lián)的張量——parameter.grad 中。
累積梯度意味著,在調(diào)用 optimizer.step() 實施一步梯度下降之前,我們會對 parameter.grad 張量中的幾個反向運算的梯度求和。在 PyTorch 中這一點很容易實現(xiàn),因為梯度張量在不調(diào)用 model.zero_grad() 或 optimizer.zero_grad() 的情況下不會重置。如果損失在訓(xùn)練樣本上要取平均,我們還需要除以累積步驟的數(shù)量。
以下是使用梯度累積訓(xùn)練模型的要點。在這個例子中,我們可以用一個大于 GPU 最大容量的 accumulation_steps 批量進行訓(xùn)練:
model.zero_grad() # Reset gradients tensors
for i, (inputs, labels) in enumerate(training_set):
predictions = model(inputs) # Forward pass
loss = loss_function(predictions, labels) # Compute loss function
loss = loss / accumulation_steps # Normalize our loss (if averaged)
loss.backward() # Backward pass
if (i+1) % accumulation_steps == 0: # Wait for several backward steps
optimizer.step() # Now we can do an optimizer step
model.zero_grad() # Reset gradients tensors
if (i+1) % evaluation_steps == 0: # Evaluate the model when we...
evaluate_model() # ...have no gradients accumulated
擴展到極致
你可以在 GPU 上訓(xùn)練連一個樣本都無法加載的模型嗎?
如果你的架構(gòu)沒有太多跳過連接,這就是可能的!解決方案是使用梯度檢查點(gradient-checkpointing)來節(jié)省計算資源。
基本思路是沿著模型將梯度在小組件中進行反向傳播,以額外的前饋傳遞為代價,節(jié)約存儲完整的反向傳播圖的內(nèi)存。這個方法比較慢,因為我們需要添加額外的計算來減少內(nèi)存要求,但在某些設(shè)置中挺有意思,比如在非常長的序列上訓(xùn)練 RNN 模型(示例參見 https://medium.com/huggingface/from-zero-to-research-an-introduction-to-meta-learning-8e16e677f78a)。
這里不再贅述,讀者可以查看以下鏈接:
TensorFlow:https://github.com/openai/gradient-checkpointing
PyTorch 文檔:https://pytorch.org/docs/stable/checkpoint.html

“節(jié)約內(nèi)存”(Memory-poor)策略需要 O(1) 的內(nèi)存(但是要求 O(n²) 的計算步)。
充分利用多 GPU 機器
現(xiàn)在我們具體來看如何在多 GPU 上訓(xùn)練模型。
在多 GPU 服務(wù)器上訓(xùn)練 PyTorch 模型的首選策略是使用 torch.nn.DataParallel。該容器可以在多個指定設(shè)備上分割輸入,按照批維度(batch dimension)分割,從而實現(xiàn)模塊應(yīng)用的并行化。
DataParallel 非常容易使用,我們只需添加一行來封裝模型:
parallel_model = torch.nn.DataParallel(model) # Encapsulate the model
predictions = parallel_model(inputs) # Forward pass on multi-GPUs
loss = loss_function(predictions, labels) # Compute loss function
loss.backward() # Backward pass
optimizer.step() # Optimizer step
predictions = parallel_model(inputs) # Forward pass with new parameters
但是,DataParallel 有一個問題:GPU 使用不均衡。
在一些設(shè)置下,GPU-1 會比其他 GPU 使用率高得多。
這個問題從何而來呢?下圖很好地解釋了 DataParallel 的行為:
使用 torch.nn.DataParallel 的前向和后向傳播。
在前向傳播的第四步(右上),所有并行計算的結(jié)果都聚集在 GPU-1 上。這對很多分類問題來說是件好事,但如果你在大批量上訓(xùn)練語言模型時,這就會成為問題。
我們可以快速計算語言模型輸出的大小:
語言模型輸出中的元素數(shù)量。
假設(shè)我們的數(shù)據(jù)集有 4 萬詞匯,每一條序列有 250 個 token、每個 batch 中有 32 條序列,那么序列中的每一個元素需要 4 個字節(jié)的內(nèi)存空間,模型的輸出大概為 1.2GB。要儲存相關(guān)的梯度張量,我們就需要把這個內(nèi)存翻倍,因此我們的模型輸出需要 2.4GB 的內(nèi)存。
這是典型 10GB GPU 內(nèi)存的主要部分,意味著相對于其它 GPU,GPU - 1 會被過度使用,從而限制了并行化的效果。
如果不調(diào)整模型和/或優(yōu)化方案,我們就無法輕易減少輸出中的元素數(shù)量。但我們可以確保內(nèi)存負載在 GPU 中更均勻地分布。

















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論