 電子發(fā)燒友App
電子發(fā)燒友App


數(shù)據(jù)庫架構(gòu)的演變
?
在業(yè)務(wù)數(shù)據(jù)量比較少的時(shí)代,我們使用單機(jī)數(shù)據(jù)庫就能滿足業(yè)務(wù)使用,隨著業(yè)務(wù)請(qǐng)求量越來越多,數(shù)據(jù)庫中的數(shù)據(jù)量快速增加,這時(shí)單機(jī)數(shù)據(jù)庫已經(jīng)不能滿足業(yè)務(wù)的性能要求,數(shù)據(jù)庫主從復(fù)制架構(gòu)隨之應(yīng)運(yùn)而生。
?
主從復(fù)制是將數(shù)據(jù)庫寫操作和讀操作進(jìn)行分離,使用多個(gè)只讀實(shí)例(slaver replication)負(fù)責(zé)處理讀請(qǐng)求,主實(shí)例(master)負(fù)責(zé)處理寫請(qǐng)求,只讀實(shí)例通過復(fù)制主實(shí)例的數(shù)據(jù)來保持與主實(shí)例的數(shù)據(jù)一致性。由于只讀實(shí)例可以水平擴(kuò)展,所以更多的讀請(qǐng)求不成問題,隨著云計(jì)算、大數(shù)據(jù)時(shí)代的到來,事情并沒有完美的得以解決,當(dāng)寫請(qǐng)求越來越多,主實(shí)例的寫請(qǐng)求變成主要的性能瓶頸。
?
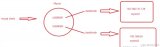
如何解決上述問題?如果僅僅通過增加一個(gè)主實(shí)例來分擔(dān)寫請(qǐng)求,寫操作如何在兩個(gè)主實(shí)例之間同步來保證數(shù)據(jù)一致性,如何避免雙寫,問題會(huì)變的更加復(fù)雜。這時(shí)就需要用到分庫分表(sharding),對(duì)寫操作進(jìn)行切分來解決,如圖1。
?
華為云中間件產(chǎn)品DDM(Distributed Database Middleware)作為RDS的前置分布式數(shù)據(jù)庫訪問服務(wù),徹底解決了數(shù)據(jù)庫的擴(kuò)展性問題,對(duì)應(yīng)用透明地實(shí)現(xiàn)海量數(shù)據(jù)的高并發(fā)訪問,實(shí)現(xiàn)了讀寫分離和分庫分表。
?
圖1:典型的讀寫分離和分庫分表
?
數(shù)據(jù)分片的實(shí)現(xiàn)方案
?
數(shù)據(jù)分片的實(shí)現(xiàn)方案可分為應(yīng)用層分片和中間件分片,這兩種實(shí)現(xiàn)方案的特點(diǎn)如圖2所示:
?
DDM作為一款優(yōu)秀的分布式數(shù)據(jù)庫中間件產(chǎn)品,實(shí)現(xiàn)了讀寫分離和數(shù)據(jù)分片功能,使用DDM來分庫分表,應(yīng)用0改動(dòng),對(duì)應(yīng)用完全透明。
?
分庫分表的切分方式
?
數(shù)據(jù)的切分(Sharding)根據(jù)其切分規(guī)則的類型,可以分為兩種切分模式。一種是按照不同的表(或者Schema)來切分到不同的數(shù)據(jù)庫(主機(jī))之上,這種切分方式可以稱之為數(shù)據(jù)的垂直(縱向)切分;另外一種則是根據(jù)表中的數(shù)據(jù)的邏輯關(guān)系,將同一個(gè)表中的數(shù)據(jù)按照某種條件拆分到多臺(tái)數(shù)據(jù)庫(主機(jī))上面,這種切分稱之為數(shù)據(jù)的水平(橫向)切分。
?
垂直切分最大特點(diǎn)就是規(guī)則簡單,實(shí)施也更為方便,尤其適合各業(yè)務(wù)之間的耦合度非常低,相互影響很小,業(yè)務(wù)邏輯非常清晰的系統(tǒng)。在這種系統(tǒng)中,可以很容易做到將不同業(yè)務(wù)模塊所使用的表分拆到不同的數(shù)據(jù)庫中。根據(jù)不同的表來進(jìn)行拆分,對(duì)應(yīng)用程序的影響也更小,拆分規(guī)則也會(huì)比較簡單清晰。
?
水平切分于垂直切分相比,相對(duì)來說稍微復(fù)雜一些。因?yàn)橐獙⑼粋€(gè)表中的不同數(shù)據(jù)拆分到不同的數(shù)據(jù)庫中,對(duì)于應(yīng)用程序來說,拆分規(guī)則本身比根據(jù)表名來拆分更為復(fù)雜,后期的數(shù)據(jù)維護(hù)也會(huì)更為復(fù)雜一些。
?
具體而言,如果單個(gè)庫太大,這時(shí)我們要看是因?yàn)楸矶喽鴮?dǎo)致數(shù)據(jù)多,還是因?yàn)閱螐埍砝锩娴臄?shù)據(jù)多。如果是因?yàn)楸矶喽鴶?shù)據(jù)多,使用垂直切分,根據(jù)業(yè)務(wù)切分成不同的庫。如果是因?yàn)閱螐埍淼臄?shù)據(jù)量太大,這時(shí)要用水平切分,即把表的數(shù)據(jù)按某種規(guī)則切分成多張表,甚至多個(gè)庫上的多張表。分庫分表的順序應(yīng)該是先垂直分,后水平分。因?yàn)榇怪狈指唵危衔覀兲幚憩F(xiàn)實(shí)世界問題的方式。
?
水平切分
?
相對(duì)于垂直拆分,水平拆分不是將表做分類,而是按照某個(gè)字段的某種規(guī)則來分散到多個(gè)庫之中,每個(gè)表中包含一部分?jǐn)?shù)據(jù)。簡單來說,我們可以將數(shù)據(jù)的水平切分理解為是按照數(shù)據(jù)行的切分,就是將表中的某些行切分到一個(gè)數(shù)據(jù)庫,而另外的某些行又切分到其他的數(shù)據(jù)庫中。
?
水平切分的優(yōu)點(diǎn):
?
1、拆分規(guī)則抽象好,join操作基本可以數(shù)據(jù)庫做。
?
2、不存在單庫大數(shù)據(jù),高并發(fā)的性能瓶頸。
?
3、應(yīng)用端改造較少。
?
4、 ?提高了系統(tǒng)的穩(wěn)定性跟負(fù)載能力。
?
水平切分的缺點(diǎn):
?
1、拆分規(guī)則難以抽象。
?
2、分片事務(wù)一致性難以解決。
?
3、數(shù)據(jù)多次擴(kuò)展難度跟維護(hù)量極大。
?
4、跨庫join性能較差。
?
水平切分的典型分片規(guī)則:
?
1、HASH取模
?
例如:取用戶id,然后hash取模,分配到不同的數(shù)據(jù)庫上。
?
2、RANGE
?
例如:從0到10000一個(gè)表,10001到20000一個(gè)表。
?
3、時(shí)間
?
按照時(shí)間切分,例如:將6個(gè)月前,甚至一年前的數(shù)據(jù)切出去放到另外的一張表,因?yàn)殡S著時(shí)間流逝,這些表的數(shù)據(jù)被查詢的概率變小,所以沒必要和”熱數(shù)據(jù)“放在一起,這個(gè)也是“冷熱數(shù)據(jù)分離”。
?
切分原則一般是根據(jù)業(yè)務(wù)找到適合的切分規(guī)則分散到不同的庫,根據(jù)用戶ID取模作為切分規(guī)則。
?
垂直切分
?
一個(gè)數(shù)據(jù)庫由很多表的構(gòu)成,每個(gè)表對(duì)應(yīng)著不同的業(yè)務(wù),垂直切分是指按照業(yè)務(wù)將表進(jìn)行分類,分布到不同的數(shù)據(jù)庫上面,這樣也就將數(shù)據(jù)或者說壓力分擔(dān)到不同的庫上面。
?
垂直切分的優(yōu)點(diǎn):
?
1、數(shù)據(jù)維護(hù)簡單。
?
2、拆分后業(yè)務(wù)清晰,拆分規(guī)則明確。
?
3、系統(tǒng)之間整合或擴(kuò)展容易。
?
垂直切分的缺點(diǎn):
?
1、事務(wù)處理復(fù)雜。
?
2、部分業(yè)務(wù)表無法join,只能通過接口方式解決,提高了系統(tǒng)復(fù)雜度。
?
3、受每種業(yè)務(wù)不同的限制存在單庫性能瓶頸,不易數(shù)據(jù)擴(kuò)展跟性能提高。
?
由于垂直切分是按照業(yè)務(wù)的分類將表分散到不同的庫,所以有些業(yè)務(wù)表會(huì)過于龐大,存在單庫讀寫與存儲(chǔ)瓶頸,所以就需要水平拆分來做解決。
?
切分原則
?
由于數(shù)據(jù)切分后數(shù)據(jù)Join的難度,在此也分享一下數(shù)據(jù)切分的經(jīng)驗(yàn):
?
第一原則:能不切分盡量不要切分。
?
第二原則:如果要切分一定要選擇合適的切分規(guī)則,提前規(guī)劃好。
?
第三原則:數(shù)據(jù)切分盡量通過數(shù)據(jù)冗余或表分組(Table Group)來降低跨庫Join的可能。
?
第四原則:由于數(shù)據(jù)庫中間件對(duì)數(shù)據(jù)Join實(shí)現(xiàn)的優(yōu)劣難以把握,而且實(shí)現(xiàn)高性能難度極大,業(yè)務(wù)讀取盡量少使用多表Join。
?
分庫分表后的問題和應(yīng)對(duì)策略
?
分庫分表主要用于應(yīng)對(duì)當(dāng)前互聯(lián)網(wǎng)常見的兩個(gè)場景:海量數(shù)據(jù)和高并發(fā)。然而,分庫分表是一把雙刃劍,雖然很好的應(yīng)對(duì)海量數(shù)據(jù)和高并發(fā)對(duì)數(shù)據(jù)庫的沖擊和壓力,但也提高了系統(tǒng)的復(fù)雜度和維護(hù)成本,帶來一些問題。
?
1、事務(wù)支持
?
在分庫分表后,就成為分布式事務(wù)了,如何保證數(shù)據(jù)的一致性成為一個(gè)必須面對(duì)的問題。一般情況下,使存儲(chǔ)數(shù)據(jù)盡可能達(dá)到用戶一致,保證系統(tǒng)經(jīng)過一段較短的時(shí)間的自我恢復(fù)和修正,數(shù)據(jù)最終達(dá)到一致。
?
2、分頁與排序問題
?
一般情況下,列表分頁時(shí)需要按照指定字段進(jìn)行排序。在單庫單表的情況下,分頁和排序也是非常容易的。但是,隨著分庫與分表的演變,也會(huì)遇到跨庫排序和跨表排序問題。為了最終結(jié)果的準(zhǔn)確性,需要在不同的分表中將數(shù)據(jù)進(jìn)行排序并返回,并將不同分表返回的結(jié)果集進(jìn)行匯總和再次排序,最后再返回給用戶。
?
3、表關(guān)聯(lián)問題
?
在單庫單表的情況下,聯(lián)合查詢是非常容易的。但是,隨著分庫與分表的演變,聯(lián)合查詢就遇到跨庫關(guān)聯(lián)的問題。粗略的解決方法:ER分片:子表的記錄與所關(guān)聯(lián)的父表記錄存放在同一個(gè)數(shù)據(jù)分片上。全局表:基礎(chǔ)數(shù)據(jù),所有庫都拷貝一份。字段冗余:這樣有些字段就不用join去查詢了。ShareJoin:是一個(gè)簡單的跨分片join,目前支持2個(gè)表的join,原理就是解析SQL語句,拆分成單表的SQL語句執(zhí)行,然后把各個(gè)節(jié)點(diǎn)的數(shù)據(jù)匯集。
?
4、分布式全局唯一ID
?
在單庫單表的情況下,直接使用數(shù)據(jù)庫自增特性來生成主鍵ID,這樣確實(shí)比較簡單。在分庫分表的環(huán)境中,數(shù)據(jù)分布在不同的分表上,不能再借助數(shù)據(jù)庫自增長特性,需要使用全局唯一ID。
?
分庫分表案例
?
某稅務(wù)核心征管系統(tǒng),全國34個(gè)省國/地稅,電子稅務(wù)局15省格局。
?
技術(shù)路徑:核心征管?+?納稅服務(wù) 業(yè)務(wù)應(yīng)用分布式上云改造。
?
業(yè)務(wù)挑戰(zhàn)
?
1、數(shù)據(jù)查詢時(shí)間3-5秒,響應(yīng)速度慢嚴(yán)重影響體驗(yàn)
?
當(dāng)前業(yè)務(wù)邏輯大量放在數(shù)據(jù)庫層,一個(gè)辦稅業(yè)務(wù)的事務(wù)邊界過大(40條SQL語句),涉及以“申報(bào)”、“發(fā)票”大表為主的多張表關(guān)聯(lián)事務(wù)操作,導(dǎo)致業(yè)務(wù)查詢響應(yīng)速度慢。
?
2、億級(jí)數(shù)據(jù)快速的增長,挑戰(zhàn)業(yè)務(wù)性能瓶頸
?
省級(jí)稅務(wù)局,辦稅高峰期承載百萬級(jí)用戶并發(fā)量,3000-5000TPS。現(xiàn)網(wǎng)分析得到數(shù)據(jù):核心征管庫近1000張表,其中“申報(bào)”、“發(fā)票”業(yè)務(wù)表數(shù)據(jù)量大、增長快,是主要瓶頸表;發(fā)票綜合信息:每省10億級(jí)條記錄,每年千萬到億條記錄級(jí)別增量;申報(bào)信息表:億級(jí)記錄數(shù)據(jù)量。
?
解決方案
?
1、垂直分庫、微服務(wù)分解數(shù)據(jù)庫壓力,降低單業(yè)務(wù)sql數(shù)
?
基于微服務(wù)將大事務(wù)拆解為異步小事務(wù),業(yè)務(wù)邏輯從數(shù)據(jù)庫層面剝離。拆分主庫數(shù)據(jù),將大表垂直拆分到多個(gè)數(shù)據(jù)庫中,一個(gè)業(yè)務(wù)40條SQL縮減到20條SQL,達(dá)到分解數(shù)據(jù)庫壓力的目的。
?
2、數(shù)據(jù)分片支撐海量數(shù)據(jù)增長,線性提升業(yè)務(wù)處理速度
?
單表億級(jí)記錄以納稅人作為拆分鍵,拆分到RDS-MySQL?的128個(gè)分片上。實(shí)現(xiàn)支撐海量數(shù)據(jù)的存儲(chǔ)。拆分后數(shù)據(jù)庫設(shè)計(jì)簡潔、簡單,數(shù)據(jù)庫的表之間不設(shè)外鍵,不寫觸發(fā)器,不寫存儲(chǔ)過程,實(shí)現(xiàn)數(shù)據(jù)庫記錄的水平擴(kuò)展。
?
3、讀寫分離提升查詢性能
?
DDM自動(dòng)實(shí)現(xiàn)讀寫分離,透明地完成寫操作和讀操作的分發(fā),應(yīng)用程序無需做特殊的改動(dòng)和處理邏輯。寫操作分發(fā)到RDS主實(shí)例,讀操作自動(dòng)分發(fā)到RDS的多個(gè)讀實(shí)例上,這樣寫操作不會(huì)影響讀操作的并發(fā),讀并發(fā)業(yè)務(wù)增長時(shí)只需要按需增加只讀實(shí)例即可。
?
企業(yè)受益
?
1、使用了DDM之后,輕松突破原來的性能瓶頸,一次業(yè)務(wù)操作,原來需要3到5秒,現(xiàn)在只需要1秒。
?
2、讀寫操作通過DDM的自動(dòng)讀寫分離,在不改動(dòng)業(yè)務(wù)情況下,輕松提升了整體的讀寫并發(fā)能力。
?
文章來源:https://www.huaweicloud.com/
?




































































 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論