 電子發(fā)燒友App
電子發(fā)燒友App


作者簡介: Dr. Luo,東南大學(xué)工學(xué)博士,英國布里斯托大學(xué)博士后,是復(fù)睿微電子英國研發(fā)中心GRUK首席AI科學(xué)家,常駐英國劍橋。Dr. Luo長期從事科學(xué)研究和機(jī)器視覺先進(jìn)產(chǎn)品開發(fā),曾在某500強(qiáng)ICT企業(yè)擔(dān)任機(jī)器視覺首席科學(xué)家。
元宇宙是人類社會網(wǎng)絡(luò)化和虛擬化,通過對實(shí)體對象對應(yīng)生成數(shù)字”智能體”來構(gòu)建一個人機(jī)共存的新社會形態(tài)。元宇宙零距離社會里的社會計算,是一種數(shù)據(jù)行為的社會計算和人機(jī)交互的社交計算。
對于生成式AI行業(yè),我們也許可以將其核心演進(jìn)趨勢定義為人機(jī)智能的社交計算,簡單表述為通過完成類似通用的問題答問Q&A系統(tǒng)任務(wù),以及特定內(nèi)容的高清圖像生成,來促進(jìn)各行業(yè)轉(zhuǎn)型升級,尤其是數(shù)字內(nèi)容生產(chǎn),人機(jī)交互與問答(聊天,教育和金融服務(wù),醫(yī)療診療,自動駕駛等)行業(yè),從而進(jìn)一步打通元宇宙中真實(shí)世界與虛擬世界的社交溝通能力。 ? 對于自動駕駛ADS行業(yè),我們也許可以將其核心演進(jìn)趨勢定義為群體智能的社會計算,簡單表述為,用GPU/NPU大算力和去中心化計算來虛擬化駕駛環(huán)境,通過數(shù)字化智能體(自動駕駛車輛AV)的多模感知交互(社交)決策,以及車車協(xié)同,車路協(xié)同,車云協(xié)同,通過跨模數(shù)據(jù)融合、高清地圖重建、云端遠(yuǎn)程智駕等可信計算來構(gòu)建元宇宙中ADS的社會計算能力。
生成式AI
生成式AI大模型,包括近兩年推出的ChatGPT和Stable Diffusion,能夠比較滿意地完成類似通用的問題答問Q&A系統(tǒng)任務(wù),以及特定內(nèi)容的高清圖像生成。對各個行業(yè)來說,呈現(xiàn)著一定程度的顛覆性意義和充滿未來想象的商業(yè)空間,可以促進(jìn)各行業(yè)轉(zhuǎn)型升級,尤其是數(shù)字內(nèi)容生產(chǎn),人機(jī)交互與問答(聊天,教育和金融服務(wù),醫(yī)療診療,自動駕駛等)行業(yè)。 ?
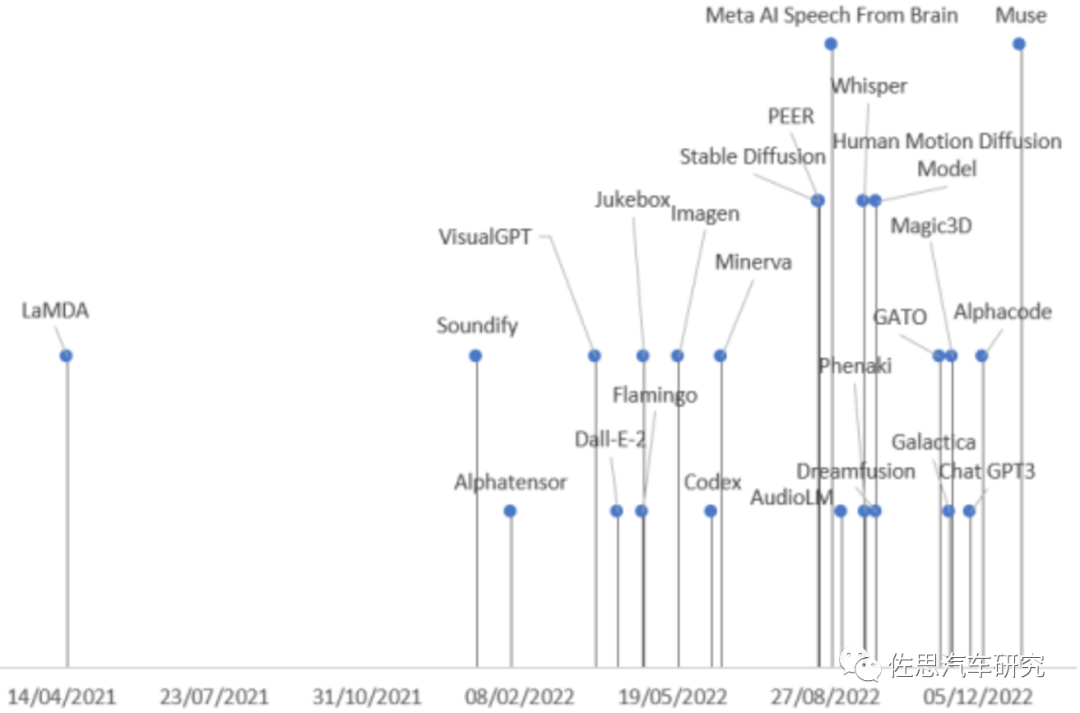
圖1:?生成式大模型發(fā)布時間軸(G-Brizuela, 2023)
如圖1所示,2021-2022年,我們很幸運(yùn)地迎來了DNN大模型的一輪大爆炸,即所謂的生成式AI(AIGC)浪潮。在演進(jìn)中的生成式AI大模型包括:
Text-to-Texts:ChatGPT3, PEER, LaMDA, Speech From Brain
Text-to-Image: Starry A.I.(GAN-based), DALLE-2 (Diffusion-based), Stable Diffusion,Muse, Imagen
Text-to-3D-Image: Dreamfusion, Majic3D
Image-to-Text: Flamingo, VisualGPT
Text-to-Video: Phenaki, Soundify
Text-to-Audio: AudioLM, Jukebox, Whisper
Text-to-Code: Codex, Alphacode
Text-to-Scientific: Galactica, AlphaTensor, Mineva, GATO
上述的主流生成式AI大模型,如果從開發(fā)到最終擁有關(guān)系角度,可以簡單分類如下:
OpenAI: DALLE-2, ChatGPT3, Jukebox, Whisper
Google: Imagen, DreamFusion, Minerva, LaMDA, Muse, Phenaki, AudioLM
DeepMind: Flamingo, AlphaTensor, AlphaCode, GATO
Meta AI: PEER, Galctica, Speech From Brian
Runway: Stable Diffusion, Soundify
nVidia: Magic3D

從上述幾個生成式AI大模型的能力對比分析(G-Brizuela, 2023),以及圖2中ChatGPT在不同場景的邏輯錯誤對比,我們也許可以簡單總結(jié)以下:
創(chuàng)造性任務(wù):Text-to-Text, Text-to-Image, Text-to-Video
???準(zhǔn)確率仍然遠(yuǎn)低于預(yù)期,有待成熟完善。
個性化任務(wù):Text-to-Audio
???有限數(shù)據(jù)集問題,大規(guī)模參數(shù)訓(xùn)練困難,有待成熟完善。
科學(xué)類任務(wù):Text-to-Science, Text-to-code
???有限數(shù)據(jù)集問題,大規(guī)模參數(shù)訓(xùn)練困難,準(zhǔn)確率低于預(yù)期。
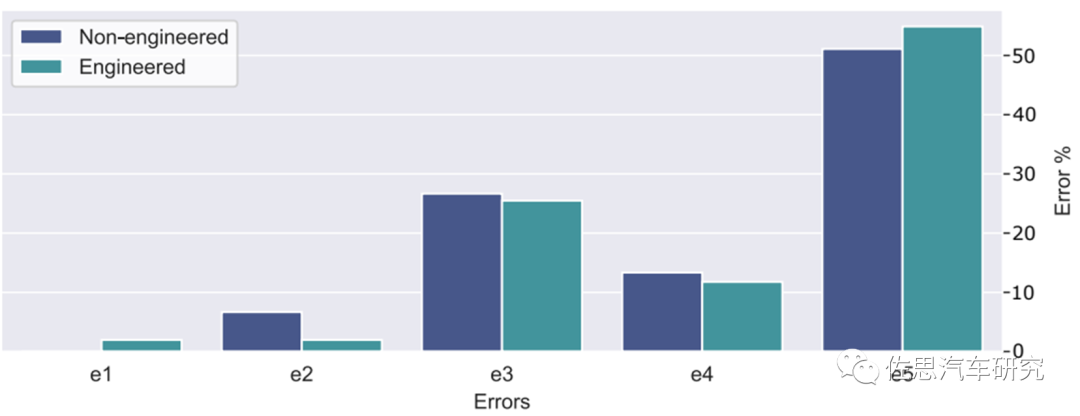
圖2: ChatGPT在不同場景下的邏輯錯誤對比
ChatGPT
ChatGPT(Generative Pre-trained Transformer)是OpenAI開發(fā)的一款生成式AI模型,它結(jié)合了監(jiān)督學(xué)習(xí)和強(qiáng)化學(xué)習(xí)方法,通過對話的方式來進(jìn)行交互:依據(jù)用戶的文本輸入來做多種語言的智能回復(fù),簡文或者長文模式,其中可以包括不同類型的問題答復(fù),翻譯,評論,行業(yè)分析,代碼生成與修改,以及撰寫各類計劃書與命題書籍等等。各類生成式AI模型也可以聯(lián)合調(diào)用來提供豐富的人機(jī)對話的能力。生成式AI模型多需要海量的參數(shù),來完成復(fù)雜的特征學(xué)習(xí)和記憶推理,例如ChatGPT模型參數(shù)為1750億。
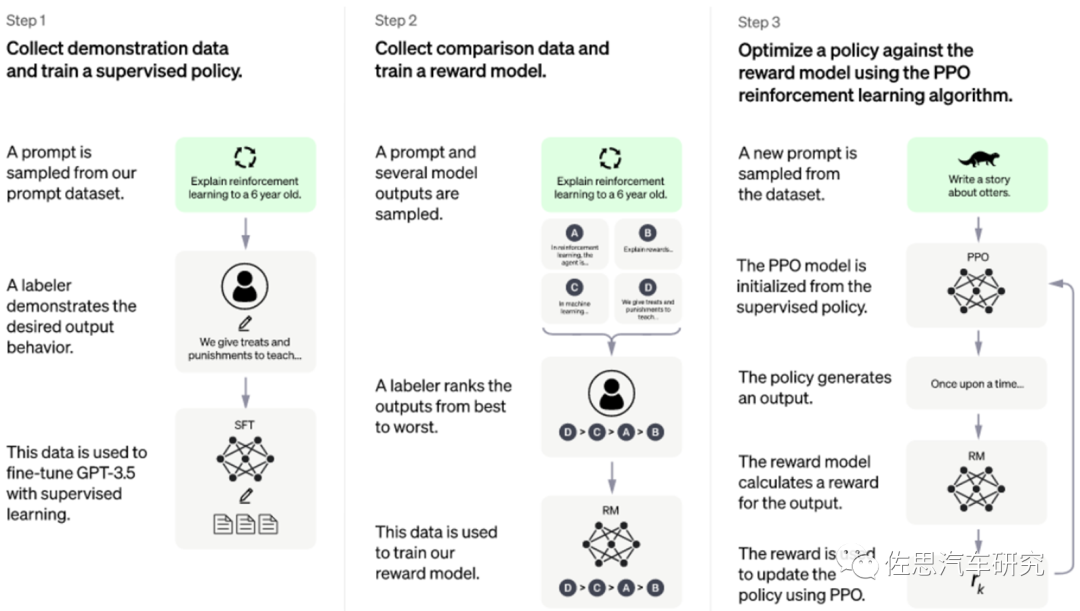
圖3:?ChatGPT模型的訓(xùn)練流程(G-Brizuela, 2023)
如圖3所示,ChatGPT模型結(jié)合了監(jiān)督學(xué)習(xí)和強(qiáng)化學(xué)習(xí)方法,采用了基于人類反饋的強(qiáng)化學(xué)習(xí)RLHF訓(xùn)練方法,與此同時采用了遷移學(xué)習(xí)(或者叫自監(jiān)督學(xué)習(xí))的訓(xùn)練方法,即通過預(yù)訓(xùn)練方式加上人工監(jiān)督進(jìn)行調(diào)優(yōu)(近端策略優(yōu)化PPO算法)。RLHF訓(xùn)練方法確實(shí)可以通過輸出的調(diào)節(jié),對結(jié)果進(jìn)行更有理解性的排序,這種激勵反饋的機(jī)制,可以有效提升訓(xùn)練速度和性能。在實(shí)際對話過程中,如果給出答案不對(這是目前最讓人質(zhì)疑的地方,可能會錯誤地引導(dǎo)使用者),可以通過反饋和連續(xù)談話中對上下文的理解,主動承認(rèn)錯誤,通過優(yōu)化來調(diào)整輸出結(jié)果。給出錯誤問答的其中一個主要原因是缺乏對應(yīng)的訓(xùn)練數(shù)據(jù),有意思的是,雖然缺乏該領(lǐng)域的常識知識和推廣能力,但模型仍然能夠胡編亂造出錯誤或者是是而非的解答。ChatGPT的另外一個主要缺陷是只能基于已有知識進(jìn)行訓(xùn)練學(xué)習(xí),通過海量的參數(shù)(近100層的Transformer層)和已有的主題數(shù)據(jù)來進(jìn)行多任務(wù)學(xué)習(xí),目前來看仍缺乏持續(xù)學(xué)習(xí)或者叫做終身學(xué)習(xí)的機(jī)制,也許下一代算法能夠解決這個難題,這也需要同步解決采用終身學(xué)習(xí)新知識引發(fā)的災(zāi)難性遺忘難題等等。
自動駕駛:多智能體間的社交決策
在真實(shí)的交通場景里,一個理性的人類司機(jī)在復(fù)雜的和擁擠的行駛場景里,通過與周圍環(huán)境的有效協(xié)商,包括揮手給其它行駛車輛讓路,設(shè)置轉(zhuǎn)向燈或閃燈來表達(dá)自己的意圖,來做出一個個有社交共識的合理決策。而這種基于交通規(guī)則+常識的動態(tài)交互,可以在多樣化的社交/交互駕駛行為分析中,通過對第三方駕駛者行為和反應(yīng)的合理期望,來有效預(yù)測場景中動態(tài)目標(biāo)的未來狀態(tài)。這也是設(shè)計智能車輛AV安全行駛算法的理論基礎(chǔ),即通過構(gòu)建多維感知+行為預(yù)測+運(yùn)動規(guī)劃的算法能力來實(shí)現(xiàn)決策安全的目的。而會影響到車輛在交互中的決策控制的駕駛行為包括駕駛者(人或AV)的社會層面交互和場景的物理層面交互兩個方面:
社會層面交互:案例包括行駛車輛在并道、換道、或讓道時的合理決策控制,主車道車輛在了解其它車輛的意圖后自我調(diào)速,給需要并換道的車輛合理讓路來避免可能的沖突和危險。
物理層面交互:案例包括靜態(tài)物理障礙(靜態(tài)停車車輛,道路可行駛的邊界,路面障礙物體)和動態(tài)物理線索(交通標(biāo)識,交通燈和實(shí)時狀態(tài)顯示,行人和運(yùn)動目標(biāo))。
ADS群體智能的社會計算,對這種交互/社交行為,可以在通常的定義上擴(kuò)展,也就是道路使用者或者行駛車輛之間的社交/交往,即通過彼此間的信息交換、協(xié)同或者博弈,實(shí)現(xiàn)各自利益最大化和獲取最低成本,這一般包括三個屬性(Wang 2022):
動態(tài)Dynamics:個體之間間和個體與環(huán)境之間的閉環(huán)反饋(State,Action, Reward),駕駛?cè)?智能體AV對總體環(huán)境動態(tài)做出貢獻(xiàn),也會被總體環(huán)境動態(tài)所影響。
度量Measurement:信息交換,包括跨模數(shù)據(jù)發(fā)布與共享,駕駛?cè)?智能體AV對道路使用者傳遞各自的社交線索和收集識別外部線索。
決策Decision:利益/利用最大化,理性來說道路使用者追求的多是個體的最大利益。
顯然,交通規(guī)則是不會完全規(guī)定和覆蓋所有駕駛行為的,其它方面可以通過個體之間的社交/交互來補(bǔ)充。人類司機(jī)總體來說也不會嚴(yán)格遵守交通規(guī)則,類似案例包括黃燈初期加速通過路口,讓路時占用部分其它道路空間來減少等待時間等等。ADS通過對這類社會行為的收集、學(xué)習(xí)與理解,可以部分模仿和社會兼容,通過Social-Aware和Safety-Assured決策,避免過度保守決策,同時提供算法模型的可解釋性、安全性能和控制效率。具體實(shí)現(xiàn)來說,可以采用類似人類司機(jī)的做法,依據(jù)駕駛?cè)蝿?wù)的不同,使用環(huán)境中不同的關(guān)注區(qū)域ROI和關(guān)注時間點(diǎn),以及直接或間接的社交/交互,采用類似概率圖模型和消息傳遞等機(jī)制來建模。
如何用生成式AI來提升自動駕駛ADS的產(chǎn)品競爭力
目前來看,生成式AI有可預(yù)期的未來,但依舊任重而道遠(yuǎn),尤其是數(shù)據(jù)的多樣性收集,如何從多模態(tài)海量知識里學(xué)習(xí)和融合各種知識,理解人類的使用需求,從上下文學(xué)習(xí)中,通過生成的方式來解決各類實(shí)際任務(wù)。對于跨行業(yè)技術(shù)推動而言,生成式AI采用的自監(jiān)督學(xué)習(xí)訓(xùn)練方法以及可以有效生成多類圖像視頻的能力,已經(jīng)開始在機(jī)器視覺任務(wù)中和自動駕駛的感知決策任務(wù)中得到應(yīng)用,可以有效填充自動駕駛場景覆蓋不足的Corner Case問題。下面將簡單列舉幾個典型應(yīng)用案例來討論一下生成式AI采用的核心技術(shù)在機(jī)器視覺和自動駕駛行業(yè)的應(yīng)用前景。
1、基于生成式AI的圖像數(shù)據(jù)拓展
機(jī)器視覺任務(wù),包括自動駕駛領(lǐng)域,一個核心的挑戰(zhàn)是數(shù)據(jù)多樣性分布不平衡(Dataset Bias)問題。采用生成式AI模型,可以生成或者基于已有數(shù)據(jù)集進(jìn)行有效拓展(Image Augmentation)。一個典型的應(yīng)用案例,例如采用Stable Diffusion模型的語義指導(dǎo)的圖像拓展SIP模型,其架構(gòu)如圖4所示。 ?
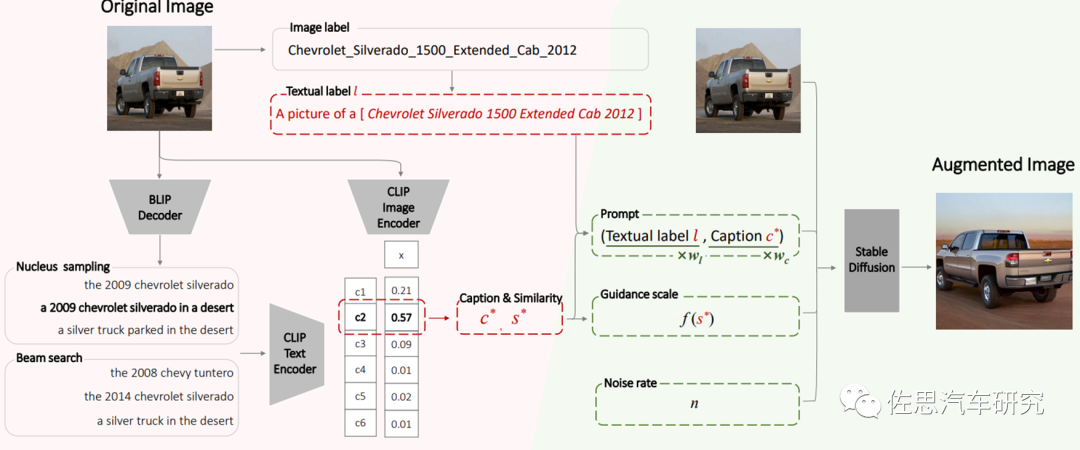
圖4:?采用Stable Diffusion模型的語義指導(dǎo)的圖像拓展案例(Li, 2023)
常用的圖像數(shù)據(jù)拓展多采用平移,變換,拷貝黏貼等策略,有像素級或者特征級等幾種類別,這些多數(shù)只是對圖像或者目標(biāo)進(jìn)行局部處理,很難在保持語義信息和多樣性之間找到平衡,而SIP模型的優(yōu)勢可以通用的生成式AI大模型,通過圖像的標(biāo)簽和標(biāo)題來指導(dǎo)Image-To-Image高清圖片生成,對比常用處理算法而言,性能也會有幾個百分點(diǎn)提升。
2、行動(action)可解釋的自動駕駛
對于自動駕駛技術(shù)而言,DL-based方法由于模塊化的設(shè)計和海量數(shù)據(jù)貢獻(xiàn),性能占優(yōu),但如何能夠提供安全能力和大規(guī)模部署,需要解決幾個挑戰(zhàn):在保證性能基礎(chǔ)上改善可解釋性;在不同的駕駛個體,場景和態(tài)勢下繼續(xù)增強(qiáng)模型的推廣能力。 ? 顯然生成式AI是可以用來對自動駕駛的每個決策過程進(jìn)行多任務(wù)的文本解釋。圖5是一個行為可感知可解釋的模型ADAPT設(shè)計架構(gòu)案例。ADAPT算法模型為每個場景可以提供用戶友好的自然語言的描述和對于每個決策控制指令/行為的比較合理的一系列解釋和推斷。這種實(shí)時的行為的文字表述和推斷,某種意義上會讓乘客了解車輛的狀態(tài),理解ADS決策如何以安全行駛為第一生產(chǎn)要素,以及決策的透明度和易于被使用者理解接受。
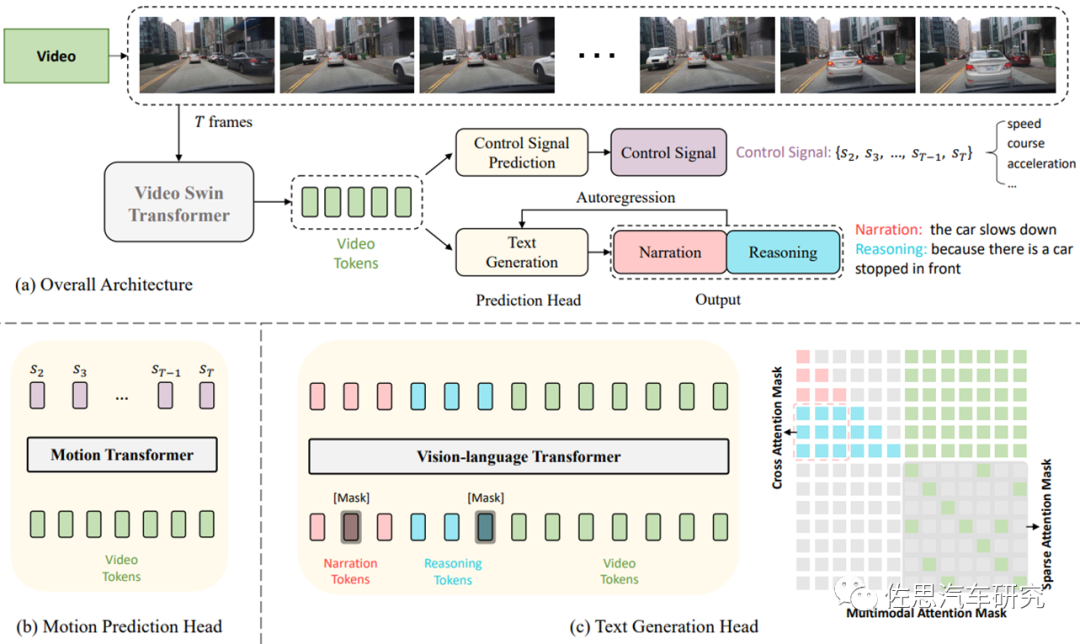
圖5:?ADAPT:Action-aware Driving Caption Transformer (Jin 2023)
ADAPT算法模型的量化分析如圖6所示。ADAPT所提供的基于語言的可解釋性,雖然只是一種簡單的嘗試,但未來對ADS能否被社會完全接受,有非常重要的意義。

圖6:?ADAPT算法模型的量化分析(Jin 2023)
參考文獻(xiàn):
[1] R. G-Brizuela anetc., “ChatGPT is not all you need: a State of the Art Review of largeGenerative AI models”, https://arxiv.org/abs/2301.04655v1
[2] S. Frieder and etc., “Mathematical Capabilities of ChatGPT”,https://arxiv.org/pdf/2301.13867.pdf
[3] B. Li and etc., “Semantic-Guided Image Augmentation with Pre-trainedModels”, https://arxiv.org/pdf/2302.02070.pdf
[4] B. Jin and etc., “”, https://arxiv.org/pdf/2302.00673.pdf
[5] W. Wang, and etc., “Social Interactions for Autonomous Driving: A Reviewand Perspective”, https://arxiv.org/pdf/2208.07541.pdf
編輯:黃飛
?








 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論