 直接通過預測 3D 關鍵點來估計透明物體深度的 ML 系統
直接通過預測 3D 關鍵點來估計透明物體深度的 ML 系統

計算機視覺應用領域的核心問題是3D 物體的位置與方向的估計,這與對象感知有關(如增強現實和機器人操作)。在這類應用中,需要知道物體在真實世界中的 3D 位置,以便直接對物體進行操作或在其四周正確放置模擬物。
圍繞這一主題已有大量研究,但此類研究雖然采用了機器學習 (ML) 技術,特別是 Deep Nets,但直接測量與物體的距離大多依賴于 Kinect 等深度感應設備。而對于表面有光澤或透明的物體,直接采用深度感應難以發揮作用。例如,下圖包括許多物體(左圖),其中兩個是透明的星星。深度感應設備無法很好的為星星測量深度值,因此難以重建 3D 點云效果圖(右圖)。
Deep Nets
https://arxiv.org/abs/1901.04780
左圖:透明物體的 RGB 圖像;右圖:左側場景的深度重建效果四格圖,上排為深度圖像,下排為 3D 點云,左側圖格采用深度相機重建,右側圖格是 ClearGrasp 模型的輸出。需要注意的是,雖然 ClearGrasp 修復了星星的深度,但它卻錯誤地識別了最右邊星星的實際深度
要解決這個問題,可以使用深度神經網絡來修復 (Inpainting) 透明物體的錯誤深度圖,例如使用 ClearGrasp 提出的方法:給定透明物體的單個 RGB-D 圖像,ClearGrasp 使用深度卷積網絡推斷透明表面法線、遮擋和遮擋邊界,然后通過這些信息完善場景中所有透明表面的初始深度估計(上圖最右)。這種方法很有前景,可以通過依賴深度的位置姿態估計方法處理具有透明物體的場景。但是修復可能會比較棘手,仍然可能導致深度錯誤,尤其是完全使用合成圖像進行訓練的情況。
我們與斯坦福大學 AI 實驗室在 CVPR 2020 上合作發表了“KeyPose: Multi-View 3D Labeling and Keypoint Estimation for Transparent Objects”,論文描述了直接通過預測 3D 關鍵點來估計透明物體深度的 ML 系統。為了訓練該系統,我們以半自動化方式收集了真實世界中透明物體圖像的大型數據集,并使用人工選擇的 3D 關鍵點標記有效姿態。然后開始訓練深度模型(稱為 KeyPose),從單目或立體圖像中估計端到端 3D 關鍵點,而不明確計算深度。
論文
https://openaccess.thecvf.com/content_CVPR_2020/html/Liu_KeyPose_Multi-View_3D_Labeling_and_Keypoint_Estimation_for_Transparent_Objects_CVPR_2020_paper.html
在訓練期間,模型在見過和未見過的物體上運行,無論是單個物體還是幾類物體。雖然 KeyPose 可以處理單目圖像,但立體圖像提供的額外信息使其結果提高了兩倍,根據物體不同,典型誤差在 5 毫米至 10 毫米之間。它對這些物體的姿態預測遠高于當前最先進水平,即使其他方法帶有地面真實深度。我們將發布關鍵點標記的透明物體數據集,供研究界使用。
關鍵點標記的透明物體數據集
https://sites.google.com/corp/view/transparent-objects
透明物體數據集
為了方便收集大量真實世界圖像,我們建立了一個機器人數據收集系統。系統的機械臂通過軌跡移動,同時使用立體攝像頭和 Kinect Azure 深度攝像頭拍攝視頻。
使用帶有立體攝像頭和 Azure Kinect 設備的機械臂自動捕捉圖像序列
目標上的 AprilTags 可以讓攝像頭準確跟蹤姿態。通過人工標記每個視頻中少量圖像 2D 關鍵點,我們可以使用多視角幾何圖形為視頻的所有幀提取 3D 關鍵點,將標記效率提高 100 倍。
我們捕捉了五種類別的 15 個不同透明物體的圖像,對每個物體使用 10 種不同的背景紋理和 4 種不同的姿勢,總計生成 600 個視頻序列,包括 4.8 萬個立體和深度圖像。我們還用不透明版本的物體捕捉了相同的圖像,以提供準確的深度圖像。所有圖像都標有 3D 關鍵點。我們將公開發布這一真實世界圖像數據集,為 ClearGrasp 合成數據集提供補充。
真實世界圖像數據集
https://sites.google.com/corp/view/transparent-objects
使用前期融合立體的 KeyPose 算法
針對關鍵點估計,本項目獨立開發出直接使用立體圖像的概念;這一概念最近也出現在手動跟蹤的環境下。下圖為基本思路:來自立體攝像頭的兩張圖像的物體被裁剪并饋送到 KeyPose 網絡,該網絡預測一組稀疏的 3D 關鍵點,代表物體的 3D 姿態。KeyPose 網絡使用 3D 關鍵點標記完成監督訓練。
手動跟蹤
https://bmvc2019.org/wp-content/uploads/papers/0219-paper.pdf

立體 KeyPose 的一個關鍵是使用允許網絡隱式計算視差的前期融合來混合立體圖像,與后期融合不同。后期融合是分別預測每個圖像的關鍵點,然后再進行組合。如下圖所示,KeyPose 的輸出圖像在平面上是 2D 關鍵點熱力圖,以及每個關鍵點的視差(即逆深度)熱力圖。這兩張熱力圖的組合會為每個關鍵點生成關鍵點 3D 坐標。

Keypose 系統圖:立體圖像被傳遞到 CNN 模型,為每個關鍵點生成概率熱力圖。此熱力圖輸出關鍵點的 2D 圖像坐標 (U,V)。CNN 模型還為每個關鍵點生成一個視差(逆深度)熱力圖,與 (U,V) 坐標結合時,可以給出 3D 位置 (X,Y,Z)
相較于后期融合或單目輸入,前期融合立體通常可以達到兩倍的準確率。
結果
下圖顯示了 KeyPose 對單個物體的定性結果。左側是一個原始立體圖像,中間是投射到圖像上的預測 3D 關鍵點。在右側,我們將 3D 瓶子模型中的點可視化,并放置在由預測 3D 關鍵點確定的姿態上。該網絡高效準確,在標準 GPU 上僅用 5 ms 的時間就預測出瓶子的 5.2 mm MAE (Mean Absolute Error) 和杯子的 10.1 mm MAE 關鍵點。
下表為 KeyPose 類別級別估計的結果。測試集使用了訓練集未見過的背景紋理。注意,MAE 從 5.8 mm 到 9.9 mm 不等,這表明該方法的準確率非常高。
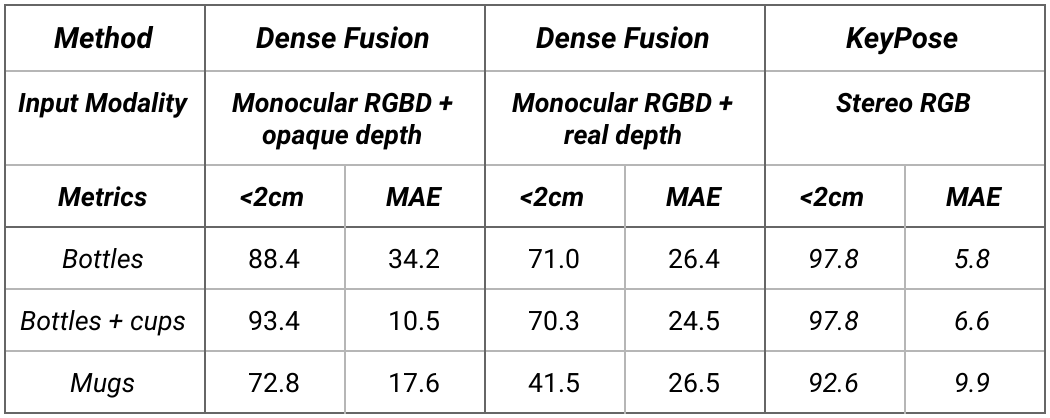
在類別級別數據上,KeyPose 與最先進的 DenseFusion 系統進行定量比較。我們為 DenseFusion 提供了兩個版本的深度:透明物體與不透明物體。<2cm是誤差小于 2cm 的估計百分比。MAE是關鍵點的平均絕對誤差,以 mm 為單位。
DenseFusion
https://arxiv.org/abs/1901.04780
有關定量結果以及消融研究的完整說明,請參見論文和補充材料以及 KeyPose 網站。
論文和補充材料
https://openaccess.thecvf.com/content_CVPR_2020/html/Liu_KeyPose_Multi-View_3D_Labeling_and_Keypoint_Estimation_for_Transparent_Objects_CVPR_2020_paper.html
KeyPose 網站
https://sites.google.com/corp/view/keypose/
結論
該研究表明,在不依賴深度圖像的情況下,從 RGB 圖像中可以準確估計透明物體的 3D 姿態。經過驗證,立體圖像可以作為前期融合 Deep Net 的輸入。在其中,網絡被訓練為直接從立體對中提取稀疏 3D 關鍵點。我們希望提供廣泛的帶標簽透明物體數據集,推動這一領域的發展。最后,盡管我們使用半自動方法對數據集進行了有效標記,但我們希望在以后的工作中能夠采用自監督方法來消除人工標記。
致謝
感謝合著者:斯坦福大學的 Xingyu Liu 以及 Rico Jonschkowski 和 Anelia Angelova;以及在項目和論文撰寫過程中,與我們一起討論并為我們提供幫助的人,包括 Andy Zheng、Suran Song、Vincent Vanhoucke、Pete Florence 和 Jonathan Tompson。
原文標題:機器人收集 + Keypose 算法:準確估計透明物體的 3D 姿態
文章出處:【微信公眾號:TensorFlow】歡迎添加關注!文章轉載請注明出處。
-
機器人
+關注
關注
213文章
29636瀏覽量
212250 -
計算機視覺
+關注
關注
9文章
1708瀏覽量
46682
原文標題:機器人收集 + Keypose 算法:準確估計透明物體的 3D 姿態
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
安森美這款iToF傳感器讓3D深度測量技術輕松落地

【AIBOX 應用案例】單目深度估計

3D IC背后的驅動因素有哪些?

2.5D和3D封裝技術介紹

3D深度感測的原理和使用二極管激光來實現深度感測的優勢
光學系統的3D可視化
3D打印技術,推動手板打樣從概念到成品的高效轉化
3D線激光輪廓測量儀的關鍵參數——最大掃碼頻率
物聯網行業中的模具定制方案_3D打印材料選型分享


3D 建模:塑造未來的無限可能
透明樹脂材料3D打印服務全透應用案例
3d打印機器人外殼模型ABS材料3D打印噴漆服務-CASAIM
紫光展銳助力全球首款AI裸眼3D手機發布






 工商網監
工商網監
評論