 PWIL:不依賴對抗性的新型模擬學習
PWIL:不依賴對抗性的新型模擬學習

強化學習 (Reinforcement Learning,RL) 是一種通過反復試驗訓練智能體 (Agent) 在復雜環境中有序決策的范式,在游戲、機器人操作和芯片設計等眾多領域都取得了巨大成功。智能體的目標通常是最大化在環境中收集的總獎勵 (Reward),這可以基于速度、好奇心、美學等各種參數。然而,由于 RL 獎勵函數難以指定或過于稀疏,想要設計具體的 RL 獎勵函數并非易事。
游戲
https://ai.googleblog.com/2019/06/introducing-google-research-football.html
這種情況下,模仿學習(Imitation Learning,IL) 方法便派上了用場,因為這種方法通過專家演示而不是精心設計的獎勵函數來學習如何完成任務。然而,最前沿 (SOTA) 的 IL 方法均依賴于對抗訓練,這種訓練使用最小化/最大化優化過程,但在算法上不穩定并且難以部署。
在“原始 Wasserstein 模仿學習”(Primal Wasserstein Imitation Learning,PWIL) 中,我們基于 Wasserstein 距離(也稱為推土機距離)的原始形式引入了一種新的 IL 方法,這種方法不依賴對抗訓練。借助 MuJoCo 任務套件,我們通過有限數量的演示(甚至是單個示例)以及與環境的有限交互來模仿模擬專家,以此證明 PWIL 方法的有效性。
原始 Wasserstein 模仿學習
https://arxiv.org/pdf/2006.04678.pdf
MuJoCo 任務套件
https://gym.openai.com/envs/#mujoco

左圖:使用任務的真實獎勵(與速度有關)訓練的算法類人機器人“專家”;右圖:使用 PWIL 基于專家演示訓練的智能體
對抗模仿學習
最前沿的對抗 IL 方法的運作方式與生成對抗網絡 (GAN) 類似:訓練生成器(策略)以最大化判別器(獎勵)的混淆度,以便判別器本身被訓練來區分智能體的狀態-動作對和專家的狀態-動作對。對抗 IL 方法可以歸結為分布匹配問題,即最小化度量空間中概率分布之間距離的問題。不過,就像 GAN 一樣,對抗 IL 方法也依賴于最小化/最大化優化問題,因此在訓練穩定性方面面臨諸多挑戰。
訓練穩定性方面面臨諸多挑戰
https://developers.google.com/machine-learning/gan/problems
模仿學習歸結為分步匹配
PWIL 方法的原理是將 IL 表示為分布匹配問題(在本例中為 Wasserstein 距離)。第一步為從演示中推斷出專家的狀態-動作分布:即專家采取的動作與相應環境狀態之間的關系的集合。接下來的目標是通過與環境的交互來最大程度地減少智能體的狀態-動作分布與專家的狀態-動作分布之間的距離。相比之下,PWIL 是一種非對抗方法,因此可繞過最小化/最大化優化問題,直接最小化智能體的狀態-動作對分布與專家的狀態-動作對分布之間的 Wasserstein 距離。
PWIL 方法
計算精確的 Wasserstein 距離會受到限制(智能體軌跡結束時才能計算出),這意味著只有在智能體與環境交互完成后才能計算獎勵。為了規避這種限制,我們為距離設置了上限,可以據此定義使用 RL 優化的獎勵。
結果表明,通過這種方式,我們確實可以還原專家的行為,并在 MuJoCo 模擬器的許多運動任務中最小化智能體與專家之間的 Wasserstein 距離。對抗 IL 方法使用來自神經網絡的獎勵函數,因此,當智能體與環境交互時,必須不斷對函數進行優化和重新估計,而 PWIL 根據專家演示離線定義一個不變的獎勵函數,并且它所需的超參數量遠遠低于基于對抗的 IL 方法。
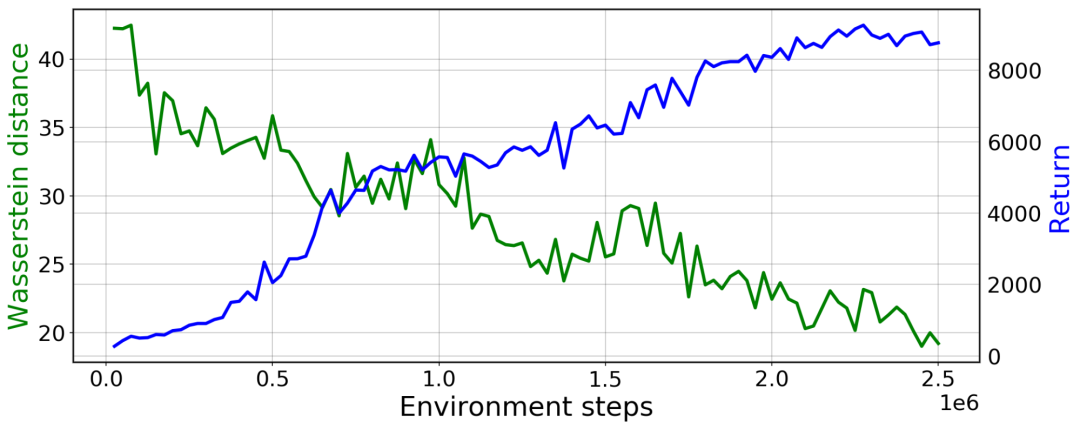
PWIL 在類人機器人上的訓練曲線:綠色表示與專家狀態-動作分布的 Wasserstein 距離;藍色表示智能體的回報(所收集獎勵的總和)
類人機器人
https://gym.openai.com/envs/Humanoid-v2/
衡量真實模仿學習環境的相似度
與 ML 領域的眾多挑戰類似,許多 IL 方法都在合成任務上進行評估,其中通常有一種方法可以使用任務的底層獎勵函數,并且可以根據性能(即預期的獎勵總和)來衡量專家行為與智能體行為之間的相似度。
PWIL 過程中會創建一個指標,該指標可以針對任何 IL 方法。這種方法能將專家行為與智能體行為進行比較,而無需獲得真正的任務獎勵。從這個意義上講,我們可以在真正的 IL 環境中使用 Wasserstein 距離,而不僅限于合成任務。
結論
在交互成本較高的環境(例如,真實的機器人或復雜的模擬器)中,PWIL 可以作為首選方案,不僅因為它可以還原專家的行為,還因為它所定義的獎勵函數易于調整,且無需與環境交互即可定義。
這為未來的探索提供了許多機會,包括部署到實際系統、將 PWIL 擴展到只能使用演示狀態(而不是狀態和動作)的設置,以及最終將 PWIL 應用于基于視覺的觀察。
責任編輯:lq
-
模擬器
+關注
關注
2文章
894瀏覽量
44259 -
智能體
+關注
關注
1文章
294瀏覽量
11038 -
強化學習
+關注
關注
4文章
269瀏覽量
11564
原文標題:PWIL:不依賴對抗性的新型模擬學習
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
NVMe IP高速傳輸卻不依賴XDMA設計之六:性能監測單元設計
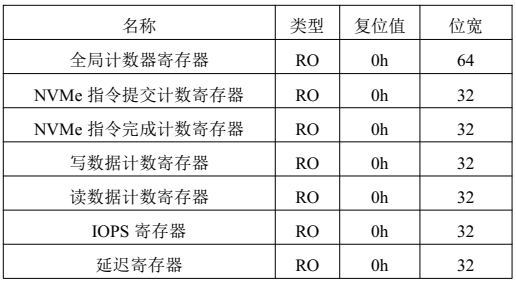
NVMe IP高速傳輸卻不依賴XDMA設計之五:DMA 控制單元設計
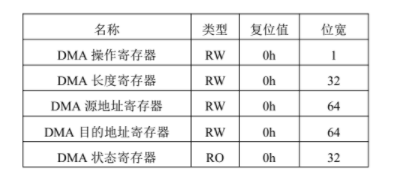
NVMe IP高速傳輸卻不依賴XDMA設計之五:DMA 控制單元設計
NVMe IP高速傳輸卻不依賴XDMA設計之四:系統控制模塊
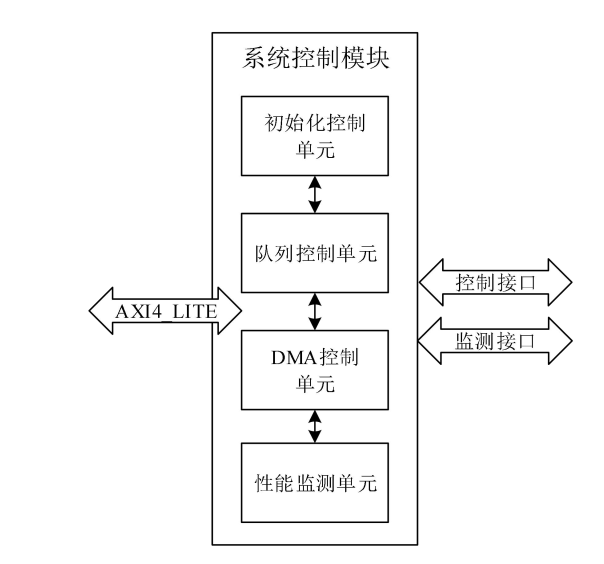
NVMe IP高速傳輸卻不依賴XDMA設計之三:系統架構
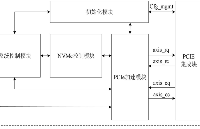
NVMe IP高速傳輸卻不依賴便利的XDMA設計之三:系統架構
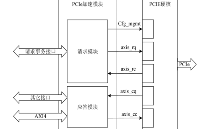
NVMe IP高速傳輸卻不依賴XDMA設計之二:PCIe讀寫邏輯
GPS對時設備,不依賴互聯網的"獨立時鐘"

NVMe IP高速傳輸卻不依賴便利的XDMA設計之二
魯棒性在機器學習中的重要性
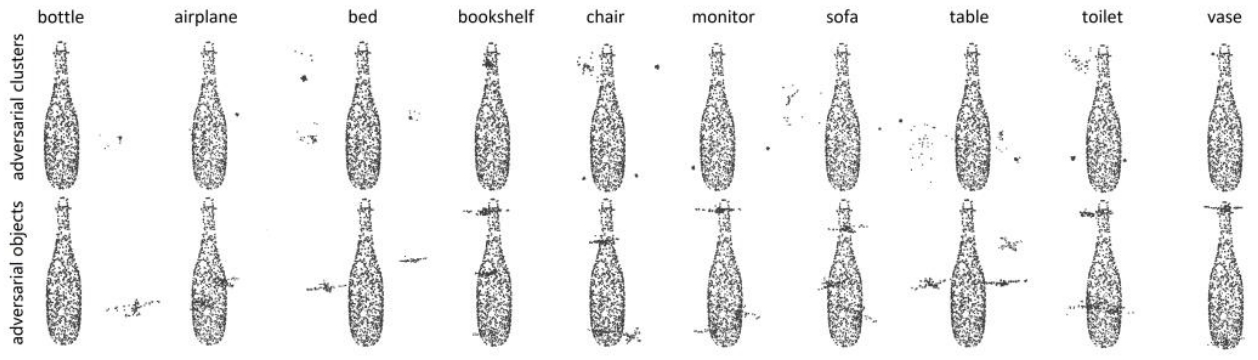
鑒源實驗室·如何通過雷達攻擊自動駕駛汽車-針對點云識別模型的對抗性攻擊的科普
原生鴻蒙系統正式發布,余承東宣布不依賴國外核心技術
FORT單元-不依賴GPS的步跟蹤定位穿戴設備@PNI

HDS-6智能型模擬斷路器使用說明






 工商網監
工商網監
評論