") b站面試之旅:了解哪些I/O模型?select是阻塞IO嗎?
b站面試之旅:了解哪些I/O模型?select是阻塞IO嗎?

此次B站服務端開發(fā)面試之旅可謂驚險,不過通過對大部分面試題套路的掌握,不出意外還是拿下了,下面我們來看看這些騷題是不是常見的不能再常見的了。這些面試題看了就能面上?當然不是,只是通過這些題讓自己知道所欠缺的是什么,以及可以去看看哪些資料。
1 操作系統(tǒng)相關
自旋鎖和一般鎖的區(qū)別是什么?為什么要使用自旋鎖?
當一個線程在獲取鎖的時候,如果這個鎖已經被其他線程獲取,那么這個線程不會破門而入,而是循環(huán)等待,但是嗷嗷待哺,需要不斷地嗷嗷叫判斷鎖是否被成功獲取,直到獲取到鎖才會退出循環(huán)。
自旋鎖通常會出現(xiàn)哪些問題?
如果某個線程拿著鎖死不放手,其他線程沒法拿到這把鎖,只好等待獲取鎖的線程進入循環(huán)等待的狀態(tài),等待不是睡覺,還是會消耗CPU,等待久了就會導致CPU的使用率太高。
那么自旋鎖和其他鎖到底有啥不同?
從線程狀態(tài)來看,自旋鎖的狀態(tài)是運行-運行-運行。而非自旋鎖的狀態(tài)是運行---阻塞---運行,所以自旋鎖會更高效。
不管是什么鎖,都是為了實現(xiàn)保護共享資源而提出的一種鎖機制,都是為了對某項資源的互斥使用。對于互斥鎖而言,如果資源已經被占用,那么資源的申請者只會進入睡眠的狀態(tài)。而自旋鎖不會引起調用者睡眠,而是一直循環(huán)在那里查看該自旋鎖的保持著是否已經釋放了鎖。
那么在Java中如何去實現(xiàn)一個自旋鎖
publicclassSpinLock{ privateAtomicReference
上段代碼中,方法lock利用的CAS,當線程A獲取鎖的時候,成功獲取不會進入while循環(huán)。如果此時線程A沒有釋放鎖,當線程B來獲取鎖的時候,由于不滿足CAS,就會進入whilei循環(huán),不斷判斷是否滿足CAS,直到線程A調用unlock釋放。
自旋鎖有哪些優(yōu)點?
因為運行在用戶態(tài),沒有上下文的線程狀態(tài)切換,線程一直處于active,減少了不必要的上下文切換,從而執(zhí)行速度較快
因為非自旋鎖在沒有獲取鎖的情況下會進入阻塞狀態(tài),從而進入內核態(tài),此時就需要線程的上下文切換,因為阻塞后進入內核調度狀態(tài),會導致用戶態(tài)和內核態(tài)之間的切換,影響鎖的性能。
了解哪些I/O模型?select是阻塞IO嗎?
首先將IO模型給安排一遍,然后把自己很熟悉的IO模型詳細說一波并介紹出應用場景,這個裝的X就算比較完美,具體的非常詳細的在下一篇文章,這里簡要說一波。這一部分在上一篇詳細闡述過
阻塞IO
我們知道在調用某個函數(shù)的時候無非就是兩種情況,要么馬上返回,然后根據(jù)返回值進行接下來的業(yè)務處理。當在使用阻塞IO的時候,應用程序會被無情的掛起,等待內核完成操作,因為此時的內核可能將CPU時間切換到了其他需要的進程中,在我們的應用程序看來感覺被卡主(阻塞)了。
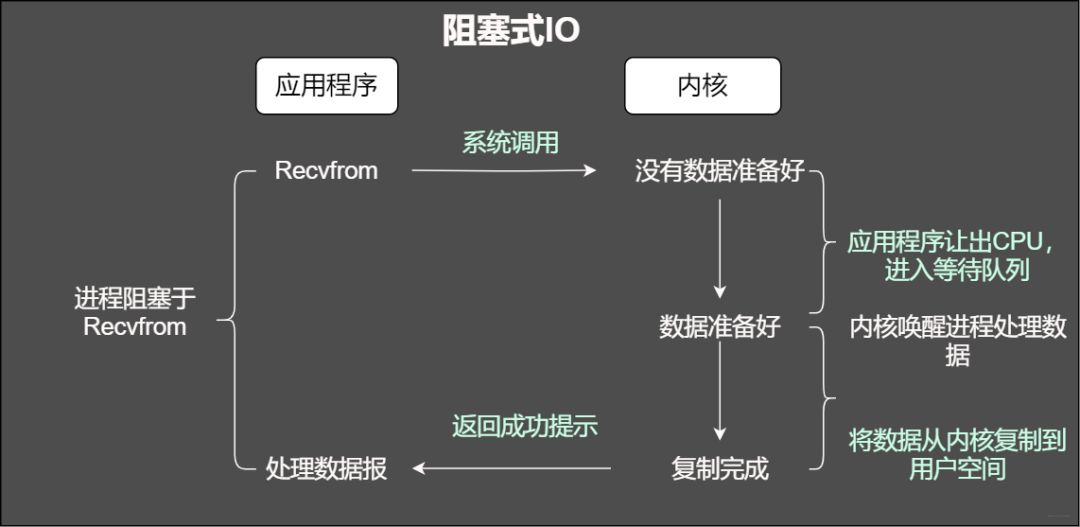
阻塞IO
非阻塞IO
當使用非阻塞函數(shù)的時候,和阻塞IO類比,內核會立即返回,返回后獲得足夠的CPU時間繼續(xù)做其他的事情。
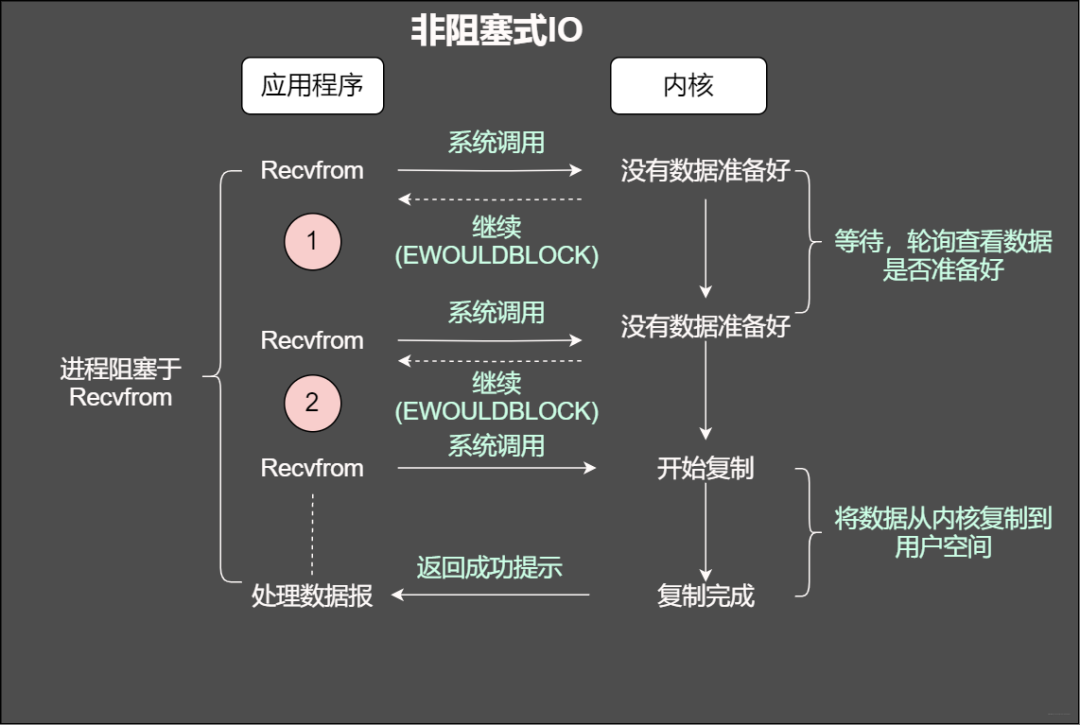
非阻塞
IO復用模型
當使用fgets等待標準輸入的時候,如果此時套接字有數(shù)據(jù)但不能讀出。IO多路復用意味著可以將標準輸入、套接字等都當做IO的一路,任何一路IO有事件發(fā)生,都將通知相應的應用程序去處理相應的IO事件,在我們看來就反復同時可以處理多個事情。這就是IO復用。
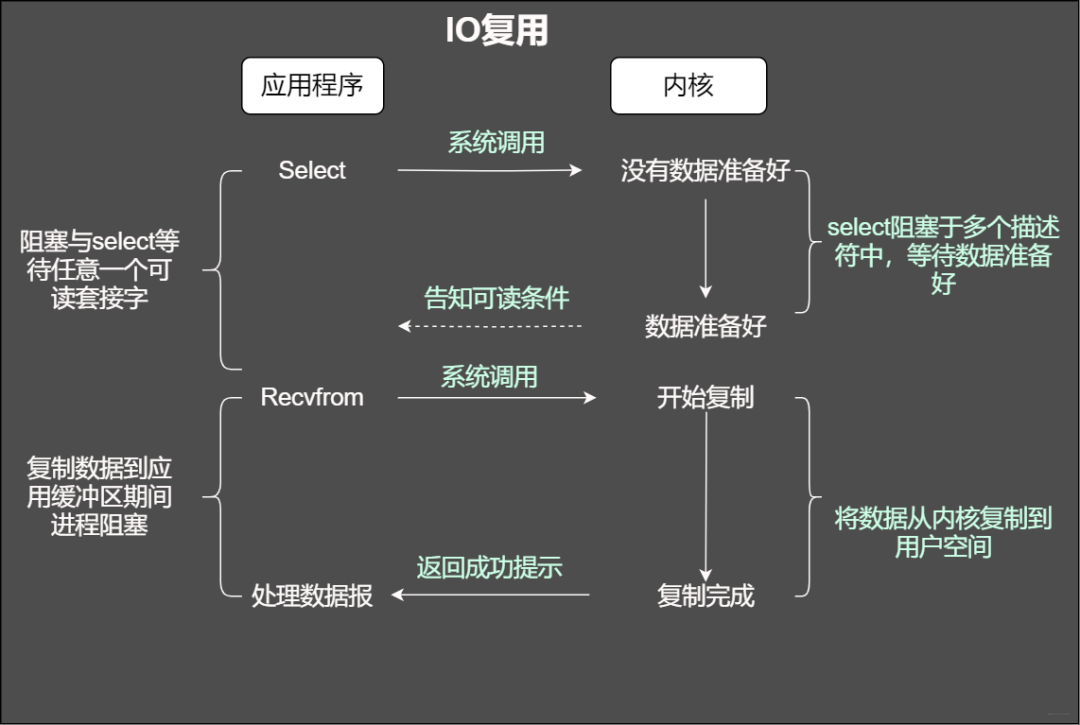
IO復用
信號驅動IO
在信號驅動式 I/O 模型中,應用程序使用套接口進行信號驅動 I/O,并安裝一個信號處理函數(shù),進程繼續(xù)運行并不阻塞。當數(shù)據(jù)準備好時,進程會收到一個 SIGIO 信號,可以在信號處理函數(shù)中調用 I/O 操作函數(shù)處理數(shù)據(jù)。
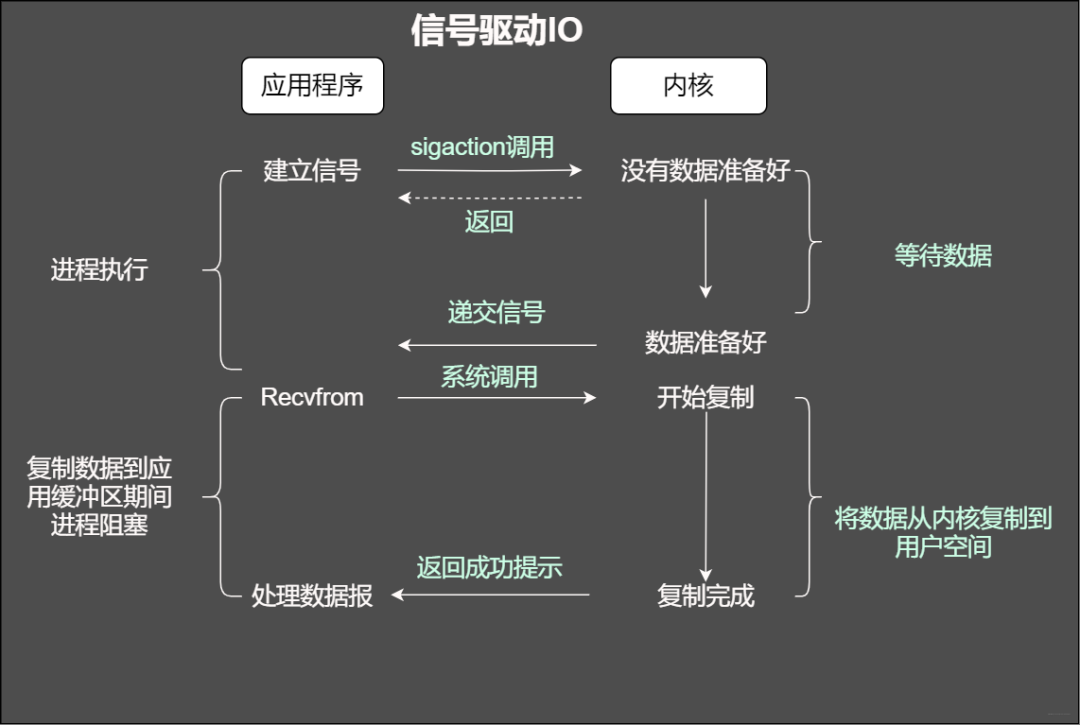
信號驅動
異步IO
用程序告知內核啟動某個操作,并讓內核在整個操作(包括將數(shù)據(jù)從內核拷貝到應用程序的緩沖區(qū))完成后通知應用程序。那么和信號驅動有啥不一樣?
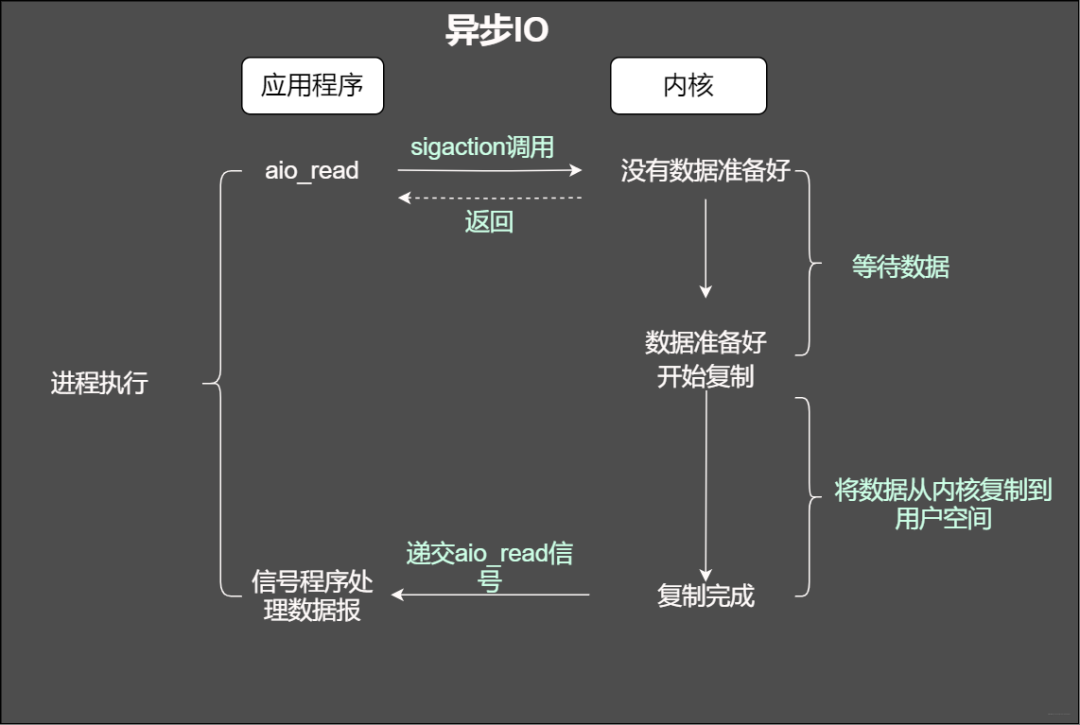
異步IO
講講select和epoll的區(qū)別?
這里一樣的套路,先說出兩者的用途,然后兩者的優(yōu)缺點。
select的缺點
select返回的是含有整個句柄的數(shù)組,應用程序需要遍歷整個數(shù)組才能發(fā)現(xiàn)哪些句柄發(fā)生了事件
select的觸發(fā)方式是水平觸發(fā),應用程序如果沒有完成對一個已經就緒的文件描述符進行IO操作,那么之后每次select調用還是會將這些文件描述符通知進程
內核 / 用戶空間內存拷貝問題,select每次都會改變內核中的句柄數(shù)據(jù)結構集,因而每次select調用時都需要從用戶空間向內核空間復制所有的句柄數(shù)據(jù)結構,產生巨大的開銷
單個進程能夠監(jiān)視的文件描述符的數(shù)量存在最大限制,通常是1024,當然可以更改數(shù)量
epoll實現(xiàn)
epoll在內核中會維護一個紅黑樹和一個雙向鏈表,紅黑樹存放通過epoll_ctl方法向epoll對象中添加進來的事件,所以不需要每次調用epoll_wait都全量復制所有的事件結構。雙向鏈表存放就緒的事件,所有添加到epoll中的事件都會與設備(網卡)驅動程序建立回調關系,也就是說,當相應的事件發(fā)生時會調用這個回調方法,這個回調方法在內核中叫ep_poll_callback,它會將發(fā)生的事件添加到rdlist雙鏈表中。調用epoll_wait就會直接返回鏈表中的就緒事件,效率高。
select適合少量活躍連接,一般幾千。
epoll適合大量不太活躍的連接。
樂觀鎖和悲觀鎖了解嗎?
這個問題延伸的問題會很多,比如線程安全,CAS原理,優(yōu)缺點等。
啥是悲觀和樂觀,咋們面試的時候不得樂觀一些。想給面試來一波官方解釋,然后大白話解釋一波就差不多了。
官方:悲觀鎖是總是假設最壞的情況,每次那數(shù)據(jù)都認為別人會修改它,所以每次去那數(shù)據(jù)都要上鎖,這樣別人去拿這個數(shù)據(jù)就會阻塞。樂觀鎖就不一樣了,總是覺得一切都是最好的安排,每次拿數(shù)據(jù)都認為別人不會修改,所以也就不上鎖,但是在更新的時候會判斷這個期間別人有沒有更新這個數(shù)據(jù)。
什么是緩存穿透?如何避免?什么是緩存雪崩?何如避免?
緩存穿透
一般來說,緩存系統(tǒng)會通過key去緩存查詢,如果不存在對應的value,就應該去后端系統(tǒng)查找(比如DB)。這個時候如果一些惡意的請求到來,就會故意查詢不存在的key,當某一時刻的請求量很大,就會對后端系統(tǒng)造成很大的壓力。這就叫做緩存穿透。
如何避免?
對查詢結果為空的情況也進行緩存,緩存時間設置短一點,或者該key對應的數(shù)據(jù)insert了之后清理緩存。對一定不存在的key進行過濾。可以把所有的可能存在的key放到一個大的Bitmap中,查詢時通過該bitmap過濾。
緩存雪崩
當緩存服務器重啟或者大量緩存集中在某一個時間段失效,這樣在失效的時候,會給后端系統(tǒng)帶來很大壓力。導致系統(tǒng)崩潰。
如何避免?
在緩存失效后,通過加鎖或者隊列來控制讀數(shù)據(jù)庫寫緩存的線程數(shù)量。比如對某個key只允許一個線程查詢數(shù)據(jù)和寫緩存,其他線程等待。
做二級緩存,A1為原始緩存,A2為拷貝緩存,A1失效時,可以訪問A2,A1緩存失效時間設置為短期,A2設置為長期。
不同的key,設置不同的過期時間,讓緩存失效的時間點盡量均勻。
2 redis相關
如果是后端/服務端面試的同學,怎么說都的去找一本redis書來看看,其出現(xiàn)的概率只有那么大了,切記切記。看看B站問了哪幾個問題。
redis的淘汰刪除策略了解嗎?
能說不了解嗎,就算是沒有聽說過,咋們也可以來一句:“不好意思面試官,這一塊還不怎么深入,但是從字面意思來理解巴拉巴拉”,不至于一臉懵逼。下面我們看看redis的緩存策略
Redis中通過maxmemory參數(shù)來設定內存的使用上限,如果Redis所使用內存超過設定的最大值,那么會根據(jù)配置文件中的策略選取要刪除的key來刪除,從而留出新的鍵值空間。主要的六種淘汰key策略
volatile-lru
在鍵空間中設置過期時間,移除哪些最近最少使用的key,占著茅坑不拉屎的key
allkeys-lru
移除最近最少使用的key
volatile-random
在鍵空間中設置過期時間,隨機移除一個key
allkeys-random
隨機移除一個key
noeviction
當內存使用達到閥值的時候,所有引起申請內存的命令會報錯;
ok,現(xiàn)在知道了需要淘汰哪些key,那我們如何去淘汰這些key
定時刪除
很簡單,設置一個鬧鐘,鬧鐘響了就刪除即可。這種方式對于內存來說還是比較友好,內存不需要啥額外的操作,直接通過定時器就可保證盡快的刪除。對于CPU來說就有點麻煩了,如果過期鍵比較多,那么定時器也就多,這刪除操作就會占用太多的CPU資源
惰性刪除
每次從鍵空間獲取鍵的時候檢查鍵的過期時間,如果過期了,刪除完事。
定期刪除
每隔一段時間就去數(shù)據(jù)庫檢查,刪除過期的鍵
這種方案是定時刪除和惰性刪除的中和方法,既通過限制刪除操作執(zhí)行的時長來減少對CPU時間的影響,也能減少內存的浪費。但是難點在于間隔時長需要根據(jù)業(yè)務情況而定。
3 mysql
mysql中使用的鎖有哪些?什么時候使用行鎖,什么時候會使用表鎖?
InnoDB中的行鎖是通過索引上的索引項實現(xiàn),主要特點是,只有通過索引條件檢索數(shù)據(jù),InnoDB才會使用行級鎖,否則InnoDB將使用表鎖。
這里注意,在Mysql中,行級鎖不是鎖記錄而是鎖索引。索引又分為主鍵索引和非主鍵索引兩種。如果在一條語句中操作了非主鍵索引,Mysql會鎖定該非主鍵索引,再鎖定相關的主鍵索引。
了解過間隙鎖嗎?間隙鎖的加鎖范圍是怎么確定的?
了解B+樹嗎?B+樹什么時候會出現(xiàn)結點分裂?
這個回答在上一篇的B+樹已經詳細說了。這里簡述一下
將已滿結點進行分裂,將已滿節(jié)點后M/2節(jié)點生成一個新節(jié)點,將新節(jié)點的第一個元素指向父節(jié)點。
父節(jié)點出現(xiàn)已滿,將父節(jié)點繼續(xù)分裂。
一直分裂,如果根節(jié)點已滿,則需要分類根節(jié)點,此時樹的高度增加。
事務還沒執(zhí)行完數(shù)據(jù)庫掛了,重啟的時候會發(fā)生什么?
undo日志和redo日志分別是干嘛的?
redo log重做日志是InnDB存儲引擎層的,用來保證事務安全。在事務提交之前,每個修改操作都會記錄變更后的數(shù)據(jù),保存的是物理日志-數(shù)據(jù),防止發(fā)生故障的時間點,有臟頁未寫入磁盤,在重啟mysql的時候,根據(jù)redo log進行重做從而達到事務的持久性
undo log回滾日志保存了事務發(fā)生之前的數(shù)據(jù)的一個版本,可以用于回滾,同時也提供多版本并發(fā)控制下的讀。
簡單講講數(shù)據(jù)庫的MVCC的實現(xiàn)原理?
細說太多了,幾個大寫字母代表啥,這幾個大寫字母又是如何關聯(lián)起來完事。細問再深究
mysql的binlog日志什么時候會使用?
首先應該知道binlog是一個二進制文件,記錄所有增刪改操作,節(jié)點之間的復制都會依靠binlog來完成。從底層原理來說,binlog有三個模式
模式1--row模式
每一行的數(shù)據(jù)被修改就會記錄在日志中,然后在slave段對相同的數(shù)據(jù)進行修改。比如說"update xx where id in(1,2,3,4,5)",使用此模式就會記錄5條記錄
模式2--statement模式
修改數(shù)據(jù)的sql會記錄到master的binlog中。slave在復制的時候sql thread會解析成和原來maseter端執(zhí)行過的相同的sql在此執(zhí)行
模式3--mixed模式
mixed模式即混合模式,Mysql會根據(jù)執(zhí)行的每一條具體sql區(qū)分對待記錄的日志形式。那么binlog的主從同步流程到底是咋樣的
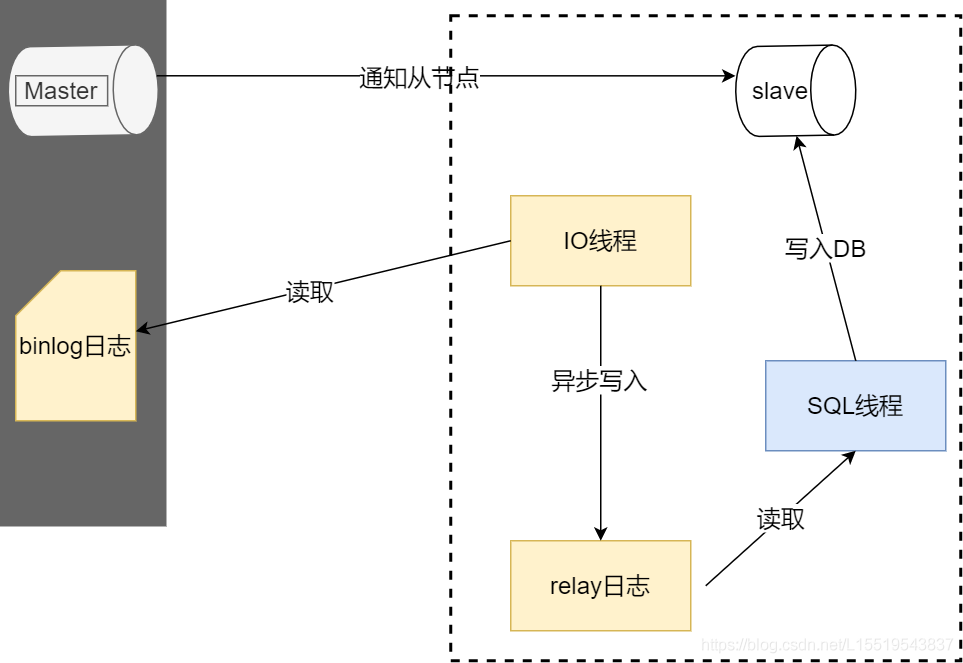
binlog同步
流程簡述:
Master執(zhí)行完增刪改操作后都會記錄binlog日志,當需要同步的時候會主動通知slave節(jié)點,slave收到通知后使用IO THREAD主動去master讀取binlog寫入relay日志(中轉日志),然后使 SQL THREAD完成對relay日志的解析然后入庫操作,完成同步。
4 基本數(shù)據(jù)結構
使用LRU時,如果短時間內會出現(xiàn)大量只會使用一次的數(shù)據(jù),可能導致之前大量高頻使用的緩存被刪除,請問有什么解決辦法?
了解過循環(huán)鏈表嗎?他的長度怎么計算?
他的主要特點是鏈表中的最后一個節(jié)點的指針域指向頭結點,整個鏈表形成一個環(huán)。*這里*循環(huán)鏈表判斷鏈表結束的標志是,判斷尾節(jié)點是不是指向頭結點
哪種數(shù)據(jù)結構可以支持快速插入,刪除,查找等操作?
思考這個問題的時候,我們不凡復習下不錯的二分查找,它依賴數(shù)組隨機訪問的特性,其查找時間復雜度為O(log n)。如果我們將元素放入鏈表中,二分查找還好使嗎?這就是今天和大家分享的跳表
理解跳表
假設使用單鏈表存儲n個元素,其中元素有序如下圖所示
 一級索引
一級索引
從鏈表中查找一個元素,自然從頭開始遍歷找到需要查找的元素,此時的時間復雜度為O(n)。那采用什么方法可以提高查詢的效率呢?問就是加索引,如何加,我們從這部分數(shù)據(jù)中抽取幾個元素出來作為單獨的一個鏈表,如下圖所示]
假設此時咋們查找元素16,首先一級索引處尋找,當找到元素14的時候,下一個節(jié)點的值為18,意味著我們尋找的數(shù)在這兩個數(shù)的中間。此時直接從14節(jié)點指針下移到下面的原始鏈表中,繼續(xù)遍歷,正好下一個元素就是我們尋找的16。好了,我們小結一下,如果從原始鏈表中尋找元素16,需要遍歷比較8次,如果通過索引鏈表尋找我們只需要5次即可。

在這里插入圖片描述
我們繼續(xù)查找元素16,此時比較次數(shù)變?yōu)?次。這樣看來,加一層索引查找的次數(shù)就變少,如果有n個元素到底有多少索引?
假設我們按照每兩個結點就抽出一個結點作為上一層的索引節(jié)點,第一層所以節(jié)點個數(shù)n/2,第二層為n/4,第x級索引的結點個數(shù)是第x-1級索引的結點個數(shù)的1/2,那第x級索引結點的個數(shù)就是n/(2^x)。假設索引有y級,我們可以得到n/(2^y)=2,從而求得y=log2n-1。
這么多索引是不是就很浪費內存嘞?
假設原始鏈表大小為n,那第一級索引大約有 n/2 個結點,第二級索引大約有 n/4 個結點,以此類推,每上升一級就減少一半,直到剩下 2 個結點。如果我們把每層索引的結點數(shù)寫出來,就是一個等比數(shù)列。這幾級索引的結點總和就是 n/2+n/4+n/8…+8+4+2=n-2 。所以,跳表的空間復雜度是 O(n) 。那還能不能降低一些呢。機智的你應該就考慮到假設每三個結點抽取一個節(jié)點作為索引鏈表的節(jié)點。
跳表與二叉查找樹
兩者其查找的時間復雜度均為O(logn) ,那跳表還有哪些優(yōu)勢?
先看二叉查找樹,
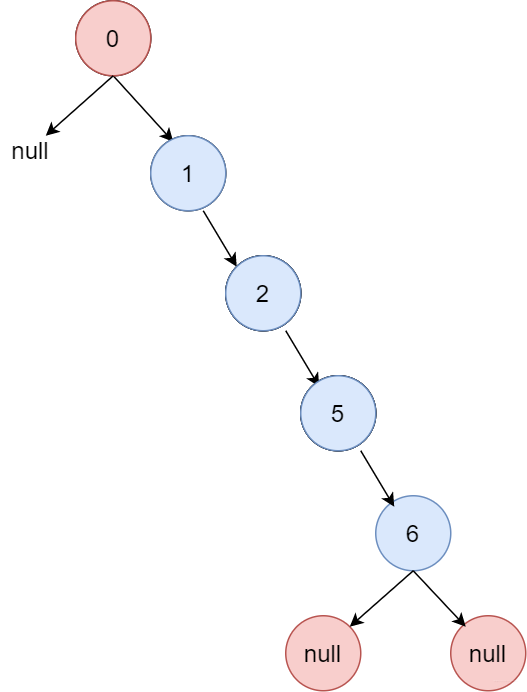
特殊二叉查找樹
這種結構會導致二叉查找樹的查找效率變?yōu)?O(n),。
跳表與紅黑樹
說實話,紅黑樹確實比較復雜,面試的時候讓你寫紅黑樹,你就給他大嘴巴子?
紅黑樹需要通過左右旋的方式去維持樹大小平衡。而跳表是通過隨機函數(shù)來維護前面提到的 “ 平衡性 ” 。當我們往跳表中插入數(shù)據(jù)的時候,我們可以選擇同時將這個數(shù)據(jù)插入到部分索引層中。如何選擇加入哪些索引層呢?
我們通過一個隨機函數(shù),來決定將這個結點插入到哪幾級索引中,比如隨機函數(shù)生成了值 K ,那我們就將這個結點添加到第一級到第 K 級這 K 級索引中。當我們往跳表中插入數(shù)據(jù)的時候,我們可以選擇同時將這個數(shù)據(jù)插入到部分索引層中。
小結
Redis中的有序集合采用了跳表的方式來實現(xiàn),其實還采用了散列表等數(shù)據(jù)結構進行融合。它在插入,刪除等都有比較快的速度,雖然紅黑樹也可以做到,但是紅黑樹對于按照區(qū)間查找數(shù)據(jù)這個操作,跳表可以做到 O(logn) 的時間復雜度定位區(qū)間的起點,然后在原始鏈表中順序往后遍歷就可以了
平時愛看技術博客嗎?分享一篇最近的技術博客?平時上B站嗎?
看的技術博客多了,這就是嘮嗑。比如說,看看小賤一天天BB的文章,哈哈哈哈哈
面試官:我擦,尼瑪說的這個我都關注了,難怪我問啥你都能說個一二三。
5 總結
請記下以下幾點:
公司招你去是干活了,不會因為你怎么怎么的而降低對你的要求標準。
工具上面寫代碼和手撕代碼完全不一樣。
珍惜每一次面試機會并學會復盤。
對于應屆生主要考察的還是計算機基礎知識的掌握,項目要求沒有那么高,是自己做的就使勁摳細節(jié),做測試,只有這樣,才知道會遇到什么問題,遇到什么難點,如何解決的。從而可以侃侃而談了。
非科班也不要怕,怕了你就輸了!一定要多嘗試。
責任編輯:lq
-
cpu
+關注
關注
68文章
11067瀏覽量
216679 -
應用程序
+關注
關注
38文章
3332瀏覽量
58938 -
select
+關注
關注
0文章
28瀏覽量
4087
原文標題:B 站面試之旅,一起來看看都問了什么?
文章出處:【微信號:TheAlgorithm,微信公眾號:算法與數(shù)據(jù)結構】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
新升級!功能更強大的串口I/O聯(lián)網模塊,ASK/OOK超外差無線射頻模塊

Google I/O 2025大會回顧
瀾起科技發(fā)布面向新一代CPU平臺的I/O集線器 (IOH) 芯片M88IO3020
納祥科技NX2069,國產I2C總線8位IO擴展器,遠程 I/O口擴展,替代PCF8574

I/O接口與I/O端口的區(qū)別
Linux--IO多路復用(select,poll,epoll)
socket編程中的阻塞與非阻塞

E系列I/O模塊在光伏制絨設備的應用

物聯(lián)網中常見的I/O擴展電路設計方案_IIC I/O擴展芯片





 工商網監(jiān)
工商網監(jiān)
評論