 如何去確定一個硬件加速器件?有哪些步驟?
如何去確定一個硬件加速器件?有哪些步驟?

在開發一個加速程序的之前,有一個很重要的步驟:正確設計程序架構。開發人員需要明確軟件應用程序中哪一部分是需要硬件加速的,并且它多少的并行量,以保證硬件加速器件(FPGA)能完美發揮其作用。
本文將分為5個步驟來介紹:
1. 基準和建立目標
2. 確定加速部分
3. 確定FPGA硬件加速并行量
4. 確定軟件部分并行量
5. 微調架構細節。
1.
基準和建立目標
首先要測試應用程序的運行時間和吞吐量,來確定當前應用程序在現有平臺的的基準性能。這些數據應涵蓋整個應用程序(起始到結束)的性能和各個主要函數的性能。通常使用valgrind,callgrind和GNU gprof這些測試軟件來獲得應用程序的性能數據,它們會顯示應用程序中所有的函數數量以及各個函數的執行時間。通過這些數據,我們可以找到耗時最長的部分,然后放到FPGA上進行加速。
評估運行時間
測試運行時間是軟件開發的基本流程,可以使用一些常用的測試軟件,或者插入計時器和性能計數器來完成此項操作。以gprof為例,可以得到類似如下圖結果。
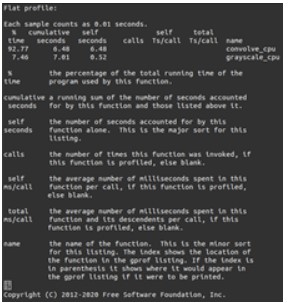
評估吞吐量
這里的吞吐量是指數據被處理的速率。對于計算給定函數的吞吐量,具體公式為函數處理的數據除以函數處理的時間,如下:
TSW= max (VINPUT, VOUTPUT) / Running Time
如果是處理固定的數據量,只要簡單的檢查代碼就能知道吞吐量的大小。但在一些情況下,數據是可變的,那么插入計數器來測量吞吐量的大小是比較實用的。
確定最大可實現的吞吐量
在大多數加速系統中,最大可實現吞吐量受PCIe總線的限制。PCIe總線受很多因素的影響,例如母板,驅動,目標板卡和發送數據大小等等。運行DMA測試能夠測試PCIe發送的有效吞吐量,從而確定加速性能潛力的上限。在安裝Alveo板卡后,我們可以使用xbutil dmatest命令來測試板卡的PCIe性能。
建立總體加速目標
在開發過程中盡早確定加速目標是非常有必要的,基于基準性能的加速目標會決定分析和決策的走向。加速目標可以是硬性的也可以是軟性的。例如,實時視頻應用程序有每秒處理60幀的嚴格硬性目標,而數據科學應用程序的軟性目標是比其他可代替實現方法快10倍。所以無論哪種方式,領域專業知識對于設置可實現的加速目標都很重要。
2.
確定加速部分
評估基準性能后,下一步就是確定哪一個函數需要在FPGA上加速。當選擇哪個函數用于加速時,有兩個方面需要考慮到:
性能瓶頸:應用程序中有哪些函數需要著重關注
加速潛力:這些函數是否有加速的潛力
確定性能瓶頸
在一個純粹的順序進行的應用程序中,可以通過解析報告很容易甄別到性能瓶頸。然而,大多數現實中的應用程序都是多進程,因此在尋找性能瓶頸的時候考慮并行性很重要。一個很簡單的例子:
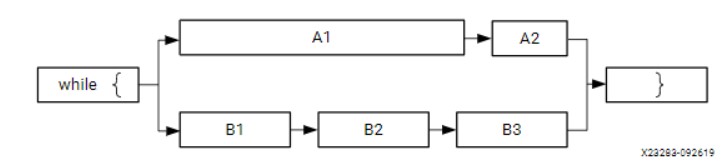
如上圖中是一個應用程序中兩條并行的路徑,長度表示它們運行消耗時間。從這里我們看出,僅僅加速A,B進程的某一個并不能提高應用程序的整體性能。即使你將A2加速100倍,該應用程序的性能還是被A1和B進程鉗制。所以考慮加速對象時,要考慮整個應用程序的性能,而不是單個函數的性能。
確定加速潛力
作為軟件程序中的瓶頸函數不一定具有加速的潛力,通常需要進行詳細分析才能準確判斷給定函數的實際加速潛力。但是,有時候一些簡單的指導方法也能確定一個函數是否有加速潛力:
1. 選擇運算復雜度比較大的,相比于順序計算來說,它可以在FPGA上可以使用并行,流水線來提高效率。
2. 相對于輸入輸出來說的,選擇運算強度比較大的,因為這樣數據搬移時間開銷占用整個加速時間比率來說會低一些。
3. 選擇那些能夠數據重用,對內存訪問比較少的,因為這可以是數據更容易在加速器中緩存,減少對全局內存的訪問。
4. 對比函數吞吐量和FPGA吞吐量的比值,以確定最大可加速的倍數。
3.
確定FPGA硬件加速并行量
在前面的步驟中確定哪個函數用于加速之后,接下來就要確定使用多少的并行量來達到這一目標。內核(kernel)的并行性可以分為大致兩種,一種是流水線形式,即是輸入和處理數據同時進行;另一種是同時處理多個任務,即是擁有多個輸入,多個任務并行處理。
評估硬件吞吐量(非并行)
沒有進行并行化的內核(kernel)吞吐量可以近似為:
THW = Frequency(頻率) / Computational Intensity(計算強度) = Frequency * max(VINPUT,VOUTPUT) / VOPS
頻率就是kernel的時鐘頻率。這個值是由特定的平臺決定,比如,Alveo U200的最大kernel時鐘是300Mhz。VINPUT,VOUTPUT是輸入輸出數據,VOPS是操作總數。由此可以看出,大量的操作數和少量的數據的函數更適合加速。
確定所需的并行量
經過上述計算后,可以估算出初始的HW/SW性能比:
Speed-up = THW/TSW = Fmax * Running Time /VOPS
沒有使用并行運算,則初始的加速(speed-up)通常會小于1。
接下來就要計算多少并行量可以滿足性能目標:
Parallelism Needed = TGoal / THW = TGoal * Vops / (Fmax * max(VINPUT, VOUTPUT))
并行方式可以通過多種方式實現:拓展數據路徑,使用多個計算引擎,使用多個kernel實例,開發人員應根據他們的需求和應用程序的特點確定最佳組合方式。
確定數據路徑應并行處理多少個樣本
一種可能性是通過創建更寬的數據路徑(數據的輸入和輸出的過程)然后并行處理更多數據以便加快計算速度。有些算法很適合這種方法,而有些則不適用。重要的是要了解這個算法的本質,確定這種方法是否可運用。如果可運用,那么并行處理多少數據才能滿足性能目標也是需要考慮的。
運用更寬的數據路徑、并行處理更多數據這些方法,本質是通過減少加速函數等待時間(運行時間)來實現提高性能的。
確定在FPGA中可以(應該)實例化多少個kernel
如果數據路徑無法并行化(或不夠充分),則請考慮添加更多kernel實例,這通常被稱為使用多個計算單元(CU)。添加更多的kernel實例的本質是允許加速函數更多的調用,從而提高應用程序的性能,如下所示。多個數據集由不同的實例并發處理。只要主機應用程序可以保持kernel繁忙,應用程序的性能就會隨著實例數的增加而線性增加。
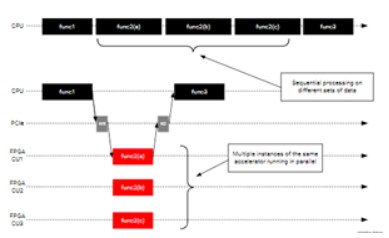
在Vitis中,很容易通過添加額外的kernel實例來提高加速性能,不需要過多的代碼調整。在這一點上,開發人員應該充分了解硬件中滿足性能目標所需的并行度,結合數據路徑寬度和kernel實例來達到預期的目標。
4.
確定軟件部分并行量
雖然FPGA及其kernel旨在提供潛在的并行性,但是必須對軟件應用程序進行設計以便利用這種潛在的并行性。
軟件應用程序中的并行性主要是以下幾方面:
?最大限度地減少空閑時間,并在kernel運行時執行其他任務。
?保持kernel處于活動狀態,以便盡早并經常執行新的計算。
?優化與FPGA之間的數據傳輸。
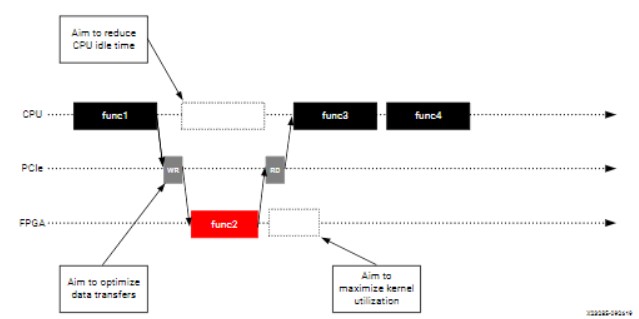
如上圖所示,host程序總是處于繁忙狀態并且計劃執行下一步的操作,而kernel端是處理當前的任務。所以,host程序必須統籌與kernel的數據傳輸,并且向kernel端發送請求,不然再多的kernel也是沒有效果的。
在kernel運行時最大程度地減少CPU空閑時間
FPGA加速是將某些計算從主機處理器轉移到FPGA的kernel中,在純順序模型中,應用程序將閑置地等待結果,準備并回復處理。設計軟件應用程序以避免此類空閑周期,首先是確定不依賴kernel結果的應用程序部分,然后重新設計,以便這些函數可以在主機處理器上與FPGA中運行的kernel同時運行處理。
保持kernel利用率
Kernel是在FPGA中的,僅在應用程序請求它們時才運行。為了最大程度地提高性能,應使kernel一致處于繁忙(工作)狀態。從概念上講,這是通過在當前請求完成之前發出下一個請求來實現的。這可以實現流水線式執行和重復執行,使kernel得到最佳利用。
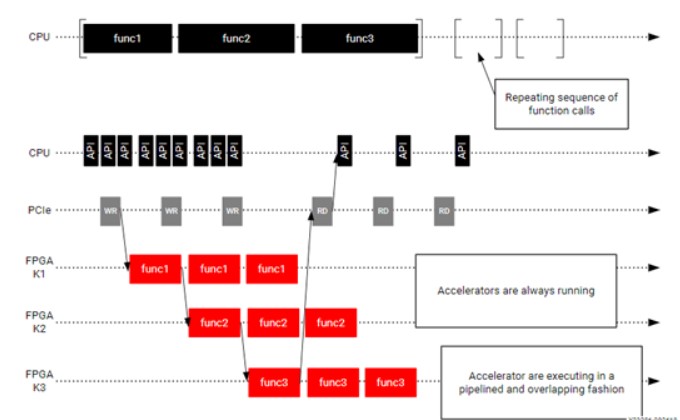
在上圖這個例子中,原始的應用程序重復的調用 func1,func2和func3。針對這個應用程序對應創建了三個kernel是K1,K2和K3。最平庸的實現是將三個kernel按順序運行,就像原始的應用程序一樣。但是,這意味著每個kernel只有三分之一的時間處于工作狀態。更好的方法是重構軟件應用程序,以便它可以向kernel發出流水線請求。這允許K1在K2處理K1的輸出的同時開始處理新的數據集。通過這個方法,三個kernel以最大化的利用率不斷運行。
優化與FPGA之間的數據傳輸
在加速的應用程序中,必須將數據從主機傳輸到FPGA,尤其是基于PCIe的應用程序中。這就引入了延遲,對于應用程序的整體性能而言,可能是非常昂貴的。數據需要在正確的時間被傳輸,如果kernel的運行需要等待數據,那么應用程序的性能會收到負面影響。因此,重要的是在kernel需要數據時提前傳輸數據。這可以通過重復數據傳輸、kernel執行來實現,這可以隱藏數據傳輸的等待時間開銷,并避免kernel等待數據的情況。
優化數據傳輸的另一種方法是傳輸最佳大小的緩沖區。如下圖所示,有效的PCIe吞吐量根據傳輸的緩沖區大小而有很大的差異。緩沖區越大,吞吐量越好,從而確保加速器始終具有可操作的數據而不會浪費時間。通常來說,最好進行1MB或更大的數據傳輸。預先運行DMA測試對于找到最佳緩沖區大小可能很有用。同樣,在確定最佳緩沖區大小時,請考慮大緩沖區對資源利用率和傳輸延遲的影響。
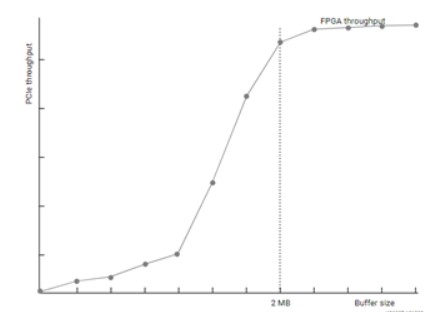
Xilinx建議在一個公共緩沖區內對多組數據進行分組,以實現最大可能的吞吐量。
概念化應用程序時間線
開發人員現在應該對哪些函數需要加速,需要什么并行性才能達到性能目標以及如何交付應用程序有很好的了解。在這一點上,以應用程序時間表的形式總結信息是非常有用的。應用程序時間軸序列(例如“保持Kernels使用率”中所示的序列)是應用程序在運行時表現性能和并行化非常有效的方法。它們可以展示應用程序如何調動體系結構中潛在的并行性。
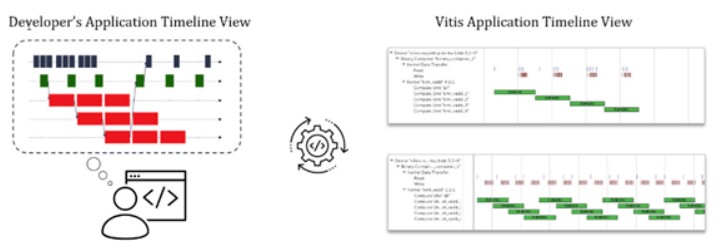
Vitis軟件平臺會從實際應用程序運行中生成時間軸視圖。如果開發人員設計了預期的時間表,則可以將其與實際結果進行比較,從而確定潛在的問題,然后迭代并收斂到最佳結果,如上圖所示。
5.
微調架構細節
在正式編寫應用程序及其kernel之前,還有最后一步:從頂層決策中細化和提煉次級體系架構的細節。
確定最終kernel邊界
之前已經有過討論,通過創建多個kernel的示例可以提高性能。然而,增加CU(compute unit)會對IO端口,帶寬和資源有額外地消耗。
在Vitis軟件平臺流程中,kernel端口的最大寬度為512,并且FPGA在資源方面也具有固定的成本,并不是無限消耗。重要的是,目標平臺也對可使用的最大端口設置了限制。所以我們要注意這些限制,以最佳方式充分使用這些端口及其帶寬。
使用多個CU進行擴展的另一種方法是通過在內核中添加多個引擎(engine)進行擴展。與添加更多CU的方式來提高性能一樣,此方法就是用在內核中的不同engine同時處理多個數據集。
將多個engine放置在同一kernel中可充分利用kernel I / O端口的帶寬。如果數據路徑engine不需要端口的全部寬度,則在kernel中添加其他engine比在其中創建具有單個engine的多個CU效率更高。
在kernel中放置多個engine還可以減少端口數量和事務數量到需要仲裁的全局內存中,從而提高了有效帶寬。另一方面,采用這種方法需要在開發kernel時考慮I / O多路復用行為,盡可能地減少全局內存的訪問。這是開發人員需要做出的權衡。
確定kernel的位置和連接性
確定kernel邊界后,開發人員要明確實例kernel的數量和連接到全局內存資源的端口數量。在這一點上,了解目標平臺的功能以及哪些全局內存資源可用很重要。例如,AlveoU200數據中心加速卡具有分布在三個超級邏輯區域(SLR)中的4 x 16 GB DDR4存儲區和3 x 128 KB的PLRAM存儲區。有關更多信息,請參閱《 Vitis Software Platform Release Notes》。
如果kernel是工廠,則全局內存是貨物往返工廠的倉庫。SLR就像獨特的工業區,可以在其中建立倉庫和工廠。雖然可以將貨物從一個區域的倉庫轉移到另一個區域的工廠,但這會增加延遲和復雜性。
使用多個DDR有助于平衡數據傳輸負載并提高性能。但是,這也會帶來成本,因為每個DDR控制器都會消耗FPGA資源。在決定如何將kernel端口連接到內存庫時,請均衡這些考慮因素。
在完善了這些架構細節之后,開發人員就應該已經掌握kernel以及整個應用程序所需的所有信息了。
責任編輯:lq6
-
處理器
+關注
關注
68文章
19868瀏覽量
234522 -
FPGA
+關注
關注
1645文章
22021瀏覽量
617247 -
主機
+關注
關注
0文章
1036瀏覽量
35935
原文標題:開發者分享 | 如何確定一個硬件加速應用
文章出處:【微信號:gh_2d1c7e2d540e,微信公眾號:XILINX開發者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
大模型推理顯存和計算量估計方法研究
粒子加速器?——?科技前沿的核心裝置

小型加速器中子源監測系統解決方案

消息稱AMD Instinct MI400 AI加速器將配備8個計算芯片
數據中心中的FPGA硬件加速器

基于Xilinx XCKU115的半高PCIe x8 硬件加速卡

適用于數據中心應用中的硬件加速器的直流/直流轉換器解決方案

圖形圖像硬件加速器卡設計原理圖:270-VC709E 基于FMC接口的Virtex7 XC7VX690T PCIeX8 接口卡





 工商網監
工商網監
評論