") 機器學習的建模流程是怎樣的?
機器學習的建模流程是怎樣的?

前言
機器學習作為人工智能領域的核心組成,是計算機程序學習數(shù)據(jù)經驗以優(yōu)化自身算法,并產生相應的“智能化的”建議與決策的過程。
一個經典的機器學習的定義是:
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
一、機器學習概論
機器學習是關于計算機基于數(shù)據(jù)分布構建出概率統(tǒng)計模型,并運用模型對數(shù)據(jù)進行分析與預測的方法。按照學習數(shù)據(jù)分布的方式的不同,主要可以分為監(jiān)督學習和非監(jiān)督學習:
1.1 監(jiān)督學習
從有標注的數(shù)據(jù)(x為變量特征空間, y為標簽)中,通過選擇的模型及確定的學習策略,再用合適算法計算后學習到最優(yōu)模型,并用模型預測的過程。模型預測結果Y的取值有限的或者無限的,可分為分類模型或者回歸模型;
1.2 非監(jiān)督學習:
從無標注的數(shù)據(jù)(x為變量特征空間),通過選擇的模型及確定的學習策略,再用合適算法計算后學習到最優(yōu)模型,并用模型發(fā)現(xiàn)數(shù)據(jù)的統(tǒng)計規(guī)律或者內在結構。按照應用場景,可以分為聚類,降維和關聯(lián)分析等模型;
二、機器學習建模流程
2.1 明確業(yè)務問題
明確業(yè)務問題是機器學習的先決條件,這里需要抽象出現(xiàn)實業(yè)務問題的解決方案:需要學習什么樣的數(shù)據(jù)作為輸入,目標是得到什么樣的模型做決策作為輸出。
(如一個簡單的新聞分類場景就是學習已有的新聞及其類別標簽數(shù)據(jù),得到一個分類模型,通過模型對每天新的新聞做類別預測,以歸類到每個新聞頻道。)
2.2 數(shù)據(jù)選擇:收集及輸入數(shù)據(jù)
數(shù)據(jù)決定了機器學習結果的上限,而算法只是盡可能逼近這個上限。意味著數(shù)據(jù)的質量決定了模型的最終效果,在實際的工業(yè)應用中,算法通常占了很小的一部分,大部分工程師的工作都是在找數(shù)據(jù)、提煉數(shù)據(jù)、分析數(shù)據(jù)。數(shù)據(jù)選擇需要關注的是:
① 數(shù)據(jù)的代表性:無代表性的數(shù)據(jù)可能會導致模型的過擬合,對訓練數(shù)據(jù)之外的新數(shù)據(jù)無識別能力;
② 數(shù)據(jù)時間范圍:監(jiān)督學習的特征變量X及標簽Y如與時間先后有關,則需要明確數(shù)據(jù)時間窗口,否則可能會導致數(shù)據(jù)泄漏,即存在和利用因果顛倒的特征變量的現(xiàn)象。(如預測明天會不會下雨,但是訓練數(shù)據(jù)引入明天溫濕度情況);
③ 數(shù)據(jù)業(yè)務范圍:明確與任務相關的數(shù)據(jù)表范圍,避免缺失代表性數(shù)據(jù)或引入大量無關數(shù)據(jù)作為噪音;
2.3 特征工程:數(shù)據(jù)預處理及特征提取
特征工程就是將原始數(shù)據(jù)加工轉化為模型有用的特征,技術手段一般可分為:
數(shù)據(jù)預處理:特征表示,缺失值/異常值處理,數(shù)據(jù)離散化,數(shù)據(jù)標準化等;特征提取:特征衍生,特征選擇,特征降維等;
特征表示
數(shù)據(jù)需要轉換為計算機能夠處理的數(shù)值形式。如果數(shù)據(jù)是圖片數(shù)據(jù)需要轉換為RGB三維矩陣的表示。
字符類的數(shù)據(jù)可以用多維數(shù)組表示,有Onehot獨熱編碼表示、word2vetor分布式表示及bert動態(tài)編碼等;
異常值處理
收集的數(shù)據(jù)由于人為或者自然因素可能引入了異常值(噪音),這會對模型學習進行干擾。
通常需要對人為引起的異常值進行處理,通過業(yè)務判斷和技術手段(python、正則式匹配、pandas數(shù)據(jù)處理及matplotlib可視化等數(shù)據(jù)分析處理技術)篩選異常的信息,并結合業(yè)務情況刪除或者替換數(shù)值。
缺失值處理
數(shù)據(jù)缺失的部分,通過結合業(yè)務進行填充數(shù)值、不做處理或者刪除。根據(jù)缺失率情況及處理方式分為以下情況:
① 缺失率較高,并結合業(yè)務可以直接刪除該特征變量。經驗上可以新增一個bool類型的變量特征記錄該字段的缺失情況,缺失記為1,非缺失記為0;
② 缺失率較低,結合業(yè)務可使用一些缺失值填充手段,如pandas的fillna方法、訓練隨機森林模型預測缺失值填充;
③ 不做處理:部分模型如隨機森林、xgboost、lightgbm能夠處理數(shù)據(jù)缺失的情況,不需要對缺失數(shù)據(jù)做任何的處理。
數(shù)據(jù)離散化
數(shù)據(jù)離散化能減小算法的時間和空間開銷(不同算法情況不一),并可以使特征更有業(yè)務解釋性。
離散化是將連續(xù)的數(shù)據(jù)進行分段,使其變?yōu)橐欢味坞x散化的區(qū)間,分段的原則有等距離、等頻率等方法。
數(shù)據(jù)標準化
數(shù)據(jù)各個特征變量的量綱差異很大,可以使用數(shù)據(jù)標準化消除不同分量量綱差異的影響,加速模型收斂的效率。常用的方法有:
① min-max 標準化:
將數(shù)值范圍縮放到(0,1),但沒有改變數(shù)據(jù)分布。max為樣本最大值,min為樣本最小值。
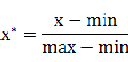
② z-score 標準化:
將數(shù)值范圍縮放到0附近, 經過處理的數(shù)據(jù)符合標準正態(tài)分布。u是平均值,σ是標準差。
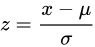
特征衍生
基礎特征對樣本信息的表述有限,可通過特征衍生出新含義的特征進行補充。特征衍生是對現(xiàn)有基礎特征的含義進行某種處理(組合/轉換之類),常用方法如:
① 結合業(yè)務的理解做衍生,比如通過12個月工資可以加工出:平均月工資,薪資變化值,是否發(fā)工資 等等;
② 使用特征衍生工具:如feature tools等技術;
特征選擇
特征選擇篩選出顯著特征、摒棄非顯著特征。特征選擇方法一般分為三類:
① 過濾法:按照特征的發(fā)散性或者相關性指標對各個特征進行評分后選擇,如方差驗證、相關系數(shù)、IV值、卡方檢驗及信息增益等方法。
② 包裝法:每次選擇部分特征迭代訓練模型,根據(jù)模型預測效果評分選擇特征的去留。
③ 嵌入法:使用某些模型進行訓練,得到各個特征的權值系數(shù),根據(jù)權值系數(shù)從大到小來選擇特征,如XGBOOST特征重要性選擇特征。
特征降維
如果特征選擇后的特征數(shù)目仍太多,這種情形下經常會有數(shù)據(jù)樣本稀疏、距離計算困難的問題(稱為 “維數(shù)災難”),可以通過特征降維解決。常用的降維方法有:主成分分析法(PCA), 線性判別分析法(LDA)等。
2.4 模型訓練
模型訓練是選擇模型學習數(shù)據(jù)分布的過程。這過程還需要依據(jù)訓練結果調整算法的(超)參數(shù),使得結果變得更加優(yōu)良。
2.4.1數(shù)據(jù)集劃分
訓練模型前,一般會把數(shù)據(jù)集分為訓練集和測試集,并可再對訓練集再細分為訓練集和驗證集,從而對模型的泛化能力進行評估。
① 訓練集(training set):用于運行學習算法。
② 開發(fā)驗證集(development set)用于調整參數(shù),選擇特征以及對算法其它優(yōu)化。常用的驗證方式有交叉驗證Cross-validation,留一法等;
③ 測試集(test set)用于評估算法的性能,但不會據(jù)此改變學習算法或參數(shù)。
2.4.2模型選擇
常見的機器學習算法如下:
模型選擇取決于數(shù)據(jù)情況和預測目標。可以訓練多個模型,根據(jù)實際的效果選擇表現(xiàn)較好的模型或者模型融合。
模型選擇
2.4.3模型訓練
訓練過程可以通過調參進行優(yōu)化,調參的過程是一種基于數(shù)據(jù)集、模型和訓練過程細節(jié)的實證過程。超參數(shù)優(yōu)化需要基于對算法的原理的理解和經驗,此外還有自動調參技術:網格搜索、隨機搜索及貝葉斯優(yōu)化等。
2.5 模型評估
模型評估的標準:模型學習的目的使學到的模型對新數(shù)據(jù)能有很好的預測能力(泛化能力)。現(xiàn)實中通常由訓練誤差及測試誤差評估模型的訓練數(shù)據(jù)學習程度及泛化能力。
2.5.1評估指標
① 評估分類模型:常用的評估標準有查準率P、查全率R、兩者調和平均F1-score 等,并由混淆矩陣的統(tǒng)計相應的個數(shù)計算出數(shù)值:
混淆矩陣
查準率是指分類器分類正確的正樣本(TP)的個數(shù)占該分類器所有預測為正樣本個數(shù)(TP+FP)的比例;
查全率是指分類器分類正確的正樣本個數(shù)(TP)占所有的正樣本個數(shù)(TP+FN)的比例。
F1-score是查準率P、查全率R的調和平均: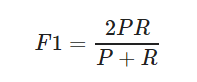
② 評估回歸模型:常用的評估指標有RMSE均方根誤差 等。反饋的是預測數(shù)值與實際值的擬合情況。
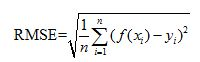
③ 評估聚類模型:可分為兩類方式,一類將聚類結果與某個“參考模型”的結果進行比較,稱為“外部指標”(external index):如蘭德指數(shù),F(xiàn)M指數(shù) 等;另一類是直接考察聚類結果而不利用任何參考模型,稱為“內部指標”(internal index):如緊湊度、分離度 等。
2.5.2模型評估及優(yōu)化
根據(jù)訓練集及測試集的指標表現(xiàn),分析原因并對模型進行優(yōu)化,常用的方法有:
2.6 模型決策
決策是機器學習最終目的,對模型預測信息加以分析解釋,并應用于實際的工作領域。
需要注意的是工程上是結果導向,模型在線上運行的效果直接決定模型的成敗,不僅僅包括其準確程度、誤差等情況,還包括其運行的速度(時間復雜度)、資源消耗程度(空間復雜度)、穩(wěn)定性的綜合考慮。
責任編輯:lq6
-
人工智能
+關注
關注
1806文章
48960瀏覽量
248575 -
機器學習
+關注
關注
66文章
8500瀏覽量
134442
原文標題:機器學習入門指南(全)
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
明晚開播 |數(shù)據(jù)智能系列講座第7期:面向高泛化能力的視覺感知系統(tǒng)空間建模與微調學習

邊緣計算中的機器學習:基于 Linux 系統(tǒng)的實時推理模型部署與工業(yè)集成!

直播預約 |數(shù)據(jù)智能系列講座第7期:面向高泛化能力的視覺感知系統(tǒng)空間建模與微調學習
VirtualLab Fusion應用:漸變折射率(GRIN)鏡頭的建模
機器學習模型市場前景如何
傳統(tǒng)機器學習方法和應用指導

如何選擇云原生機器學習平臺
構建云原生機器學習平臺流程
什么是機器學習?通過機器學習方法能解決哪些問題?






 工商網監(jiān)
工商網監(jiān)
評論