") 深入剖析多線程計(jì)算平臺(tái)的性能模型
深入剖析多線程計(jì)算平臺(tái)的性能模型

在以前的文章里,筆者談到單核CPU無論在PC端還是服務(wù)器上基本上已經(jīng)退出歷史舞臺(tái),目前主流的計(jì)算平臺(tái)是使用多核(multiple cores)的CPU以及眾核(many cores)的GPU。另外處理器與內(nèi)存訪問速度差距也不斷增大,為克服訪存瓶頸主要采用兩種方法。
其中多核CPU與單核CPU都是利用Cache來掩蓋訪問系統(tǒng)內(nèi)存的延遲,以減輕訪存帶寬的壓力,其芯片的較大面積也都貢獻(xiàn)給Cache。在另一端,GPU通過同時(shí)運(yùn)行很多簡(jiǎn)單的線程,不使用或者只利用相對(duì)較小的Cache。
而主要通過線程間的并行(Thread Level Parallelism, TLP)來隱藏內(nèi)存訪問延遲,當(dāng)一部分線程因?yàn)樵L存停滯的時(shí)候,另一部分線程會(huì)接著執(zhí)行,使得處理單元不會(huì)空閑下來。
目前的異構(gòu)計(jì)算平臺(tái)同時(shí)采用這兩種截然不同的架構(gòu),使得性能預(yù)測(cè)和優(yōu)化都不太容易,面對(duì)一個(gè)給定的計(jì)算負(fù)載,我們應(yīng)該如何分發(fā)能夠達(dá)到性能最佳?對(duì)芯片架構(gòu)師而言,在面積受限的芯片上,怎樣合理部署處理單元、Register File和Cache等等也是讓人撓頭的事情。
希望能夠?yàn)槔斫鈨?yōu)化性能提供參考,論文作者定義了一個(gè)統(tǒng)一仿真模型可以容納延展這兩種不同特點(diǎn)的架構(gòu)設(shè)計(jì)。這個(gè)模型對(duì)應(yīng)一個(gè)想象的混合計(jì)算平臺(tái),該平臺(tái)由很多簡(jiǎn)單的處理單元以及較大的共享緩存構(gòu)成,通過靈活配置一系列參數(shù),包括處理單元個(gè)數(shù)、緩存大小以及緩存和內(nèi)存的訪問延遲等等,可以觀察不同參數(shù)變化對(duì)計(jì)算性能的影響。
為保持模型簡(jiǎn)單,論文假設(shè)所有線程相互不共享數(shù)據(jù)且系統(tǒng)內(nèi)存帶寬足夠大。如下圖所示,作者發(fā)現(xiàn),當(dāng)線程數(shù)量較少的時(shí)候,隨著線程數(shù)量增加,性能開始提升,而當(dāng)線程數(shù)量到達(dá)轉(zhuǎn)折點(diǎn),Cache不能夠容納所有線程的工作集的時(shí)候,性能反而下降。
之后,隨著線程數(shù)量越來越多,由于有足夠的線程來掩蓋Cache訪問不命中帶來內(nèi)存訪問延遲,性能又接著上升,直達(dá)到平臺(tái)可獲得的最大性能。我們可以認(rèn)為MC Region對(duì)應(yīng)多核CPU的情形,而MT Region自然對(duì)應(yīng)有超多線程的GPU,MC Region和MT Region之間的性能波谷區(qū)域在我們的架構(gòu)設(shè)計(jì)和程序優(yōu)化中都是要努力避免的。
以下我們具體推導(dǎo)下參數(shù)曲線對(duì)應(yīng)的公式,下表列出計(jì)算模型涉及的參數(shù),左邊是平臺(tái)相關(guān)的,右邊跟運(yùn)算任務(wù)有關(guān)。
公式(1)為考慮Cache命中率的線程平均訪問內(nèi)存所需要的時(shí)鐘數(shù)。
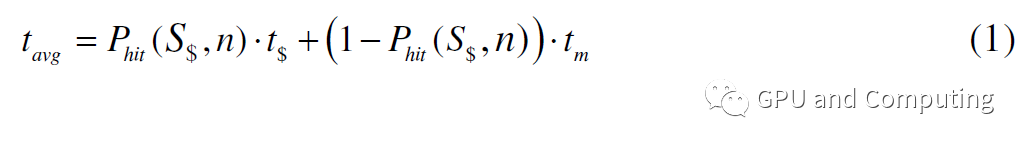
這就是說,線程每運(yùn)行1/rm條指令,就會(huì)因?yàn)樵L存停滯tavg時(shí)鐘,如果沒有別的線程替換進(jìn)來,對(duì)應(yīng)的處理單元就會(huì)處于空閑狀態(tài),要讓該處理單元充分利用,額外需要的線程數(shù)為tavg/(CPIexe/rm)。所以要讓整個(gè)計(jì)算平臺(tái)滿負(fù)荷運(yùn)轉(zhuǎn),總共需要的線程數(shù)量為
NPE * (1 +tavg/(CPIexe/rm))。給定有n個(gè)線程的計(jì)算任務(wù),計(jì)算平臺(tái)的利用率η可以計(jì)算如公式(2)。
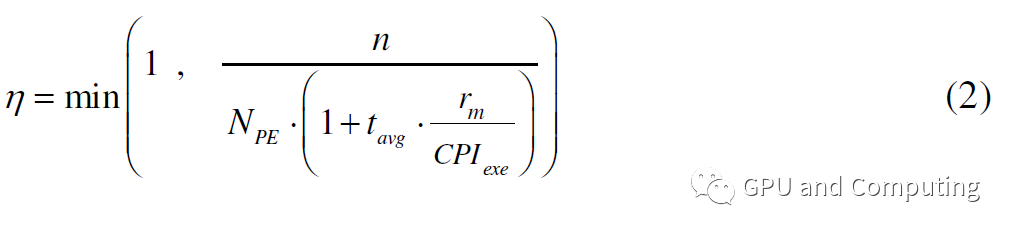
在η=1的情況下,再添加多余的線程于性能無補(bǔ)。根據(jù)利用率η我們可以得到計(jì)算平臺(tái)的預(yù)期性能為NPE * (f/CPIexe)*η OPS(Operations Per Second,每秒鐘運(yùn)算數(shù))。通過該公式,我們可以觀察以下各種參數(shù)調(diào)節(jié)對(duì)性能曲線的影響。
值得注意的是以上計(jì)算中我們沒有考慮內(nèi)存帶寬受限的情況,如果把它納入考慮,對(duì)特定性能Performance,我們可以按公式(3)計(jì)算所要求帶寬。
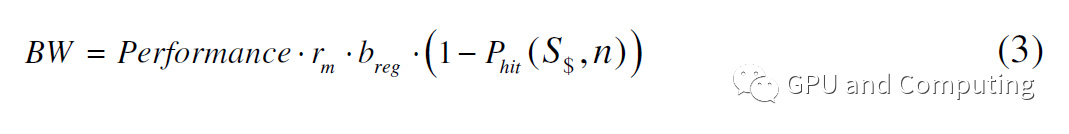
所以在內(nèi)存帶寬也是約束條件的情況下,性能計(jì)算修正為公式(4)。
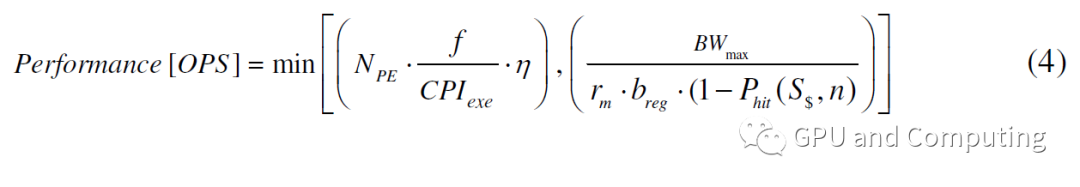
而下圖也反映了內(nèi)存帶寬對(duì)性能曲線的影響。值得提醒的是性能曲線水平頂表示計(jì)算任務(wù)在該平臺(tái)上已經(jīng)觸到了內(nèi)存帶寬墻(off-chip bandwidth wall),在這種情況下繼續(xù)增加線程有可能會(huì)惡化Cache命中率,使得帶寬問題更加嚴(yán)重反而有損性能,這也是為什么之前我們提到過的GPU顯存帶寬要遠(yuǎn)大于CPU系統(tǒng)內(nèi)存帶寬。
主要參考資料:
Many-core vs many-thread machines: Stay away from the valley
The Interplay of Caches and Threads in Chip-MultiProcessors
編輯:jq
-
cpu
+關(guān)注
關(guān)注
68文章
11069瀏覽量
216684 -
PC
+關(guān)注
關(guān)注
9文章
2146瀏覽量
156357 -
內(nèi)存
+關(guān)注
關(guān)注
8文章
3118瀏覽量
75164 -
TLP
+關(guān)注
關(guān)注
0文章
34瀏覽量
15989
原文標(biāo)題:多線程計(jì)算平臺(tái)的性能模型
文章出處:【微信號(hào):LinuxDev,微信公眾號(hào):Linux閱碼場(chǎng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
大模型推理顯存和計(jì)算量估計(jì)方法研究
多線程的安全注意事項(xiàng)
工控一體機(jī)多線程任務(wù)調(diào)度優(yōu)化:聚徽分享破解工業(yè)復(fù)雜流程高效協(xié)同密碼
請(qǐng)問如何在Python中實(shí)現(xiàn)多線程與多進(jìn)程的協(xié)作?
請(qǐng)問rt-thread studio如何進(jìn)行多線程編譯?
摩爾線程宣布成功部署DeepSeek蒸餾模型推理服務(wù)
華為云 X 實(shí)例 CPU 性能測(cè)試詳解與優(yōu)化策略

socket 多線程編程實(shí)現(xiàn)方法
AI高性能計(jì)算平臺(tái)是什么
Python中多線程和多進(jìn)程的區(qū)別
CPU線程和程序線程的區(qū)別
深入剖析石英 CMOS 振蕩器 PC3225 系列(1 to 200 MHz)的卓越性能






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論