 基于預訓練視覺-語言模型的跨模態Prompt-Tuning
基于預訓練視覺-語言模型的跨模態Prompt-Tuning

論文:CPT:Colorful Prompt Tuning for Pre-Training Vision-Language Models
狀態:Work in Progress
單位:清華大學、新加坡國立大學
鏈接:https://arxiv.org/pdf/2109.11797.pdf
提取摘要
預訓練的視覺語言模型 (VL-PTMs) 在將自然語言融入圖像數據中顯示出有前景的能力,促進了各種跨模態任務。
然而,作者注意到模型pre-training和finetune的客觀形式之間存在顯著差距,導致需要大量標記數據來刺激 VL-PTMs 對下游任務的視覺基礎能力。
為了應對這一挑戰,本文提出了跨模態提示調優Cross-modal Prompt Tuning(CPT,或者,彩色-Color提示調優),這是一種用于finetune VL-PTMs 的新范式,它在圖像和文本中使用基于顏色的共同參照標記重新構建了視覺定位問題,使之成為一個填空問題,最大限度地縮小差距。
通過這種方式,本文的Prompt-Tuning方法可以讓 VL-PTMs 在少樣本甚至零樣本的強大的視覺預測能力。
綜合實驗結果表明,Prompt-Tuning的 VL-PTMs 大大優于 finetune 的方法(例如,在 RefCOCO 評估中,一次平均提高 17.3% 準確度,one shot下平均相對標準偏差降低73.8%)。
數據和代碼會在之后公開,小伙伴們不要急~
方法介紹
背景:該任務為Visual Grounding視覺定位問題,通過一個給定的expression來定位在圖像中的位置。
Pre-training和fine-tuning
比如有一張識別好的圖片和下面的文字:

普通使用MLM(masked language modeling)的預訓練模型的到VL-PTMs方法為:

就是使用[mask]機制來預測被被掩蓋的token。
而finetune的話,就是使用傳統的[CLS]來遷就下游的任務,比如做二分類:
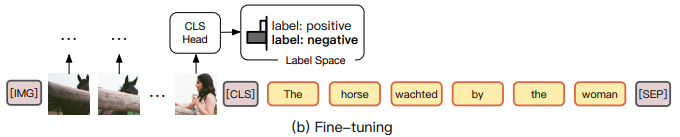
而使用被大規模數據預訓練的模型通過[CLS]來遷就下游任務,其實并不可解釋,而反過來讓下游帶著任務來到預訓練模型的[mask]戰場上,才能更能發揮其作用呀。
CPT: Cross-model Prompt Tuning
CPT方法首先將圖片用不同顏色來區分不同的實體模塊:

其次將Query Text插入到color-based的模板(eg. is in [mask] color)里:
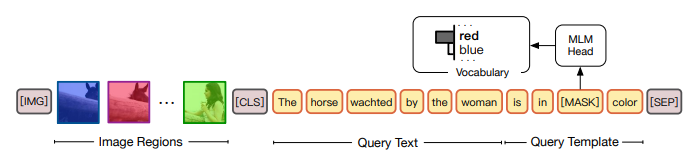
最后在[mask]上預測對應的該是哪個顏色即可,語義上非常行得通。
模型公式
普通Finetune for VL-PLMs
首先從圖片 I 中通過目標檢測工具,檢測出一系列的region:
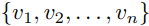
最終這些被選出來的region和Query Text(w)將被放入:
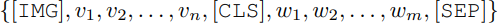
其中[IMG]、[CLS]和[SEP]為特殊token。
其中圖片regions的representation通過視覺的encoder獲得,而文本的就是lookup即可,最后通過預訓練模型VL-PLMs會得到:
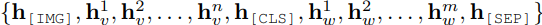
最終使用隱層finetune做分類即可。
但是,finetuned VL-PLMs需要大量的標注數據來提高視覺定位的效果,這個也是一個弊端吧。
Cross-Modal Prompt Tuning - CPT
上面說過了,CPT需要兩個部分:
視覺子prompt
文本子prompt
視覺子prompt,目的是為了區分每一個region通過可分辨的標記,比如顏色,比如RGB (255, 0, 0)表示red,RGB和text要對應起來。
這里要注意的是,這個子prompt是直接加在原圖片上的,所以既沒有改變模型結果,又沒有改變參數。
文本子prompt,目的就是在圖片和Query Text之間建立一個鏈接,這里使用的模板為:
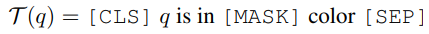
然后,VL-PTMs模型通過這樣的提示(prompt)來決定哪個顏色的region填在這個空里最恰當:
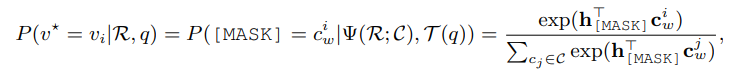
實驗
和finetune相比,CPT在zero-shot和few-shot下,性能可以說是爆表,巨額提升。在全量數據下,也能達到最佳值或者接近最佳值:
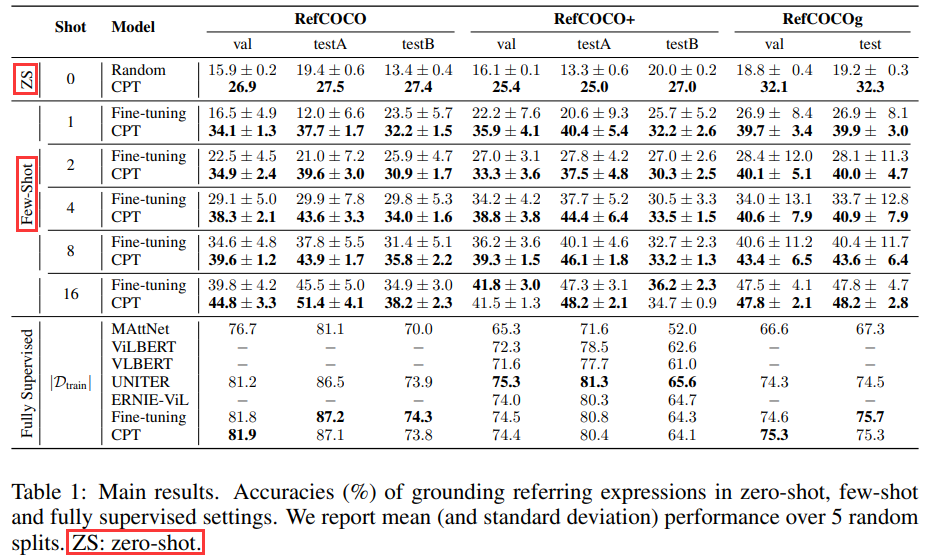
CPT在其他視覺任務上的應用
實體檢測

謂元分類

場景圖分類

總之,Prompt方法就是通過模板重新定義了任務,讓模型更具有解釋性,本篇文章第一次將Prompt用在了Vision-Language上,未來還會有很大的研究動向,感興趣的小伙伴可以細讀原文。
編輯:jq
-
數據
+關注
關注
8文章
7254瀏覽量
91777 -
RGB
+關注
關注
4文章
807瀏覽量
59882 -
CLS
+關注
關注
0文章
9瀏覽量
9793 -
prompt
+關注
關注
0文章
15瀏覽量
2768
原文標題:清華劉知遠提出CPT:基于預訓練視覺-語言模型的跨模態Prompt-Tuning
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
用PaddleNLP為GPT-2模型制作FineWeb二進制預訓練數據集

?VLM(視覺語言模型)?詳細解析

從Open Model Zoo下載的FastSeg大型公共預訓練模型,無法導入名稱是怎么回事?
小白學大模型:訓練大語言模型的深度指南

用PaddleNLP在4060單卡上實踐大模型預訓練技術


騰訊公布大語言模型訓練新專利
【「基于大模型的RAG應用開發與優化」閱讀體驗】+大模型微調技術解讀
《具身智能機器人系統》第7-9章閱讀心得之具身智能機器人與大模型
KerasHub統一、全面的預訓練模型庫
NaVILA:加州大學與英偉達聯合發布新型視覺語言模型
一文理解多模態大語言模型——下


直播預約 |數據智能系列講座第4期:預訓練的基礎模型下的持續學習






 工商網監
工商網監
評論