 美團落實 AI 框架在 GPU 上性能推理的優化實踐
美團落實 AI 框架在 GPU 上性能推理的優化實踐

美團是一家集生活服務及商品零售的電商平臺,公司聚焦“零售+科技”戰略,以“吃”為核心,通過科技創新,服務于生活服務業需求側和供給側數字化升級。美團在中國業務涵蓋餐飲、配送、網約車、共享單車、酒店及旅游預訂、電影票務等 200 多個服務品類,覆蓋全國 2800 個市區縣,服務 6.7 億活躍用戶和 830萬活躍商家。
伴隨著用戶規模的提升和業務的精細化運營,業務側對推薦系統的準確度、吞吐能力和時延都提出了新的挑戰,而 CTR 模型作為推薦系統的核心模型,其效果直接影響業務的收入。
美團的 CTR 模型過去一直在使用 CPU 推理的方式,但隨著用戶訪問量的提升和深度神經網絡的引入,CTR 模型結構趨于復雜,吞吐和計算量也越來越大,CPU 開始不能滿足模型對于算力的需求,而僅僅通過 CPU 服務器的堆疊帶來的性能提升性價比相較偏低。
而 GPU 擁有數以千計的計算核心,可以在單機內提供密集的并行計算能力,特別適合深度學習場景,在行業內已經在 CV 、NLP 等領域展示了強大的能力。通過 CUDA 及相關 API ,NVIDIA 建立了完整的 GPU 生態系統。基于此,美團基礎研發平臺將 CTR 模型部署到 GPU 上,并通過一系列針對 CPU 與 GPU 的異構系統并行計算設計、數據存儲方式和傳輸方式上的特定優化,希望能通過 GPU 強大的計算力,協助美團在 CTR 預測的各業務場景中發揮出最大優勢。
為了解決算力瓶頸及上述各種挑戰,美團機器學習平臺采用 NVIDIA AI 計算平臺,在繼 CV 、NLP 及 CTR 訓練后,也使用了 NVIDIA T4 來提供 CTR 預測支持,大幅提升用戶體驗與服務穩定性。除此之外,時延也是業務側非常重視的性能指標,許多復雜模型縱有更好的準確度,但卻因響應時間不達標而無法落地應用,例如,在某搜索框自動補全的場景,由于天然的交互屬性,時延要求非常苛刻,一般來說無法使用復雜的模型。而在 GPU 能力的加持下,其復雜模型的平均響應時間從 15 毫秒降低至 6~7 毫秒,足足縮短了一倍多,達到了上線要求。
通過 NVIDIA T4 深度優化方案,成功為美團 CTR 模型創造更多應用機會,不僅極大地提升了系統吞吐量,更進一步地提升了整個模型訓練的速度與降低訓練成本,落實 AI 框架在 GPU 上性能推理的優化實踐。
美團研發工程師,機器學習平臺預測引擎負責人王新表示,“在美團和英偉達的共同努力下, CTR 預測服務成功的遷移到 GPU 平臺上,在為業務提供更好的支撐的同時也獲得了更好的性價比;下一步,機器學習平臺計劃采用 NVIDIA Triton 推理服務框架和 NVIDIA Ampere A30 ,進一步提升美團推理服務的效率。”
原文標題:美團機器學習平臺使用 NVIDIA GPU 助力公司 CTR 預測服務升級
文章出處:【微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
-
cpu
+關注
關注
68文章
11074瀏覽量
216883 -
NVIDIA
+關注
關注
14文章
5299瀏覽量
106286 -
AI
+關注
關注
88文章
35040瀏覽量
279016 -
美團
+關注
關注
0文章
125瀏覽量
10655
原文標題:美團機器學習平臺使用 NVIDIA GPU 助力公司 CTR 預測服務升級
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
提升AI訓練性能:GPU資源優化的12個實戰技巧

RK3588核心板在邊緣AI計算中的顛覆性優勢與場景落地
英偉達GTC25亮點:NVIDIA Dynamo開源庫加速并擴展AI推理模型
摩爾線程GPU原生FP8計算助力AI訓練

無法在GPU上運行ONNX模型的Benchmark_app怎么解決?
AI推理帶火的ASIC,開發成敗在此一舉!


SSM框架的性能優化技巧 SSM框架中RESTful API的實現
SSM框架在Java開發中的應用 如何使用SSM進行web開發
Arm KleidiAI助力提升PyTorch上LLM推理性能
《算力芯片 高性能 CPUGPUNPU 微架構分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
NPU與GPU的性能對比

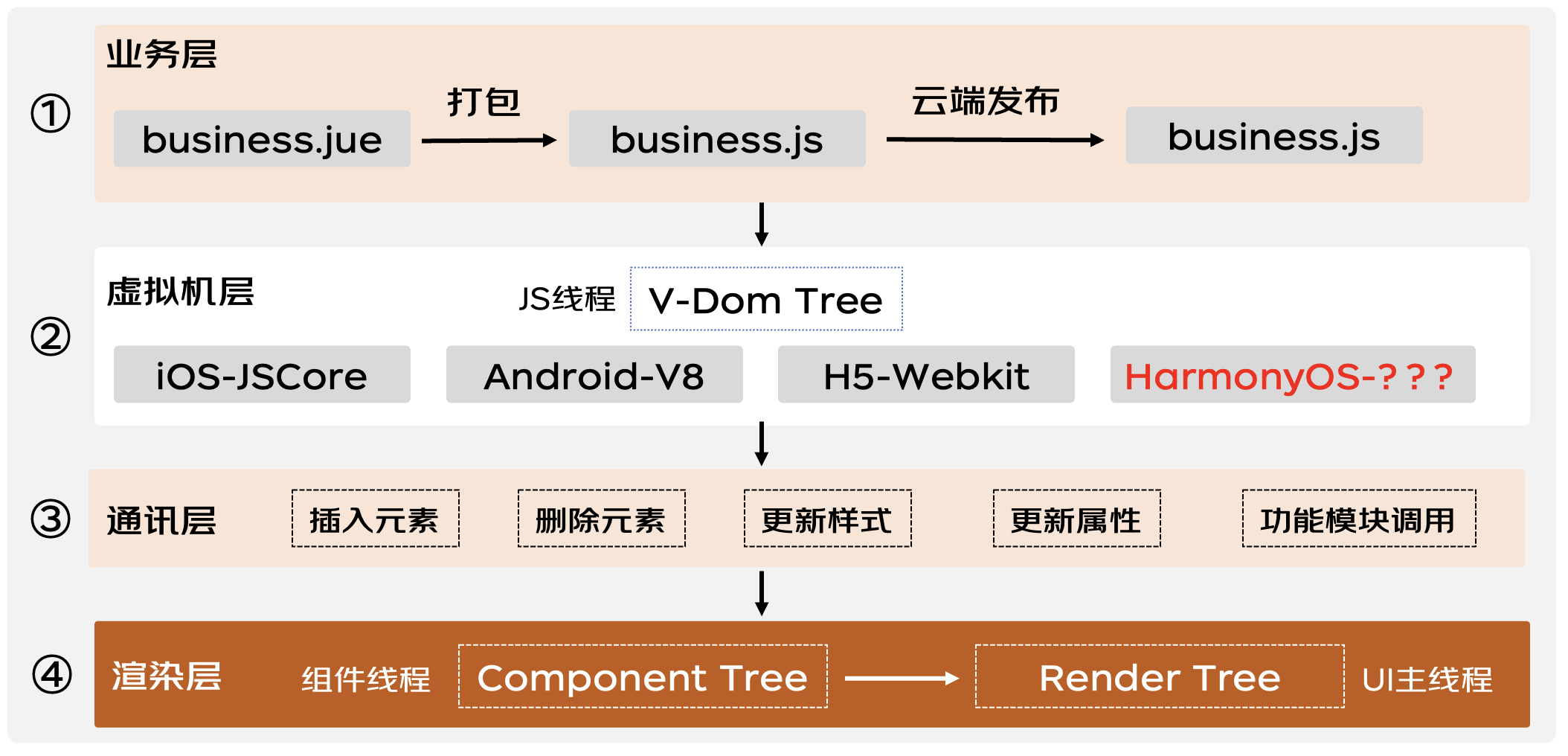
揭秘動態化跨端框架在鴻蒙系統下的高性能解決方案





 工商網監
工商網監
評論