") 如何使用BERT模型進(jìn)行抽取式摘要
如何使用BERT模型進(jìn)行抽取式摘要

寫?在前面
paper:https://arxiv.org/pdf/1903.10318.pdf
github:https://github.com/nlpyang/BertSum
后面,又發(fā)表于EMNLP2019,為《Text Summarization with Pretrained Encoders》,增加了生成式(抽象式,Abstractive)摘要部分,并對第一版論文進(jìn)行了部分內(nèi)容的補(bǔ)充與刪減。
paper:https://aclanthology.org/D19-1387.pdf
github:https://github.com/nlpyang/PreSumm
介紹
文本摘要任務(wù)主要分為抽象式摘要(abstractive summarization)和抽取式摘要(extractive summarization)。在抽象式摘要中,目標(biāo)摘要所包含的詞或短語會不在原文中,通常需要進(jìn)行文本重寫等操作進(jìn)行生成;而抽取式摘要,就是通過復(fù)制和重組文檔中最重要的內(nèi)容(一般為句子)來形成摘要。那么如何獲取并選擇文檔中重要句子,就是抽取式摘要的關(guān)鍵。
傳統(tǒng)抽取式摘要方法包括Lead-3和TextRank,傳統(tǒng)深度學(xué)習(xí)方法一般采用LSTM或GRU模型進(jìn)行重要句子的判斷與選擇,而本文采用預(yù)訓(xùn)練語言模型BERT進(jìn)行抽取式摘要。
模型結(jié)構(gòu)BertSum模型
結(jié)構(gòu)如下圖所示
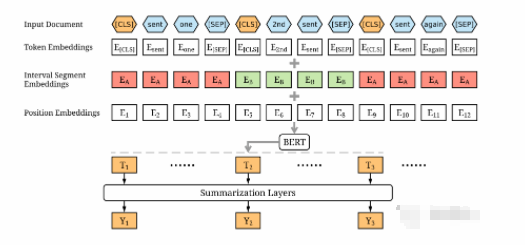
主要由句子編碼層和摘要判斷層組成,其中,「句子編碼層」通過BERT模型獲取文檔中每個(gè)句子的句向量編碼,「摘要判斷層」通過三種不同的結(jié)構(gòu)進(jìn)行選擇判斷,為每個(gè)句子進(jìn)行打分,最終選取最優(yōu)的top-n個(gè)句子作為文檔摘要。
句子編碼層
由于BERT模型MLM預(yù)訓(xùn)練機(jī)制,使得其輸出向量為每個(gè)token的向量;即使分隔符可以區(qū)分輸入的不同句子,但是僅有兩個(gè)標(biāo)簽(句子A或句子B),與抽取式摘要需要分隔多個(gè)句子大不相同;因此對BERT模型的輸入進(jìn)行了修改,如下:
將文檔中的每個(gè)句子前后均插入[CLS]和[SEP]標(biāo)記,并將每個(gè)句子前的[CLS]標(biāo)記進(jìn)入模型后的輸出向量,作為該句子的句向量表征。例如:文檔為”我愛南京。我喜歡NLP。我學(xué)習(xí)摘要。“,輸入序列為”[CLS]我愛南京。[SEP][CLS]我喜歡NLP。[SEP][CLS]我學(xué)習(xí)摘要。[SEP]“
采用Segment Embeddings區(qū)分文檔中的多個(gè)句子,將奇數(shù)句子和偶數(shù)句子的Segment Embeddings分別設(shè)置為和,例如:文檔為,那么Segment Embeddings為。
摘要判斷層
從句子編碼層獲取文檔中每個(gè)句子的句向量后,構(gòu)建了3種摘要判斷層,以通過獲取每個(gè)句子在文檔級特征下的重要性。對于每個(gè)句子,計(jì)算出最終的預(yù)測分?jǐn)?shù),模型的損失是相對于金標(biāo)簽的二元交叉熵。
Simple Classifier,僅在BERT輸出上添加一個(gè)線性全連接層,并使用一個(gè)sigmoid函數(shù)獲得預(yù)測分?jǐn)?shù),如下:
Transformer,在BERT輸出后增加額外的Transformer層,進(jìn)一步提取專注于摘要任務(wù)的文檔級特征,如下:
其中,為句子的句向量,,PosEmb函數(shù)為在句向量中增加位置信息函數(shù),MHAtt函數(shù)為多頭注意力函數(shù),為Transformer的層數(shù)。最后仍然接一個(gè)sigmoid函數(shù)的全連接層,
最終選擇為2。
LSTM,在BERT輸出增加額外的LSTM層,進(jìn)一步提取專注于摘要任務(wù)的文檔級特征,如下:
其中,分別為遺忘門、輸入門和輸出門;分別為隱藏向量、記憶向量和輸出向量;分別為不同的layer normalization操作。最后仍然接一個(gè)sigmoid函數(shù)的全連接層,
實(shí)驗(yàn)細(xì)節(jié)訓(xùn)練集構(gòu)建
由于目前文本摘要的數(shù)據(jù)大多為抽象式文本摘要數(shù)據(jù)集,不適合訓(xùn)練抽取摘要模型。論文利用貪心算法構(gòu)建每個(gè)文檔抽取式摘要對應(yīng)的句子集合,即通過算法貪婪地選擇能使ROUGE分?jǐn)?shù)最大化的句子集合。將選中的句子集合中的句子的標(biāo)簽設(shè)為1,其余的句子為0。
模型預(yù)測
在模型預(yù)測階段,將文檔按照句子進(jìn)行切分,采用BertSum模型獲取每個(gè)句子的得分,然后根據(jù)分?jǐn)?shù)從高到低對這些句子進(jìn)行排序,并選擇前3個(gè)句子作為摘要。
在句子選擇階段,采用Trigram Blocking機(jī)制來減少摘要的冗余,即對應(yīng)當(dāng)前已組成摘要S和侯選句子c,如果S和c直接存在tri-gram相同片段,則跳過句子c,也就是句子c不會增加在已組成摘要S中。
數(shù)據(jù)超出BERT限制
BERT模型由于最大長度為512,而現(xiàn)實(shí)中文檔長度常常會超出。在《Text Summarization with Pretrained Encoders》文中提到,在BERT模型中添加更多的位置嵌入來克服這個(gè)限制,并且位置嵌入是隨機(jī)初始化的,并在訓(xùn)練時(shí)與其他參數(shù)同時(shí)進(jìn)行微調(diào)。
實(shí)驗(yàn)結(jié)果主要對比了LEAD、REFRESH、NEUSUM、PGN以及DCA方法,較當(dāng)時(shí)方法,該論文效果確實(shí)不錯(cuò),如下表所示,
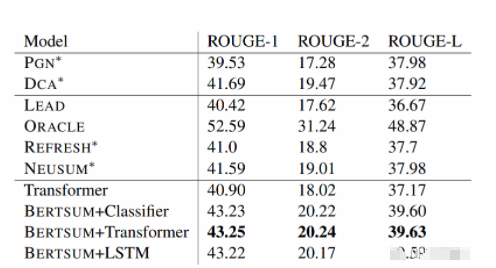
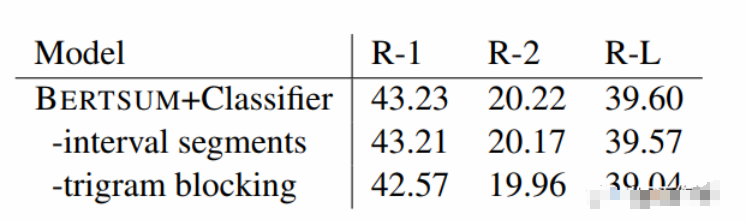
在三種摘要判斷層中,Transformer的效果最優(yōu)。并且進(jìn)行了進(jìn)一步的消融實(shí)驗(yàn),發(fā)現(xiàn)采用不同的Segment Embeddings會給結(jié)果帶來一些提升,但是Trigram Blocking機(jī)制更為關(guān)鍵,具體如下表所示。
總結(jié)個(gè)人認(rèn)為該論文是一篇較為經(jīng)典的BERT模型應(yīng)用論文,當(dāng)時(shí)2019年看的時(shí)候就進(jìn)行了嘗試,并且也將其用到了一些項(xiàng)目中。
放假ing,但是也要學(xué)習(xí)。
原文標(biāo)題:BertSum-基于BERT模型的抽取式文本摘要
文章出處:【微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
審核編輯:湯梓紅
-
結(jié)構(gòu)
+關(guān)注
關(guān)注
1文章
117瀏覽量
21930 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4376瀏覽量
64496 -
模型
+關(guān)注
關(guān)注
1文章
3501瀏覽量
50172
原文標(biāo)題:BertSum-基于BERT模型的抽取式文本摘要
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
自動識別事件類別的中文事件抽取技術(shù)研究
基于XML的WEB信息抽取模型設(shè)計(jì)
BERT模型的PyTorch實(shí)現(xiàn)
簡述基于神經(jīng)網(wǎng)絡(luò)的抽取式摘要方法
XLNet和Bert比,有什么不同?要進(jìn)行改進(jìn)嗎?
圖解BERT預(yù)訓(xùn)練模型!
模型NLP事件抽取方法總結(jié)

NLP:關(guān)系抽取到底在乎什么
融合BERT詞向量與TextRank的關(guān)鍵詞抽取方法
抽取式摘要方法中如何合理設(shè)置抽取單元?
基于BERT+Bo-LSTM+Attention的病歷短文分類模型

基于BERT的中文科技NLP預(yù)訓(xùn)練模型
基于Zero-Shot的多語言抽取式文本摘要模型
Instruct-UIE:信息抽取統(tǒng)一大模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論