") CUDA簡介: CUDA編程模型概述
CUDA簡介: CUDA編程模型概述

本章和下一章中使用的向量加法示例的完整代碼可以在 vectorAddCUDA示例中找到。
2.1 內(nèi)核
CUDA C++ 通過允許程序員定義稱為kernel的 C++ 函數(shù)來擴(kuò)展 C++,當(dāng)調(diào)用內(nèi)核時,由 N 個不同的 CUDA 線程并行執(zhí)行 N 次,而不是像常規(guī) C++ 函數(shù)那樣只執(zhí)行一次。
使用__global__聲明說明符定義內(nèi)核,并使用新的<<<...>>>執(zhí)行配置語法指定內(nèi)核調(diào)用的 CUDA 線程數(shù)(請參閱C++ 語言擴(kuò)展)。 每個執(zhí)行內(nèi)核的線程都有一個唯一的線程 ID,可以通過內(nèi)置變量在內(nèi)核中訪問。
作為說明,以下示例代碼使用內(nèi)置變量threadIdx將兩個大小為 N 的向量 A 和 B 相加,并將結(jié)果存儲到向量 C 中:
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
...
// Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
...
}
這里,執(zhí)行 VecAdd() 的 N 個線程中的每一個線程都會執(zhí)行一個加法。
2.2 線程層次
為方便起見,threadIdx 是一個 3 分量向量,因此可以使用一維、二維或三維的線程索引來識別線程,形成一個一維、二維或三維的線程塊,稱為block。 這提供了一種跨域的元素(例如向量、矩陣或體積)調(diào)用計算的方法。
線程的索引和它的線程 ID 以一種直接的方式相互關(guān)聯(lián):對于一維塊,它們是相同的; 對于大小為(Dx, Dy)的二維塊,索引為(x, y)的線程的線程ID為(x + y*Dx); 對于大小為 (Dx, Dy, Dz) 的三維塊,索引為 (x, y, z) 的線程的線程 ID 為 (x + y*Dx + z*Dx*Dy)。
例如,下面的代碼將兩個大小為NxN的矩陣A和B相加,并將結(jié)果存儲到矩陣C中:
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<>>(A, B, C);
...
}
每個塊的線程數(shù)量是有限制的,因為一個塊的所有線程都應(yīng)該駐留在同一個處理器核心上,并且必須共享該核心有限的內(nèi)存資源。在當(dāng)前的gpu上,一個線程塊可能包含多達(dá)1024個線程。
但是,一個內(nèi)核可以由多個形狀相同的線程塊執(zhí)行,因此線程總數(shù)等于每個塊的線程數(shù)乘以塊數(shù)。
塊被組織成一維、二維或三維的線程塊網(wǎng)格(grid),如下圖所示。網(wǎng)格中的線程塊數(shù)量通常由正在處理的數(shù)據(jù)的大小決定,通常超過系統(tǒng)中的處理器數(shù)量。
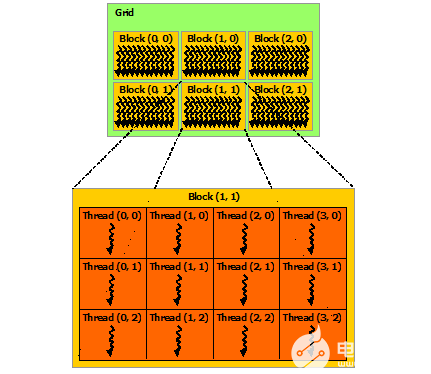
<<<...>>>語法中指定的每個塊的線程數(shù)和每個網(wǎng)格的塊數(shù)可以是int或dim3類型。如上例所示,可以指定二維塊或網(wǎng)格。
網(wǎng)格中的每個塊都可以由一個一維、二維或三維的惟一索引標(biāo)識,該索引可以通過內(nèi)置的blockIdx變量在內(nèi)核中訪問。線程塊的維度可以通過內(nèi)置的blockDim變量在內(nèi)核中訪問。
擴(kuò)展前面的MatAdd()示例來處理多個塊,代碼如下所示。
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation with one block of N * N * 1 threads
int numBlocks = 1;
dim3 threadsPerBlock(N, N);
MatAdd<<>>(A, B, C);
...
}
線程塊大小為16×16(256個線程),盡管在本例中是任意更改的,但這是一種常見的選擇。網(wǎng)格是用足夠的塊創(chuàng)建的,這樣每個矩陣元素就有一個線程來處理。為簡單起見,本例假設(shè)每個維度中每個網(wǎng)格的線程數(shù)可以被該維度中每個塊的線程數(shù)整除,盡管事實并非如此。
程塊需要獨立執(zhí)行:必須可以以任何順序執(zhí)行它們,并行或串行。 這種獨立性要求允許跨任意數(shù)量的內(nèi)核以任意順序調(diào)度線程塊,如下圖所示,使程序員能夠編寫隨內(nèi)核數(shù)量擴(kuò)展的代碼。
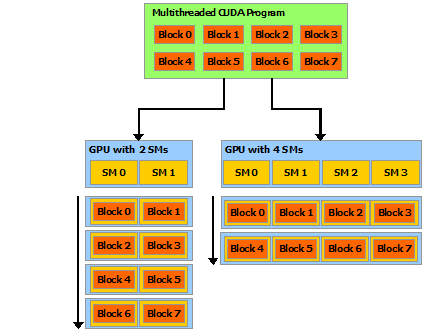
塊內(nèi)的線程可以通過一些共享內(nèi)存共享數(shù)據(jù)并通過同步它們的執(zhí)行來協(xié)調(diào)內(nèi)存訪問來進(jìn)行協(xié)作。 更準(zhǔn)確地說,可以通過調(diào)用__syncthreads()內(nèi)部函數(shù)來指定內(nèi)核中的同步點;__syncthreads()充當(dāng)屏障,塊中的所有線程必須等待,然后才能繼續(xù)。Shared Memory給出了一個使用共享內(nèi)存的例子。 除了__syncthreads()之外,Cooperative Groups API還提供了一組豐富的線程同步示例。
為了高效協(xié)作,共享內(nèi)存是每個處理器內(nèi)核附近的低延遲內(nèi)存(很像 L1 緩存),并且__syncthreads()是輕量級的。
2.3 存儲單元層次
CUDA 線程可以在執(zhí)行期間從多個內(nèi)存空間訪問數(shù)據(jù),如下圖所示。每個線程都有私有的本地內(nèi)存。 每個線程塊都具有對該塊的所有線程可見的共享內(nèi)存,并且具有與該塊相同的生命周期。 所有線程都可以訪問相同的全局內(nèi)存。
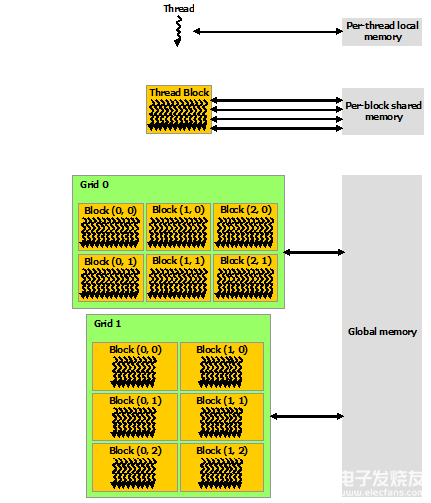
還有兩個額外的只讀內(nèi)存空間可供所有線程訪問:常量和紋理內(nèi)存空間。 全局、常量和紋理內(nèi)存空間針對不同的內(nèi)存使用進(jìn)行了優(yōu)化(請參閱設(shè)備內(nèi)存訪問)。 紋理內(nèi)存還為某些特定數(shù)據(jù)格式提供不同的尋址模式以及數(shù)據(jù)過濾(請參閱紋理和表面內(nèi)存)。
全局、常量和紋理內(nèi)存空間在同一應(yīng)用程序的內(nèi)核啟動中是持久的。
2.4 異構(gòu)編程
如下圖所示,CUDA 編程模型假定 CUDA 線程在物理獨立的設(shè)備上執(zhí)行,該設(shè)備作為運行 C++ 程序的主機(jī)的協(xié)處理器運行。例如,當(dāng)內(nèi)核在 GPU 上執(zhí)行而 C++ 程序的其余部分在 CPU 上執(zhí)行時,就是這種情況。
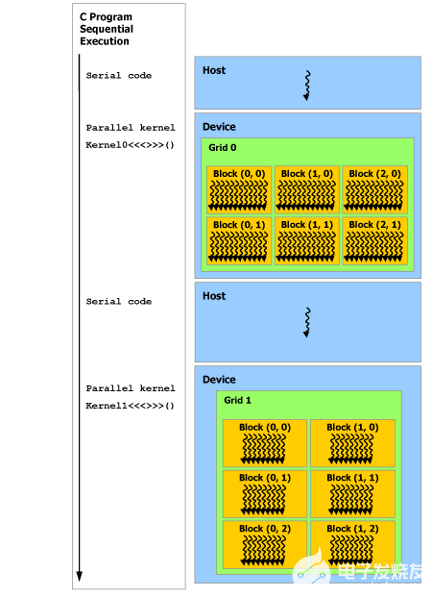
CUDA 編程模型還假設(shè)主機(jī)(host)和設(shè)備(device)都在 DRAM 中維護(hù)自己獨立的內(nèi)存空間,分別稱為主機(jī)內(nèi)存和設(shè)備內(nèi)存。因此,程序通過調(diào)用 CUDA 運行時(在編程接口中描述)來管理內(nèi)核可見的全局、常量和紋理內(nèi)存空間。這包括設(shè)備內(nèi)存分配和釋放以及主機(jī)和設(shè)備內(nèi)存之間的數(shù)據(jù)傳輸。
統(tǒng)一內(nèi)存提供托管內(nèi)存來橋接主機(jī)和設(shè)備內(nèi)存空間。托管內(nèi)存可從系統(tǒng)中的所有 CPU 和 GPU 訪問,作為具有公共地址空間的單個連貫內(nèi)存映像。此功能可實現(xiàn)設(shè)備內(nèi)存的超額訂閱,并且無需在主機(jī)和設(shè)備上顯式鏡像數(shù)據(jù),從而大大簡化了移植應(yīng)用程序的任務(wù)。有關(guān)統(tǒng)一內(nèi)存的介紹,請參閱統(tǒng)一內(nèi)存編程。
注:串行代碼在主機(jī)(host)上執(zhí)行,并行代碼在設(shè)備(device)上執(zhí)行。
2.5 異步SIMT編程模型
在 CUDA 編程模型中,線程是進(jìn)行計算或內(nèi)存操作的最低抽象級別。 從基于 NVIDIA Ampere GPU 架構(gòu)的設(shè)備開始,CUDA 編程模型通過異步編程模型為內(nèi)存操作提供加速。 異步編程模型定義了與 CUDA 線程相關(guān)的異步操作的行為。
異步編程模型為 CUDA 線程之間的同步定義了異步屏障的行為。 該模型還解釋并定義了如何使用 cuda::memcpy_async 在 GPU計算時從全局內(nèi)存中異步移動數(shù)據(jù)。
2.5.1 異步操作
異步操作定義為由CUDA線程發(fā)起的操作,并且與其他線程一樣異步執(zhí)行。在結(jié)構(gòu)良好的程序中,一個或多個CUDA線程與異步操作同步。發(fā)起異步操作的CUDA線程不需要在同步線程中.
這樣的異步線程(as-if 線程)總是與發(fā)起異步操作的 CUDA 線程相關(guān)聯(lián)。異步操作使用同步對象來同步操作的完成。這樣的同步對象可以由用戶顯式管理(例如,cuda::memcpy_async)或在庫中隱式管理(例如,cooperative_groups::memcpy_async)。
同步對象可以是cuda::barrier或cuda::pipeline。這些對象在Asynchronous Barrier和Asynchronous Data Copies using cuda::pipeline.中進(jìn)行了詳細(xì)說明。這些同步對象可以在不同的線程范圍內(nèi)使用。作用域定義了一組線程,這些線程可以使用同步對象與異步操作進(jìn)行同步。下表定義了CUDA c++中可用的線程作用域,以及可以與每個線程同步的線程。

這些線程作用域是在CUDA標(biāo)準(zhǔn)c++庫中作為標(biāo)準(zhǔn)c++的擴(kuò)展實現(xiàn)的。
2.6 Compute Capability
設(shè)備的Compute Capability由版本號表示,有時也稱其“SM版本”。該版本號標(biāo)識GPU硬件支持的特性,并由應(yīng)用程序在運行時使用,以確定當(dāng)前GPU上可用的硬件特性和指令。
Compute Capability包括一個主要版本號X和一個次要版本號Y,用X.Y表示
主版本號相同的設(shè)備具有相同的核心架構(gòu)。設(shè)備的主要修訂號是8,為NVIDIA Ampere GPU的體系結(jié)構(gòu)的基礎(chǔ)上,7基于Volta設(shè)備架構(gòu),6設(shè)備基于Pascal架構(gòu),5設(shè)備基于Maxwell架構(gòu),3基于Kepler架構(gòu)的設(shè)備,2設(shè)備基于Fermi架構(gòu),1是基于Tesla架構(gòu)的設(shè)備。
次要修訂號對應(yīng)于對核心架構(gòu)的增量改進(jìn),可能包括新特性。
Turing是計算能力7.5的設(shè)備架構(gòu),是基于Volta架構(gòu)的增量更新。
CUDA-Enabled GPUs列出了所有支持 CUDA 的設(shè)備及其計算能力。Compute Capabilities給出了每個計算能力的技術(shù)規(guī)格。
關(guān)于作者
Ken He 是 NVIDIA 企業(yè)級開發(fā)者社區(qū)經(jīng)理 & 高級講師,擁有多年的 GPU 和人工智能開發(fā)經(jīng)驗。自 2017 年加入 NVIDIA 開發(fā)者社區(qū)以來,完成過上百場培訓(xùn),幫助上萬個開發(fā)者了解人工智能和 GPU 編程開發(fā)。在計算機(jī)視覺,高性能計算領(lǐng)域完成過多個獨立項目。并且,在機(jī)器人和無人機(jī)領(lǐng)域,有過豐富的研發(fā)經(jīng)驗。對于圖像識別,目標(biāo)的檢測與跟蹤完成過多種解決方案。曾經(jīng)參與 GPU 版氣象模式GRAPES,是其主要研發(fā)者。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5292瀏覽量
106150 -
gpu
+關(guān)注
關(guān)注
28文章
4934瀏覽量
131031 -
人工智能
+關(guān)注
關(guān)注
1806文章
48955瀏覽量
248409
發(fā)布評論請先 登錄
使用NVIDIA CUDA-X庫加速科學(xué)和工程發(fā)展
借助PerfXCloud和dify開發(fā)代碼轉(zhuǎn)換器

【「大模型啟示錄」閱讀體驗】對大模型更深入的認(rèn)知
使用英特爾AI PC為YOLO模型訓(xùn)練加速






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論