 使用Omniverse Replicator SDK構建自定義、物理級精確的合成數據生成管線
使用Omniverse Replicator SDK構建自定義、物理級精確的合成數據生成管線

提供合成數據生成工具和服務的企業以及開發者現在可以使用 Omniverse Replicator SDK 構建自定義、物理級精確的合成數據生成管線。Omniverse Replicator SDK 建立在 NVIDIA Omniverse 平臺上,目前已在 Omniverse Code 內提供公測版。
Omniverse Replicator 是一個建立在可擴展的 Omniverse 平臺上的高度可擴展 SDK,它可以生成物理級精確的 3D 合成數據來加速 AI 感知網絡的訓練和性能。開發者、研究人員和工程師現在可以使用 Omniverse Replicator 生成的大規模逼真合成數據來引導和提高現有深度學習感知模型的性能。
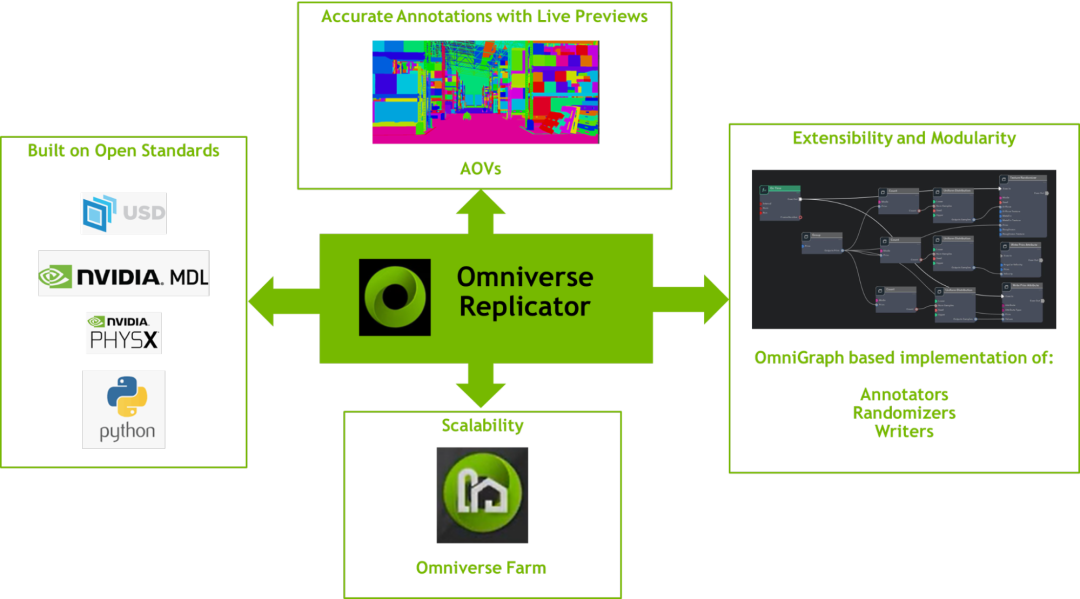
圖1:Replicator 使用基于開放標準的 Omniverse 平臺,以及 OmniGraph 和 Farm 架構提供的可延伸性和可擴展性
Omniverse Replicator 為開發者提供了一個可以根據他們的神經網絡要求構建特定合成數據生成應用的特殊平臺。它建立在通用場景描述(USD)、PhysX 和材質定義語言(MDL)等開放標準之上并帶有易于使用的 python API,還具有可擴展性并且支持自定義隨機發生器、注釋器和寫入器。Replicator 通過基于 CUDA 的 OmniGraph 實現核心注釋器功能,支持瞬間數據生成,因此可以實時預覽輸出。當與 Omniverse Farm 和 SwiftStack 輸出相結合時,Replicator 可在云中提供大規模的可擴展性。
Omniverse Replicator SDK 由六個用于自定義合成數據工作流程的主要組件組成:
語義模式編輯器:通過對 3D 資產及其 prim 進行語義標記,Replicator 可以在渲染和數據生成過程中對目標對象進行注釋。語義模式編輯器提供一種通過用戶界面將這些標簽應用于 prim 的方式。
可視化器:為分配給 3D 資產的語義標簽以及 2D/3D bounding box、法線、深度等注釋提供可視化功能。
隨機發生器:域隨機化是 Replicator 最重要的功能之一。用戶可以使用隨機發生器創建隨機化的場景,從資產、材質、照明和攝像機位置等隨機化能力中取樣。
Omni.syntheticdata:提供與 Omniverse RTX 渲染器和 OmniGraph 計算圖系統的低層次集成,驅動 Replicator 的基準真值數據提取注釋器,將任意輸出變量(AOV)從渲染器傳遞到注釋器。
注釋器:從 Omni.syntheticdata 擴展程序中提取 AOV 和其他輸出,生成用于深度神經網絡(DNN)訓練的精確標記注釋。
寫入器:處理來自注釋器的圖像和其他注釋,并生成用于訓練的 DNN 專用數據格式。
用于 AI 訓練的合成數據
為了訓練一個用于感知任務的 DNN,通常需要從數百萬圖像中手動采集數據,然后對這些圖像進行手動注釋和有選擇性的增強。
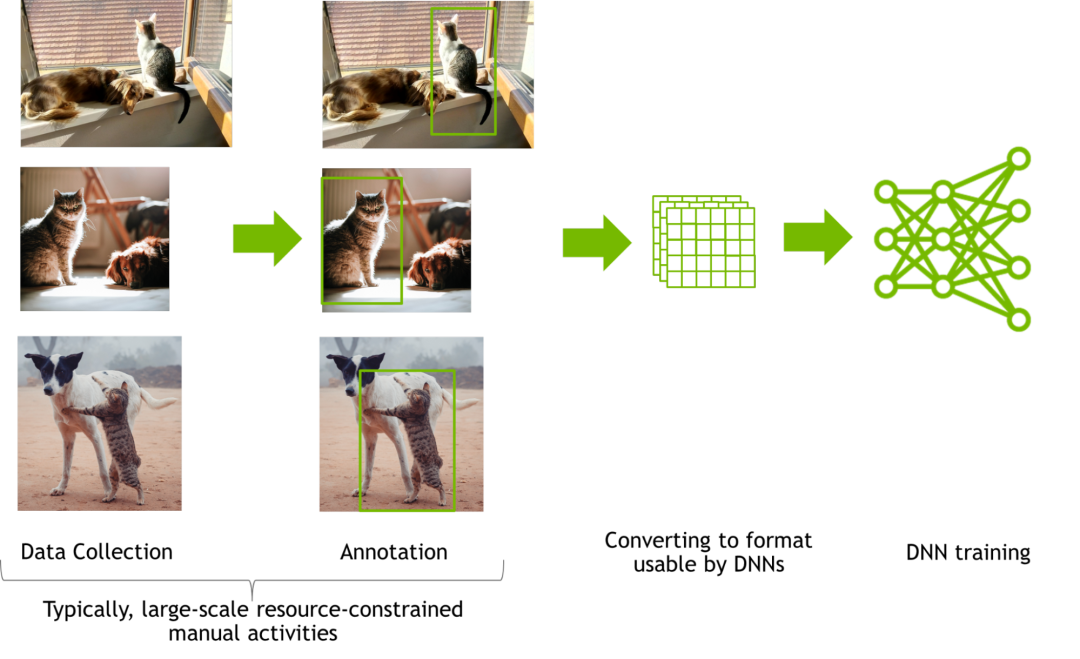
圖2:數據采集和注釋任務圖
人工數據采集和注釋是一項費力而主觀的任務。在采集和注釋真實圖像的過程中,即便只是像大規模 2D bounding box 這樣的簡單注釋也會帶來許多人力協調方面的挑戰。分割等所涉及到的注釋存在資源限制,并且手動執行此類任務時的準確性要差得多。

圖3:語義分割任務的復雜性
在采集和注釋完畢后,數據將被轉換成 DNN 可用的格式,然后訓練用于感知任務的 DNN。一般情況下,接下來會通過超參數調節或改變網絡結構來優化網絡性能。在對模型性能進行分析時,可能會導致數據集發生變化,在大多數情況下,還需要進行一輪手動數據采集和注釋,這種人工數據采集和注釋的迭代循環是昂貴、乏味且緩慢的。
憑借以合成方式生成的數據,團隊就能以一種高成本效益的方式啟動和加強帶有準確注釋的大規模訓練數據的生成。此外,合成數據生成還有助于解決與長尾異常、缺乏可用訓練數據和在線強化學習有關的挑戰。不同于人工采集和注釋的數據,以合成方式生成的數據具有較低的攤銷成本。由于數據采集/注釋和模型訓練周期一般具有迭代性,因此這一點十分有益。
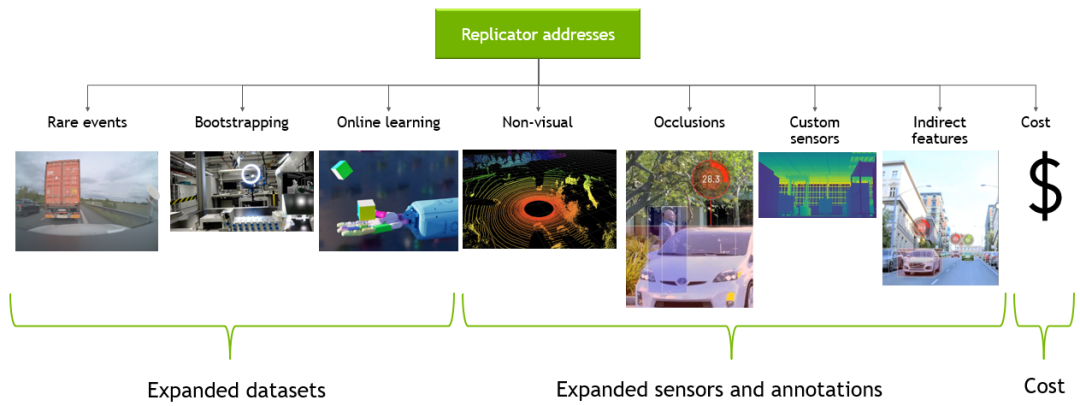
圖4:使用 Omniverse Replicator 生成帶有準確注釋的大規模訓練數據
Omniverse Replicator 通過利用 Omniverse 平臺的眾多核心功能和最佳實踐來解決這些挑戰,包括但不限于物理級精確、逼真的數據集和對超大數據集的訪問。
為了生成物理級精確的逼真數據集,需要使用各種 RTX 技術、基于物理學的材質和物理引擎等 Omniverse 平臺的所有核心技術進行準確的光線追蹤和路徑追蹤。

圖5:使用 Omniverse Replicator 增強倉庫場景中的傳感器注釋
基于通用場景描述(USD)的 Omniverse 可以無縫連接其他 3D 應用,因此開發者可以導入自定義內容或編寫自己的工具來生成不同的域場景。由于需要在多個 GPU 和節點上進行擴展,因此這些資產的生成往往會成為瓶頸。
Omniverse Replicator 通過 Omniverse Farm 使團隊能夠一起使用多個工作站或服務器驅動渲染或合成數據生成等工作。合成數據生成工作流程不是一蹴而就的,為了成功使用合成數據訓練網絡,必須在真實數據集上反復測試該網絡。Replicator 通過將模擬世界轉換為一組可學習的參數來提供這種以數據為中心的 AI 訓練。
使用 Omniverse Replicator 和 TAO 工具套件加速現有的工作流程
開發者、工程師和研究人員可以將 Omniverse Replicator 與現有的工具進行整合,來加快 AI 模型的訓練速度。例如,在生成合成數據后,開發者可以利用 NVIDIA TAO 工具套件快速訓練他們的 AI 模型。TAO 工具套件利用遷移學習讓開發者無需事先掌握 AI 專業知識,就能根據其用例來訓練、調整和優化模型。
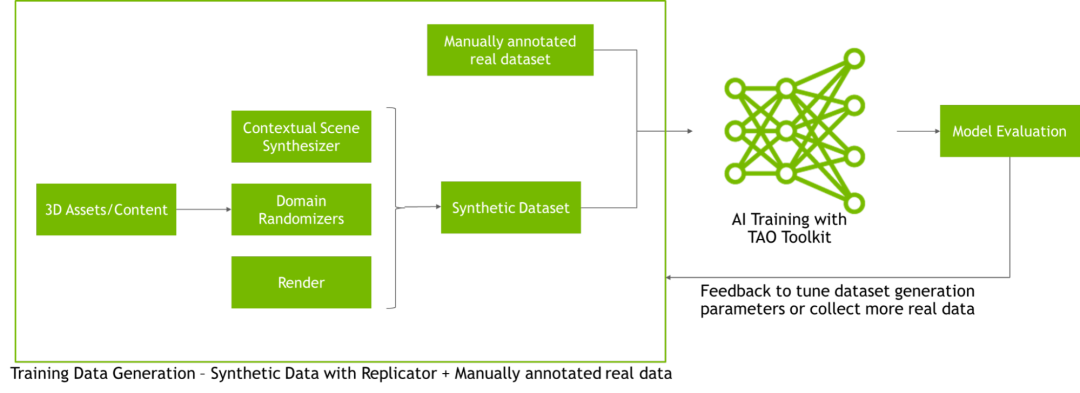
圖6:用于合成數據生成和模型訓練的 Omniverse Replicator 和 TAO 工具套件工作流程
使用 Omniverse Replicator 構建應用
Kinetic Vision 是一家為零售、內部物流、消費性制造和消費性包裝品行業的大型客戶提供服務的系統集成商。為了向客戶提供高質量的合成數據服務,該公司正在開發一個基于 Omniverse Replicator SDK 的新企業應用。
當訓練深度學習模型所需的數據不可用時,Omniverse Replicator 會生成可用于增強有限數據集的合成數據。Lightning AI (前身為 Grid.AI)使用 NVIDIA Omniverse Replicator 生成基于通用場景描述(USD)格式、物理級精確的 3D 數據集,這些數據集可用于訓練這些模型。用戶只需要拖放 3D 資產,然后在數據集生成后,就可以選擇最新、最先進的計算機視覺模型并使用合成數據自動訓練。
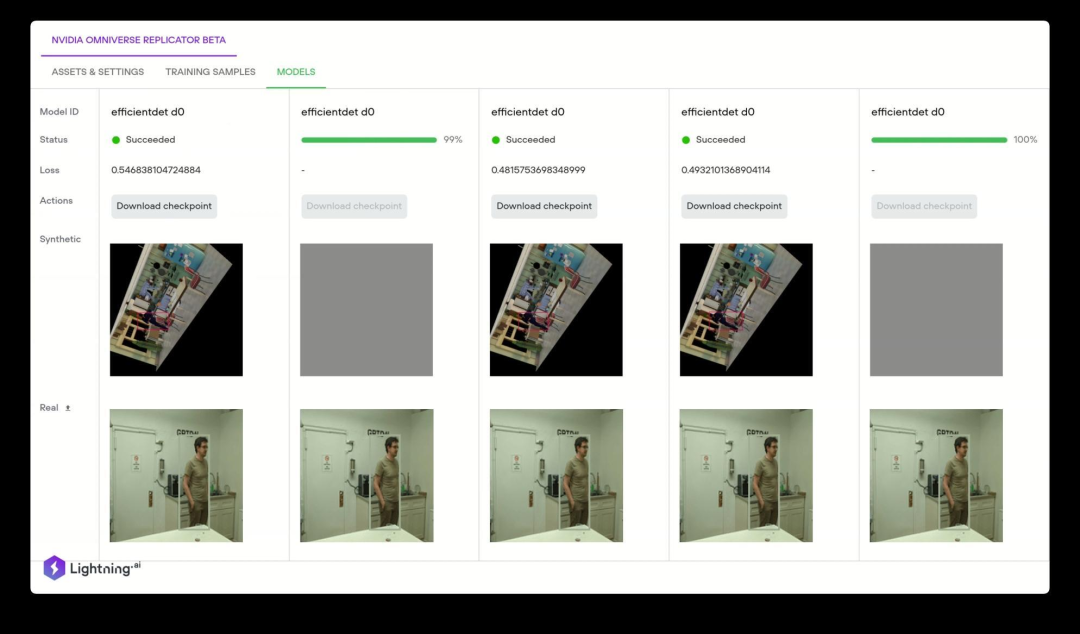
圖7:Lightning AI 應用正在基于 Replicator 生成的合成數據來訓練和測試 DNN。
NVIDIA Isaac Sim 和 DRIVE Sim 團隊使用 Omniverse Replicator SDK 構建特定領域的合成數據生成工具——用于機器人的 Isaac Replicator 和用于自動駕駛汽車訓練的 DRIVE Replicator。Omniverse Replicator SDK 為開發者提供一套核心功能,方便開發者利用 Omniverse 平臺所提供的所有優勢建立任何特定領域的合成數據生成管線。Replicator 通過將 Omniverse 作為 3D 模擬、渲染和 AI 開發能力的開發平臺,提供自定義合成數據生成管線。

圖8:使用 Omniverse Replicator 構建的 NVIDIA Isaac Sim(左)和 DRIVE Sim(右)合成數據生成能力
使用Omniverse Replicator
現在可以在 Omniverse Code 中使用 Omniverse Replicator SDK。用戶可從 Omniverse Launcher 下載 Omniverse Code。
審核編輯 :李倩
-
編輯器
+關注
關注
1文章
821瀏覽量
31917 -
SDK
+關注
關注
3文章
1074瀏覽量
47994 -
深度學習
+關注
關注
73文章
5557瀏覽量
122664
原文標題:已開啟公測 | 使用 Omniverse Replicator 構建自定義合成數據生成管線
文章出處:【微信號:Leadtek,微信公眾號:麗臺科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
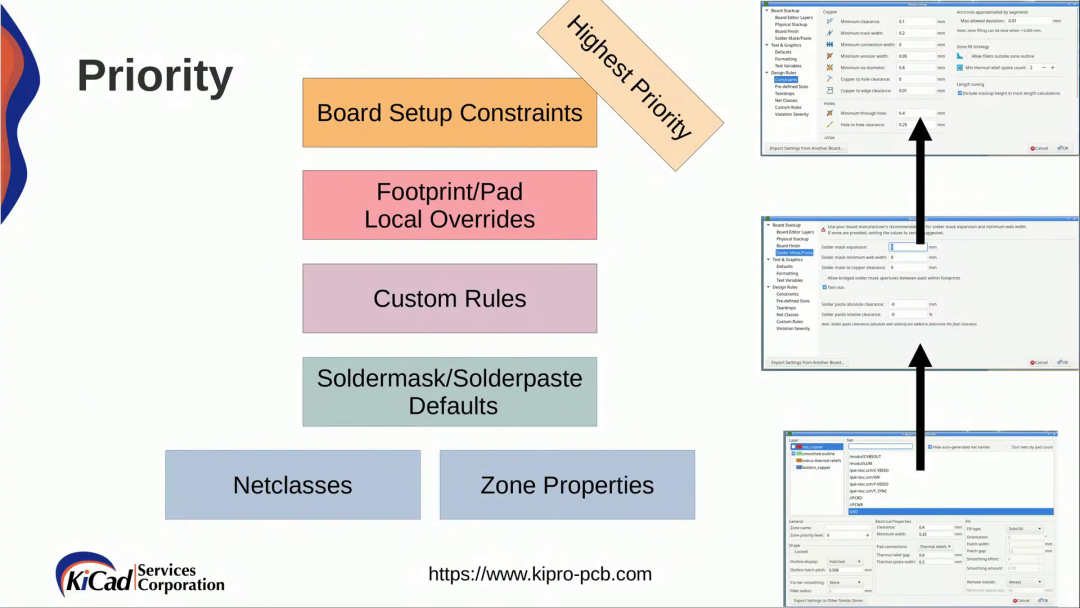
KiCad 中的自定義規則(KiCon 演講)
HarmonyOS應用自定義鍵盤解決方案
如何添加自定義單板
無法將自定義COCO數據集導入到OpenVINO? DL Workbench怎么解決?
如何快速創建用戶自定義Board和App工程


NVIDIA Omniverse擴展至生成式物理AI領域
think-cell:自定義think-cell(四)
think-cell;自定義think-cell(一)

NVIDIA Omniverse微服務助力構建大規模數字孿生

NVIDIA AI Foundry 為全球企業打造自定義 Llama 3.1 生成式 AI 模型






 工商網監
工商網監
評論