") 有關(guān)batch size的設(shè)置范圍
有關(guān)batch size的設(shè)置范圍

有關(guān) batch size 的設(shè)置范圍,其實(shí)不必那么拘謹(jǐn)。
我們知道,batch size 決定了深度學(xué)習(xí)訓(xùn)練過程中,完成每個(gè) epoch 所需的時(shí)間和每次迭代(iteration)之間梯度的平滑程度。batch size 越大,訓(xùn)練速度則越快,內(nèi)存占用更大,但收斂變慢。
又有一些理論說,GPU 對(duì) 2 的冪次的 batch 可以發(fā)揮更好性能,因此設(shè)置成 16、32、64、128 … 時(shí),往往要比設(shè)置為其他倍數(shù)時(shí)表現(xiàn)更優(yōu)。
后者是否是一種玄學(xué)?似乎很少有人驗(yàn)證過。最近,威斯康星大學(xué)麥迪遜分校助理教授,著名機(jī)器學(xué)習(xí)博主 Sebastian Raschka 對(duì)此進(jìn)行了一番認(rèn)真的討論。
Sebastian Raschka
關(guān)于神經(jīng)網(wǎng)絡(luò)訓(xùn)練,我認(rèn)為我們都犯了這樣的錯(cuò)誤:我們選擇批量大小為 2 的冪,即 64、128、256、512、1024 等等。(這里,batch size 是指當(dāng)我們通過基于隨機(jī)梯度下降的優(yōu)化算法訓(xùn)練具有反向傳播的神經(jīng)網(wǎng)絡(luò)時(shí),每個(gè) minibatch 中的訓(xùn)練示例數(shù)。)
據(jù)稱,我們這樣做是出于習(xí)慣,因?yàn)檫@是一個(gè)標(biāo)準(zhǔn)慣例。這是因?yàn)槲覀冊(cè)?jīng)被告知,將批量大小選擇為 2 的冪有助于從計(jì)算角度提高訓(xùn)練效率。
這有一些有效的理論依據(jù),但它在實(shí)踐中是如何實(shí)現(xiàn)的呢?在過去的幾天里,我們對(duì)此進(jìn)行了一些討論,在這里我想寫下一些要點(diǎn),以便將來參考。我希望你也會(huì)發(fā)現(xiàn)這很有幫助!
理論背景
在看實(shí)際基準(zhǔn)測試結(jié)果之前,讓我們簡要回顧一下將批大小選擇為 2 的冪的主要思想。以下兩個(gè)小節(jié)將簡要強(qiáng)調(diào)兩個(gè)主要論點(diǎn):內(nèi)存對(duì)齊和浮點(diǎn)效率。
內(nèi)存對(duì)齊
選擇批大小為 2 的冪的主要論據(jù)之一是 CPU 和 GPU 內(nèi)存架構(gòu)是以 2 的冪進(jìn)行組織的。或者更準(zhǔn)確地說,存在內(nèi)存頁的概念,它本質(zhì)上是一個(gè)連續(xù)的內(nèi)存塊。如果你使用的是 macOS 或 Linux,就可以通過在終端中執(zhí)行 getconf PAGESIZE 來檢查頁面大小,它應(yīng)該會(huì)返回一個(gè) 2 的冪的數(shù)字。
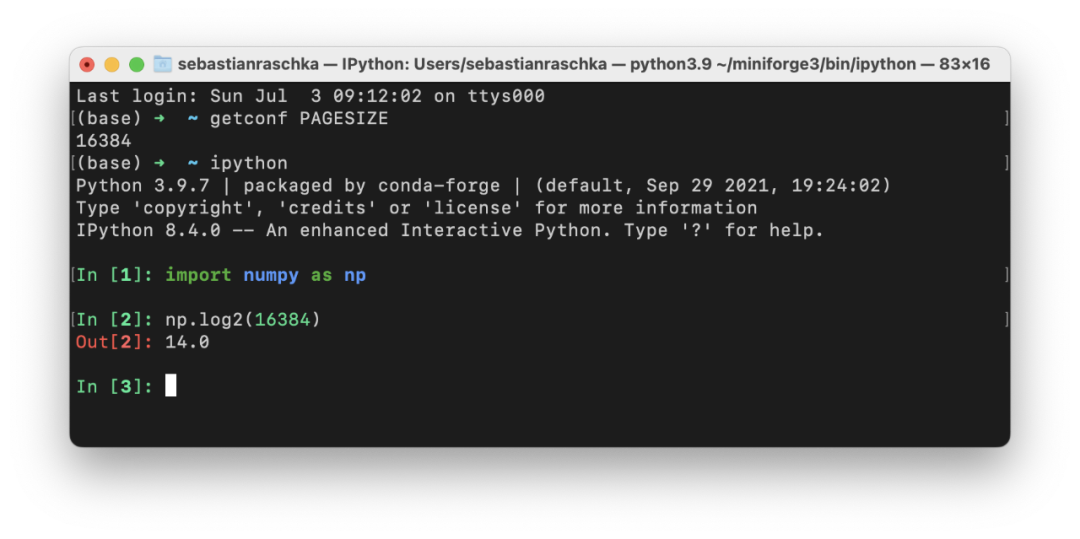
這個(gè)想法是將一個(gè)或多個(gè)批次整齊地放在一個(gè)頁面上,以幫助 GPU 并行處理。或者換句話說,我們選擇批大小為 2 以獲得更好的內(nèi)存對(duì)齊。這與在視頻游戲開發(fā)和圖形設(shè)計(jì)中使用 OpenGL 和 DirectX 時(shí)選擇二次冪紋理類似。
矩陣乘法和 Tensor Core
再詳細(xì)一點(diǎn),英偉達(dá)有一個(gè)矩陣乘法背景用戶指南,解釋了矩陣尺寸和圖形處理單元 GPU 計(jì)算效率之間的關(guān)系。因此,本文建議不要將矩陣維度選擇為 2 的冪,而是將矩陣維度選擇為 8 的倍數(shù),以便在具有 Tensor Core 的 GPU 上進(jìn)行混合精度訓(xùn)練。不過,當(dāng)然這兩者之間存在重疊:

為什么會(huì)是 8 的倍數(shù)?這與矩陣乘法有關(guān)。假設(shè)我們?cè)诰仃?A 和 B 之間有以下矩陣乘法:
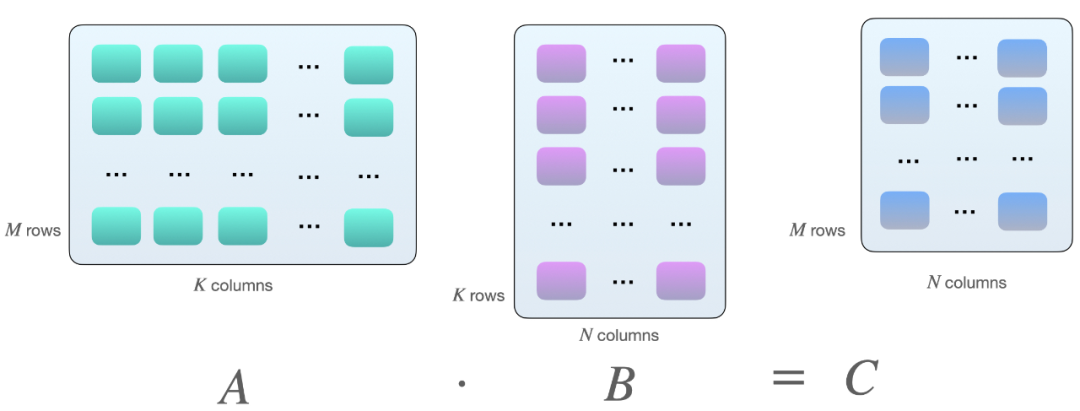
將兩個(gè)矩陣 A 和 B 相乘的一種方法,是計(jì)算矩陣 A 的行向量和矩陣 B 的列向量之間的點(diǎn)積。如下所示,這些是 k 元素向量對(duì)的點(diǎn)積:
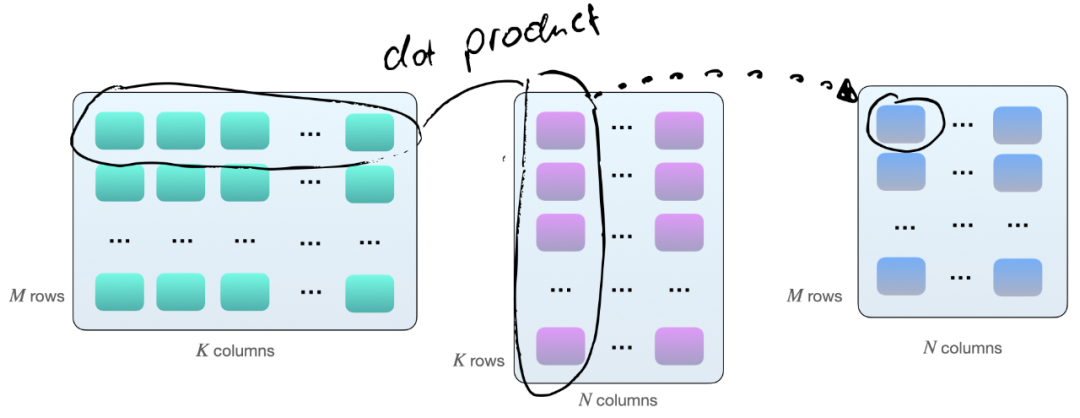
每個(gè)點(diǎn)積由一個(gè)「加」和一個(gè)「乘」操作組成,我們有 M×N 個(gè)這樣的點(diǎn)積。因此,共有 2×M×N×K 次浮點(diǎn)運(yùn)算(FLOPS)。不過需要知道的是:現(xiàn)在矩陣在 GPU 上的乘法并不完全如此,GPU 上的矩陣乘法涉及平鋪。
如果我們使用帶有 Tensor Cores 的 GPU,例如英偉達(dá) V100,當(dāng)矩陣維度 (M、N 和 K)與 16 字節(jié)的倍數(shù)對(duì)齊(根據(jù) Nvidia 的本指南)后,在 FP16 混合精度訓(xùn)練的情況下,8 的倍數(shù)對(duì)于效率來說是最佳的。
通常,維度 K 和 N 由神經(jīng)網(wǎng)絡(luò)架構(gòu)決定(盡管如果我們自己設(shè)計(jì)還會(huì)有一些回旋余地),但批大小(此處為 M)通常是我們可以完全控制的。
因此,假設(shè)批大小為 8 的倍數(shù)在理論上對(duì)于具有 Tensor Core 和 FP16 混合精度訓(xùn)練的 GPU 來說是最有效的,讓我們研究一下在實(shí)踐中可見的差異有多大。
簡單的 Benchmark
為了解不同的批大小如何影響實(shí)踐中的訓(xùn)練,我運(yùn)行了一個(gè)簡單的基準(zhǔn)測試,在 CIFAR-10 上訓(xùn)練 MobileNetV3 模型 10 個(gè) epoch—— 圖像大小調(diào)整為 224×224 以達(dá)到適當(dāng)?shù)?GPU 利用率。在這里,我使用 16 位原生自動(dòng)混合精度訓(xùn)練在英偉達(dá) V100 卡上運(yùn)行訓(xùn)練,它更有效地使用了 GPU 的張量核心。
如果想自己運(yùn)行它,代碼可在此 GitHub 存儲(chǔ)庫中找到:https://github.com/rasbt/b3-basic-batchsize-benchmark
小 Batch Size 基準(zhǔn)
我們從批大小為 128 的小基準(zhǔn)開始。「訓(xùn)練時(shí)間」對(duì)應(yīng)于在 CIFAR-10 上訓(xùn)練 MobileNetV3 的 10 個(gè) epoch。推理時(shí)間意味著在測試集中的 10k 圖像上評(píng)估模型。
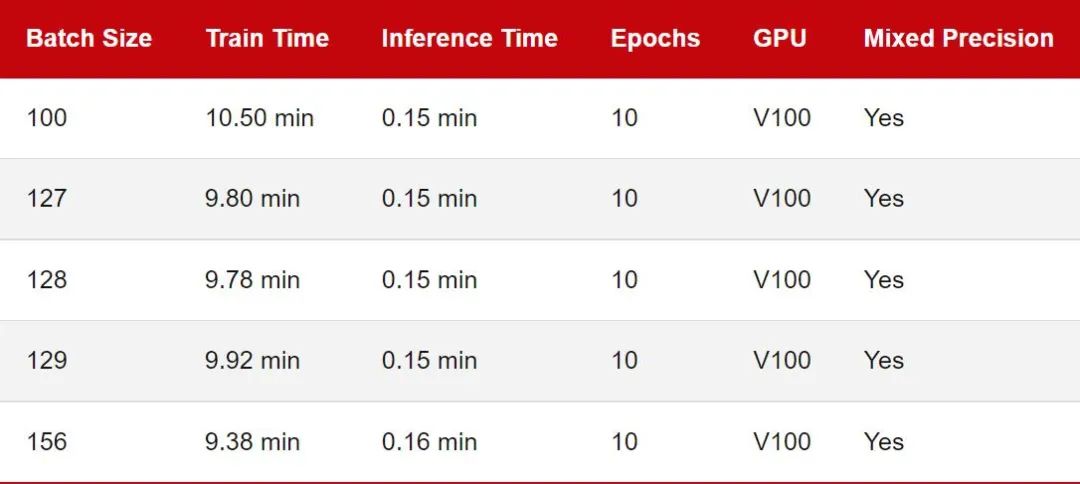
查看上表,讓我們將批大小 128 作為參考點(diǎn)。似乎將批量大小減少一 (127) 或?qū)⑴看笮≡黾右?(129) 確實(shí)會(huì)導(dǎo)致訓(xùn)練性能減慢。但這里的差異看來很小,我認(rèn)為可以忽略不計(jì)。
將批大小減少 28 (100) 會(huì)導(dǎo)致性能明顯下降。這可能是因?yàn)槟P同F(xiàn)在需要處理比以前更多的批次(50,000 / 100 = 500 對(duì)比 50,000 / 100 = 390)。可能出于類似的原因,當(dāng)我們將批大小增加 28 (156) 時(shí)就可以觀察到更快的訓(xùn)練時(shí)間。
最大 Batch Size 基準(zhǔn)
鑒于 MobileNetV3 架構(gòu)和輸入圖像大小,上一節(jié)中的批尺寸相對(duì)較小,因此 GPU 利用率約為 70%。為了研究 GPU 滿負(fù)荷時(shí)的訓(xùn)練時(shí)間差異,我將批量大小增加到 512,以使 GPU 顯示出接近 100% 的計(jì)算利用率:
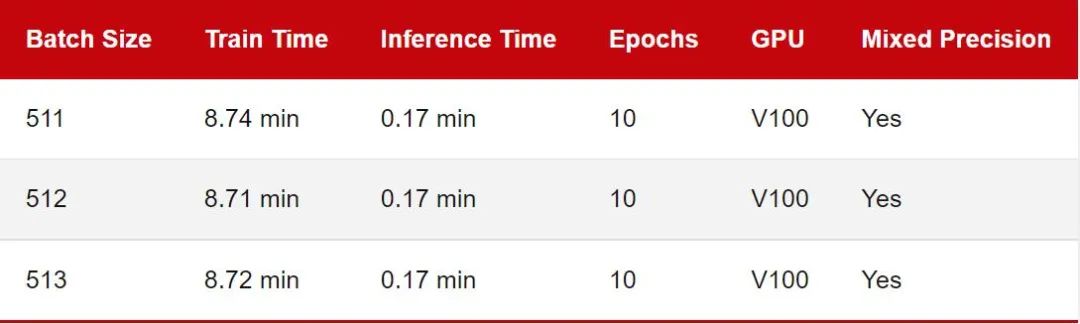
由于 GPU 內(nèi)存限制,批大小不可能超過 515。
同樣,正如我們之前看到的,作為 2 的冪(或 8 的倍數(shù))的批大小確實(shí)會(huì)產(chǎn)生很小但幾乎不明顯的差異。
多 GPU 訓(xùn)練
之前的基準(zhǔn)測試評(píng)估了單塊 GPU 上的訓(xùn)練性能。不過如今在多 GPU 上訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)更為常見。所以讓我們看看下面的多 GPU 訓(xùn)練的數(shù)字比較:
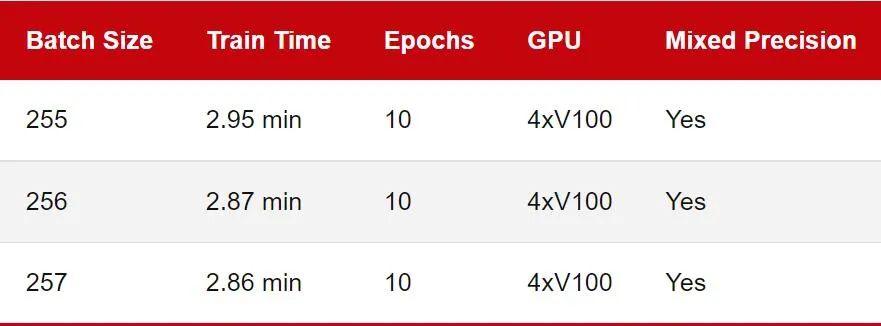
請(qǐng)注意,推理速度被省略了,因?yàn)樵趯?shí)踐中我們通常仍會(huì)使用單個(gè) GPU 進(jìn)行推理。此外,由于 GPU 的內(nèi)存限制,我無法運(yùn)行批處理大小為 512 的基準(zhǔn)測試,因此在這里降低到 256。
正如我們所看到的,這一次 2 的冪和 8 的倍數(shù)批量大小 (256) 并不比 257 快。在這里,我使用 DistributedDataParallel (DDP) 作為默認(rèn)的多 GPU 訓(xùn)練策略。你也可以使用不同的多 GPU 訓(xùn)練策略重復(fù)實(shí)驗(yàn)。GitHub 上的代碼支持 —strategy ddp_sharded (fairscale)、ddp_spawn、deepspeed 等。
基準(zhǔn)測試注意事項(xiàng)
這里需要強(qiáng)調(diào)的是上述所有基準(zhǔn)測試都有注意事項(xiàng)。例如我只運(yùn)行每個(gè)配置一次。理想情況下,我們希望多次重復(fù)這些運(yùn)行并報(bào)告平均值和標(biāo)準(zhǔn)偏差。(但這可能不會(huì)影響我們的結(jié)論,即性能沒有實(shí)質(zhì)性差異)
此外,雖然我在同一臺(tái)機(jī)器上運(yùn)行了所有基準(zhǔn)測試,但我以連續(xù)的順序運(yùn)行它們,運(yùn)行之間沒有很長的等待時(shí)間。因此這可能意味著基本 GPU 溫度在運(yùn)行之間可能有所不同,并且可能會(huì)對(duì)計(jì)時(shí)產(chǎn)生輕微影響。
我運(yùn)行基準(zhǔn)測試來模仿真實(shí)世界的用例,即在 PyTorch 中訓(xùn)練具有相對(duì)常見設(shè)置的現(xiàn)成架構(gòu)。然而,正如 Piotr Bialecki 正確指出的那樣,通過設(shè)置 torch.backends.cudnn.benchmark = True 可以稍微提高訓(xùn)練速度。
其他資源和討論
正如 Ross Wightman 所提到的,他也不認(rèn)為選擇批量大小作為 2 的冪會(huì)產(chǎn)生明顯的差異。但選擇 8 的倍數(shù)對(duì)于某些矩陣維度可能很重要。此外 Wightman 指出,在使用 TPU 時(shí)批量大小至關(guān)重要。(不幸的是,我無法輕松訪問 TPU,也沒有任何基準(zhǔn)比較)
如果你對(duì)其他 GPU 基準(zhǔn)測試感興趣,請(qǐng)?jiān)诖颂幉榭?Thomas Bierhance 的優(yōu)秀文章:https://wandb.ai/datenzauberai/Batch-Size-Testing/reports/Do-Batch-Sizes-Actually-Need-to-be-Powers-of-2---VmlldzoyMDkwNDQx
特別是你想要比較:
顯卡是否有 Tensor Core;
顯卡是否支持混合精度訓(xùn)練;
在像 DeiT 這樣的無卷積視覺轉(zhuǎn)換器。
Rémi Coulom-Kayufu 的一個(gè)有趣的實(shí)驗(yàn)表明,2 次方的批大小實(shí)際上很糟糕。看來對(duì)于卷積神經(jīng)網(wǎng)絡(luò),可以通過以下方式計(jì)算出較好的批大小:
Batch Size=int ((n×(1《《14)×SM)/(H×W×C))。
其中,n 是整數(shù),SM 是 GPU 內(nèi)核的數(shù)量(例如,V100 為 80,RTX 2080 Ti 為 68)。
結(jié)論
根據(jù)本文中共享的基準(zhǔn)測試結(jié)果,我不認(rèn)為選擇批大小作為 2 的冪或 8 的倍數(shù)在實(shí)踐中會(huì)產(chǎn)生明顯的差異。
然而,在任何給定的項(xiàng)目中,無論是研究基準(zhǔn)還是機(jī)器學(xué)習(xí)的實(shí)際應(yīng)用上,都已經(jīng)有很多旋鈕需要調(diào)整。因此,將批大小選擇為 2 的冪(即 64、128、256、512、1024 等)有助于使事情變得更加簡單和易于管理。此外,如果你對(duì)發(fā)表學(xué)術(shù)研究論文感興趣,將批大小選擇為 2 的冪將使結(jié)果看起來不像是刻意挑選好結(jié)果。
雖然堅(jiān)持批大小為 2 的冪有助于限制超參數(shù)搜索空間,但重要的是要強(qiáng)調(diào)批大小仍然是一個(gè)超參數(shù)。一些人認(rèn)為較小的批尺寸有助于泛化性能,而另一些人則建議盡可能增加批大小。
個(gè)人而言,我發(fā)現(xiàn)最佳批大小在很大程度上取決于神經(jīng)網(wǎng)絡(luò)架構(gòu)和損失函數(shù)。例如,在最近一個(gè)使用相同 ResNet 架構(gòu)的研究項(xiàng)目中,我發(fā)現(xiàn)最佳批大小可以在 16 到 256 之間,具體取決于損失函數(shù)。
因此,我建議始終考慮調(diào)整批大小作為超參數(shù)優(yōu)化搜索的一部分。但是,如果因?yàn)閮?nèi)存限制而不能使用 512 的批大小,則不必降到 256。有限考慮 500 的批大小是完全可行的。
原文標(biāo)題:一番實(shí)驗(yàn)后,有關(guān)Batch Size的玄學(xué)被打破了
文章出處:【微信公眾號(hào):OpenCV學(xué)堂】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4813瀏覽量
103383 -
存儲(chǔ)
+關(guān)注
關(guān)注
13文章
4527瀏覽量
87341 -
gpu
+關(guān)注
關(guān)注
28文章
4935瀏覽量
131076
原文標(biāo)題:一番實(shí)驗(yàn)后,有關(guān)Batch Size的玄學(xué)被打破了
文章出處:【微信號(hào):CVSCHOOL,微信公眾號(hào):OpenCV學(xué)堂】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
變頻器控制電機(jī)需要設(shè)置哪些參數(shù)
dlp2010更新flash時(shí),如圖Batch File 和Pattern File這兩個(gè)文件不知道輸入什么,在哪里找到?
使用DLPC3478+DLPA3005做了一款板子,修改了batch file關(guān)燈但是無效,怎么回事?
ADS1178轉(zhuǎn)換速率是否只與MODE有關(guān),與輸入時(shí)鐘無關(guān)?
中科芯CKS32K148 MCU SCG時(shí)鐘工作頻率范圍和寄存器設(shè)置
DAC81416電壓為什么達(dá)不到設(shè)定輸出范圍最大值?
電流速斷保護(hù)的保護(hù)范圍與什么有關(guān)
鋸齒波同步觸發(fā)電路移相范圍與哪些參數(shù)有關(guān)
放大電路的帶寬與什么有關(guān)
瀚海微SD NAND存儲(chǔ)功能描述(27)C_SIZE






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論