 GPU網絡中光互連的市場和產業趨勢、策略和計劃
GPU網絡中光互連的市場和產業趨勢、策略和計劃

摘要
GPU加速的計算系統可為諸多科學應用提供強大的計算能力支撐,亦是業界推動人工智能革命的重要手段。為了滿足大規模數據中心和高性能計算場景的帶寬拓展需求,光通信和光互連技術正在迅速而廣泛地滲入此類系統的各個網絡或鏈路層級。作為系列文章的第三篇,本文針對GPU網絡中光互連的市場和產業趨勢、策略和計劃做出分析。
在前兩篇大略地介紹了GPU網絡中光互連的歷史趨勢、短長期需求權衡、光通信技術手段之后,本篇將為讀者簡要分析其市場動向以及業界正在開展的進一步探索。
01
市場和產業動向:展望2025
與過去電信應用推進光互連的演變相類似,當前光互連的產業驅動力已經由數據通信應用(即數據中心)所主導。近幾年,隨著社交媒體、視頻數據流、智能手機的用戶數量不斷增長,人們對數據中心內部更高的網絡帶寬需求愈發迫切。為了應對諸如5G、云服務、物聯網、4K視頻等新興應用技術,全球數據中心的數量、占地面積、帶寬容量均有顯著增加。
上述現象在2016年最為明顯。彼時,全球數據中心的傳輸鏈路迎來了由40 Gbit/s到100 Gbit/s的大規模鏈路升級。自此以降,受到新數據中心的擴張建設、已有數據中心的翻新改裝、企業級數據中心的實際部署等因素的推動,光收發器的收益便以39%的復合年均增長率大幅增長[1]。而為了滿足數據中心應用對100 Gbit/s光模組的大批量需求,光收發器供應商的制造能力也得到了大幅提升。
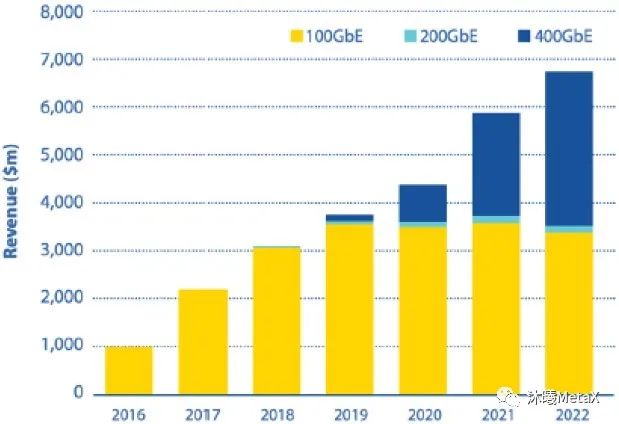
圖1. 100 G,200 G,400 G光收發器的總收益
(來源于參考資料[1])
占據設備連接總數目的最大一部分便是數據中心內部的服務器互連,而帶寬消耗的顯著增長則使得人們需要更多地去考慮光互連的成本效益問題。為了適應近期PAM4的廣泛使用和服務器速率由10 Gbit/s向著25 Gbit/s轉化,網絡的上行鏈路亦需增速。事實上,人們對容量提升的初始目標是引入400 Gbit/s的解決方案;而從成本和性能優化的角度考慮,業界在中途又加入了200 Gbit/s方案,以試圖為后續400 Gbit/s方案尋求一個更加適宜的遷移路徑。自2016年至2021年,光收發器總體(包括100 G,200 G,400 G)的復合年均增長率為63%;而僅就100 G光收發器而言,其復合年均增長率高達53%[2]。這主要是因為自2019年以來,200 G和400 G光收發器被商業化部署并開始小幅占據100 G光收發器的市場份額(見圖1)。
對于數據中心內部的短距離光互連來說,多模光纖鏈路仍要比單模光纖鏈路占據更為主要的地位。與傳統的串行傳輸有所不同,并行光路傳輸使用一個光模塊接口,數據在多根光纖中同時得以發送和接收:40 GbE傳輸由4根光纖之上的單方向4×10 G實現;100 GbE傳輸由10根光纖之上的單方向10×10 G實現。這類標準引領了對高質量、低損耗的多模多路并行光學(Multi-Parallel Optics, MPO)接口的需求。
人們對數據中心帶寬增長的不斷需求繼續驅動著業界的更多革新。以往,數據中心互連僅要求在多模或單模光纖中傳輸單個波長,而近期的技術驅動則聚焦在單模光纖中傳輸多個波長。2016年,與100 Gbit/s光收發器相符合的粗波分復用(Coarse Wavelength Division Multiplexing 4, CWDM4)技術已可以和并行單模(Parallel Single Mode 4, PSM4)在市場份額方面平分秋色。而隨著200 Gbit/s和400 Gbit/s自2019年開始的實際部署,市場容量的增長已經由并行光路技術和多波長技術共同驅動。
在2016年早期,眾多業界領軍者在多源協議方面合作開發了一種高速的雙密度四通道小型可插拔(Quad Small Form Factor Pluggable- Double Density, QSFP-DD)接口。作為可插拔收發器,QSFP-DD在保持占用空間以實現與標準QSFP的反向兼容之外,可為8通路的電接口附加提供的一排觸點。QSFP-DD 8個通路中的任意一個都可以在25 Gbit/s NRZ調制或50 Gbit/s PAM4調制下工作,從而可以為200 Gbit/s或400 Gbit/s的聚合帶寬提供支持;而QSFP-DD的反向兼容特點也可支撐新興模塊類型的使用、加速總體網絡遷移。
當前,標準的QSFP收發器模塊連接均已采用LC 雙工連接器(尤其是在基于波分復用的雙工模塊情形下)。盡管LC雙工連接器仍可在QSFP-DD收發器模塊中使用,但是傳輸帶寬還受限在單獨的波分復用引擎設計上。該引擎使用一個1:4復用/解復用器來達到200 GbE,或是使用一個1:8復用/解復用器來達到400 GbE。這無疑增加了收發器的成本,并且提高了對收發器的冷卻要求。

圖2. CS連接器和LC雙工連接器的比較
在保持連接器占用空間不變的前提下,人們期待能夠實現一種可將連接器與QSFP-DD之間的連接性提升一倍的新型連接器類型。于是,作為一種雙套管連接器,CS連接器應運而生。如圖2所示,和LC雙工連接器相比較,CS連接器的占用空間相對更小。于是,人們可在一個QSFP-DD模塊的前接口部署兩個CS連接器。這使得雙波分復用引擎具有了較好的可行性:該雙引擎可使用一個1:4復用/解復用器來達到2×100 GbE,或是在一個單獨的QSFP-DD收發器上實現2×200 GbE。除了QSFP-DD收發器之外,CS連接器亦可與八通道小型可插拔模塊和板中光學模塊相適配。
在眾多供應商采用QSDP-DD作為收發器接口的時候,網絡交換面板密度也在成倍增加。自2012年以來,數據中心交換機的最大網絡交換面板密度是128個單通道(信道)端口或32個4通道端口。近期,網絡交換機ASIC供應商已能夠將單個交換ASIC的信道數目提升到256個乃至512個。在保持單個機架單位交換機面板形狀系數的同時,為了有效管理不斷增長的帶寬密度,人們在若干類多源協議(包括QSFP-DD,OSFP,SFP-DD)中采用了雙倍密度的光收發器。由此,光纖數目也已經由4通道增長到了8通道、乃至于提升至8對光纖。而為了保持和已安裝的光纖和網絡交換機基礎設備的兼容性,在上述收發器的實際部署中,人們可將8通道分開為2個獨立的四路接口。當新型交換器得以實際部署時,數據中心的短期需求便是在同樣物理空間之內的光纖對終端數量的增加。
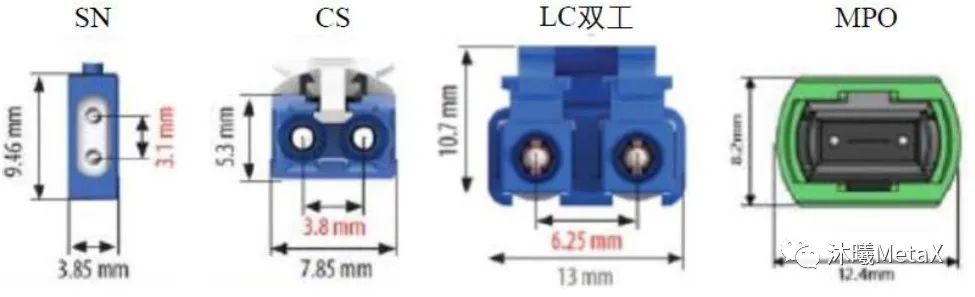
圖3. SN、CS、LC雙工和MPO的比較
上述需求又反過來促使業界人士去探尋進一步的革新:如圖3所示,與CS連接器將LC連接器的密度增加一倍相類似,SN連接器又將CS連接器的密度增加了一倍。

圖4. 在葉和脊結構中使用SN接口實現光纖分線
如圖4所示,SN連接器是一種面向400 G數據中心優化方案的新型雙工光纖連接器,其設計初衷是為四路方式收發器(QSFP,QSFP-DD,OSFP)提供獨立的雙工光纖分線。與MPO連接器相比較,SN連接器的效率和可靠性較高、成本較低。

圖5. 未來光互連技術的演進
自2018年的Optical Fiber Communication Conference開始,市場分析師和技術專家便對將光互連部件移動到距離ASIC更近位置的必要性開展了廣泛討論。而早在2017年,the Consortium for On-Board Optics已針對板上光學發布了第一部工業指標規范[3]。這些技術布局的關鍵推動力就是高數據速率條件下銅線互連的固有限制。隨著數據速率的上升,銅線的衰減大幅增加且其絕對傳輸限制被限定在100 Gbp/s/m[4]。而對高于這一限制的速率來說,使用光學信道便成了無法避免的技術手段。因此,光互連產業的演進并不僅限于板上光學,也包括了用于替代傳統集成電路的光子集成光路(Photonic Integrated Circuits, PIC)。如圖5所示,光互連下一步的演進既要滿足前面板互連器件的需求,又要更多考慮PIC、板中和背板的互連器需求。
02
策略和計劃:跨越成本和功耗之墻
在節點性能借助多芯片組件和GPU加速器等特殊計算單元來實現提升的同時,人們不僅對數據中心網絡的帶寬需求仍在持續,而且對人工智能和高性能計算的工作負載需求也呈現出激增態勢。而通過增加單通道數據速率的傳統方式已不再是獲取效益的唯一辦法。這是因為功效增益已有平緩化趨勢,且低成本的電學鏈路已無法覆蓋當前的互連傳輸距離。舉例來說,在12.8 Tbit/s(2016)和102.4 Tbit/s(~2025)這兩代交換芯片之間,光互連占據網絡功率的比例將從約30%增長為超過50% [5];而對數據中心整體而言,光網絡占比將會從10 Gbit/s以太網代際(2015)中的幾個百分比增長為800 Gbit/s代際(~2025)中的20%以上[6]。此外,光學成本在不久的將來便會超越交換機端口的成本[5]。為了應對這不斷逼近的成本和功耗之墻,人們需要從新型網絡結構、共封裝光學等角度來尋求一系列解決方案。在下文中,筆者將對這些方案逐一做出簡短分析。
2.1
更加扁平化的網絡
更加扁平化的網絡意味著具備高通道數目的交換機得以使用,從而減少了交換層級。由此,人們可大幅減少交換機部件的數量并改進系統的總體吞吐量和延遲性能。而更高的端口數目可以通過使用尖端的單芯片交換機(已接近50 Tbit/s及以上)或者復合芯片配置實現。因為未來的交換芯片可具有超越單個機架所需的交換能力,所以拓撲結構應包括使用行間(End of Row)交換機來替代機架頂端(Top of Rack)交換機。
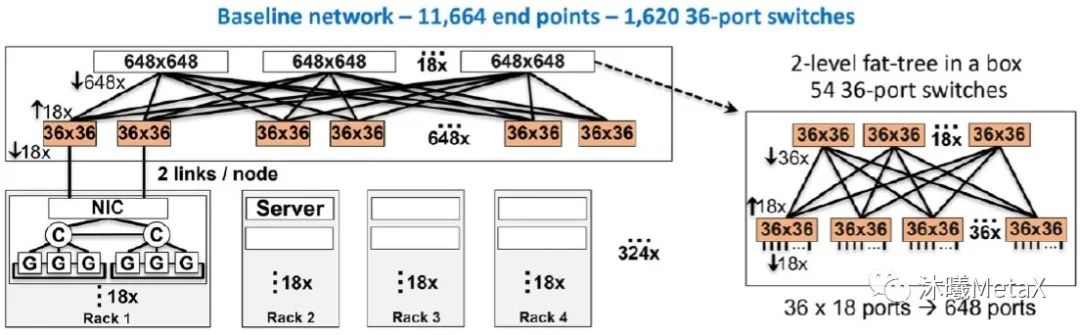
圖6. 由36端口交換芯片所構成的基準網絡
(來源于參考資料[7])
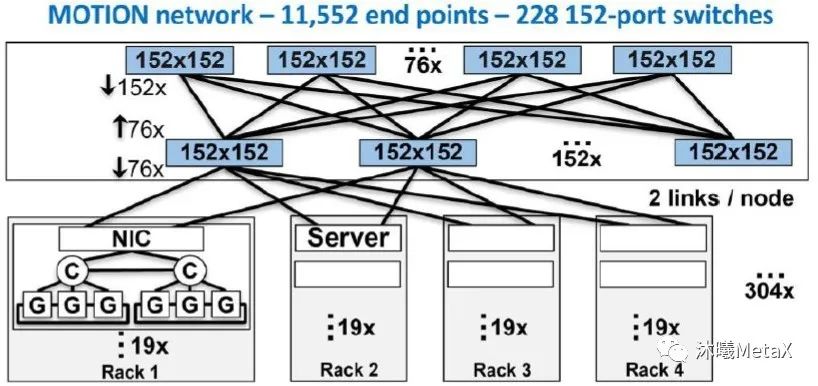
圖7. 使用162端口交換芯片的扁平化網絡
(來源于參考資料[7])
近期,IBM公司的P. Maniotis等[7]對使用高通道數目交換機(借助低功率的共封裝光學)實現更加扁平化網絡的優勢做出了詳細討論。圖6展示了一個由“當今的”36端口單芯片交換機所構成的高性能計算規模網絡(包含11600個終端);而圖7展示了一個由152端口交換芯片所構成的類似規模網絡。相較而言,更加扁平化的網絡可令交換芯片的數量減少85%,可大幅降低功耗和成本。
2.2
專門的硬件和網絡
盡管多樣化的工作負載可為數據中心定義一個更具通用性的網絡和計算資源基礎結構,但是在高性能計算領域,人們卻一直對優化的網絡拓撲結構(如用于科學計算的環形拓撲結構、用于圖形分析的蜻蜓拓撲結構)頗感興趣。
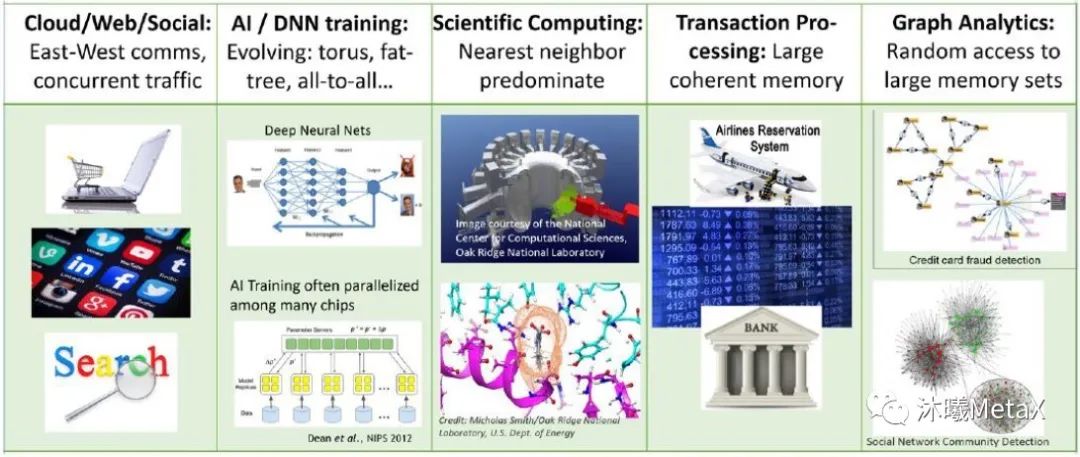
圖8. 對網絡工作負載需求的示例
(來源于參考資料[8])
圖8展示了各式各樣工作負載類型的需求范圍。隨著特定工作負載的重要性不斷增加,針對特定任務(如人工智能訓練)來制定專門的計算和網絡設計將會是業界的一個關鍵考慮。
2.3
組合式/解聚式系統
針對特定的工作負載需求來構建資源是眾多數據中心設計者夢寐以求的能力。組合式/解聚式系統意味著人們可以使用高性能結構來改進數據中心的總體效率。其潛在的優勢包括:硬件可具備獨立的恢復周期、用于特定工作負載的資源優化分派更具靈活性、更容易添加新的資源形態(如新型加速器)、有效降低運行成本和資本支出等。
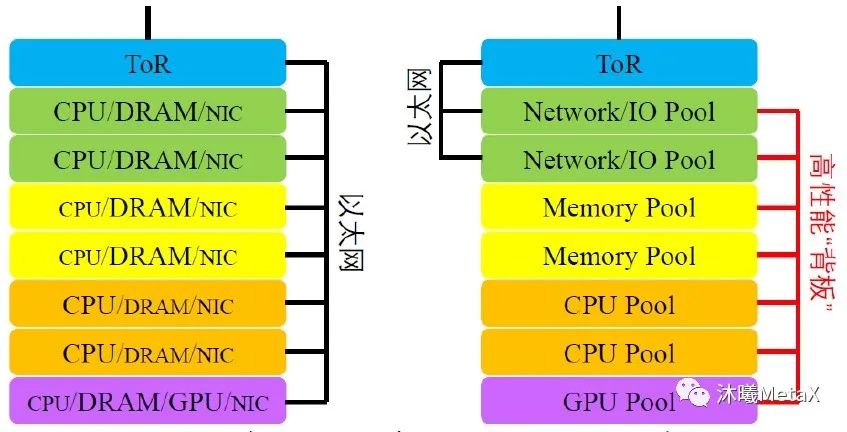
圖9. 當今異構結構和未來組合式結構的概念示意圖
圖9為異構結構和組合式結構的概念示意圖。其中,Compute Express Link[9]可為存儲器和加速器解聚提供支持。在總線和接口標準(Peripheral Component Interface Express, PCIe)物理層以及給定的數據速率條件下,光互連(在跨越機架或多機架距離的高速場景中)的一個關鍵問題便是PCIe Gen 6中64 Gbit/s和大量以太網應用中53-56 Gbit/s 或106-112 Gbit/s之間的失配特性。
2.4
物理層效率和共封裝光學
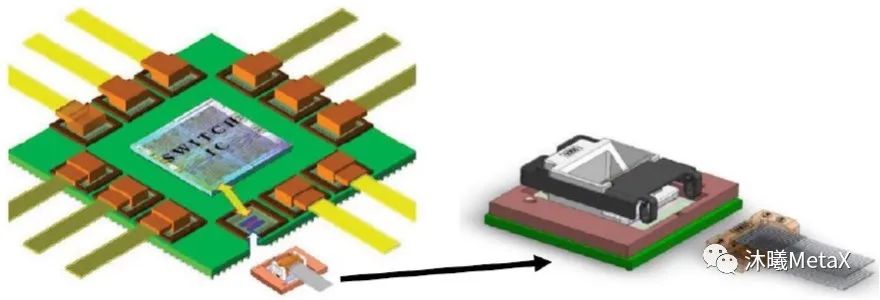
圖10. 基于垂直腔面發射激光器的共封裝光學概念
(來源于參考資料[7])
在持續的CMOS代際和改進的電路設計基礎上,電學鏈路依舊能夠在功率效率方面獲得收效。然而,在更高的數據速率需求下,電學鏈路中不可避免的高信道衰減使得人們對利用光學鏈路滿足傳輸距離的需求顯著增多。共封裝技術可使得電學鏈路的傳輸距離大幅減小,在功耗和信號一致性方面有著明顯優勢。它可為功耗低于5 pJ/bit的完整電-光-電鏈路(例如IBM公司正在開展的MOTIO2項目[10])提供潛在可能性。如圖10所示,該項目基于垂直腔面發射激光器的共封裝模塊技術,旨在實現低成本、高性能(112 Gbit/s,< $0.25/Gbps)傳輸。
03
小結
基于新技術標準化的重要性,許多標準化組織、產業聯盟和政府研究機構已開始著手制定未來光互連的各類技術規范。而為了跨越GPU網絡光互連的成本和功耗之墻,業界也正在探索諸如更加有效的網絡拓撲結構、針對特定工作負載的計算和網絡結構、光電共封裝等解決方案。以筆者觀察,這些方案可為滿足未來數據中心的高帶寬需求提供有效幫助。
倘若讀者對GPU網絡的光互連這一領域有著獨特興趣,歡迎你關注、走近沐曦,讓我們一起釋放和安頓這份好奇心以及追根究底的脾氣。
審核編輯 :李倩
-
gpu
+關注
關注
28文章
4935瀏覽量
131068 -
網絡
+關注
關注
14文章
7804瀏覽量
90760 -
模組
+關注
關注
6文章
1629瀏覽量
31307
原文標題:【智算芯聞】面向GPU網絡的光互連(3):凡是過去,皆為序章
文章出處:【微信號:沐曦MetaX,微信公眾號:沐曦MetaX】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
TE推出AMPMODU互連系統具有哪些產品特性?-赫聯電子
華為智能光伏第三屆全球安裝商大會圓滿收官
AI驅動的高速互連趨勢下,如何實現超前布局?

OpenVINO?檢測到GPU,但網絡無法加載到GPU插件,為什么?
半導體封裝革新之路:互連工藝的升級與變革

TE推出AMPMODU互連系統是什么?哪家有?-赫聯電子
華為發布2025充電網絡產業十大趨勢
華為發布2025充電網絡產業十大趨勢
華為發布2025智能光伏十大趨勢
未來網絡的高速引擎:800G光模塊市場預測與應用前景
GPU服務器AI網絡架構設計






 工商網監
工商網監
評論