 NVIDIA Triton推理服務器的功能與架構簡介
NVIDIA Triton推理服務器的功能與架構簡介

前面文章介紹微軟 Teams 會議系統、微信軟件與騰訊 PCG 服務三個 Triton 推理服務器的成功案例,讓大家對 Triton 有初步的認知,但別誤以為這個軟件只適合在大型的服務類應用中使用,事實上 Triton 能適用于更廣泛的推理環節中,并且在越復雜的應用環境中就越能展現其執行成效。
在說明 Triton 推理服務器的架構與功能之前,我們需要先了解一個推理服務器所需要面對并解決的問題。
與大部分的服務器軟件所需要的基本功能類似,一個推理服務器也得接受來自不同用戶端所提出的各種要求(request)然后做出回應(response),并且對系統的處理進行性能優化與穩定性管理。
但是推理計算需要面對深度學習領域的各式各樣推理模型,包括圖像分類、物件檢測、語義分析、語音識別等不同應用類別,每種類別還有不同神經網絡算法與不同框架所訓練出來的模型格式等。此外,我們不能對任務進行單純的串行隊列(queue)方式處理,這會使得任務等待時間拖得很長,影響使用的體驗感,因此必須對任務進行并行化處理,這里就存在非常復雜的任務管理技巧。
下面列出一個推理服務器所需要面對的技術問題:
1.支持多種模型格式:至少需要支持普及度最高的
2.TensorFlow 的 GraphDef 與 SavedMode 中一種以上格式
(1) PyTorch 的 TorchScript 格式
(2) ONNX 開放標準格式
(3) 其他:包括自定義模型格式
3.支持多種查詢類型,包括
(1) 在線的實時查詢:盡量降低查詢的延遲(latency)時間
(2) 離線的批量處理:盡量提高查詢的通量(throughput)
(3) 流水線傳輸的識別號管理等工作
4.支持多種部署方式:包括
(2) 公共云或數據中心
5.對模型進行最佳縮放處理:讓個別模型提供更好的性能
6.優化多個 KPI:包括
(1) 硬件利用率
(2) 模型推理識別時間
(3) 總體成本(TCO)
7.提高系統穩定性:需監控模型狀態并解決問題以防止停機
在了解推理服務器所需要解決的關鍵問題之后,接著來看看下方的 Triton 系統高階架構圖,就能更清楚每個板塊所負責的任務與使用的對應技術。
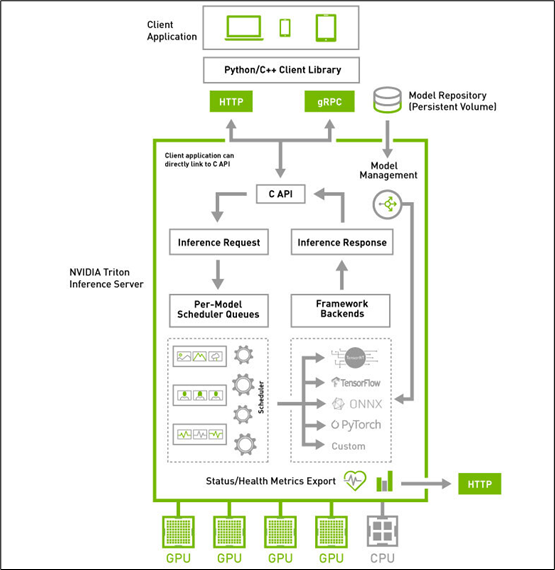
Triton 推理服務器采用屬于 “主從(client-server)” 架構的系統,由圖中的四個板塊所組成:
1.模型倉(Model Repostory):存放 Triton 服務器所要使用的模型文件與配置文件的存儲設備,可以是本地服務器的文件系統,也可以使用 Google、AWS、Azure 等云存儲空間,只要遵循 Triton 服務器所要求的規范就可以;
2.客戶端應用(Client Application):基于 Triton 用戶端 Python / C++ / Java 庫所撰寫,可以在各種操作系統與 CPU 架構上操作,對 Triton 服務器提交任務請求,并且接受返回的計算結果。這是整個 Triton 推理應用中代碼量最多的一部分,也是開發人員需要花費最多心思的部分,在后面會有專文講解。
3.HTTP / gPRC 通訊協議:作為用戶端與服務端互動的通訊協議,開發人員可以根據實際狀況選擇其中一種通訊協議進行操作,能透過互聯網對服務器提出推理請求并返回推理結果,如下圖所示:
使用這類通訊協議有以下優點:
(1)支持實時、批處理和流式推理查詢,以獲得最佳應用程序體驗
(2)提供高吞吐量推理,同時使用動態批處理和并發模型執行來滿足緊張的延遲預算
(3)模型可以在現場制作中更新,而不會中斷應用程序
4.推理服務器(Inference Server):這是整個 Triton 服務器最核心且最復雜的部分,特別在 “性能”、“穩定”、“擴充” 這三大要求之間取得平衡的管理,主要包括以下幾大功能板塊:
(1) C 開發接口:
在服務器內的代碼屬于系統底層機制,主要由 NVIDIA 系統工程師進行維護,因此只提供性能較好的 C 開發接口,一般應用工程師可以忽略這部分,除非您有心深入 Triton 系統底層進行改寫。
(2) 模型管理器(Model Management):
支持多框架的文件格式并提供自定義的擴充能力,目前已支持 TensorFlow 的 GraphDef 與 SavedModel 格式、ONNX、PyTorch TorchScript、TensorRT、用于基于樹的 RAPIDS FIL 模型、OpenVINO 等模型文件格式,還能使用自定義的 Python / C++ 模型格式;
(3) 模型的推理隊列調度器(Per-Model Scheduler Queues):
將推理模型用管道形式進行管理,將一個或多個模型的預處理或后處理進行邏輯排列,并管理模型之間的輸入和輸出張量的連接,任何的推理請求都會觸發這個模型管道。這部分還包含以下兩個重點:
并發模型執行(Concurrent Model Execution):允許同一模型的多個模型和 / 或多個實例在同一系統上并行執行,系統可能有零個、一個或多個 GPU。
模型和調度程序(Models And Schedulers):支持多種調度和批量處理算法,可為每個模型單獨選擇無狀態(stateless)、有狀態(stateful)或集成(ensemble)模式。對于給定的模型,調度器的選擇和配置是通過模型的配置文件完成的。
(4) 計算資源的優化處理:
這是作為服務器軟件的最重要工作之一,就是要將設備的計算資源充分調度,并且優化總體計算性能,主要使用以下三種技術。
支持異構計算模式:可部署在純 x86 與 ARM CPU 的計算設備上,也支持裝載 NVIDIA GPU 的計算設備。
動態批量處理(Dynamic batching)技術:對支持批處理的模型提供多個內置的調度和批處理算法,并結合各個推理請求以提高推理吞吐量,這些調度和批量處理決策對請求推理的客戶端是透明的。
批量處理推理請求分為客戶端批量處理和服務器批量處理兩種,通過將單個推理請求組合在一起來實現服務器批處理,以提高推理吞吐量;
構建一個批量處理緩存區,當達到配置的延遲閾值后便啟動處理機制;
調度和批處理決策對請求推斷的客戶機是透明的,并且根據模型進行配置。
c.并發模型(Concurrent model)運行:多個模型或同一模型的多個實例,可以同時在一個 GPU 或多個 GPU 上運行,以滿足不同的模型管理需求。
(5) 框架后端管理器(Framework Backends):
Triton 的后端就是執行模型的封裝代碼,每種支持的框架都有一個對應的后端作為支持,例如 tensorrt_backend 就是支持 TensorRT 模型推理所封裝的后端、openvino_backend 就是支持 openvine 模型推理所封裝的后端,目前在 Triton 開源項目里已經提供大約 15 種后端,技術人員可以根據開發無限擴充。
要添加一個新的后臺是相當復雜的過程,因此在本系列文章中并不探索,這里主要說明以下 Triton 服務器對各個后端的管理機制,主要是以下重點:
采用 KFServing 的新社區標準 gRPC 和 HTTP/REST 數據平面(data plane)v2 協議(如下圖),這是 Kubernetes 上基于各種標準的無服務器推理架構
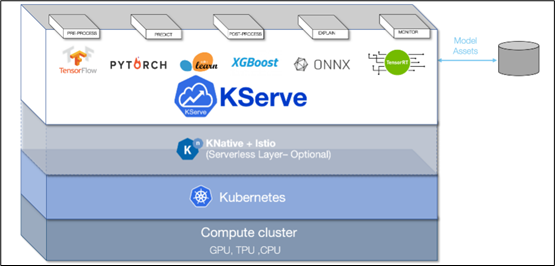
通過配置自動化和自動擴展簡化 Kubernetes 中的推理服務部署
透明地處理負載峰值,即使請求數量顯著增加,請求的服務也將繼續順利運行
可以通過定義轉換器,輕松地將標記化和后處理等預處理步驟包含在部署中
可以用 NGC 的 Helm 命令在 Kubernetes 中部署 Triton,也可以部署為容器微服務,為 GPU 和 CPU 上的預處理或后處理和深度學習模型提供服務,也能輕松部署在數據中心或云平臺上
將推理實例進行微服務處理,每個實例都可以在 Kubernetes 環境中獨立擴展,以獲得最佳性能
通過這種新的集成,可以輕松地在 Kubernetes 使用 Triton 部署高性能推理
以上是 Triton 推理服務器的高級框架與主要特性的簡介,如果看完本文后仍感覺有許多不太理解的部分,這是正常的現象,因為整個 Triton 系統集成非常多最先進的技術在內,并非朝夕之間就能掌握的。
后面的內容就要進入 Triton 推理服務器的環境安裝與調試,以及一些基礎范例的執行環節,透過這些實際的操作,逐步體驗 Triton 系統的強大。
審核編輯:湯梓紅
-
NVIDIA
+關注
關注
14文章
5283瀏覽量
106106 -
服務器
+關注
關注
13文章
9758瀏覽量
87629 -
Triton
+關注
關注
0文章
28瀏覽量
7154
原文標題:NVIDIA Triton系列文章(2):功能與架構簡介
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
使用NVIDIA Triton和TensorRT-LLM部署TTS應用的最佳實踐

基于RAKsmart云服務器的AI大模型實時推理方案設計
AI 推理服務器都有什么?2025年服務器品牌排行TOP10與選購技巧

國產推理服務器如何選擇?深度解析選型指南與華頡科技實戰案例

英偉達GTC25亮點:NVIDIA Dynamo開源庫加速并擴展AI推理模型
Triton編譯器的優化技巧
Triton編譯器功能介紹 Triton編譯器使用教程
GPU服務器AI網絡架構設計






 工商網監
工商網監
評論