") 王井東:大模型已經(jīng)成為自動(dòng)駕駛能力提升核心驅(qū)動(dòng)力
王井東:大模型已經(jīng)成為自動(dòng)駕駛能力提升核心驅(qū)動(dòng)力

百度Apollo Day技術(shù)開(kāi)放日
2022年11月29日,百度Apollo Day技術(shù)開(kāi)放日活動(dòng)線上舉辦。百度自動(dòng)駕駛技術(shù)專(zhuān)家全景化展示Apollo技術(shù)實(shí)力及前沿技術(shù)理念,在業(yè)內(nèi)首發(fā)文心大模型落地應(yīng)用于自動(dòng)駕駛的技術(shù)。
大模型技術(shù)是自動(dòng)駕駛行業(yè)近年的熱議趨勢(shì),但能否落地應(yīng)用、能否用好是關(guān)鍵難題。百度自動(dòng)駕駛依托文心大模型特色優(yōu)勢(shì),率先實(shí)現(xiàn)技術(shù)應(yīng)用突破。百度自動(dòng)駕駛技術(shù)專(zhuān)家王井東表示:文心大模型-圖文弱監(jiān)督預(yù)訓(xùn)練模型,背靠文心圖文大模型數(shù)千種物體識(shí)別能力,大幅擴(kuò)充自動(dòng)駕駛語(yǔ)義識(shí)別數(shù)據(jù),如:特殊車(chē)輛(消防車(chē)、救護(hù)車(chē))識(shí)別、塑料袋等,自動(dòng)駕駛長(zhǎng)尾問(wèn)題解決效率指數(shù)級(jí)提升;此外,得益于文心大模型-自動(dòng)駕駛感知模型10億以上參數(shù)規(guī)模,通過(guò)大模型訓(xùn)練小模型,自動(dòng)駕駛感知泛化能力顯著增強(qiáng)。
以下為演講全文
大家好,我是王井東,由我跟大家分享自動(dòng)駕駛感知相關(guān)的內(nèi)容,我演講的標(biāo)題是:文心大模型在自動(dòng)駕駛感知中的落地應(yīng)用。
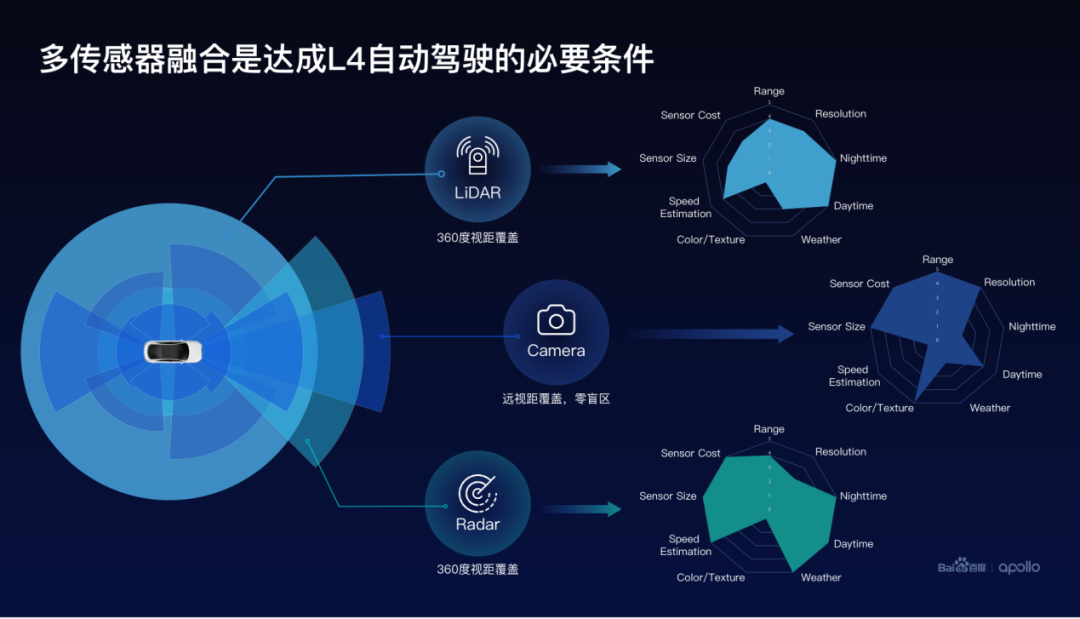
百度認(rèn)為傳感器融合是實(shí)現(xiàn)L4自動(dòng)駕駛的必要條件,激光點(diǎn)云、毫米波雷達(dá)和攝像頭這三種傳感器是如何實(shí)現(xiàn)互補(bǔ)關(guān)系的。激光點(diǎn)云和毫米波雷達(dá)點(diǎn)云不能夠提供很豐富的顏色信息和紋理信息,使得點(diǎn)云的識(shí)別效果一般。攝像頭可以提供豐富的顏色紋理等信息,能夠幫助提升語(yǔ)義識(shí)別的效果。
那激光點(diǎn)云和攝像頭在天氣不佳的條件下,如雨雪天氣,感知效果受到限制,這個(gè)時(shí)候毫米波雷達(dá)點(diǎn)云仍然能夠提供很好的效果,那毫米波雷達(dá)點(diǎn)云相對(duì)而言噪聲比較大,分辨率比較低,這個(gè)時(shí)候雷達(dá)和攝像頭提供了分辨率非常高的互補(bǔ)信息。
除此以外,攝像頭相對(duì)遠(yuǎn)距離的感知效果比較友好。
百度自動(dòng)駕駛感知經(jīng)歷了兩代,第一代感知1.0,在感知1.0經(jīng)過(guò)了三個(gè)階段:
第一階段
主要依賴(lài)激光雷達(dá)點(diǎn)云感知,輔助紅綠燈的識(shí)別,同時(shí)利用了毫米波目標(biāo)陣列。
第二階段
增加了環(huán)視圖像的感知,與激光雷達(dá)點(diǎn)云感知形成了兩層的感知融合,提升了識(shí)別效果。
第三階段
自研了毫米波點(diǎn)云感知算法,形成了三層感知的融合,那這些多模感知實(shí)際上用的是后融合的方案。
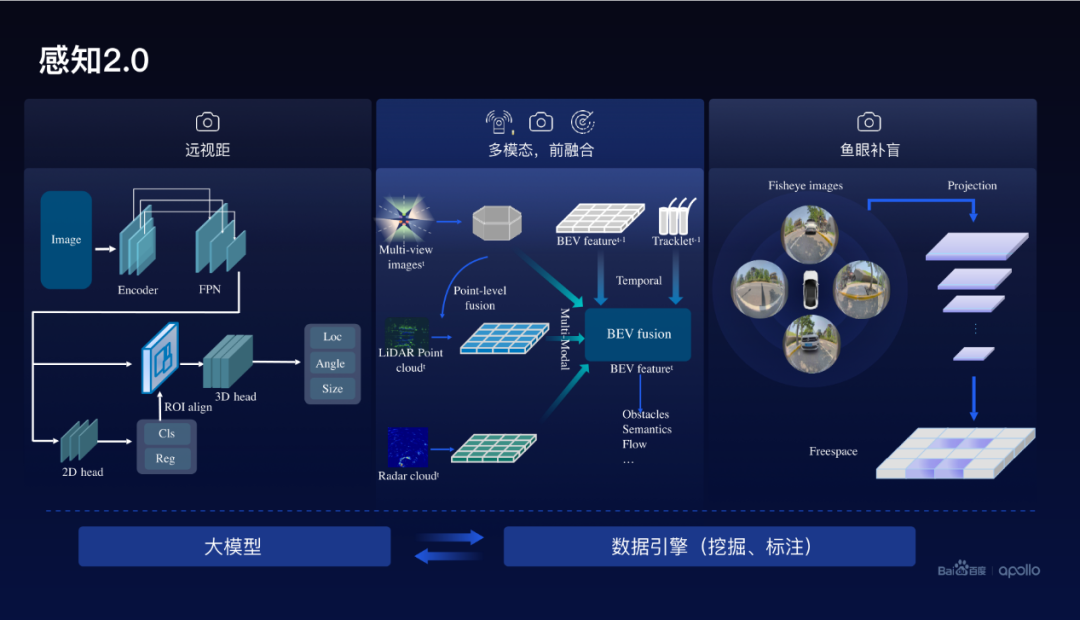
在后融合方案里面通常需要規(guī)則的方法,把這三種傳感器的感知結(jié)果融合在一起,那這種基于規(guī)則的方法是不可學(xué)習(xí)的,它相對(duì)而言它的泛化能力不夠。基于此,百度開(kāi)發(fā)了基于前融合方案的新一代感知2.0。

感知2.0主要的一個(gè)部分是多模態(tài)前融合端到端的方案,在點(diǎn)云和圖像的表征層次上進(jìn)行融合。除此以外,還包括遠(yuǎn)視距的視覺(jué)感知,通常在200米以上視覺(jué)的感知效果相對(duì)比較好。
另外,在近距離采用了魚(yú)眼感知,從魚(yú)眼感知實(shí)現(xiàn)了freespace的預(yù)測(cè),百度把這三者有機(jī)的融合在一起,實(shí)現(xiàn)了近距離、中等距離和遠(yuǎn)距離統(tǒng)統(tǒng)形成高質(zhì)量的這種感知。
在做感知時(shí)候,需要豐富的數(shù)據(jù)、高質(zhì)量的數(shù)據(jù),基于此,百度在2.0還利用大模型進(jìn)行數(shù)據(jù)挖掘和數(shù)據(jù)的自動(dòng)標(biāo)注。
下面看幾個(gè)例子,看看在自動(dòng)駕駛感知里面遇到的一些挑戰(zhàn)。
首先遠(yuǎn)距離的視覺(jué)感知,在較遠(yuǎn)的地方,物體看起來(lái)是比較小的,分辨率是比較低的,這對(duì)識(shí)別和感知帶來(lái)非常大的挑戰(zhàn)。那在遠(yuǎn)距離的情況下面,通常會(huì)遇到坡度比較大,對(duì)于感知也是非常大的挑戰(zhàn)。大部分的數(shù)據(jù)都是地平面的,道路是平的,那這里面往往會(huì)利用了地平面接地這樣一個(gè)重要的性質(zhì),去實(shí)現(xiàn)遠(yuǎn)距離物體的感知。

下面再看看第二個(gè)挑戰(zhàn),因?yàn)槲覀儾捎玫募す饫走_(dá)傳感器不斷的升級(jí),那點(diǎn)云的空間分布也產(chǎn)生了非常大的變化,在早先激光雷達(dá)傳感器基于威力登,后來(lái)我們升級(jí)為兩種型號(hào)的禾賽,目前正在考慮啟用半固態(tài)的傳感器,這些傳感器升級(jí)帶來(lái)了點(diǎn)云空間的分布的變化,從原來(lái)的稀疏到現(xiàn)在的稠密,在點(diǎn)云空間去做3D的標(biāo)注是非常困難的,能不能把以前舊的傳感器的標(biāo)注在新的傳感器能很好利用起來(lái),也成為技術(shù)上的一個(gè)重要挑戰(zhàn)。

下面是長(zhǎng)尾數(shù)據(jù)挖掘的問(wèn)題,這里面舉了三類(lèi)典型的例子:
第一類(lèi)是少見(jiàn)的車(chē)型,比如說(shuō)異形車(chē)出現(xiàn)的頻率比較低,通常這種異型車(chē)它的形態(tài)、形狀不太規(guī)則,甚至有時(shí)候會(huì)有一些突出的部件,那這個(gè)時(shí)候會(huì)為感知、理解帶來(lái)挑戰(zhàn),很難很好地定位這些異形車(chē)的空間位置以及距離。
第二類(lèi)是各種形態(tài)、各種姿態(tài)的行人,這個(gè)時(shí)候可能是一群人在道路上面,這樣會(huì)帶來(lái)非常大的挑戰(zhàn),同時(shí)也為后面的預(yù)測(cè)跟蹤帶來(lái)很大的挑戰(zhàn)。
第三類(lèi)是低矮物體以及交通、施工的元素,那低矮物體一直是感知里面非常有挑戰(zhàn)的問(wèn)題,那我們?cè)趯?shí)踐過(guò)程里面你會(huì)發(fā)現(xiàn)一些施工元素會(huì)對(duì)我們自動(dòng)駕駛感知帶來(lái)一些問(wèn)題,比如說(shuō)道路中間的護(hù)欄,其實(shí)往往意味著這條路可能是不可通行的,那我們需要識(shí)別這樣的道路施工元素。

那如何解決剛才提到的這三種挑戰(zhàn)呢?百度利用了大模型技術(shù)來(lái)提升自動(dòng)駕駛感知的能力,從兩個(gè)方面去解決這個(gè)自動(dòng)駕駛感知遇到的挑戰(zhàn)。
第一個(gè),利用文心大模型自動(dòng)駕駛感知的技術(shù),來(lái)提升車(chē)載小模型的感知能力,另外,在數(shù)據(jù)方面,利用了文心大模型圖像弱監(jiān)督預(yù)訓(xùn)練的模型來(lái)挖掘長(zhǎng)尾數(shù)據(jù),來(lái)提升模型訓(xùn)練的效果。

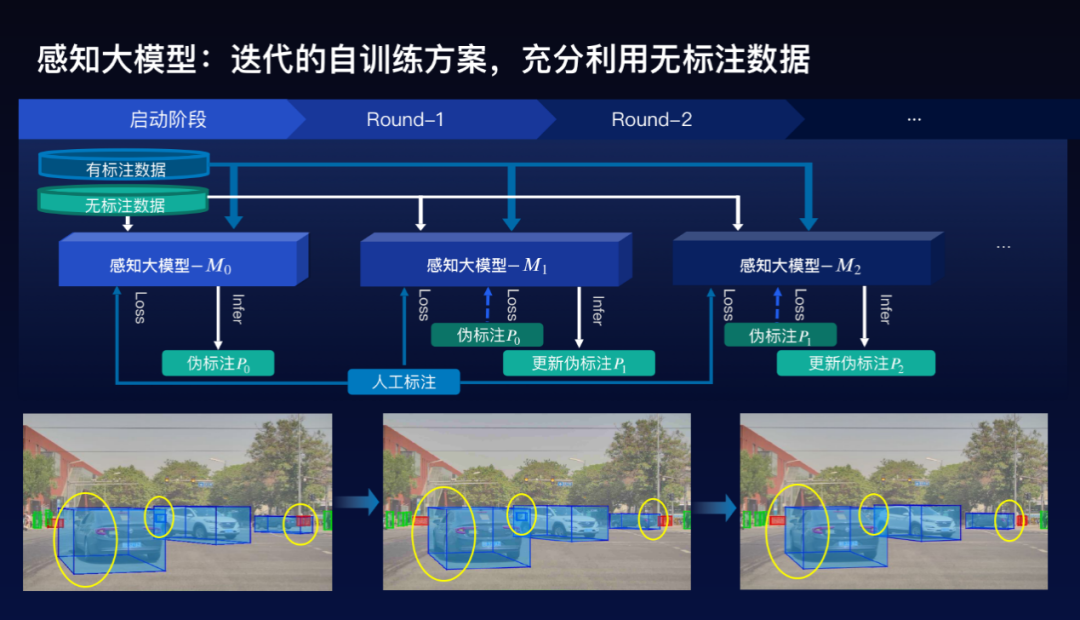
這個(gè)自動(dòng)駕駛感知大模型是怎么訓(xùn)練的。在自動(dòng)駕駛感知里面,需要標(biāo)注大量的數(shù)據(jù),但是在這里面,往往相對(duì)而言容易獲得千萬(wàn)量級(jí)的2D的標(biāo)注數(shù)據(jù),但對(duì)3D的標(biāo)注數(shù)據(jù)來(lái)講相對(duì)比較困難,如何利用這些沒(méi)有3D標(biāo)注的數(shù)據(jù)是成為一個(gè)很大的挑戰(zhàn),百度采用半監(jiān)督的方法來(lái)充分利用2D的標(biāo)注和沒(méi)有3D標(biāo)注的數(shù)據(jù)。
具體方案是采用迭代的自訓(xùn)練方案。首先是在既有2D又有3D的訓(xùn)練數(shù)據(jù)上面,去訓(xùn)練一個(gè)感知大模型,給那些沒(méi)有3D標(biāo)注的數(shù)據(jù)打上3D偽標(biāo)注。然后再繼續(xù)訓(xùn)練一個(gè)感知大模型出來(lái),如此迭代,逐步把感知大模型的效果提升,同時(shí)也使得3D尾標(biāo)注的效果越來(lái)越好,可以看到下面的三個(gè)圖的例子,結(jié)果實(shí)際上是變得越來(lái)越好。
這樣的一個(gè)感知大模型,不僅用于視覺(jué),也用于點(diǎn)云,也用于我們后面要講的多模態(tài)端到端的方案。
在這個(gè)遠(yuǎn)視覺(jué)感知方案里面,實(shí)際上也利用了編碼器和解碼器的預(yù)訓(xùn)練方案,利用了公開(kāi)的數(shù)據(jù)集Object 365和COCO這樣的預(yù)訓(xùn)練。
那這里要提一下的是,百度基于這么一個(gè)編碼器和解碼器預(yù)訓(xùn)練的方案,采用的方法Group DETR v2,實(shí)際上在標(biāo)準(zhǔn)的公開(kāi)數(shù)據(jù)集上面首次突破了64.5mAP的一個(gè)效果。
我們看看大模型在三個(gè)方面的應(yīng)用,首先是在遠(yuǎn)視距方面。

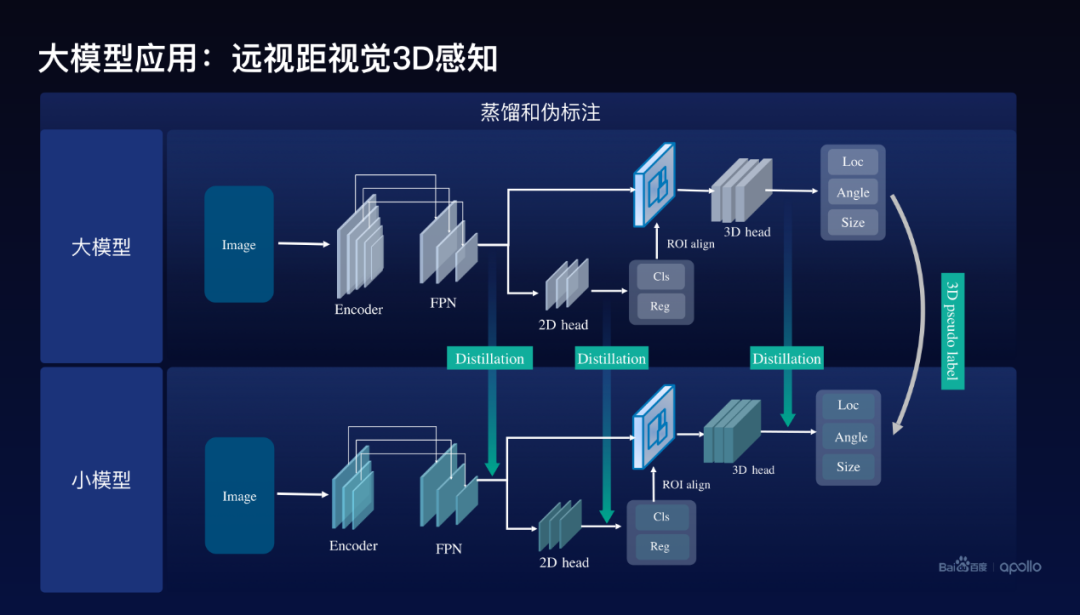
大模型怎么去幫助小模型,百度采用的方案是基于蒸餾和偽標(biāo)注的方案,偽標(biāo)注通過(guò)剛才訓(xùn)練好的感知大模型,給這個(gè)圖像打上3D的偽標(biāo)注,同時(shí)使用了蒸餾方案。在網(wǎng)絡(luò)架構(gòu)里面通常會(huì)包含編碼器。還有2D檢測(cè)的Head,以及3D檢測(cè)的Head,百度分別在三個(gè)地方使用了蒸餾,第一個(gè)是在編碼器出來(lái)的地方,用大模型的特征去幫助訓(xùn)練小模型的特征,除此以外在2D的Head上面與3D的Head上面分別去做大模型到小模型特征的蒸餾。
這里我們實(shí)際上在訓(xùn)練這個(gè)模型的時(shí)候還使用了這么一個(gè)小的技巧,就是把大模型的Detection head,包括2D、3D里面的參數(shù),直接作為小模型的初始化,進(jìn)一步地提升訓(xùn)練的效率和效果。
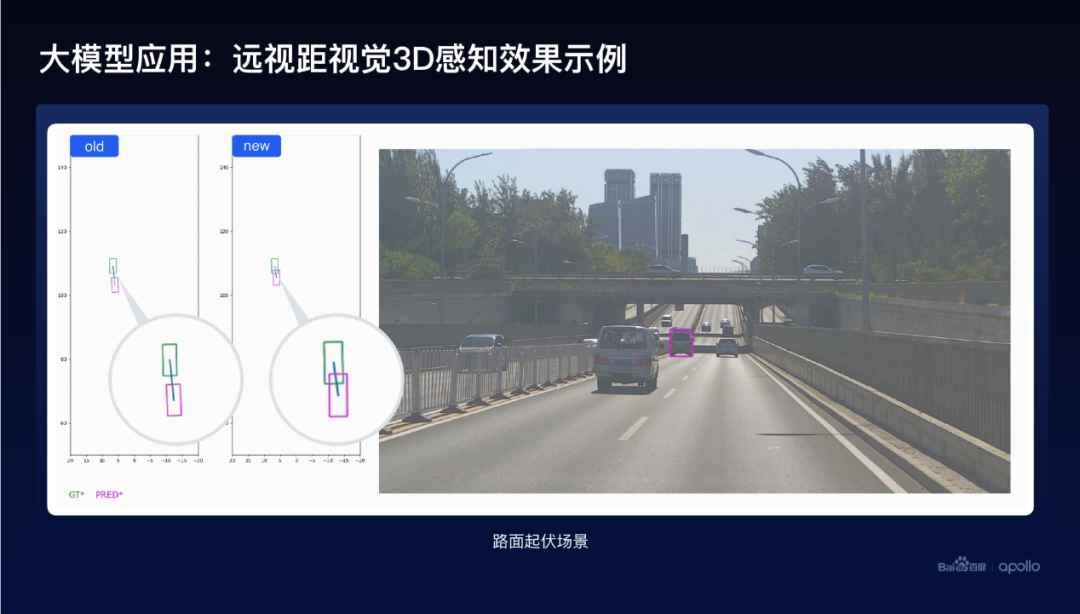
大模型幫助小模型帶來(lái)了一個(gè)效果,遠(yuǎn)視距3D感知帶來(lái)的效果,遮擋的場(chǎng)景可以看到這個(gè)圖里面,左邊綠色的框是對(duì)應(yīng)的Ground truth,紅色的是預(yù)測(cè)的,對(duì)比一下在舊模型和新模型的對(duì)比可以看到,新模型的效果從感知、預(yù)測(cè)車(chē)輛的距離等方面,效果提升是非常明顯的。
再看一看道路起伏的例子,仍然可以看到左邊這個(gè)舊模型和新模型效果的對(duì)比,跟前面對(duì)比起來(lái),不僅僅預(yù)測(cè)的物體的車(chē)輛的距離變得更準(zhǔn)確了,同時(shí)這個(gè)車(chē)輛的方向也預(yù)測(cè)得會(huì)更好,它的角度也會(huì)更好。

這邊僅僅給大家展示了兩個(gè)例子,在實(shí)際里面會(huì)發(fā)現(xiàn)更多非常好的效果,下面看看大模型在多模態(tài)前融合端到端感知上面的一個(gè)應(yīng)用。多模態(tài)前融合的方案對(duì)應(yīng)的大模型實(shí)際上是用前面我們講到的方案,通過(guò)半監(jiān)督的方案,迭代的自訓(xùn)練的方案去訓(xùn)練出來(lái)的。
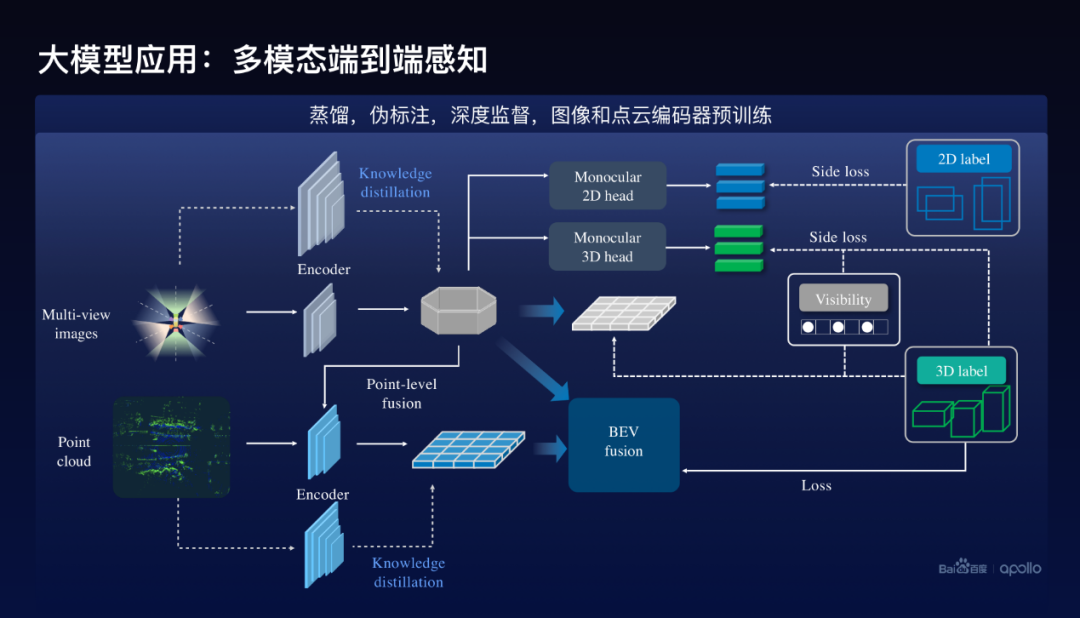
在這個(gè)地方怎么去幫助小模型的訓(xùn)練呢?除了蒸餾方案以外,在編碼器做蒸餾以外,也使用了偽標(biāo)注,就是用大模型對(duì)數(shù)據(jù)進(jìn)行偽標(biāo)注,然后去幫助訓(xùn)練。這里面要特別提到的其他幾點(diǎn):第一個(gè)我們使用了深度監(jiān)督的方法,分別在圖像端和點(diǎn)云端做了3D的預(yù)測(cè),比如說(shuō)在圖像端對(duì)每個(gè)圖像進(jìn)行2D的跟3D的預(yù)測(cè),我們稱(chēng)之為Side loss,這樣能夠很好的提升訓(xùn)練的效果。
還有一點(diǎn)百度還使用了預(yù)訓(xùn)練的方案,因?yàn)樵诙嗄B(tài)方案里面,既有圖像的編碼器,也有點(diǎn)云的編碼器,這個(gè)時(shí)候圖像的編碼器實(shí)際上不是在多模態(tài)下面訓(xùn)練出來(lái)的編碼器,來(lái)作為它的初始化,類(lèi)似的點(diǎn)云也是同樣。

要跟大家分享的是,把這樣的一個(gè)方案降級(jí)到多視角圖像的端到端的感知里面去。這樣一個(gè)方案,在公開(kāi)的nuScenes數(shù)據(jù)集上面取得了非常好的一個(gè)效果,目前在nuScenes 3D檢測(cè)里面multi-view的情況下面取得了最好的效果,能夠把這樣的一個(gè)方案應(yīng)用到nuScenes里面的跟蹤tracking里面去,也取得了非常好的效果。現(xiàn)在目前是在這個(gè)tracking榜單里面排名第一的。
那下面看看點(diǎn)云感知的效果,在多模態(tài)前融合方案里面,我們使用了點(diǎn)云感知的編碼器的預(yù)訓(xùn)練,如果只是在點(diǎn)云里面使用大模型的方案帶來(lái)了一個(gè)效果,這里面我們可以看到從舊模型和新模型的對(duì)比,在路測(cè)的誤檢方面我們改進(jìn)得非常多,同時(shí)在中間的比如說(shuō)綠化硬隔離帶也會(huì)有一些誤檢,那這樣子我們通過(guò)大模型幫助小模型以后,可以解決很多問(wèn)題。

下面看看多模態(tài)前融合感知的整體的效果,這里舉了一個(gè)非常困難的一個(gè)例子,大家看看左邊實(shí)際上是一個(gè)灑水車(chē),灑水車(chē)的前面實(shí)際上有噴霧。那在舊的方案里面,如果沒(méi)有使用我們這個(gè)多模態(tài)前融合端到端的方案,很容易把這個(gè)噴霧識(shí)別成車(chē)輛,但是用了新方案以后,這樣的誤檢就會(huì)消失。
最后看看大模型在數(shù)據(jù)挖掘里面的使用,這是整個(gè)自動(dòng)駕駛感知的數(shù)據(jù)閉環(huán)的流程圖。這里主要分享一下數(shù)據(jù)挖掘方面的這么一個(gè)技術(shù)。


在數(shù)據(jù)挖掘里面采用了大模型的方案,跟前面的感知的方案相關(guān),但不完全一樣,這使用了基于圖文弱監(jiān)督預(yù)訓(xùn)練模型去幫助做長(zhǎng)尾數(shù)據(jù)的挖掘。怎么去做預(yù)訓(xùn)練的模型,通常里面會(huì)有大量的圖文,把圖像送到一個(gè)我們稱(chēng)之為圖像編碼器里面去,圖文對(duì)里面對(duì)應(yīng)的文本也送到文本編碼器里面,通過(guò)優(yōu)化所謂的對(duì)比損失來(lái)訓(xùn)練這個(gè)文本編碼器和圖像編碼器。
這樣訓(xùn)練出來(lái)的編碼器有非常好的一個(gè)效果,可以處理稱(chēng)之為開(kāi)放集的語(yǔ)義識(shí)別,不同于傳統(tǒng)的比如說(shuō)在ImageNet上面,通常ImageNet-1K可以處理1000類(lèi),那這樣訓(xùn)練出來(lái)的圖文預(yù)訓(xùn)練模型可以處理1000類(lèi)以外,甚至成千上萬(wàn)的類(lèi)別,正是利用了這么一個(gè)性質(zhì)去幫助做數(shù)據(jù)挖掘。
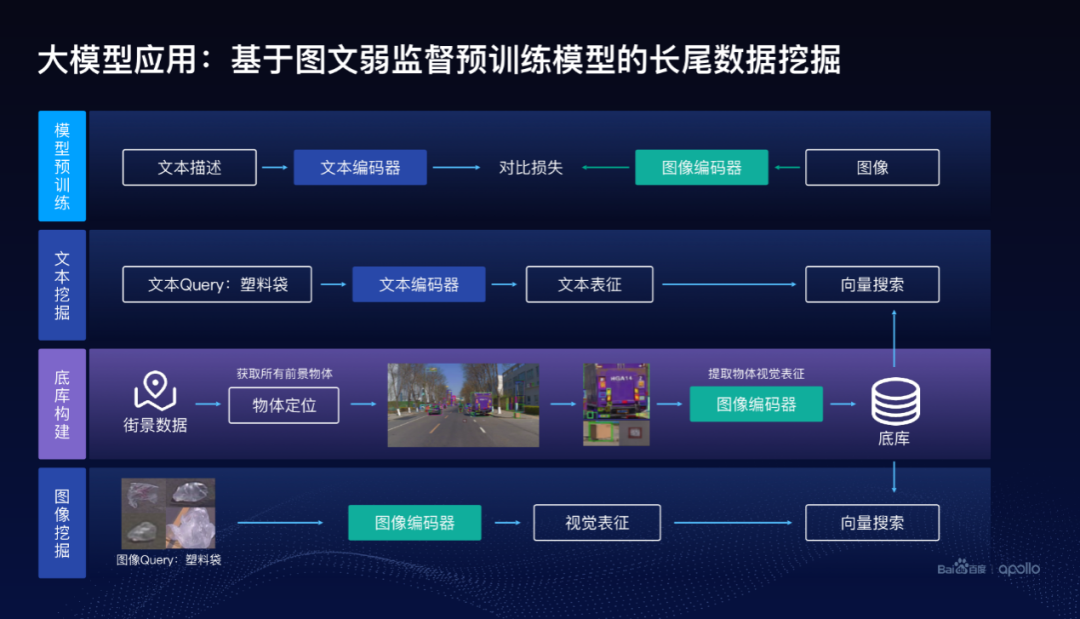
當(dāng)訓(xùn)練好這么一個(gè)模型以后,在自動(dòng)駕駛數(shù)據(jù)庫(kù)里面,經(jīng)過(guò)我們的底庫(kù)構(gòu)建,怎么做呢?
我們把街景數(shù)據(jù),比如這里面圖像,首先做一步物體定位,把這個(gè)圖像里面可能的物體都給找出來(lái),這里面使用了叫Group DETRv2的檢測(cè)方案,很好地把可能的物體給定位出來(lái)。把可能的物體定位出來(lái)以后,物體所在的圖像塊摳出來(lái),放到圖像編碼器里面,形成一個(gè)向量,這就是底庫(kù)的構(gòu)建。
做數(shù)據(jù)挖掘的時(shí)候可以采用兩種:一種是沒(méi)有所需要挖掘的圖像時(shí),可以直接通過(guò)文本去進(jìn)行挖掘,比如,把塑料袋輸入到文本編碼器里面,形成一個(gè)文本特征,變成一個(gè)文本表征的向量,然后通過(guò)快速的向量搜索算法,在底庫(kù)里面很快找到可能是塑料袋的圖像出來(lái)。
慢慢的已經(jīng)找到了一些塑料袋圖像以后,這個(gè)時(shí)候也可以把圖像輸入到圖像編碼器里面,抽取視覺(jué)表征,然后類(lèi)似的進(jìn)行向量搜索。
在這樣的過(guò)程中,剛開(kāi)始搜索出來(lái)的圖像效果準(zhǔn)確率不見(jiàn)得那么高,隨著搜索越來(lái)越多,回來(lái)的圖像數(shù)量越來(lái)越多,可以訓(xùn)練一個(gè)稱(chēng)之為fine classifier完成進(jìn)一步的篩選,最終不斷地提升數(shù)據(jù)挖掘的效果。
看看數(shù)據(jù)挖掘一些例子,以及最終怎么幫助自動(dòng)駕駛感知能力的提升呢?左邊是給了一些典型的例子。比如說(shuō)小孩在路面上面,比如說(shuō)快遞車(chē)、輪椅、地面上有塑料袋,還有消防車(chē)、救護(hù)車(chē)等,是百度在數(shù)據(jù)挖掘的例子。

在能力提升方面把它分為兩大類(lèi):一類(lèi)是本來(lái)有這么一個(gè)能力,通過(guò)這樣的數(shù)據(jù)挖掘以后這個(gè)能力得到了很大的提升,比如說(shuō)對(duì)兒童的檢測(cè),比如說(shuō)對(duì)塑料袋的誤檢,因?yàn)樗芰洗鼨z測(cè)是非常重要的,如果說(shuō)不能夠很好的把塑料袋跟其他的比如說(shuō)非常硬的物體給區(qū)分開(kāi)來(lái),那對(duì)后面的PNC會(huì)帶來(lái)很大的挑戰(zhàn),會(huì)容易出現(xiàn)急剎的情況。
另外一個(gè)能力的提升,就是說(shuō)本來(lái)可能沒(méi)有這樣的能力,通過(guò)數(shù)據(jù)挖掘以后,就有這樣的能力了,比方說(shuō)消防車(chē)和救護(hù)車(chē)這樣的例子,以前可能并不區(qū)分消防車(chē)和救護(hù)車(chē),消防車(chē)和救護(hù)車(chē)在路上會(huì)有較高的路權(quán),這個(gè)時(shí)候如果很好地把它識(shí)別出來(lái)以后,對(duì)后面下游的駕駛策略調(diào)整會(huì)起到很大的幫助。
另外一個(gè),在實(shí)踐里面就會(huì)發(fā)現(xiàn)一些有意思的現(xiàn)象,道路上有時(shí)候會(huì)出現(xiàn)一些小動(dòng)物,比如說(shuō)我們?cè)诔啥级h(huán)路上會(huì)發(fā)現(xiàn),成都二環(huán)路上的馬,還有我們?cè)诼飞蠒?huì)發(fā)現(xiàn)少見(jiàn)的羊群,比如說(shuō)我們?cè)陧樍x區(qū)路上會(huì)發(fā)現(xiàn)的羊群,這樣都是感知長(zhǎng)尾問(wèn)題,通過(guò)這樣的數(shù)據(jù)挖掘,現(xiàn)在有了這個(gè)能力,充分增強(qiáng)了自動(dòng)駕駛感知的效果。
最后,我用這么一句話來(lái)結(jié)束我今天的報(bào)告。大模型,已經(jīng)成為自動(dòng)駕駛能力提升的核心驅(qū)動(dòng)力。
審核編輯 :李倩
-
自動(dòng)駕駛
+關(guān)注
關(guān)注
788文章
14266瀏覽量
170186 -
毫米波雷達(dá)
+關(guān)注
關(guān)注
107文章
1094瀏覽量
65258 -
Apollo
+關(guān)注
關(guān)注
5文章
348瀏覽量
18774 -
大模型
+關(guān)注
關(guān)注
2文章
3086瀏覽量
3972
原文標(biāo)題:百度Apollo Day|王井東:大模型已經(jīng)成為自動(dòng)駕駛能力提升核心驅(qū)動(dòng)力
文章出處:【微信號(hào):baiduidg,微信公眾號(hào):Apollo智能駕駛】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
自動(dòng)駕駛安全基石:ODD
新能源車(chē)軟件單元測(cè)試深度解析:自動(dòng)駕駛系統(tǒng)視角

劉強(qiáng)東,進(jìn)軍汽車(chē)領(lǐng)域# 京東# 自動(dòng)駕駛# 自動(dòng)駕駛出租車(chē)# 京東自動(dòng)駕駛快遞車(chē)
“兩會(huì)”熱議“機(jī)器人和飛行汽車(chē)”,核心動(dòng)力電機(jī)可能會(huì)火
自動(dòng)駕駛大模型中常提的Token是個(gè)啥?對(duì)自動(dòng)駕駛有何影響?
小馬智行開(kāi)通廣州自動(dòng)駕駛示范運(yùn)營(yíng)專(zhuān)線
自動(dòng)駕駛規(guī)控算法驗(yàn)證到底需要什么樣的場(chǎng)景仿真軟件?

標(biāo)貝科技:自動(dòng)駕駛中的數(shù)據(jù)標(biāo)注類(lèi)別分享

標(biāo)貝科技:自動(dòng)駕駛中的數(shù)據(jù)標(biāo)注類(lèi)別分享

連接視覺(jué)語(yǔ)言大模型與端到端自動(dòng)駕駛

激光雷達(dá)與純視覺(jué)方案,哪個(gè)才是自動(dòng)駕駛最優(yōu)選?
速程精密直線旋轉(zhuǎn)執(zhí)行器:工業(yè)自動(dòng)化的核心驅(qū)動(dòng)力
新能源自動(dòng)駕駛編隊(duì)運(yùn)輸聯(lián)盟成立,圖達(dá)通攜手卡爾動(dòng)力共塑自動(dòng)駕駛貨運(yùn)新未來(lái)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論