 自然語言處理或將迎來新的范式變遷
自然語言處理或將迎來新的范式變遷

最近幾天被OpenAI推出的ChatGPT[1]刷屏了,其影響已經不僅局限于自然語言處理(NLP)圈,就連投資圈也開始蠢蠢欲動了,短短幾天ChatGPT的用戶數就超過了一百萬。通過眾多網友以及我個人對其測試的結果看,ChatGPT的效果可以用驚艷來形容,具體結果我在此就不贅述了。不同于GPT-3剛推出時人們的反應,對ChatGPT大家發出更多的是贊嘆之詞。聊天、問答、寫作、編程等等,樣樣精通。因此也有人驚呼,“通用人工智能(AGI)即將到來”、“Google等傳統搜索引擎即將被取代”,所以也對傳說中即將發布的GPT-4更加期待。
從技術角度講,ChatGPT還是基于大規模預訓練語言模型(GPT-3.5)強大的語言理解和生成的能力,并通過在人工標注和反饋的大規模數據上進行學習,從而讓預訓練語言模型能夠更好地理解人類的問題并給出更好的回復。這一點上和OpenAI于今年3月份推出的InstructGPT[2]是一致的,即通過引入人工標注和反饋,解決了自然語言生成結果不易評價的問題,從而就可以像玩兒游戲一樣,利用強化學習技術,通過嘗試生成不同的結果并對結果進行評分,然后鼓勵評分高的策略、懲罰評分低的策略,最終獲得更好的模型。
不過說實話,我當時并不看好這一技術路線,因為這仍然需要大量的人工勞動,本質上還是一種“人工”智能。不過ChatGPT通過持續投入大量的人力,把這條路走通了,從而更進一步驗證了那句話,“有多少人工,就有多少智能”。
不過,需要注意的是,ChatGPT以及一系列超大規模預訓練語言模型的成功將為自然語言處理帶來新的范式變遷,即從以BERT為代表的預訓練+精調(Fine-tuning)范式,轉換為以GPT-3為代表的預訓練+提示(Prompting)的范式[3]。所謂提示,指的是通過構造自然語言提示符(Prompt),將下游任務轉化為預訓練階段的語言模型任務。例如,若想識別句子“我喜歡這部電影。”的情感傾向性,可以在其后拼接提示符“它很 ”。如果預訓練模型預測空格處為“精彩”,則句子大概率為褒義。這樣做的好處是無需精調整個預訓練模型,就可以調動模型內部的知識,完成“任意”的自然語言處理任務。當然,在ChatGPT出現之前,這種范式轉變的趨勢并不明顯,主要有兩個原因:
第一,GPT-3級別的大模型基本都掌握在大公司手里,因此學術界在進行預訓練+提示的研究時基本都使用規模相對比較小的預訓練模型。由于規模規模不夠大,因此預訓練+提示的效果并不比預訓練+精調的效果好。而只有當模型的規模足夠大后,才會涌現(Emerge)出“智能”[4]。最終,導致之前很多在小規模模型上得出的結論,在大規模模型下都未必適用了。
第二,如果僅利用預訓練+提示的方法,由于預訓練的語言模型任務和下游任務之間差異較大,導致這種方法除了擅長續寫文本這種預訓練任務外,對其他任務完成得并不好。因此,為了應對更多的任務,需要在下游任務上繼續預訓練(也可以叫預精調),而且現在的趨勢是在眾多的下游任務上預精調大模型,以應對多種、甚至未曾見過的新任務[5]。所以更準確地說,預訓練+預精調+提示將成為自然語言處理的新范式。
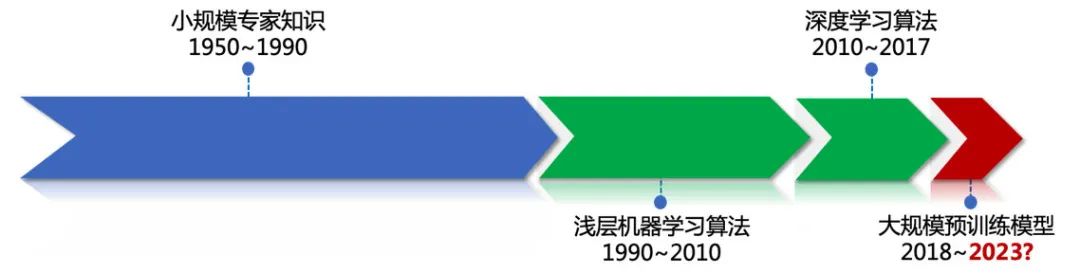
不同于傳統預訓練+精調范式,預訓練+預精調+提示范式將過去一個自然語言處理模型擅長處理一個具體任務的方式,轉換為了用一個模型處理多個任務,甚至未曾見過的通用任務的方式。所以從這個角度來講,通用人工智能也許真的即將到來了。這似乎也和我幾年前的預測相吻合,我當時曾預測,“結合自然語言處理歷次范式變遷的規律(圖1),2018年預訓練+精調的范式出現之后5年,即2023年自然語言處理也許將迎來新的范式變遷”。
那么,接下來如何進一步提升預訓練+預精調+提示新范式的能力,并在實際應用中將其落地呢?
首先,顯式地利用人工標注和反饋仍然費時費力,我們應該設法更自然地獲取并利用人類的反饋。也就是在實際應用場景中,獲取真實用戶的自然反饋,如其回復的語句、所做的行為等,并利用這些反饋信息提升系統的性能,我們將這種方式稱為交互式自然語言處理。不過用戶的交互式反饋相對稀疏,并且有些用戶會做出惡意的反饋,如何克服稀疏性以及避免惡意性反饋都將是亟待解決的問題。
其次,目前該范式生成的自然語言文本具有非常好的流暢性,但是經常會出現事實性錯誤,也就是會一本正經地胡說八道。當然,使用上面的交互式自然語言處理方法可以一定程度上解決此類問題,不過對于用戶都不知道答案的問題,他們是無法對結果進行反饋的。此時又回到了可解釋性差,這一深度學習模型的老問題上。如果能夠像寫論文時插入參考文獻一樣,在生成的結果中插入相關信息的出處,則會大大提高結果的可解釋性。
最后,該范式依賴超大規模預訓練語言模型,然而這些模型目前只掌握在少數的大公司手中,即便有個別開源的大模型,由于其過于龐大,小型公司或研究組也無法下載并使用它們。所以,在線調用是目前使用這些模型最主要的模式。在該模式下,如何針對不同用戶面對的不同任務,使用用戶私有的數據對模型進行進一步預精調,并且不對公有的大模型造成影響,成為該范式實際應用落地所迫切需要解決的問題。此外,為了提高系統的運行速度,如何通過在線的大模型獲得離線的小模型,并且讓離線小模型保持大模型在某些任務上的能力,也成為模型能實際應用的一種解決方案。
審核編輯:郭婷
-
人工智能
+關注
關注
1806文章
48971瀏覽量
248663 -
nlp
+關注
關注
1文章
490瀏覽量
22585
原文標題:哈工大車萬翔:自然語言處理范式正在變遷
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監
評論