") 深度學(xué)習(xí)基礎(chǔ)知識(shí)(5)
深度學(xué)習(xí)基礎(chǔ)知識(shí)(5)

上一節(jié)中說到,需要求使損失函數(shù)最小的權(quán)重和偏置,高中數(shù)學(xué)中,求函數(shù)的極值就是使函數(shù)導(dǎo)數(shù)為0的點(diǎn)。
1、導(dǎo)數(shù)
導(dǎo)數(shù)是某個(gè)瞬間的變化量,瞬間的定義是時(shí)間趨近于0
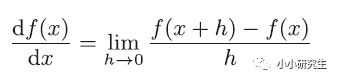
使用代碼來實(shí)現(xiàn):
def numerical_diff(f,x):
h=10e-50
return(f(x+h)-f(x))/h
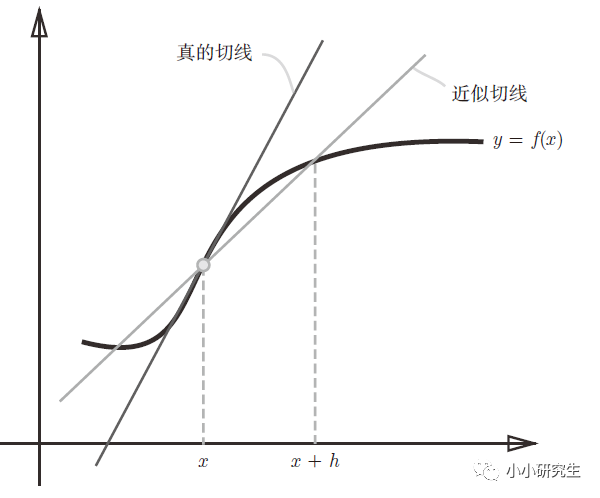
此時(shí),h取一個(gè)極小的數(shù)來表示趨近于0,但是如果太小的話在計(jì)算機(jī)中貴產(chǎn)生舍入誤差,用float32的浮點(diǎn)數(shù)來表示依然是0.0。另外,上述定義是函數(shù)f在x與x+h之間的差分,是近似的導(dǎo)數(shù)定義,而真正的導(dǎo)數(shù)是曲線在某一點(diǎn)上的切線,這個(gè)誤差產(chǎn)生是由于h不可能無限趨近于0。因此,可以計(jì)算f在x+h和x-h之間的差分進(jìn)一步減小誤差。
真正數(shù)值微分的代碼:
def numerical_diff(f,x):
h=1e-4
return (f(x+h)-f(x-h))/(2*h)
真正用函數(shù)的導(dǎo)數(shù)計(jì)算出的結(jié)果是解析解,而數(shù)值微分近似的結(jié)果嚴(yán)格意義上并不一致,但是由于誤差可以忽略不計(jì),因此可以認(rèn)為它們是相等的。
2、偏導(dǎo)數(shù)
當(dāng)函數(shù)y有多變量時(shí),多變量函數(shù)的導(dǎo)數(shù)就是偏導(dǎo)數(shù)。求偏導(dǎo)數(shù)時(shí),多變量中的一個(gè)變量是目標(biāo)變量,其他變量需要為定值。
求偏導(dǎo)的代碼:
def function_2(x):
return x[0]**2+x[1]**2
3、梯度
偏導(dǎo)數(shù)匯總而成的向量成為梯度。
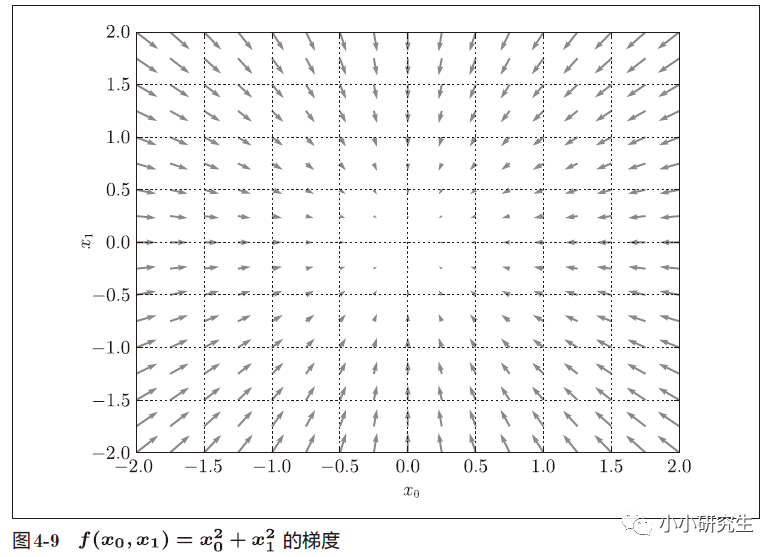
向量是有大小和方向的,在梯度圖中,箭頭的指向就是梯度的方向,箭頭的長(zhǎng)度就是梯度的大小。 梯度總是指向函數(shù)值減小最多的方向。
知道梯度的定義,就可以用梯度來使損失函數(shù)減小。復(fù)雜函數(shù)中,梯度指示的方向基本上都不是函數(shù)值最小處,但沿著梯度方向可以最大限度減小函數(shù)的值。在梯度法中,函數(shù)的值從當(dāng)前位置沿著梯度方向前進(jìn),然后在新的地方重新求梯度,再沿著新梯度的方向前進(jìn),不斷重復(fù),逐漸減小函數(shù)值。尋找最小值的梯度法是梯度下降法,尋找最大值的梯度法是梯度上升法,一般神經(jīng)網(wǎng)絡(luò)中梯度法主要是指梯度下降法。
4、梯度法求某個(gè)函數(shù)值優(yōu)化結(jié)果
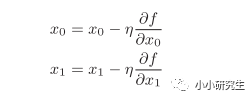
η是學(xué)習(xí)率,表示更新量,決定在一次學(xué)習(xí)中,應(yīng)該學(xué)習(xí)多少以及在多大程度上更新參數(shù)。上式會(huì)反復(fù)執(zhí)行,逐漸減小函數(shù)值。學(xué)習(xí)率需要事先確定,過大或過小都不行,一般會(huì)一邊改變學(xué)習(xí)率一邊確定學(xué)習(xí)是否正確進(jìn)行。
梯度下降法代碼:
def gradient_descent(f,init_x,lr=0.01,step_num=100);
x=init_x
for i in range(step_num):
grad=numerical_gradient(f,x)
x-=lr*grad
return x
參數(shù)f是要最優(yōu)化的函數(shù),init_x是初始值,lr是學(xué)習(xí)率,step_num是重復(fù)次數(shù)。 numerical_gradient()會(huì)求函數(shù)梯度,并更新x。
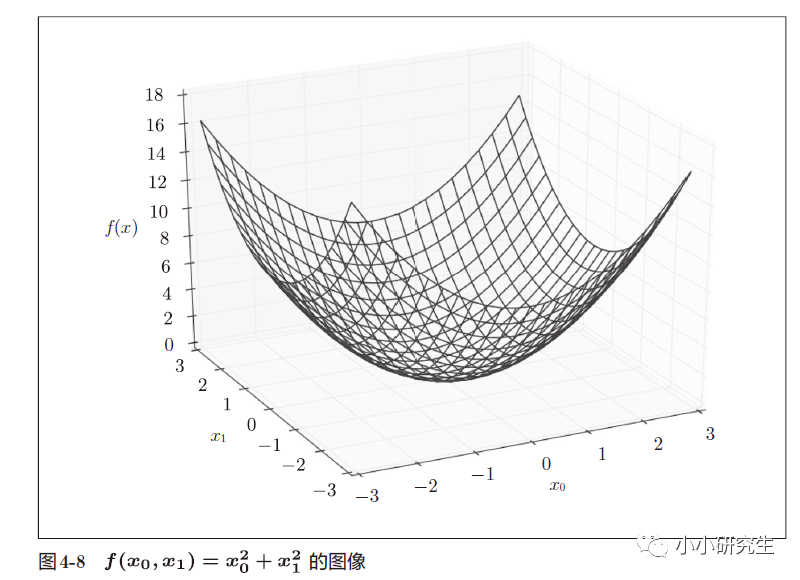
當(dāng)使用梯度法求f(x0,x1)=x0^2+x1^2的最小值時(shí),設(shè)置初始值為(-3,-4),學(xué)習(xí)率為1,上面次數(shù)定義的時(shí)候是100,實(shí)際使用的時(shí)候設(shè)置是20,最終結(jié)果為[-0.03458765 0.04611686]。 使用解析法求最小值是[0,0],因此結(jié)果在一定程度上可以認(rèn)為是一致的。
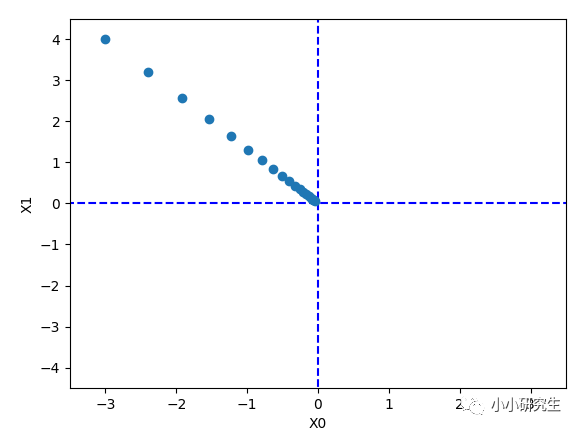
對(duì)梯度法每次迭代進(jìn)行繪圖顯示,函數(shù)的取值在向原點(diǎn)(最小值處)逐步靠近。
學(xué)習(xí)率的設(shè)置非常重要,當(dāng)我們將其設(shè)置為10時(shí),結(jié)果為[-2.58983747e+13 ,-1.29524862e+12]發(fā)散成一個(gè)很大的值。 當(dāng)設(shè)置成1e-10時(shí),結(jié)果為[-2.99999999 , 3.99999998]幾乎沒有什么變化。 學(xué)習(xí)率這種超參數(shù)和權(quán)重偏置不同,只能人工設(shè)定,需要嘗試多個(gè)值。
5、梯度法求神經(jīng)網(wǎng)絡(luò)的損失函數(shù)優(yōu)化結(jié)果
class simpleNet:
def __init__(self):
self.W = np.random.randn(2,3)
def predict(self, x):
return np.dot(x, self.W)
def loss(self, x, t):
z = self.predict(x)
y = softmax(z)
loss = cross_entropy_error(y, t)
return loss
x = np.array([0.6, 0.9])
t = np.array([0, 0, 1])
net = simpleNet()
f = lambda w: net.loss(x, t)
dW = numerical_gradient(f, net.W)
print(dW)
init (self)創(chuàng)建一個(gè)隨機(jī)的2*3的矩陣,predict(self,x)讓x與W矩陣相乘,loss(self,x,t)定義了損失函數(shù)。 給定了x,t之后調(diào)用了實(shí)例化的類,再將net.loss傳遞給f后,在numerical_gradient()函數(shù)中進(jìn)行調(diào)用求梯度。
至此,求出了神經(jīng)網(wǎng)絡(luò)的梯度,接下來只需要根據(jù)梯度法更新權(quán)重參數(shù)。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4812瀏覽量
103268 -
計(jì)算機(jī)
+關(guān)注
關(guān)注
19文章
7648瀏覽量
90518 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4378瀏覽量
64590 -
C代碼
+關(guān)注
關(guān)注
1文章
90瀏覽量
14736 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5557瀏覽量
122672
發(fā)布評(píng)論請(qǐng)先 登錄
5G新空口標(biāo)準(zhǔn)基礎(chǔ)知識(shí)
5G新空口標(biāo)準(zhǔn)基礎(chǔ)知識(shí)
通信基礎(chǔ)知識(shí)教程
FPGA開發(fā)經(jīng)驗(yàn)與技巧_基礎(chǔ)知識(shí)學(xué)習(xí)篇(1)
ADC【DSP基礎(chǔ)知識(shí)】
使用Eclipse基礎(chǔ)知識(shí)
Verilog_HDL基礎(chǔ)知識(shí)非常好的學(xué)習(xí)教程 (1)

機(jī)器學(xué)習(xí)的基礎(chǔ)知識(shí)詳細(xì)說明
了解一下機(jī)器學(xué)習(xí)中的基礎(chǔ)知識(shí)
51單片機(jī)學(xué)習(xí) 基礎(chǔ)知識(shí)總結(jié)

單片機(jī)基礎(chǔ)知識(shí)學(xué)習(xí)筆記





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論