") 驚!大腦視覺信號被Stable Diffusion復(fù)現(xiàn)成視頻!
驚!大腦視覺信號被Stable Diffusion復(fù)現(xiàn)成視頻!

現(xiàn)在,AI可以把人類腦中的信息,用高清視頻展示出來了!
例如你坐在副駕所欣賞到的沿途美景信息,AI分分鐘給重建了出來:

看到過的水中的魚兒、草原上的馬兒,也不在話下:


這就是由新加坡國立大學(xué)和香港中文大學(xué)共同完成的最新研究,團隊將項目取名為MinD-Video。

Cinematic Mindscapes: High-quality Video Reconstruction from Brain Activity 主頁:https://mind-video.com/ 論文:https://arxiv.org/abs/2305.11675 代碼:https://github.com/jqin4749/MindVideo
這波操作,宛如科幻電影《超體》中Lucy讀取反派大佬記憶一般:

引得網(wǎng)友直呼:
推動人工智能和神經(jīng)科學(xué)的前沿。
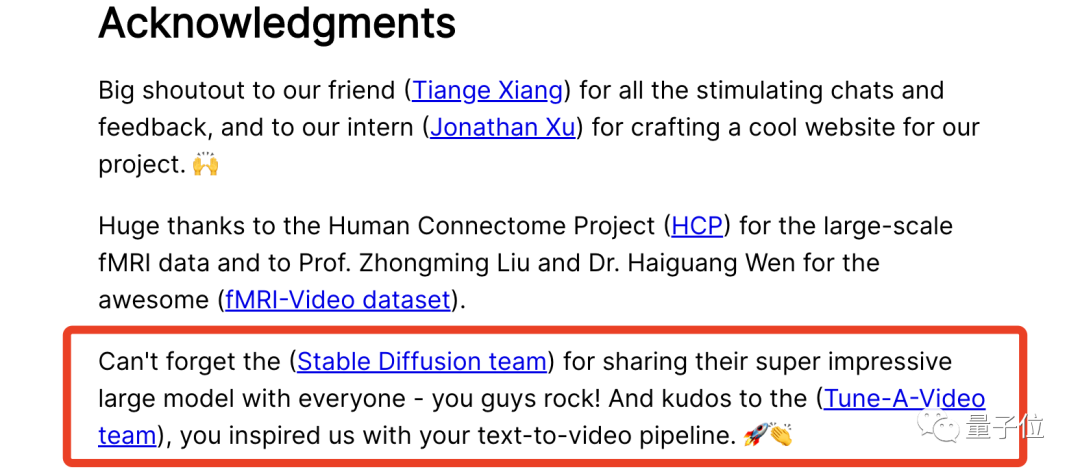
值得一提的是,大火的Stable Diffusion也在這次研究中立了不小的功勞。
怎么做到的?
從大腦活動中重建人類視覺任務(wù),尤其是功能磁共振成像技術(shù)(fMRI)這種非侵入式方法,一直是受到學(xué)界較多的關(guān)注。
因為類似這樣的研究,有利于理解我們的認知過程。
但以往的研究都主要聚焦在重建靜態(tài)圖像,而以高清視頻形式來展現(xiàn)的工作還是較為有限。
之所以會如此,是因為與重建一張靜態(tài)圖片不同,我們視覺所看到的場景、動作和物體的變化是連續(xù)、多樣化的。
而fMRI這項技術(shù)的本質(zhì)是測量血氧水平依賴(BOLD)信號,并且在每隔幾秒鐘的時間里捕捉大腦活動的快照。
相比之下,一個典型的視頻每秒大約包含30幀畫面,如果要用fMRI去重建一個2秒的視頻,就需要呈現(xiàn)起碼60幀。
因此,這項任務(wù)的難點就在于解碼fMRI并以遠高于fMRI時間分辨率的FPS恢復(fù)視頻。
為了彌合圖像和視頻大腦解碼之間差距,研究團隊便提出了MinD-Video的方法。
整體來看,這個方法主要包含兩大模塊,它們分別做訓(xùn)練,然后再在一起做微調(diào)。
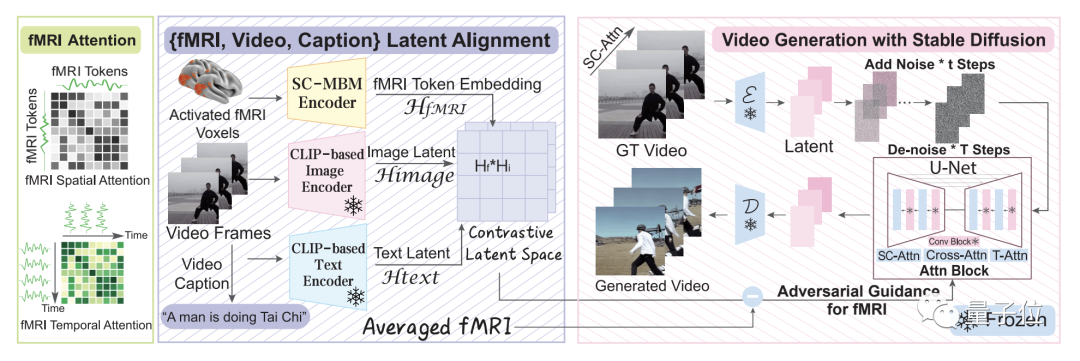
這個模型從大腦信號中逐步學(xué)習(xí),在第一個模塊多個階段的過程,可以獲得對語義空間的更深入理解。
具體而言,便是先利用大規(guī)模無監(jiān)督學(xué)習(xí)與mask brain modeling(MBM)來學(xué)習(xí)一般的視覺fMRI特征。
然后,團隊使用標(biāo)注數(shù)據(jù)集的多模態(tài)提取語義相關(guān)特征,在對比語言-圖像預(yù)訓(xùn)練(CLIP)空間中使用對比學(xué)習(xí)訓(xùn)練fMRI編碼器。
在第二個模塊中,團隊通過與增強版Stable Diffusion模型的共同訓(xùn)練來微調(diào)學(xué)習(xí)到的特征,這個模型是專門為fMRI技術(shù)下的視頻生成量身定制的。
如此方法之下,團隊也與此前的諸多研究做了對比,可以明顯地看到MinD-Video方法所生成的圖片、視頻質(zhì)量要遠優(yōu)于其它方法。
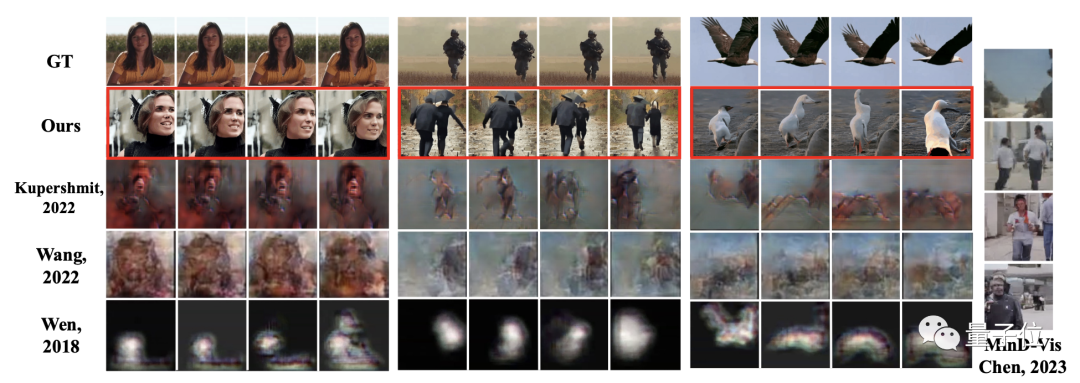
而且在場景連續(xù)變化的過程中,也能夠呈現(xiàn)高清、有意義的連續(xù)幀。

研究團隊
這項研究的共同一作,其中一位是來自新加坡國立大學(xué)的博士生Zijiao Chen,目前在該校的神經(jīng)精神疾病多模式神經(jīng)成像實驗室(MNNDL_Lab)。
另一位一作則是來自香港中文大學(xué)的Jiaxin Qing,就讀專業(yè)是信息工程系。
除此之外,通訊作者是新加坡國立大學(xué)副教授Juan Helen ZHOU。
據(jù)了解,這次的新研究是他們團隊在此前一項名為MinD-Vis的功能磁共振成像圖像重建工作的延伸。
MinD-Vis已經(jīng)被CVPR 2023所接收。

審核編輯 :李倩
-
AI
+關(guān)注
關(guān)注
88文章
34781瀏覽量
277120 -
人工智能
+關(guān)注
關(guān)注
1805文章
48899瀏覽量
247971 -
視覺
+關(guān)注
關(guān)注
1文章
157瀏覽量
24322
原文標(biāo)題:驚!大腦視覺信號被Stable Diffusion復(fù)現(xiàn)成視頻!"AI讀腦術(shù)"又來了!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
是德N5173B信號發(fā)生器在EMC測試中的干擾信號精準復(fù)現(xiàn)技巧
?Diffusion生成式動作引擎技術(shù)解析
IGBT模塊的反向恢復(fù)現(xiàn)象

使用OpenVINO GenAI和LoRA適配器進行圖像生成
安裝OpenVINO?工具包穩(wěn)定擴散后報錯,怎么解決?
Meta非入侵式腦機技術(shù):AI讀取大腦信號打字準確率80%
Meta AI推出Brain2Qwerty:非侵入性大腦信號轉(zhuǎn)文本系統(tǒng)

HDMI光端機:打造高清視頻信號傳輸?shù)臉蛄?/a>
AMS-MC158:重塑視覺邊界,引領(lǐng)LED視頻處理新風(fēng)尚
機器視覺系統(tǒng)硬件組成之工業(yè)相機篇

常見的視頻接口有哪些
PCB視頻板 —— 開啟視覺盛宴的關(guān)鍵之匙
示波器的波形存儲與復(fù)現(xiàn),再也不怕瞬時信號抓不住了

實操: 如何在AirBox上跑Stable Diffusion 3






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論