") 從混沌到清晰:大語言模型如何化繁為簡,開創(chuàng)數(shù)據(jù)清洗新時(shí)代!
從混沌到清晰:大語言模型如何化繁為簡,開創(chuàng)數(shù)據(jù)清洗新時(shí)代!

在數(shù)字時(shí)代,準(zhǔn)確可靠的數(shù)據(jù)對企業(yè)來說至關(guān)重要。這些數(shù)據(jù)為企業(yè)提供個(gè)性化的體驗(yàn),并幫助他們做出明智的決策[1]。然而,由于龐大的數(shù)據(jù)量和復(fù)雜度,處理數(shù)據(jù)常常面臨重大挑戰(zhàn),需要進(jìn)行大量枯燥且手動(dòng)的工作。在這種情況下,大語言模型(LLM)應(yīng)運(yùn)而生,這項(xiàng)變革性技術(shù)具備了自然語言處理和模式識(shí)別的能力,有望徹底改變數(shù)據(jù)清洗的過程,使數(shù)據(jù)更具可用性。
在數(shù)據(jù)科學(xué)家的工具箱中,LLM就像是扳手和螺絲刀,能夠重塑活動(dòng)并發(fā)揮作用,以提升數(shù)據(jù)質(zhì)量。就像諺語中說的一錘定音,LLM將揭示出可行的洞見,最終為創(chuàng)造更好的客戶體驗(yàn)鋪平道路。
現(xiàn)在,讓我們直接進(jìn)入今天的案例。
案例
當(dāng)對學(xué)生進(jìn)行調(diào)查問卷時(shí),將事實(shí)字段設(shè)為自由形式的文本是最糟糕的選擇!你可以想象我們收到的一些回答。
開個(gè)玩笑,我們的客戶之一是Study Fetch,這是一個(gè)AI驅(qū)動(dòng)的平臺(tái),利用課程材料為學(xué)生創(chuàng)建個(gè)性化的全方位學(xué)習(xí)套件。他們在大學(xué)生中進(jìn)行了一項(xiàng)調(diào)查,收到了超過10,000個(gè)反饋。然而,他們的首席執(zhí)行官兼聯(lián)合創(chuàng)始人Esan Durrani遇到了一個(gè)小問題。原來,在調(diào)查中,"主修"字段是一個(gè)自由形式的文本框,這意味著回答者可以輸入任何內(nèi)容。作為數(shù)據(jù)科學(xué)家,我們知道這對于進(jìn)行統(tǒng)計(jì)計(jì)算來說絕對不是一個(gè)明智的選擇。所以,從調(diào)查中獲得的原始數(shù)據(jù)看起來像這樣...

天了嚕,讓你的Excel準(zhǔn)備好吧!準(zhǔn)備好花上一個(gè)小時(shí),甚至三個(gè)小時(shí)的冒險(xiǎn)來對付這些數(shù)據(jù)異類。
但是,別擔(dān)心,我們有一把大語言模型(LLM)的錘子。
正如一位長者所言,假如你只有一把錘子,那么所有的問題都會(huì)像是釘子。而數(shù)據(jù)清洗工作難道不正是最適合這把錘子的任務(wù)嗎?
我們只需要簡單地使用我們友好的大語言模型將它們歸類到已知的類別中。特別是,OpenAI的生成式預(yù)訓(xùn)練Transformer(GPT)模型,正是當(dāng)下流行的聊天機(jī)器人應(yīng)用ChatGPT背后的LLM。GPT模型使用了高達(dá)1750億個(gè)參數(shù),并且已經(jīng)通過對來自公開數(shù)據(jù)集Common Crawl的26億個(gè)存儲(chǔ)網(wǎng)頁進(jìn)行訓(xùn)練。此外,通過一種稱為從人類反饋中的強(qiáng)化學(xué)習(xí)(RLHF)的技術(shù),訓(xùn)練者可以推動(dòng)并激勵(lì)模型提供更準(zhǔn)確和有用的回答[2]。
對于我們的目標(biāo)來說,我相信超過1750億個(gè)參數(shù)應(yīng)該足夠了,只要我們能給出正確的提示(prompt)。
圖片由Kelly Sikkema上傳至Unsplash
關(guān)鍵在于提示語
來自某AI公司的Ryan和Esan,他們的主要業(yè)務(wù)是編寫出色的提示語。他們提供了我們的提示語的第一個(gè)版本。這個(gè)版本很棒,使用語言推斷[3]效果非常好,但有兩個(gè)可以改進(jìn)的地方:
首先,它僅適用于單個(gè)記錄。
其次,它使用了達(dá)芬奇模型的'Completion'方法(一提到它,我的銀行賬戶就開始恐慌)。
這導(dǎo)致了過高的成本,這是我們無法接受的。因此,Ryan和我分別使用'gpt-3.5-turbo'重新編寫了提示語,以便進(jìn)行批量操作。對我來說,OpenAI的提示語最佳實(shí)踐和ChatGPT Prompt Engineering for Developers課程非常有幫助。經(jīng)過一系列思考、實(shí)施、分析和改進(jìn)的迭代,我們最終獲得了一個(gè)出色的工作版本。
現(xiàn)在,讓我們馬上展示經(jīng)過第二次修訂后的提示語:

對這個(gè)提示語,LLM給的回應(yīng)是:

這個(gè)方法或多或少會(huì)有些效果。但我并不太喜歡那些重復(fù)的、長篇大論的項(xiàng)目名稱。在LLM中,文本就是tokens,tokens就是真金白銀啊。你知道,我的編程技能是在互聯(lián)網(wǎng)泡沫破裂的火熱深淵中鍛煉出來的。讓我告訴你,我從不放過任何一次節(jié)省成本的機(jī)會(huì)。
因此,我在“期望的格式”部分略微修改了提示語。我要求模型只輸出調(diào)查反饋的序數(shù)(例如,上面的戲劇為1)和項(xiàng)目的序數(shù)(例如,文學(xué)為1)。然后Ryan建議我應(yīng)該要求輸出JSON格式而不是CSV,以便更簡單地解析。他還建議我添加一個(gè)“示例輸出”部分,這是一個(gè)極好的建議。
最終的提示語如下(為清晰起見,已簡化):

模型的輸出結(jié)果是:
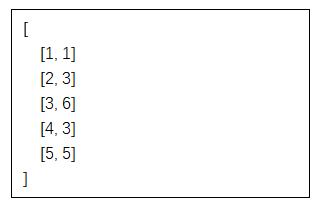
所以,正如我們之前討論的,模型的輸出是我們定義的類別與調(diào)查響應(yīng)的序數(shù)之間的映射。以第一行為例:1,1。這意味著1是響應(yīng)編號(hào),1是相應(yīng)的映射程序編號(hào)。調(diào)查響應(yīng)1是“戲劇”,映射的程序1是“文學(xué)與人文”。這看起來很正確!戲劇在它應(yīng)有的#1位置,成為了所有人的焦點(diǎn)。
雖然輸出結(jié)果乍看之下像是嵌入的輸出(用于聚類和降維),但它們只是相同的映射信息,只不過是序數(shù)位置。除了在token使用上提供一些成本優(yōu)勢外,這些數(shù)字還更容易解析。
我們現(xiàn)在可以把原始的調(diào)查反饋文件轉(zhuǎn)換為有意義的專業(yè),做聚合,獲得有價(jià)值的可操作的洞察。
但等等,我不打算坐在電腦前,把每一塊調(diào)查反饋輸入瀏覽器并計(jì)算映射。這除了令人頭腦麻木,錯(cuò)誤率也是無法接受的。
我們需要的是一些好的自動(dòng)化工具。讓我們來看看API...
API救世主
可能你已經(jīng)知道,應(yīng)用程序接口(API)使我們的程序能夠高效地與第三方服務(wù)進(jìn)行交互。盡管許多人通過使用ChatGPT實(shí)現(xiàn)了令人印象深刻的成果,但語言模型的真正潛力在于利用API將自然語言能力無縫地集成到應(yīng)用程序中,使用戶感覺不到它的存在。就像你正在用來閱讀這篇文章的手機(jī)或電腦背后的令人難以置信的科學(xué)技術(shù)。
我們將使用REST來調(diào)用chat completion API。調(diào)用的示例如下:

我們快速看一下參數(shù)及其效果。
模型
到目前為止,對公眾開放的聊天完成模型只有g(shù)pt-3.5-turbo。Esan可以使用GPT 4模型,我對此非常嫉妒。雖然gpt-4更準(zhǔn)確,且出現(xiàn)錯(cuò)誤的可能性更小[2],但它的成本大約是gpt-3.5-turbo的20倍,對于我們的需求來說,gpt-3.5-turbo完全足夠了,謝謝。
溫度(temperature)
temperature是我們可以傳遞給模型的最重要的設(shè)置之一,僅次于提示。根據(jù)API文檔,它可以設(shè)置在0和2之間的值。它有著顯著的影響[6],因?yàn)樗刂戚敵鲋械碾S機(jī)性,有點(diǎn)像你開始寫作前體內(nèi)的咖啡因含量。你可以在這里找到一個(gè)對于每個(gè)應(yīng)用可以使用的值的指南[7]。
對于我們的用例,我們只想要沒有變化的輸出。我們希望引擎給我們原封不動(dòng)的映射,每次都是相同的。所以,我們使用了0的值。
N值
生成多少個(gè)聊天完成選擇?如果我們是為了創(chuàng)造性寫作并希望有多個(gè)選擇,我們可以使用2或者3。對于我們的情況,n=1(默認(rèn))會(huì)很好。
角色
角色可以是system(系統(tǒng))、user(用戶)或assistant(助手)。系統(tǒng)角色提供指令和設(shè)定環(huán)境。用戶角色代表來自最終用戶的提示。助手角色是基于對話歷史的響應(yīng)。這些角色幫助構(gòu)造對話,并使用戶和AI助手能夠有效地互動(dòng)。
模型最大Token
這不一定是我們在請求中傳遞的參數(shù),盡管另一個(gè)參數(shù)max_tokens限制了從聊天中獲取的響應(yīng)的總長度。
首先,token可以被認(rèn)為是一個(gè)詞的一部分。一個(gè)token大約是英語中的4個(gè)字符。例如,被歸于亞伯拉罕·林肯(Abraham Lincoln)和其他人的引語“The best way to predict the future is to create it”包含了11個(gè)token。

如果你認(rèn)為一個(gè)token就是一個(gè)詞,那么這里有一個(gè)64個(gè)token的例子,可以顯示它并非那么簡單。

做好準(zhǔn)備,因?yàn)楝F(xiàn)在要揭示一個(gè)令人震驚的事實(shí):每個(gè)你在消息中使用的表情符號(hào)都會(huì)額外增加高達(dá)6個(gè)重要令牌的成本。沒錯(cuò),你喜愛的笑臉和眨眼都是偷偷摸摸的小令牌竊賊!
模型的最大token窗口是一種技術(shù)限制。你的提示(包括其中的任何額外數(shù)據(jù))和答案必須適應(yīng)模型的最大限制。在對話完成的情況下,內(nèi)容、角色和之前的所有消息都會(huì)占用token。如果你從輸入或輸出(助手消息)中刪除一條消息,模型將完全失去對它的了解[8]。就像多麗在尋找奇科時(shí),沒有法比奧,沒有賓果,沒有哈波,沒有艾爾莫?... 尼莫!
對于gpt-3.5-turbo,模型的最大限制是4096個(gè)token,或大約16000個(gè)字符。對于我們的示例來說,提示大約占用2000個(gè)字符,每個(gè)調(diào)查反饋平均約20個(gè)字符,映射反饋約為7個(gè)字符。因此,如果我們在每個(gè)提示中放入N個(gè)調(diào)查反饋,最大字符數(shù)應(yīng)為:
2000 + 20N + 7N應(yīng)小于16000。
解這個(gè)等式后,我們得到一個(gè)小于518或大約500的N值。從技術(shù)角度來說,我們可以在每個(gè)請求中放入500個(gè)調(diào)查反饋,并處理我們的數(shù)據(jù)20次。然而,我們選擇在每個(gè)反饋中放入50個(gè)反饋,并進(jìn)行200次處理,因?yàn)槿绻覀冊趩蝹€(gè)請求中放入超過50個(gè)調(diào)查反饋,我們會(huì)偶爾收到異常響應(yīng)。有時(shí)候,服務(wù)可能會(huì)出現(xiàn)問題!我們不確定這是一個(gè)系統(tǒng)的長期問題,還是我們碰巧遇到了不幸的情況。
那么,我們該如何使用我們擁有的API呢?讓我們進(jìn)入精彩部分,代碼。
代碼的方法
Node.js是一個(gè)JavaScript運(yùn)行環(huán)境[9]。我們將編寫一個(gè)Node.js/JavaScript程序,它將按照這個(gè)流程圖所描述的動(dòng)作執(zhí)行操作:
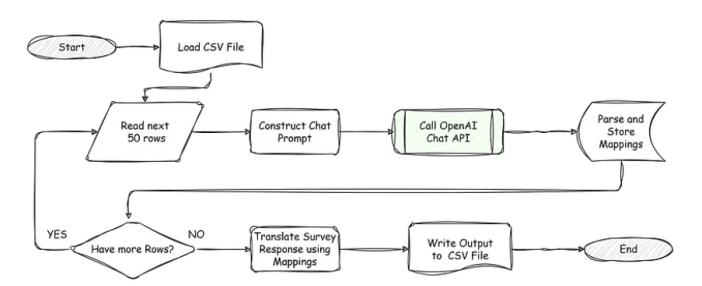
程序的流程圖,由作者繪制
我的Javascript技能并不是那么出色。我可以寫更好的Java,PHP,Julia,Go,C#,甚至Python。但是Esan堅(jiān)持使用Node,所以就用Javascript吧。
完整的代碼,提示和樣本輸入可以在這個(gè)GitHub鏈接(https://github.com/aaxis-nram/data-cleanser-llm-node)中找到。然而,讓我們先看一下最吸引人的部分:
首先,讓我們看看我們?nèi)绾问褂谩癱sv-parser” Node庫來讀取CSV文件。

接下來,我們調(diào)用分類器來生成映射。

然后,我們從類別、主提示文本以及CSV中的數(shù)據(jù)構(gòu)造出提示。接著,我們使用他們的 OpenAI Node 庫將提示發(fā)送給服務(wù)。

最后,當(dāng)所有迭代都完成后,我們可以將 srcCol 文本(即調(diào)查反饋)轉(zhuǎn)換為 targetCol(即標(biāo)準(zhǔn)化的項(xiàng)目名稱),并寫出CSV。

這點(diǎn) JavaScript 并沒有我預(yù)期的那么復(fù)雜,而且在2到3小時(shí)內(nèi)就完成了。我想,任何事情在你開始做之前總是看起來令人生畏的。
所以,現(xiàn)在我們已經(jīng)準(zhǔn)備好了代碼,是時(shí)候進(jìn)行最終的執(zhí)行了…
執(zhí)行過程
現(xiàn)在,我們需要一個(gè)地方來運(yùn)行這個(gè)代碼。在爭論是否應(yīng)該在云實(shí)例上運(yùn)行負(fù)載之后,我做了一些快速的計(jì)算,意識(shí)到我可以在我的筆記本電腦上在不到一個(gè)小時(shí)內(nèi)跑完。這還不算太糟糕。
我們開始進(jìn)行一輪測試,并注意到該服務(wù)在10次請求中有1次會(huì)返回提供給它的數(shù)據(jù),而不是映射數(shù)據(jù)。因此,我們只會(huì)收到調(diào)查反饋的列表。由于沒有找到映射,CSV文件中的這些反饋將被映射為空字符串。
為了避免在代碼中檢測并重試,我決定重新運(yùn)行腳本,但只處理目標(biāo)列為空的記錄。
腳本會(huì)先將所有行的目標(biāo)列設(shè)為空,并填入規(guī)范化的程序名稱。由于響應(yīng)中的錯(cuò)誤,一些行的目標(biāo)列不會(huì)被映射,保持為空。當(dāng)腳本第二次運(yùn)行時(shí),它只會(huì)為第一次運(yùn)行中未處理的響應(yīng)構(gòu)建提示。我們運(yùn)行了幾次程序,并將所有內(nèi)容都映射出來。
多次運(yùn)行大約花費(fèi)了30分鐘左右,并且不需要太多監(jiān)督。以下是模型中一些更有趣的映射的精選:
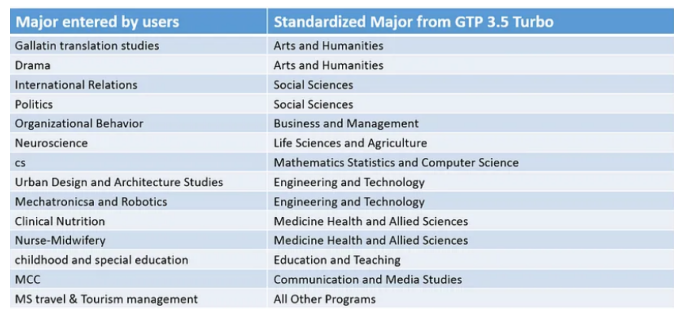
輸入與程序名稱之間的樣例映射,圖表由作者繪制
大多數(shù)看起來都對。不確定組織行為(Organizational Behavior)是否屬于社會(huì)科學(xué)(Social Sciences)或商業(yè)(Business)?我想任何一個(gè)都可以。
每個(gè)大約50條記錄的請求總共需要大約800個(gè)token。整個(gè)練習(xí)的成本是40美分。我們可能在測試、重新運(yùn)行等方面花費(fèi)了10美分。所以,總成本大約是50美分,大約2.5小時(shí)的編碼/測試時(shí)間,半小時(shí)的運(yùn)行時(shí)間,我們完成了任務(wù)。
總成本:大約不到1美元
總時(shí)間:大約3小時(shí)
或許手動(dòng)使用Excel進(jìn)行轉(zhuǎn)換,排序,正則表達(dá)式,和拖拽復(fù)制,我們可能在相同的時(shí)間內(nèi)完成它,并節(jié)省了一點(diǎn)小錢。但是,這樣做更有趣,我們學(xué)到了東西,我們有了可以重復(fù)的腳本/流程,并且還產(chǎn)出了一篇文章。而且,我覺得StudyFetch可以負(fù)擔(dān)得起50美分。
這是我們以高效率,高收益的方式實(shí)現(xiàn)的一個(gè)很好的應(yīng)用,但LLM還可以用于哪些其他用途呢?
探索更多的用例
將語言功能添加到你的應(yīng)用程序中可能有比我上面所示更多的用例。以下是與我們剛剛查看的評論數(shù)據(jù)相關(guān)的更多用例:
數(shù)據(jù)解析和標(biāo)準(zhǔn)化:LLM可以通過識(shí)別和提取非結(jié)構(gòu)化或半結(jié)構(gòu)化數(shù)據(jù)源(如我們剛剛看到的數(shù)據(jù)源)中的相關(guān)信息,幫助解析和標(biāo)準(zhǔn)化數(shù)據(jù)。
數(shù)據(jù)去重:LLM可以通過比較各種數(shù)據(jù)點(diǎn)來幫助識(shí)別重復(fù)記錄。例如,我們可以在評論數(shù)據(jù)中比較姓名、專業(yè)和大學(xué),以標(biāo)記潛在的重復(fù)記錄。
數(shù)據(jù)摘要:LLM可以對不同的記錄進(jìn)行摘要,以了解回答的概況。例如,對于問題“在學(xué)習(xí)過程中你面臨的最大挑戰(zhàn)是什么?”,一個(gè)大語言模型可以對來自同一專業(yè)和大學(xué)的多個(gè)回答進(jìn)行摘要,以查看是否存在任何模式。然后,我們可以將所有的摘要放入一個(gè)請求中,得到一個(gè)整體的列表。但我猜每個(gè)客戶細(xì)分的摘要可能會(huì)更有用。
情感分析:LLM可以分析評論以確定情感,并提取有價(jià)值的見解。對于問題“你愿意為幫助你學(xué)習(xí)的服務(wù)付費(fèi)嗎?”,LLM可以將情感分類為0(非常負(fù)面)到5(非常正面)。然后,我們可以利用這一點(diǎn)通過細(xì)分分析學(xué)生對付費(fèi)服務(wù)的興趣。
盡管學(xué)生評論只是一個(gè)微小的示例,但這項(xiàng)技術(shù)在更廣泛的領(lǐng)域中有著多種應(yīng)用。在我所在的AAXIS公司,我們專注于企業(yè)和消費(fèi)者數(shù)字商務(wù)解決方案。我們的工作包括將大量數(shù)據(jù)從現(xiàn)有的舊系統(tǒng)遷移到具有不同數(shù)據(jù)結(jié)構(gòu)的新系統(tǒng)。為了確保數(shù)據(jù)的一致性,我們使用各種數(shù)據(jù)工具對源數(shù)據(jù)進(jìn)行分析。這篇文章中介紹的技術(shù)對于這個(gè)目標(biāo)非常有幫助。
其他數(shù)字商務(wù)用例包括檢查產(chǎn)品目錄中的錯(cuò)誤、編寫產(chǎn)品說明、掃描評論回復(fù)和生成產(chǎn)品評論摘要等等。相比詢問學(xué)生的專業(yè),編寫這些用例的代碼要簡單得多。
然而,需要注意的是,盡管LLM在數(shù)據(jù)清洗方面是強(qiáng)大的工具,但它們應(yīng)與其他技術(shù)和人工監(jiān)督相結(jié)合使用。數(shù)據(jù)清洗過程通常需要領(lǐng)域?qū)I(yè)知識(shí)、上下文理解和人工審核,以做出明智的決策并保持?jǐn)?shù)據(jù)的完整性。LLM并不是推理引擎[10],它們只是下一個(gè)詞的預(yù)測器。它們往往以極大的自信和說服力提供錯(cuò)誤的信息(幻覺)[2][11]。在我們的測試中,由于我們主要涉及分類,我們沒有遇到任何幻覺的情況。
如果您謹(jǐn)慎行事并了解其中的陷阱,LLM可以成為您工具箱中強(qiáng)大的工具。
尾聲
在這篇文章中,我們首先研究了數(shù)據(jù)清洗的一個(gè)具體應(yīng)用案例:將調(diào)查問卷反饋規(guī)范化為一組特定的值。這樣做可以將反饋進(jìn)行分組并獲得有價(jià)值的見解。為了對這些反饋進(jìn)行分類,我們使用了OpenAI的GPT 3.5 Turbo,一個(gè)強(qiáng)大的LLM。我們詳細(xì)介紹了使用的提示、如何利用API調(diào)用來處理提示以及實(shí)現(xiàn)自動(dòng)化的代碼。最終,我們成功地將所有組件整合在一起,以不到一美元的成本完成了任務(wù)。
我們是不是像拿著一把傳說中的LLM錘子,找到了在自由文本形式的調(diào)查反饋中那顆完美閃亮的釘子?也許吧。更可能的是,我們拿出了一把瑞士軍刀,用它剝皮并享用了一些美味的魚肉。雖然LLM不是專門為此而設(shè)計(jì)的工具,但仍然非常實(shí)用。而且,Esan真的非常喜歡壽司。
那么,你有什么LLM的用例呢?我們非常樂意聽聽你的想法!
鳴謝
本文的主要工作由我、Esan Durrani和Ryan Trattner完成,我們是StudyFetch的聯(lián)合創(chuàng)始人。StudyFetch是一個(gè)基于人工智能的平臺(tái),利用課程資料為學(xué)生創(chuàng)建個(gè)性化的一站式學(xué)習(xí)集。
我要感謝AAXIS Digital的同事Prashant Mishra、Rajeev Hans、Israel Moura和Andy Wagner對本文的審查和建議。
我還要感謝我30年的朋友、TRM Labs的工程副總裁Kiran Bondalapati,感謝他在生成式人工智能領(lǐng)域的初期引導(dǎo)以及對本文的審閱。
同時(shí),我要特別感謝我的編輯Megan Polstra,她一如既往地為文章增添了專業(yè)和精致的風(fēng)格。
-
人工智能
+關(guān)注
關(guān)注
1805文章
48922瀏覽量
248142 -
語言模型
+關(guān)注
關(guān)注
0文章
561瀏覽量
10740 -
AI驅(qū)動(dòng)
+關(guān)注
關(guān)注
0文章
65瀏覽量
4299
原文標(biāo)題:從混沌到清晰:大語言模型如何化繁為簡,開創(chuàng)數(shù)據(jù)清洗新時(shí)代!
文章出處:【微信號(hào):AI智勝未來,微信公眾號(hào):AI智勝未來】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
小白學(xué)大模型:從零實(shí)現(xiàn) LLM語言模型

設(shè)備管理系統(tǒng):從紙筆到智能,跨越時(shí)代的進(jìn)化之旅






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論