") 只需簡單的幾步,2D視頻變3D?最新視頻創(chuàng)作AI模型!
只需簡單的幾步,2D視頻變3D?最新視頻創(chuàng)作AI模型!

文中解決了從描述復(fù)雜動(dòng)態(tài)場景的單目視頻中合成新視圖的問題。作者提出了一種新方法,該方法不是在 MLP 的權(quán)重內(nèi)對整個(gè)動(dòng)態(tài)場景進(jìn)行編碼,而是該方法通過采用基于體積圖像的渲染框架,該框架通過以場景運(yùn)動(dòng)感知的方式聚合來自附近視圖的特征來合成新的視點(diǎn),從而解決了這些限制。此系統(tǒng)保留了先前方法(Dynamicn NeRFs)在對復(fù)雜場景和視圖相關(guān)效果進(jìn)行建模的能力方面的優(yōu)勢,但也能夠從具有無約束相機(jī)軌跡的復(fù)雜場景動(dòng)態(tài)的長視頻合成逼真的新視圖。此方法在動(dòng)態(tài)場景數(shù)據(jù)集上展示了對最先進(jìn)方法的顯著改進(jìn),并將此方法應(yīng)用于具有具有挑戰(zhàn)性的相機(jī)和對象運(yùn)動(dòng)的野外視頻,先前的方法在此應(yīng)用中是無法生成高質(zhì)量的渲染。
1 前言
計(jì)算機(jī)視覺方法現(xiàn)在可以產(chǎn)生具有驚人質(zhì)量的靜態(tài)3D場景的自由視點(diǎn)渲染。那么在移動(dòng)的場景的表現(xiàn)怎么樣呢,比如那些有人物或?qū)櫸锏膱鼍?從動(dòng)態(tài)場景的單目視頻中合成新視圖是一個(gè)更具挑戰(zhàn)性的動(dòng)態(tài)場景重建問題。最近的工作在空間和時(shí)間合成新視圖方面取得了進(jìn)展,這要?dú)w功于新的時(shí)變神經(jīng)體積表示,如HyperNeRF和神經(jīng)場景流場(Neural Scene Flow Fields,NSFF),它們在基于坐標(biāo)的多層感知器(MLP)中對時(shí)空變化的場景內(nèi)容進(jìn)行體積編碼。然而,這些Dynamic NeRF方法有局限性,阻礙了它們在復(fù)雜、戶外視頻中的應(yīng)用。本文提出了一種新的方法(DynIBaR),可以擴(kuò)展到具有1)長時(shí)間持續(xù)時(shí)間、2)無界場景、3)不受控制的攝像機(jī)軌跡以及4)快速和復(fù)雜的物體運(yùn)動(dòng)捕獲的動(dòng)態(tài)視頻。本文的主要貢獻(xiàn)如下:
提出了在場景運(yùn)動(dòng)調(diào)整的光線空間中聚合多視圖圖像特征,這個(gè)方法能夠正確推理時(shí)空變化的幾何和外觀。
為了有效地跨多個(gè)視圖建模場景運(yùn)動(dòng),使用跨越多幀的運(yùn)動(dòng)軌跡場對這種運(yùn)動(dòng)進(jìn)行建模,用學(xué)習(xí)的基函數(shù)表示。
為了在動(dòng)態(tài)場景重建中實(shí)現(xiàn)時(shí)間一致性,引入了一種新的時(shí)間光度損失,該損失在運(yùn)動(dòng)調(diào)整的射線空間中運(yùn)行。這里也推薦「3D視覺工坊」新課程《如何學(xué)習(xí)相機(jī)模型與標(biāo)定?(代碼+實(shí)戰(zhàn))》。
為了提高新視圖的質(zhì)量,提出通過一種新的在貝葉斯學(xué)習(xí)框架中的基于IBR的運(yùn)動(dòng)分割技術(shù)將場景分解為靜態(tài)和動(dòng)態(tài)組件。
2 相關(guān)背景
Novel view synthesis(新視圖生成方法)經(jīng)典的基于圖像的渲染(IBR)方法通過整合輸入圖像的像素信息來合成新視圖,并根據(jù)它們對顯式幾何的依賴進(jìn)行分類。光場或亮度圖渲染方法通過使用顯式幾何模型過濾和插值采樣射線來生成新的視圖。為了處理稀疏輸入視圖,許多方法 利用預(yù)先計(jì)算的代理幾何,例如深度圖或網(wǎng)格來渲染新視圖。
Dynamic scene view synthesis(動(dòng)態(tài)場景視圖合成)大多數(shù)先前關(guān)于動(dòng)態(tài)場景新視圖合成的工作需要多個(gè)同步輸入視頻,限制了它們在現(xiàn)實(shí)世界中的適用性。一些方法使用領(lǐng)域知識(shí)(domian knowledge),例如模板模型(template models)來實(shí)現(xiàn)高質(zhì)量的結(jié)果,但僅限于特定類別的。最近,許多工作建議從單個(gè)相機(jī)合成動(dòng)態(tài)場景的新穎視圖。Yoon等人通過使用通過單視圖深度和多視圖立體(multi view stereo)獲得的深度圖顯式扭曲(explicit warping)來渲染新視圖。然而,這種方法無法對復(fù)雜的場景幾何進(jìn)行建模,并在不遮擋時(shí)填充真實(shí)和一致的內(nèi)容。隨著神經(jīng)渲染的進(jìn)步,基于 NeRF 的動(dòng)態(tài)視圖合成方法顯示了最先進(jìn)的結(jié)果。一些方法,如Nerfies和HyperNeRF,使用變形場(deformation field)表示場景,將每個(gè)局部觀測映射到規(guī)范場景表示。這些變形以時(shí)間或每幀潛碼(per-frame latent code)為條件,參數(shù)化為平移或剛體運(yùn)動(dòng)場。這些方法可以處理長視頻,但大多局限于物體中心場景,物體運(yùn)動(dòng)相對較小,攝像機(jī)路徑控制。其他方法將場景表示為時(shí)變nerf(time-varying nerfs)。特別是,NSFF使用神經(jīng)場景流場,可以捕獲快速和復(fù)雜的3D場景運(yùn)動(dòng),用于戶外視頻。然而,這種方法僅適用于短(1-2 秒)、面向前向視頻。
3 方法
本文的網(wǎng)絡(luò)將給定一個(gè)具有幀的動(dòng)態(tài)場景的單目視頻(I1, I2,…,, IN ) 和已知的相機(jī)參數(shù) (P1, P2,., PN ),目標(biāo)是在視頻中任何所需時(shí)間合成一個(gè)新的視點(diǎn)。與許多其他方法一樣,此方法訓(xùn)練每個(gè)視頻,首先優(yōu)化模型來重建輸入幀,然后使用該模型渲染新視圖。
3.1 Motion-adjusted feature aggregation(運(yùn)動(dòng)調(diào)整的特征聚合)
我們通過聚合從某一時(shí)刻附近的源視圖中提取的特征來合成新的視圖。為了渲染時(shí)刻i的圖像,我們首先在i的時(shí)間半徑r幀內(nèi)識(shí)別源視圖Ij, j∈N (i) = [i?r, i + r]。對于每個(gè)源視圖,我們通過共享卷積編碼器網(wǎng)絡(luò)提取一個(gè)二維特征圖Fi,形成一個(gè)輸入元組{Ij, Pj, Fj}。
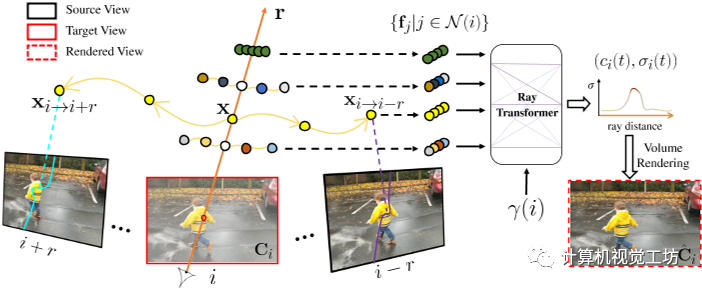
圖 2. 通過運(yùn)動(dòng)調(diào)整的多視圖特征聚合渲染。給定沿目標(biāo)射線r在時(shí)間i的采樣位置x,我們估計(jì)其運(yùn)動(dòng)軌跡,它確定x在附近時(shí)間j∈N (i)處的3D對應(yīng)關(guān)系,記為xi→j。然后將每個(gè)扭曲點(diǎn)投影到其對應(yīng)的源視圖中。沿投影曲線提取的圖像特征 fj 被聚合并饋送到具有時(shí)間嵌入 γ(i) 的光線轉(zhuǎn)換器,產(chǎn)生每個(gè)樣本的顏色和密度 (ci, σi)。然后通過沿 r 的體積渲染 (ci, σi) 合成最終像素顏色 ^Ci。
為了預(yù)測沿目標(biāo)射線r采樣的每個(gè)點(diǎn)的顏色和密度,我們必須在考慮場景運(yùn)動(dòng)的同時(shí)聚合源視圖特征。對于靜態(tài)場景,沿目標(biāo)射線的點(diǎn)將位于相鄰源視圖中對應(yīng)的極線上,通過簡單地沿相鄰極線采樣來聚合潛在的對應(yīng)關(guān)系。然而移動(dòng)場景元素違反極線約束,導(dǎo)致特征聚合不一致。因此,作者執(zhí)行運(yùn)動(dòng)調(diào)整(motion-adjust)特征聚合。**Motion trajectory fileds(運(yùn)動(dòng)軌跡場) **文中使用根據(jù)學(xué)習(xí)基函數(shù)描述的運(yùn)動(dòng)軌跡場來表示場景運(yùn)動(dòng)。對于時(shí)刻i沿目標(biāo)射線r的給定3D點(diǎn)x,用MLP GMT編碼其軌跡系數(shù):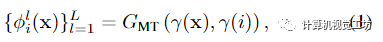 其中
其中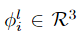 是基系數(shù)(使用下面描述的運(yùn)動(dòng)基,x、y、z分別有系數(shù)),γ表示位置編碼。本文還引入了全局可學(xué)習(xí)的運(yùn)動(dòng)基
是基系數(shù)(使用下面描述的運(yùn)動(dòng)基,x、y、z分別有系數(shù)),γ表示位置編碼。本文還引入了全局可學(xué)習(xí)的運(yùn)動(dòng)基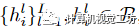 ,它跨越輸入視頻的每一個(gè)時(shí)間步長i,并與MLP聯(lián)合優(yōu)化。將x的運(yùn)動(dòng)軌跡定義為
,它跨越輸入視頻的每一個(gè)時(shí)間步長i,并與MLP聯(lián)合優(yōu)化。將x的運(yùn)動(dòng)軌跡定義為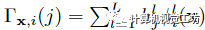 ,則在j時(shí)刻x與其三維對應(yīng)xi→j之間的相對位移計(jì)算為:
,則在j時(shí)刻x與其三維對應(yīng)xi→j之間的相對位移計(jì)算為: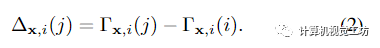 使用這種運(yùn)動(dòng)軌跡表示,在鄰近視圖中查找查詢點(diǎn)x的3D對應(yīng)關(guān)系只需要一個(gè)MLP查詢,從而在本文的體繪制框架內(nèi)實(shí)現(xiàn)高效的多視圖特征聚合。利用x在時(shí)刻i的估計(jì)運(yùn)動(dòng)軌跡,作者將x在時(shí)刻j對應(yīng)的三維點(diǎn)記為。使用相機(jī)參數(shù)將每個(gè)扭曲點(diǎn)投影到其源視圖中,并在投影的2D像素位置提取顏色和特征向量。通過加權(quán)平均池化將輸出特征聚合到共享MLP中,從而在沿射線r的每個(gè)3D樣本點(diǎn)處生成單個(gè)特征向量。然后,具有時(shí)間嵌入的Ray Transformer網(wǎng)絡(luò)沿射線處理聚合特征序列,以預(yù)測每個(gè)樣本的顏色和密度。然后,我們使用標(biāo)準(zhǔn)NeRF體渲染,從這個(gè)顏色和密度序列中獲得射線的最終像素顏色。
使用這種運(yùn)動(dòng)軌跡表示,在鄰近視圖中查找查詢點(diǎn)x的3D對應(yīng)關(guān)系只需要一個(gè)MLP查詢,從而在本文的體繪制框架內(nèi)實(shí)現(xiàn)高效的多視圖特征聚合。利用x在時(shí)刻i的估計(jì)運(yùn)動(dòng)軌跡,作者將x在時(shí)刻j對應(yīng)的三維點(diǎn)記為。使用相機(jī)參數(shù)將每個(gè)扭曲點(diǎn)投影到其源視圖中,并在投影的2D像素位置提取顏色和特征向量。通過加權(quán)平均池化將輸出特征聚合到共享MLP中,從而在沿射線r的每個(gè)3D樣本點(diǎn)處生成單個(gè)特征向量。然后,具有時(shí)間嵌入的Ray Transformer網(wǎng)絡(luò)沿射線處理聚合特征序列,以預(yù)測每個(gè)樣本的顏色和密度。然后,我們使用標(biāo)準(zhǔn)NeRF體渲染,從這個(gè)顏色和密度序列中獲得射線的最終像素顏色。
3.2 Cross-time rendering for temporal consistency(跨時(shí)間渲染以實(shí)現(xiàn)時(shí)間一致性)
如果通過單獨(dú)比較和 來優(yōu)化我們的動(dòng)態(tài)場景表示,則表示可能會(huì)過度擬合輸入圖像。這可能是因?yàn)楸硎居心芰槊總€(gè)時(shí)間實(shí)例重建完全獨(dú)立的模型,而無需利用或準(zhǔn)確地重建場景運(yùn)動(dòng)。因此,為了恢復(fù)具有物理上合理的運(yùn)動(dòng)的一致場景,本文強(qiáng)制場景表示的時(shí)間相干性。在這種情況下定義時(shí)間一致性的一種方法是在考慮場景運(yùn)動(dòng)時(shí),兩個(gè)相鄰時(shí)間 i 和 j 的場景應(yīng)該是一致的。
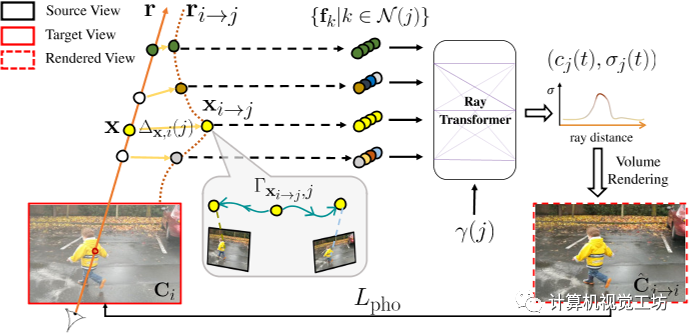
圖三:通過跨時(shí)間渲染實(shí)現(xiàn)時(shí)間一致性。為了加強(qiáng)動(dòng)態(tài)重建中的時(shí)間一致性,我們使用來自附近時(shí)間j的場景模型渲染每個(gè)幀Ii,我們稱之為跨時(shí)間渲染。圖像i中的射線r使用彎曲射線ri→j渲染,即r扭曲到時(shí)間j。也就是說,從沿r的每個(gè)采樣位置計(jì)算出在時(shí)間j附近的運(yùn)動(dòng)調(diào)整點(diǎn)xi→j = x+?x,i(j),我們通過MLP查詢xi→j和時(shí)間j,預(yù)測其運(yùn)動(dòng)軌跡Γxi→j,j,我們將從時(shí)間k∈N (j)內(nèi)的源視圖中提取的圖像特征fk聚合在一起。沿著ri→jr聚合的特征通過時(shí)間嵌入γ(j)輸入到射線轉(zhuǎn)換器中,在j時(shí)刻生成每個(gè)樣本的顏色和密度(cj, σj)。通過體繪制計(jì)算得到像素顏色(cj, σj) mj→iis,然后與地面真色Ci進(jìn)行比較,形成重建損失Lpho。
特別是,本文通過在運(yùn)動(dòng)調(diào)整的光線空間中的跨時(shí)間渲染來加強(qiáng)優(yōu)化表示中的時(shí)間光度一致性。具體為通過時(shí)間i附近的某個(gè)時(shí)間j來時(shí)間i渲染視圖,稱之為跨時(shí)間渲染。對于每個(gè)附近的時(shí)間 j ∈ N (i),不是直接使用沿光線 r 的點(diǎn) x,而是考慮沿運(yùn)動(dòng)調(diào)整的光線 的點(diǎn) 并將它們視為它們位于時(shí)間 j 的光線上。具體來說,在計(jì)算運(yùn)動(dòng)調(diào)整點(diǎn)時(shí),查詢MLP來預(yù)測新軌跡并使用公式2計(jì)算時(shí)間窗口N (j)中圖像k對應(yīng)的3D點(diǎn)然后使用這些新的三維對應(yīng)關(guān)系精確地渲染像素顏色,如第3.1節(jié)中“直”射線所述,除了現(xiàn)在沿著彎曲的、運(yùn)動(dòng)調(diào)整的射線 。也就是,每個(gè)點(diǎn)被投影到其源視圖和具有相機(jī)參數(shù) 的特征圖 以提取 RGB 顏色和圖像特征 ,然后將這些特征聚合并輸入到具有時(shí)間嵌入 的光線轉(zhuǎn)換器。結(jié)果是在時(shí)間j沿的顏色和密度序列,可以通過體繪制合成以形成顏色。然后通過運(yùn)動(dòng)錯(cuò)位感知 RGB 重建損失將 與目標(biāo)像素 進(jìn)行比較
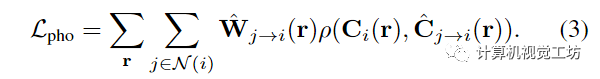
對 RGB 損失 ρ 使用廣義 Charbonnier 損失,是運(yùn)動(dòng)錯(cuò)位權(quán)重,由時(shí)間 i 和 j 之間的累積 alpha 權(quán)重的差異計(jì)算,以解決 NSSF 描述的運(yùn)動(dòng)錯(cuò)位歧義。
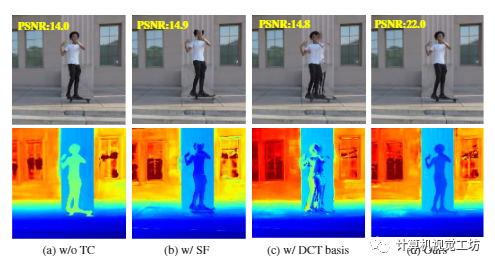
圖4 定性消融。從左到右,我們展示了我們的系統(tǒng) (a) 中渲染的新視圖(頂部)和深度(底部),而不強(qiáng)制執(zhí)行時(shí)間一致性,(b) 使用場景流場而不是運(yùn)動(dòng)軌跡聚合圖像特征,(c) 表示具有固定 DCT 基礎(chǔ)的運(yùn)動(dòng)軌跡而不是學(xué)習(xí)的視圖,以及 (d) 具有完整配置。簡單配置顯著降低了渲染質(zhì)量
上圖的第一列中展示了使用和不使用時(shí)間一致性的方法之間的比較。
3.3 Combining static and dynamic models(結(jié)合靜態(tài)和動(dòng)態(tài)模型)
正如在NSFF中觀察到的,使用小時(shí)間窗口合成新視圖不足以恢復(fù)靜態(tài)場景區(qū)域的完整和高質(zhì)量的內(nèi)容,因?yàn)橄鄼C(jī)路徑不受控制的,內(nèi)容只能在空間上遙遠(yuǎn)的幀中觀察到。因此,我們遵循NSFF的思想,并使用兩個(gè)獨(dú)立的表示對整個(gè)場景進(jìn)行建模。動(dòng)態(tài)內(nèi)容 用如上所述的時(shí)變模型表示(在優(yōu)化過程中用于跨時(shí)間渲染)。靜態(tài)內(nèi)容用時(shí)不變模型表示,該模型以與時(shí)變模型相同的方式呈現(xiàn),但在沒有場景運(yùn)動(dòng)調(diào)整(即沿極線)的情況下聚合多視圖特征。使用NeRF-W的靜態(tài)和瞬態(tài)模型相結(jié)合的方法,將動(dòng)態(tài)和靜態(tài)預(yù)測組合成單個(gè)輸出顏色(或跨時(shí)間渲染期間的)。每個(gè)模型都的顏色和密度估計(jì)也可以單獨(dú)渲染,為靜態(tài)內(nèi)容提供顏色,為動(dòng)態(tài)內(nèi)容提供。結(jié)合這兩種表示時(shí),我們將公式3中的光度一致性項(xiàng)重寫為將與目標(biāo)像素 進(jìn)行比較的損失:
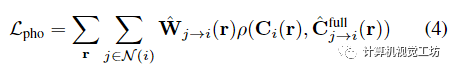
Image-based motion segmentation(基于圖像的運(yùn)動(dòng)分割)在本文的框架中,作者觀察到,在沒有任何初始化的情況下,場景分解往往以時(shí)不變或時(shí)變表示為主。為了便于分解,作者提出了一種新的運(yùn)動(dòng)分割模塊,該模塊生成分割掩碼來監(jiān)督本文的主要雙分量場景表示。該想法是受到最近的工作中提出的貝葉斯學(xué)習(xí)技術(shù)的啟發(fā),但集成到動(dòng)態(tài)視頻的體積IBR表示中。在訓(xùn)練主要雙分量場景表示之前,聯(lián)合訓(xùn)練兩個(gè)輕量級模型來獲得每個(gè)輸入幀的運(yùn)動(dòng)分割掩碼。使用IBRNet對靜態(tài)場景內(nèi)容進(jìn)行建模,IBRNet通過沿附近源視圖的極線特征聚合沿每條射線渲染像素顏色,而不考慮場景運(yùn)動(dòng);我們使用二維卷積編碼器-解碼器網(wǎng)絡(luò)D對動(dòng)態(tài)場景內(nèi)容進(jìn)行建模,該網(wǎng)絡(luò)從輸入幀預(yù)測二維不透明度圖、置信圖和RGB圖像: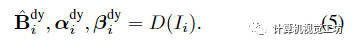 然后,從兩個(gè)模型的輸出像素級合成完整的重建圖像:
然后,從兩個(gè)模型的輸出像素級合成完整的重建圖像: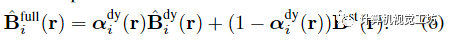 為了分割移動(dòng)對象,我們假設(shè)觀察到的像素顏色以異方差任意方式不確定,并使用具有時(shí)間依賴置信度 的 Cauchy 分布對視頻中的觀察結(jié)果進(jìn)行建模。通過取觀察的負(fù)對數(shù)似然,我們的分割損失寫成加權(quán)重建損失:
為了分割移動(dòng)對象,我們假設(shè)觀察到的像素顏色以異方差任意方式不確定,并使用具有時(shí)間依賴置信度 的 Cauchy 分布對視頻中的觀察結(jié)果進(jìn)行建模。通過取觀察的負(fù)對數(shù)似然,我們的分割損失寫成加權(quán)重建損失:
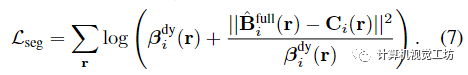
下圖展示了我們估計(jì)的運(yùn)動(dòng)分割掩碼疊加在輸入圖像上。

圖 5. 運(yùn)動(dòng)分割。我們展示了覆蓋渲染動(dòng)態(tài)內(nèi)容*(底部)的完整渲染(頂部)和運(yùn)動(dòng)分割。我們的方法分割具有挑戰(zhàn)性的動(dòng)態(tài)元素,例如移動(dòng)陰影、擺動(dòng)和搖擺灌木。
Supervision with segmentation masks(基于分割掩碼的監(jiān)督)本文使用掩碼初始化主要時(shí)變和時(shí)不變模型,如Omnimatte,通過將重構(gòu)損失應(yīng)用于動(dòng)態(tài)區(qū)域的時(shí)變模型的渲染,并從靜態(tài)區(qū)域的時(shí)不變模型渲染:
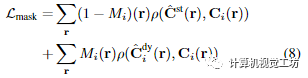
對進(jìn)行形態(tài)侵蝕和膨脹,分別得到動(dòng)態(tài)區(qū)域和靜態(tài)區(qū)域的掩模,從而關(guān)閉掩模邊界附近的損失。我們用 Lmask 監(jiān)督系統(tǒng),每 50K 優(yōu)化步驟將動(dòng)態(tài)區(qū)域的權(quán)重衰減 5 倍。
3.4 Regularization(正則化)
如前所述,復(fù)雜動(dòng)態(tài)場景的單目重建是高度不適定的,單獨(dú)使用光度一致性不足以在優(yōu)化過程中避免糟糕的局部極小值。因此,我們采用先前工作中使用的正則化方案,該方案由三個(gè)主要部分組成是一個(gè)數(shù)據(jù)驅(qū)動(dòng)的術(shù)語,由單眼深度和光流一致性先驗(yàn)組成,使用Zhang等人和RAFT的估計(jì)。是一個(gè)運(yùn)動(dòng)軌跡正則化項(xiàng),它鼓勵(lì)估計(jì)的軌跡場是周期一致的和時(shí)空平滑的。是一個(gè)緊實(shí)先驗(yàn),它鼓勵(lì)場景分解通過熵?fù)p失二進(jìn)制,并通過失真損失減輕漂浮物。參考補(bǔ)充以獲取更多詳細(xì)信息。總之,用于優(yōu)化時(shí)空視圖合成的主要表示的最終組合損失是: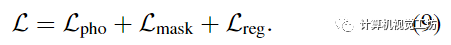
4 實(shí)驗(yàn)
4.1 Baselines and error metrics-評價(jià)指標(biāo)
對比對象:Nerfies, HyperNeRF, NSFF, DVS評價(jià)指標(biāo):峰值信噪比 (PSNR)、結(jié)構(gòu)相似性 (SSIM) 、通過 LPIPS 的感知相似性 ,并計(jì)算整個(gè)場景 (Full) 的誤差并僅限于移動(dòng)區(qū)域 (Dynamic Only)。這里也推薦「3D視覺工坊」新課程《如何學(xué)習(xí)相機(jī)模型與標(biāo)定?(代碼+實(shí)戰(zhàn))》。
4.2 Quantitative evaluation-定量評價(jià)
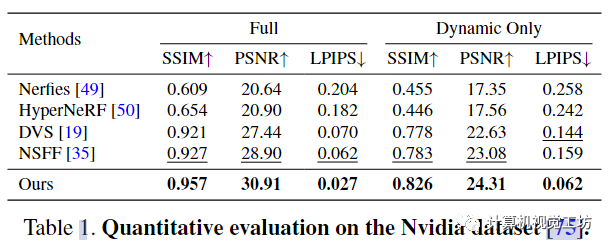
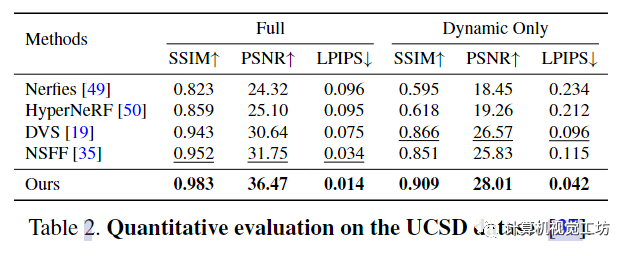
這些結(jié)果表明,本文的框架在恢復(fù)高度詳細(xì)的場景內(nèi)容方面更有效。
4.3 Ablations - 消融研究
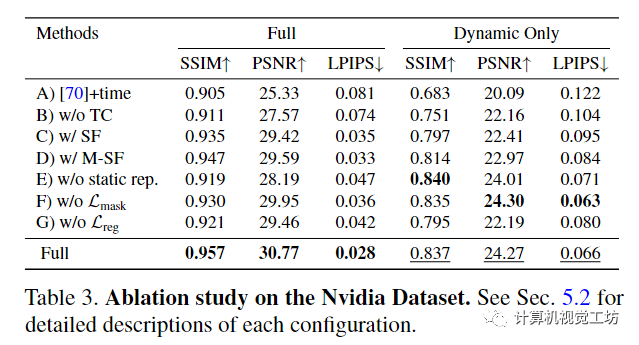
image.png
A)基線IBRNet,具有額外的時(shí)間嵌入;B)不通過跨時(shí)間渲染強(qiáng)制時(shí)間一致性;C)使用場景流場在一個(gè)時(shí)間步內(nèi)聚合圖像特征;D)預(yù)測多個(gè)3D場景流向量,指向每個(gè)樣本附近2r次;E)不使用時(shí)不變靜態(tài)場景模型;F)通過估計(jì)的運(yùn)動(dòng)分割掩碼沒有掩模重建損失;G)沒有正則化損失。
對于該項(xiàng)消融研究,使用每條射線 64 個(gè)樣本訓(xùn)練每個(gè)模型。如果沒有我們的運(yùn)動(dòng)軌跡表示和時(shí)間一致性,視圖合成質(zhì)量顯著下降,如表3的前三行所示。集成全局空間坐標(biāo)嵌入進(jìn)一步提高了渲染質(zhì)量。結(jié)合靜態(tài)和動(dòng)態(tài)模型可以提高靜態(tài)元素的質(zhì)量,如完整場景的指標(biāo)所示。最后,從運(yùn)動(dòng)分割或正則化中去除監(jiān)督會(huì)降低整體渲染質(zhì)量,證明了在優(yōu)化過程中避免不良局部最小值的建議損失值。


先前的動(dòng)態(tài)NeRF方法很難渲染運(yùn)動(dòng)物體的細(xì)節(jié),如過于模糊的動(dòng)態(tài)內(nèi)容所示,包括氣球、人臉和服裝的紋理。相比之下,本文的方法綜合了靜態(tài)和動(dòng)態(tài)場景內(nèi)容的照片真實(shí)感新視圖,最接近地面真實(shí)圖像。


本文的方法綜合了逼真的新視圖,而先前的動(dòng)態(tài)Nerf方法無法恢復(fù)靜態(tài)和動(dòng)態(tài)場景內(nèi)容的高質(zhì)量細(xì)節(jié),例如圖8中的襯衫皺紋和狗的毛皮。另一方面,顯式深度扭曲在咬合和視野外的區(qū)域產(chǎn)生孔洞。
5 Discussion and conclusion-討論與總結(jié)
Limitations(局限):由于不正確的初始深度和光流估計(jì),我們的方法無法處理小的快速運(yùn)動(dòng)物體;與之前的動(dòng)態(tài)NeRF方法相比,合成的視圖并不是嚴(yán)格的多視圖一致,靜態(tài)內(nèi)容的渲染質(zhì)量取決于選擇哪個(gè)源視圖;本文的方法能夠合成僅出現(xiàn)在遙遠(yuǎn)時(shí)間的動(dòng)態(tài)內(nèi)容

我們的方法可能無法對移動(dòng)薄物體進(jìn)行建模,例如移動(dòng)皮帶(左)。我們的方法只能渲染在遠(yuǎn)距離幀(中間)中可見的動(dòng)態(tài)內(nèi)容。如果為給定像素聚合源視圖特征不足(右),則渲染的靜態(tài)內(nèi)容可能不切實(shí)際或空白。
結(jié)論:本文提出了一種從描述復(fù)雜動(dòng)態(tài)場景的單目視頻中合成時(shí)空視圖合成的新方法。通過在體積IBR框架內(nèi)表示動(dòng)態(tài)場景,克服了最近的方法無法對具有復(fù)雜相機(jī)和物體運(yùn)動(dòng)的長視頻進(jìn)行建模的局限性。實(shí)驗(yàn)已經(jīng)證明,本文的方法可以從野外動(dòng)態(tài)視頻中合成照片逼真的新視圖,并且可以在動(dòng)態(tài)場景基準(zhǔn)上比以前的最先進(jìn)方法取得顯著改進(jìn)。
-
3D
+關(guān)注
關(guān)注
9文章
2956瀏覽量
110505 -
AI
+關(guān)注
關(guān)注
88文章
34839瀏覽量
277445 -
模型
+關(guān)注
關(guān)注
1文章
3506瀏覽量
50235
原文標(biāo)題:CVPR 2023 ,只需簡單的幾步,2D視頻變3D?最新視頻創(chuàng)作AI模型!
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
ModelSource免費(fèi)的原理圖,PCB組件庫 和 2D & 3D 模型下載
ModelSource免費(fèi)的原理圖,PCB組件庫 和 2D & 3D 模型下載
Dialog半導(dǎo)體推出首款2D到3D視頻轉(zhuǎn)換芯片,為智能手機(jī)
全球首款2D/3D視頻轉(zhuǎn)換實(shí)時(shí)處理芯片:DA8223
2D到3D視頻自動(dòng)轉(zhuǎn)換系統(tǒng)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論