") jdk17下netty導(dǎo)致堆內(nèi)存瘋漲原因排查
jdk17下netty導(dǎo)致堆內(nèi)存瘋漲原因排查

來源| OSCHINA 社區(qū)
作者 | 京東云開發(fā)者社區(qū)-京東零售 劉鵬
背景:
介紹
天網(wǎng)風(fēng)控靈璣系統(tǒng)是基于內(nèi)存計算實現(xiàn)的高吞吐低延遲在線計算服務(wù),提供滑動或滾動窗口內(nèi)的 count、distinctCout、max、min、avg、sum、std 及區(qū)間分布類的在線統(tǒng)計計算服務(wù)。客戶端和服務(wù)端底層通過 netty 直接進行 tcp 通信,且服務(wù)端也是基于 netty 將數(shù)據(jù)備份到對應(yīng)的 slave 集群。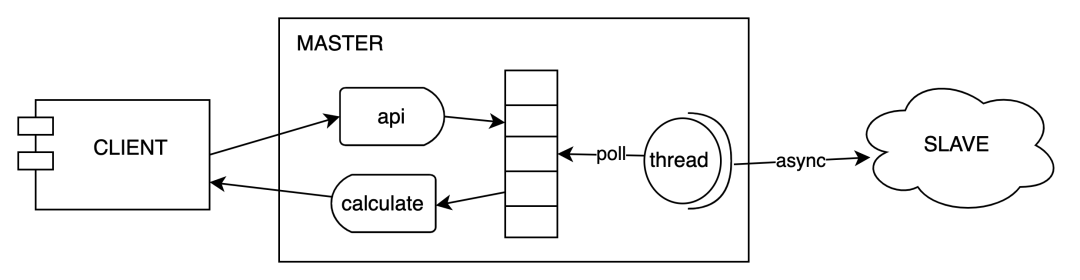
低延遲的瓶頸
靈璣第 1 個版本經(jīng)過大量優(yōu)化,系統(tǒng)能提供較大的吞吐量。如果對客戶端設(shè)置 10ms 超時,服務(wù)端 1wqps/core 的流量下,可用率只能保證在 98.9% 左右,高并發(fā)情況下主要是 gc 導(dǎo)致可用率降低。如果基于 cms 垃圾回收器。當(dāng)一臺 8c16g 的機器在經(jīng)過第二個版本優(yōu)化后吞吐量超過 20wqps 的時候,那么大概每 4 秒會產(chǎn)生一次 gc。如果按照一次 gc 等于 30ms。那么至少分鐘顆粒度在 gc 時間的占比至少在 (15*30/1000/60)=0.0075。也就意味著分鐘級別的 tp992 至少在 30ms。不滿足相關(guān)業(yè)務(wù)的需求。
jdk17+ZGC
為了解決上述延遲過高的相關(guān)問題,JDK 11 開始推出了一種低延遲垃圾回收器 ZGC。ZGC 使用了一些新技術(shù)和優(yōu)化算法,可以將 GC 暫停時間控制在 10 毫秒以內(nèi),而在 JDK 17 的加持下,ZGC 的暫停時間甚至可以控制在亞毫秒級別。實測在平均停頓時間在 10us 左右,主要是基于一個染色指針和讀屏障做到大多數(shù) gc 階段可以做到并發(fā)的,有興趣的同學(xué)可以了解下,并且 jdk17 是一個 lts 版本。
問題:
采用 jdk17+zgc 經(jīng)過相關(guān)的壓測后,一切都在向著好的方向發(fā)展,但是在一種特殊場景壓測,需要將數(shù)據(jù)從北京數(shù)據(jù)中心同步給宿遷數(shù)據(jù)中心的時候,發(fā)現(xiàn)了一些詭異的事情
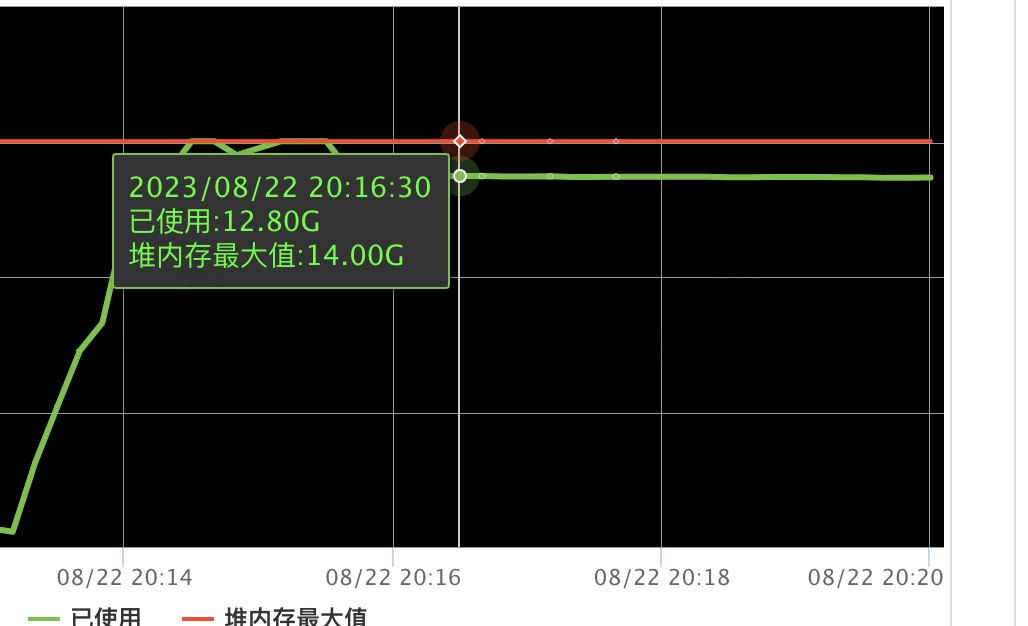
服務(wù)端容器的內(nèi)存瘋漲,并且停止壓測后,內(nèi)存只是非常緩慢的減少。
相關(guān)機器 cpu 一直保存在 20%(已經(jīng)無流量請求)
一直在次數(shù)不多的 gc。大概每 10s 一次
排查之旅
內(nèi)存泄漏排查
第一反應(yīng)是遇到內(nèi)存瘋漲和無法釋放該問題時,首先歸納為內(nèi)存泄漏問題,感覺這題也簡單明了。開始相關(guān)內(nèi)存泄漏檢查:先 dump 堆內(nèi)存分析發(fā)現(xiàn)占用堆內(nèi)存的是 netty 相關(guān)的對象,恰好前段時間也有個同學(xué)也分享了 netty 下的不合理使用 netty byteBuf 導(dǎo)致的內(nèi)存泄漏,進一步增加了對 netty 內(nèi)存泄露的懷疑。于是開啟 netty 內(nèi)存泄漏嚴(yán)格檢查模式 (加上 jvm 參數(shù) Dio.netty.leakDetection.level=PARANOID),重新試跑并沒有發(fā)現(xiàn)相關(guān)內(nèi)存泄漏日志。好吧~!初步判定不是 netty 內(nèi)存泄漏。 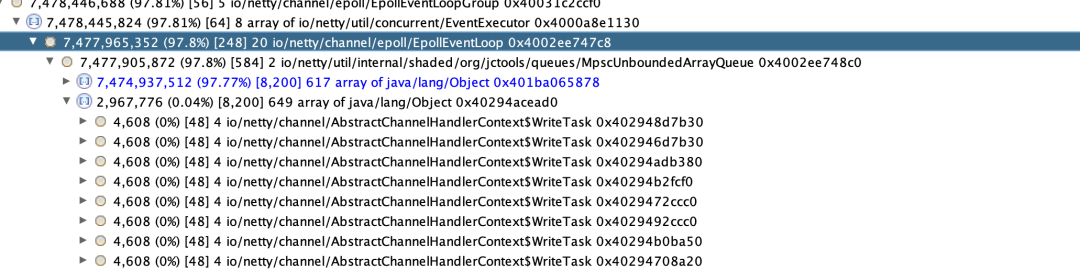
jdk 與 netty 版本 bug 排查
會不會是 netty 與 jdk17 兼容不好導(dǎo)致的 bug? 回滾 jdk8 測試發(fā)現(xiàn)的確不存在這個問題,當(dāng)時使用的是 jdk17.0.7 版本。正好官方發(fā)布了 jdk17.0.8 版本,并且看到版本介紹上有若干的 Bug Fixes。所以又升級了 jdk 一個小版本,然而發(fā)現(xiàn)問題仍然在。會不會是 netty 的版本過低?正好看見 gitup 上也有類似的 issue# https://github.com/netty/netty/issues/6125WriteBufferWaterMark's 并且在高版本疑似修復(fù)了該問題,修改了 netty 幾個版本重新壓測,然而發(fā)現(xiàn)問題仍然在。
直接原因定位與解決
經(jīng)過上述兩次排查,發(fā)現(xiàn)問題比想象中復(fù)雜,應(yīng)該深入分析下為什么,重新梳理了下相關(guān)線索:
發(fā)現(xiàn)回滾至 jdk8 的時候,對應(yīng)宿遷中心的集群接受到的備份數(shù)據(jù)量比北京中心發(fā)送的數(shù)據(jù)量低了很多
為什么沒有流量了還一直有 gc,cpu 高應(yīng)該是 gc 造成的(當(dāng)時認(rèn)為是 zgc 的內(nèi)存的一些特性)
內(nèi)存分析:為什么 netty 的 MpscUnboundedArrayQueue 引用了大量的 AbstractChannelHandlerContext$WriteTask 對象,。MpscUnboundedArrayQueue 是生產(chǎn)消費 writeAndFlush 任務(wù)隊列,WriteTask 是相關(guān)的 writeAndFlush 的任務(wù)對象,正是因為大量的 WriteTask 對象及其引用導(dǎo)致了內(nèi)存占用過高。
只有跨數(shù)據(jù)中心出現(xiàn)該問題,同數(shù)據(jù)中心數(shù)據(jù)壓測不會出現(xiàn)該問題。
分析過后已經(jīng)有了基本的猜想,因為跨數(shù)據(jù)中心下機房延遲更大,單 channel 信道下已經(jīng)沒法滿足同步數(shù)據(jù)能力,導(dǎo)致 netty 的 eventLoop 的消費能不足導(dǎo)致積壓。 解決方案:增加與備份數(shù)據(jù)節(jié)點的 channel 信道連接,采用 connectionPool,每次批量同步數(shù)據(jù)的時候隨機選擇一個存活的 channel 進行數(shù)據(jù)通信。經(jīng)過相關(guān)改造后發(fā)現(xiàn)問題得到了解決。
根因定位與解決
根因定位
雖然經(jīng)過上述的改造,表面上看似解決了問題,但是問題的根本原因還是沒有被發(fā)現(xiàn)
1. 如果是 eventLoop 消費能力不足,為什么停止壓測后,相關(guān)內(nèi)存只是緩慢減少,按理說應(yīng)該是瘋狂的內(nèi)存減少。
2. 為什么一直 cpu 在 23% 左右,按照平時的壓測數(shù)據(jù),同步數(shù)據(jù)是一個流轉(zhuǎn)批的操作,最多也就消耗 5% cpu 左右,多出來的 cpu 應(yīng)該是 gc 造成的,但是數(shù)據(jù)同步應(yīng)該并不多,不應(yīng)該造成這么多的 gc 壓力。
3. 為什么 jdk8 下不會存在該問題
推測應(yīng)該是有個 netty eventLoop 消費耗時阻塞的操作導(dǎo)致消費能力大幅度下降。所以感覺還是 netty 的問題,于是開了 netty 的相關(guān) debug 日志。發(fā)現(xiàn)了一行關(guān)鍵日志
[2023-08-23 1116.163] DEBUG [] - io.netty.util.internal.PlatformDependent0 - direct buffer constructor: unavailable: Reflective setAccessible(true) disabled順著這條日志找到了本次的問題根因,為什么一個直接內(nèi)存的構(gòu)造器不能使用會導(dǎo)致我們系統(tǒng) WriteTask 消費阻塞, 帶著這個目的去查看相關(guān)的源碼。
源碼分析
一) netty 默認(rèn)會用 PooledByteBufAllocator 來分配直接內(nèi)存,采用類似 jmelloc 的內(nèi)存池機制,每次內(nèi)存不足的時候會通過創(chuàng)建 io.netty.buffer.PoolArena.DirectArena#newChunk 去預(yù)占申請內(nèi)存。
protected PoolChunknewChunk() { // 關(guān)鍵代碼 ByteBuffer memory = allocateDirect(chunkSize); } }
二) allocateDirect () 是申請直接內(nèi)存的邏輯。大致就是如果能采用底層 unsafe 去申請、釋放直接內(nèi)存和反射創(chuàng)建 ByteBuffer 對象,那么就采用 unsafe。否則就直接調(diào)用 java 的 Api ByteBuffer.allocateDirect 來直接分配內(nèi)存并且采用自帶的 Cleaner 來釋放內(nèi)存。這里 PlatformDependent.useDirectBufferNoCleaner 是個關(guān)鍵點,其實就是 USE_DIRECT_BUFFER_NO_CLEANER 參數(shù)配置
PlatformDependent.useDirectBufferNoCleaner() ?
PlatformDependent.allocateDirectNoCleaner(capacity) : ByteBuffer.allocateDirect(capacity);
三) USE_DIRECT_BUFFER_NO_CLEANER 參數(shù)邏輯配置在 PlatformDependent 類的 static {} 里面。
關(guān)鍵邏輯:maxDirectMemory==0 和!hasUnsafe () 在 jdk17 下沒有特殊配置都是不滿足條件的,關(guān)鍵是 PlatformDependent0.hasDirectBufferNoCleanerConstructor 的判斷邏輯
if (maxDirectMemory == 0 || !hasUnsafe() || !PlatformDependent0.hasDirectBufferNoCleanerConstructor()) { USE_DIRECT_BUFFER_NO_CLEANER = false; } else { USE_DIRECT_BUFFER_NO_CLEANER = true;
四) PlatformDependent0.hasDirectBufferNoCleanerConstructor () 的判斷是看 PlatformDependent0 的 DIRECT_BUFFER_CONSTRUCTOR 是否 NULL,回到了剛開的 debug 日志,我們是可以看到在默認(rèn)情況下 DIRECT_BUFFER_CONSTRUCTOR 該構(gòu)造器是 unavailable 的(unavailable 則為 NULL)。以下代碼具體的邏輯判斷及其偽代碼。
1. 開啟條件一:jdk9 及其以上必須要開啟 jvm 參數(shù) -io.netty.tryReflectionSetAccessible 參數(shù) 2. 開啟條件二:能反射獲取到一個 private DirectByteBuffer 構(gòu)造器,該構(gòu)造器是通過內(nèi)存地址和大小來構(gòu)造 DirectByteBuffer.(備注:如果在 jdk9 以上對 java.nio 有模塊權(quán)限限制,需要加上 jvm 啟動參數(shù) --add-opens=java.base/java.nio=ALL-UNNAMED , 否則會報 Unable to make private java.nio.DirectByteBuffer (long,int) accessible: module java.base does not "opens java.nio" to unnamed module) 所以這里我們默認(rèn)是沒有開啟這兩個 jvm 參數(shù)的,那么 DIRECT_BUFFER_CONSTRUCTOR 為空值,對應(yīng)第二部 PlatformDependent.useDirectBufferNoCleaner () 為 false。
// 偽代碼,實際與這不一致
ByteBuffer direct = ByteBuffer.allocateDirect(1);
if(SystemPropertyUtil.getBoolean("io.netty.tryReflectionSetAccessible",
javaVersion() < 9 || RUNNING_IN_NATIVE_IMAGE)) {
DIRECT_BUFFER_CONSTRUCTOR =
direct.getClass().getDeclaredConstructor(long.class, int.class)
}
五) 現(xiàn)在回到第 2 步驟,發(fā)現(xiàn) PlatformDependent.useDirectBufferNoCleaner () 在 jdk 高版本下默認(rèn)值是 false。那么每次申請直接內(nèi)存都是通過 ByteBuffer.allocateDirect 來創(chuàng)建。那么到這個時候就已經(jīng)定位到相關(guān)根因了,通過 ByteBuffer.allocateDirect 來申請直接內(nèi)存,如果內(nèi)存不足的時候會強制系統(tǒng) System.Gc (),并且會同步等待 DirectByteBuffer 通過 Cleaner 的虛引用回收內(nèi)存。下面是 ByteBuffer.allocateDirect 預(yù)占內(nèi)存(reserveMemory)的關(guān)鍵代碼。大概邏輯是 觸達申請的最大的直接內(nèi)存 -> 判斷是否有相關(guān)的對象在 gc 回收 -> 沒有在回收則主動觸發(fā) System.gc () 來觸發(fā)回收 -> 在同步循環(huán)最多等待 MAX_SLEEPS 次數(shù)看是否有足夠的直接內(nèi)存。整個同步等待邏輯在親測在 jdk17 版本最多能 1 秒以上。
所以最根本原因:如果這個時候我們的 netty 的消費者 EventLoop 處理消費因為申請直接內(nèi)存在達到最大內(nèi)存的場景,那么就會導(dǎo)致有大量的任務(wù)消費都會同步去等待申請直接內(nèi)存上。并且如果沒有足夠的的直接內(nèi)存,那么就會成為大面積的消費阻塞。
static void reserveMemory(long size, long cap) {
if (!MEMORY_LIMIT_SET && VM.initLevel() >= 1) {
MAX_MEMORY = VM.maxDirectMemory();
MEMORY_LIMIT_SET = true;
}
// optimist!
if (tryReserveMemory(size, cap)) {
return;
}
final JavaLangRefAccess jlra = SharedSecrets.getJavaLangRefAccess();
boolean interrupted = false;
try {
do {
try {
refprocActive = jlra.waitForReferenceProcessing();
} catch (InterruptedException e) {
// Defer interrupts and keep trying.
interrupted = true;
refprocActive = true;
}
if (tryReserveMemory(size, cap)) {
return;
}
} while (refprocActive);
// trigger VM's Reference processing
System.gc();
int sleeps = 0;
while (true) {
if (tryReserveMemory(size, cap)) {
return;
}
if (sleeps >= MAX_SLEEPS) {
break;
}
try {
if (!jlra.waitForReferenceProcessing()) {
Thread.sleep(sleepTime);
sleepTime <<= 1;
sleeps++;
}
} catch (InterruptedException e) {
interrupted = true;
}
}
// no luck
throw new OutOfMemoryError
("Cannot reserve "
+ size + " bytes of direct buffer memory (allocated: "
+ RESERVED_MEMORY.get() + ", limit: " + MAX_MEMORY +")");
} finally {
if (interrupted) {
// don't swallow interrupts
Thread.currentThread().interrupt();
}
}
}
六) 雖然我們看到了阻塞的原因,但是為什么 jdk8 下為什么就不會阻塞從 4 步驟中看到 java 9 以下是設(shè)置了 DIRECT_BUFFER_CONSTRUCTOR 的,因此采用的是 PlatformDependent.allocateDirectNoCleaner 進行內(nèi)存分配。以下是具體的介紹和關(guān)鍵代碼
步驟一:申請內(nèi)存前:通過全局內(nèi)存計數(shù)器DIRECT_MEMORY_COUNTER,在每次申請內(nèi)存的時候調(diào)用 incrementMemoryCounter 增加相關(guān)的 size,如果達到相關(guān) DIRECT_MEMORY_LIMIT (默認(rèn)是 - XX:MaxDirectMemorySize) 參數(shù)則直接拋出異常,而不會去同步 gc 等待導(dǎo)致大量耗時。。
步驟二:分配內(nèi)存 allocateDirectNoCleaner: 是通過 unsafe 去申請內(nèi)存,再用構(gòu)造器DIRECT_BUFFER_CONSTRUCTOR通過內(nèi)存地址和大小來構(gòu)造 DirectBuffer。釋放也可以通過 unsafe.freeMemory 根據(jù)內(nèi)存地址來釋放相關(guān)內(nèi)存,而不是通過 java 自帶的 cleaner 來釋放內(nèi)存。
public static ByteBuffer allocateDirectNoCleaner(int capacity) {
assert USE_DIRECT_BUFFER_NO_CLEANER;
incrementMemoryCounter(capacity);
try {
return PlatformDependent0.allocateDirectNoCleaner(capacity);
} catch (Throwable e) {
decrementMemoryCounter(capacity);
throwException(e);
return null; }
}
private static void incrementMemoryCounter(int capacity) {
if (DIRECT_MEMORY_COUNTER != null) {
long newUsedMemory = DIRECT_MEMORY_COUNTER.addAndGet(capacity);
if (newUsedMemory > DIRECT_MEMORY_LIMIT) {
DIRECT_MEMORY_COUNTER.addAndGet(-capacity);
throw new OutOfDirectMemoryError("failed to allocate " + capacity
+ " byte(s) of direct memory (used: " + (newUsedMemory - capacity)
+ ", max: " + DIRECT_MEMORY_LIMIT + ')');
}
}
}
static ByteBuffer allocateDirectNoCleaner(int capacity) {
return newDirectBuffer(UNSAFE.allocateMemory(Math.max(1, capacity)), capacity);
}
經(jīng)過上述的源碼分析,已經(jīng)看到了根本原因,就是 ByteBuffer.allocateDirect gc 同步等待直接內(nèi)存釋放導(dǎo)致消費能力嚴(yán)重不足導(dǎo)致的,并且在最大直接內(nèi)存不足的情況下,大面積的消費阻塞耗時在申請直接內(nèi)存,導(dǎo)致消費 WriteTask 能力接近于 0,內(nèi)存從而無法下降
總結(jié)
1. 流程圖: 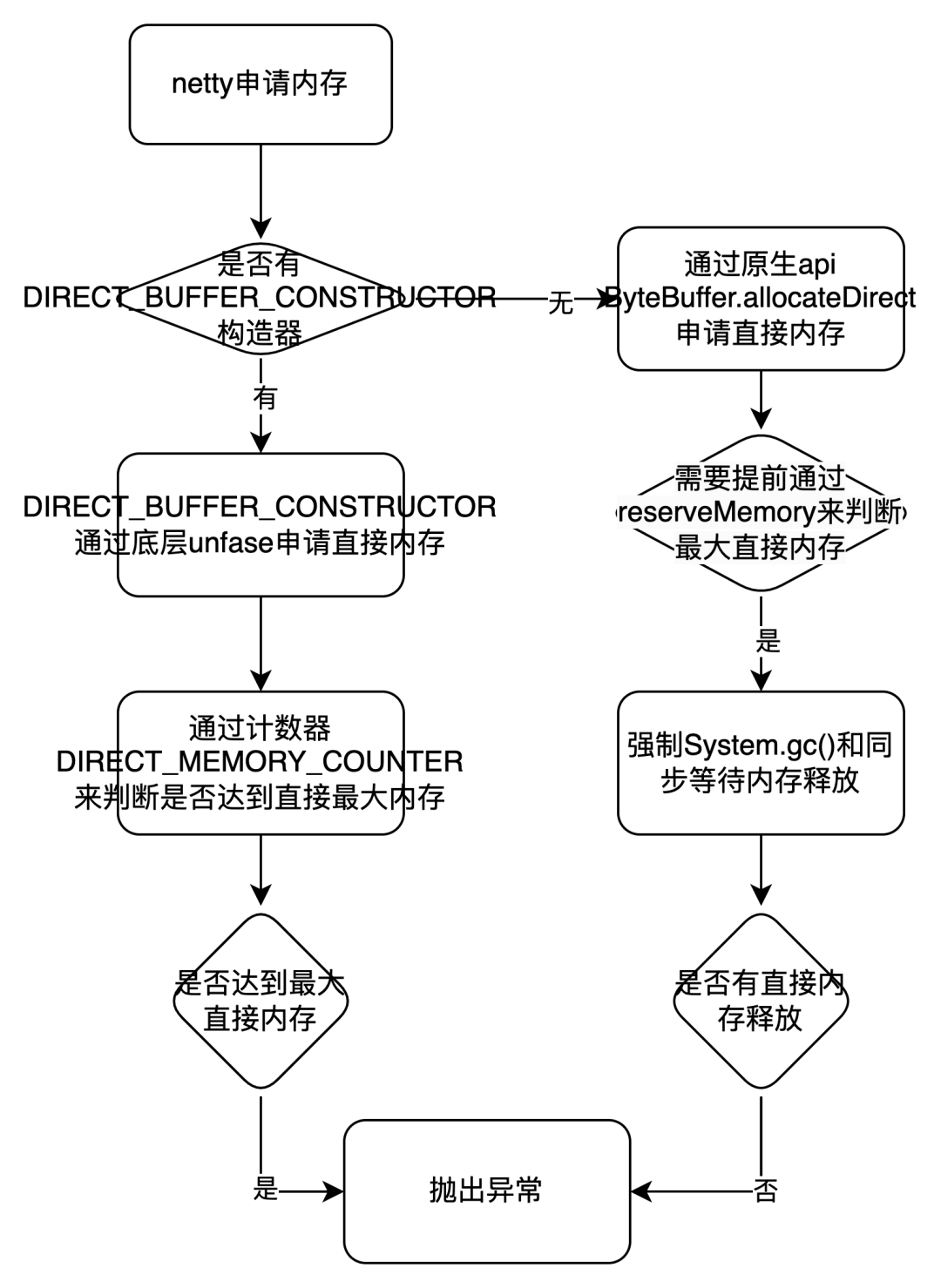 2. 直接原因:
2. 直接原因:
跨數(shù)據(jù)中心同步數(shù)據(jù)單 channel 管道同步數(shù)據(jù)能力不足,導(dǎo)致 tcp 環(huán)阻塞。從而導(dǎo)致 netty eventLoop 的消費 WriteTask 任務(wù) (WriteAndFlush) 中的 write 能力大于 flush 能力,因此申請的大量的直接內(nèi)存存放在 ChannelOutboundBuffer#unflushedEntry 鏈表中沒法 flush。
3. 根本原因:
netty 在 jdk 高版本需要手動添加 jvm 參數(shù) -add-opens=java.base/java.nio=ALL-UNNAMED 和 - io.netty.tryReflectionSetAccessible 來開啟采用直接調(diào)用底層 unsafe 來申請內(nèi)存,如果不開啟那么 netty 申請內(nèi)存采用 ByteBuffer.allocateDirect 來申請直接內(nèi)存,如果 EventLoop 消費任務(wù)申請的直接內(nèi)存達到最大直接內(nèi)存場景,那么就會導(dǎo)致有大量的任務(wù)消費都會同步去等待申請直接內(nèi)存上。并且如果沒有釋放足夠的直接內(nèi)存,那么就會成為大面積的消費阻塞,也同時導(dǎo)致大量的對象累積在 netty 的無界隊列 MpscUnboundedArrayQueue 中。
4. 反思與定位問題慢的原因:
默認(rèn)同步數(shù)據(jù)這里不會是系統(tǒng)瓶頸,沒有加上 lowWaterMark 和 highWaterMark 水位線的判斷(socketChannel.isWritable ()),如果同步數(shù)據(jù)達到系統(tǒng)瓶頸應(yīng)該提前能感知到拋出異常。
同步數(shù)據(jù)的時候調(diào)用 writeAndFlush 應(yīng)該加上相關(guān)的異常監(jiān)聽器(以下代碼 2),若果能提前感知到異常 OutOfMemoryError 那么更方便排查到相關(guān)問題。
(1)ChannelFuture writeAndFlush(Object msg) (2)ChannelFuture writeAndFlush(Object msg, ChannelPromise promise);
jdk17 下監(jiān)控系統(tǒng)看到的非堆內(nèi)存監(jiān)控并未與系統(tǒng)實際使用的直接內(nèi)存統(tǒng)計一致,導(dǎo)致開始定位問題無法定位到直接內(nèi)存已經(jīng)達到最大值,從而并未往這個方案思考。
相關(guān)引用的中間件底層通信也是依賴于 netty 通信,如果有類似的數(shù)據(jù)同步也可能會觸發(fā)類似的問題。特別 ump 在高版本和 titan 使用 netty 的時候是進行了 shade 打包的,并且相關(guān)的 jvm 參數(shù)也被修改,雖然不會觸發(fā)該 bug,但是也可能導(dǎo)致觸發(fā)系統(tǒng) gc。
ump高版本:jvm參數(shù)修改(低版本直接采用了底層socket通信,未使用netty和創(chuàng)建ByteBuffer) io.netty.tryReflectionSetAccessible->ump.profiler.shade.io.netty.tryReflectionSetAccessible titan:jvm參數(shù)修改:io.netty.tryReflectionSetAccessible->titan.profiler.shade.io.netty.tryReflectionSetAccessible
審核編輯:湯梓紅
-
cpu
+關(guān)注
關(guān)注
68文章
11074瀏覽量
216893 -
數(shù)據(jù)中心
+關(guān)注
關(guān)注
16文章
5218瀏覽量
73464 -
TCP
+關(guān)注
關(guān)注
8文章
1402瀏覽量
80960 -
內(nèi)存計算
+關(guān)注
關(guān)注
1文章
15瀏覽量
12239
原文標(biāo)題:jdk17下netty導(dǎo)致堆內(nèi)存瘋漲原因排查
文章出處:【微信號:OSC開源社區(qū),微信公眾號:OSC開源社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
【原創(chuàng)】堆內(nèi)存的那些事
分享一種內(nèi)存泄漏定位排查技巧
用rt_memheap_init分配堆內(nèi)存初始化失敗是何原因?怎么解決?
花旗:這五個原因或?qū)⑼苿犹O果股票明年瘋漲
比特幣瘋漲背后的四個原因以及是否存在騙局的分析
什么是堆內(nèi)存?堆內(nèi)存是如何分配的?
netty推送消息接口及實現(xiàn)
一步步解決長連接Netty服務(wù)內(nèi)存泄漏
什么是堆內(nèi)存?存儲方式是什么樣的?

JDK11升級JDK17最全實踐

java內(nèi)存溢出排查方法
Java怎么排查oom異常
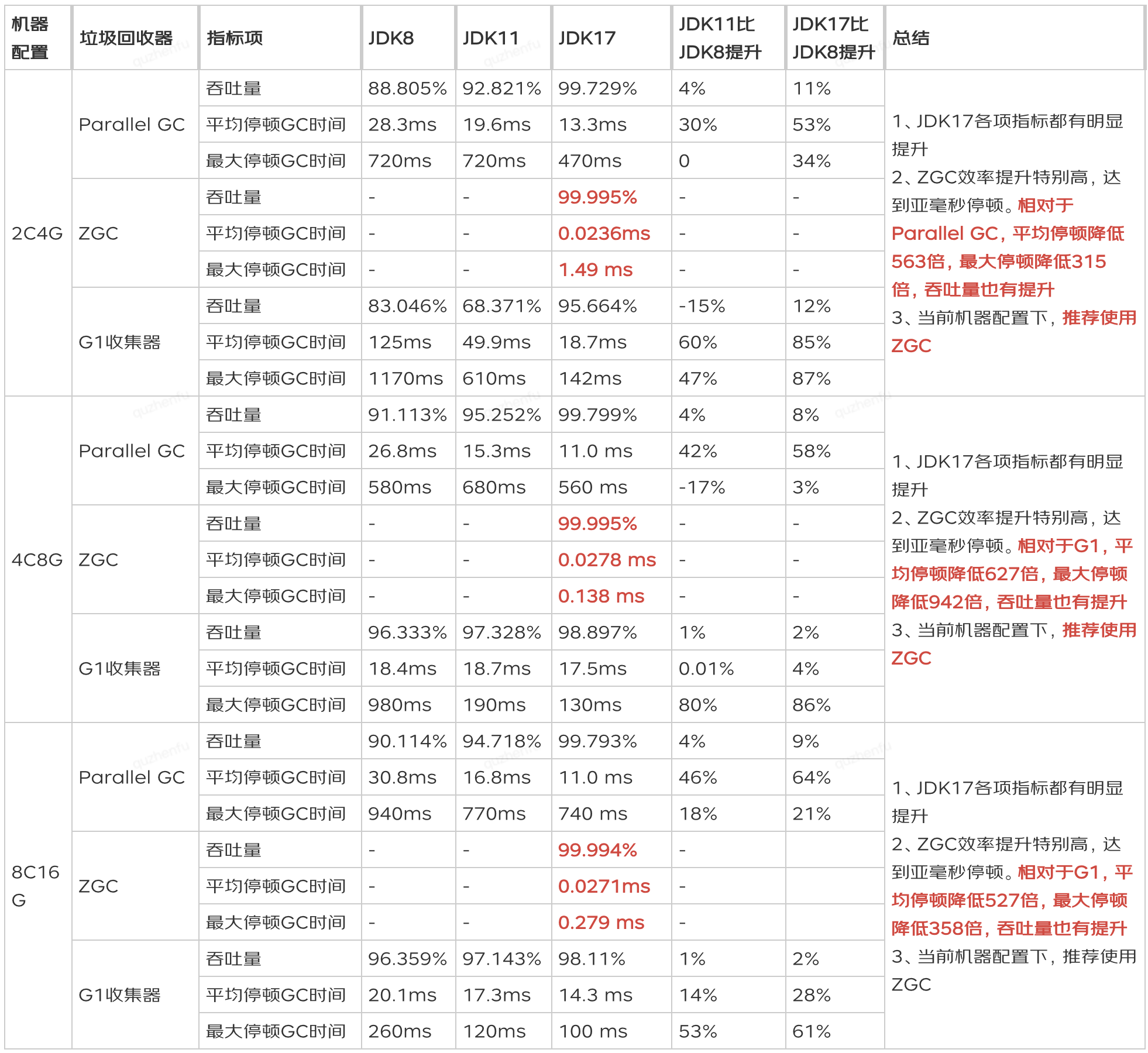
JDK11升級JDK17最全實踐干貨來了
鉍金屬瘋漲:中低溫焊錫膏中的鉍金屬何去何從?及其在戰(zhàn)爭中的應(yīng)用探索






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論