") NeurIPS 2023 | 擴散模型解決多任務強化學習問題
NeurIPS 2023 | 擴散模型解決多任務強化學習問題

擴散模型(diffusion model)在 CV 領(lǐng)域甚至 NLP 領(lǐng)域都已經(jīng)有了令人印象深刻的表現(xiàn)。最近的一些工作開始將 diffusion model 用于強化學習(RL)中來解決序列決策問題,它們主要利用 diffusion model 來建模分布復雜的軌跡或提高策略的表達性。
但是, 這些工作仍然局限于單一任務單一數(shù)據(jù)集,無法得到能同時解決多種任務的通用智能體。那么,diffusion model 能否解決多任務強化學習問題呢?我們最近提出的一篇新工作——“Diffusion Model is an Effective Planner and Data Synthesizer for Multi-Task Reinforcement Learning”,旨在解決這個問題并希望啟發(fā)后續(xù)通用決策智能的研究:

論文鏈接:
https://arxiv.org/abs/2305.18459

背景
數(shù)據(jù)驅(qū)動的大模型在 CV 和 NLP 領(lǐng)域已經(jīng)獲得巨大成功,我們認為這背后源于模型的強表達性和數(shù)據(jù)集的多樣性和廣泛性。基于此,我們將最近出圈的生成式擴散模型(diffusion model)擴展到多任務強化學習領(lǐng)域(multi-task reinforcement learning),利用 large-scale 的離線多任務數(shù)據(jù)集訓練得到通用智能體。 目前解決多任務強化學習的工作大多基于 Transformer 架構(gòu),它們通常對模型的規(guī)模,數(shù)據(jù)集的質(zhì)量都有很高的要求,這對于實際訓練來說是代價高昂的。基于 TD-learning 的強化學習方法則常常面臨 distribution-shift 的挑戰(zhàn),在多任務數(shù)據(jù)集下這個問題尤甚,而我們將序列決策過程建模成條件式生成問題(conditional generative process),通過最大化 likelihood 來學習,有效避免了 distribution shift 的問題。

方法
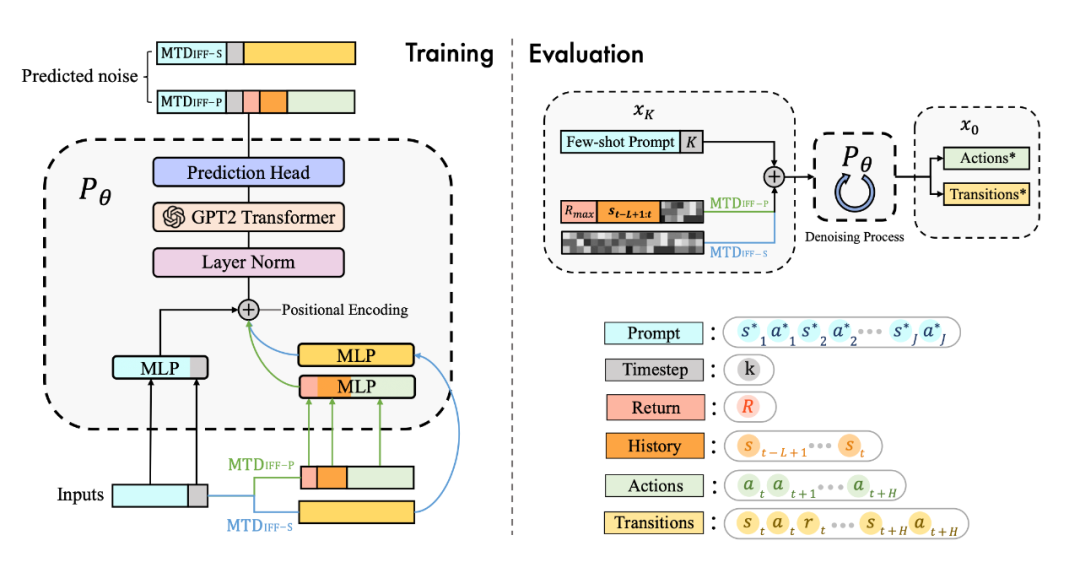
具體來說,我們發(fā)現(xiàn) diffusion model 不僅能很好地輸出 action 進行實時決策,同樣能夠建模完整的(s,a,r,s')的 transition 來生成數(shù)據(jù)進行數(shù)據(jù)增強提升強化學習策略的性能,具體框架如圖所示:
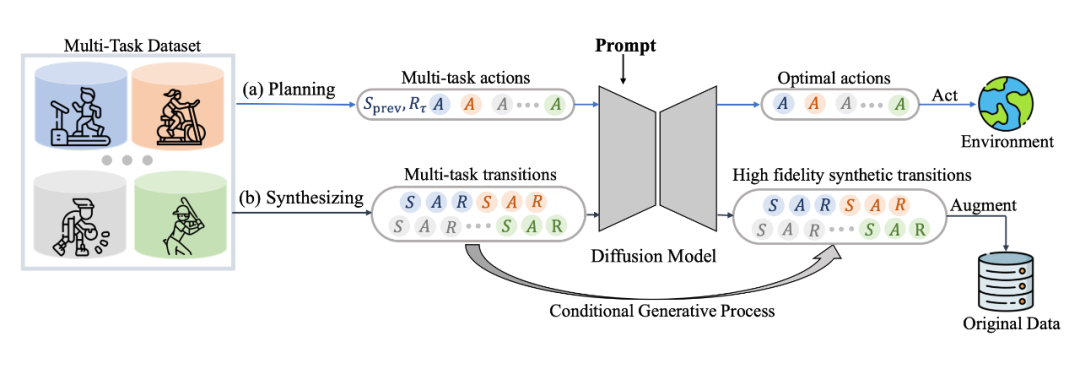
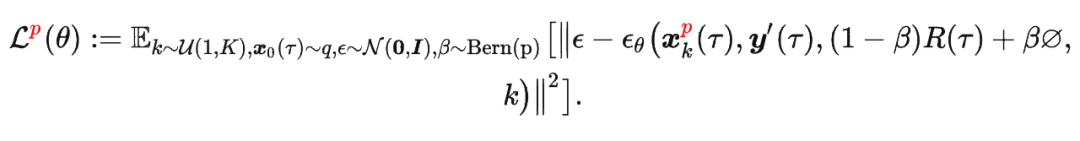 其中
其中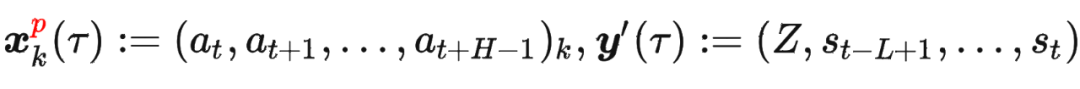 是軌跡的標準化累積回報, 是 Demonstration Prompt,可以表示為:
是軌跡的標準化累積回報, 是 Demonstration Prompt,可以表示為:

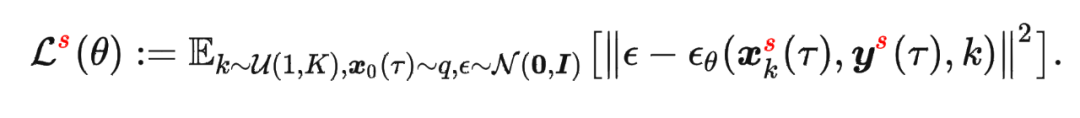 其中
其中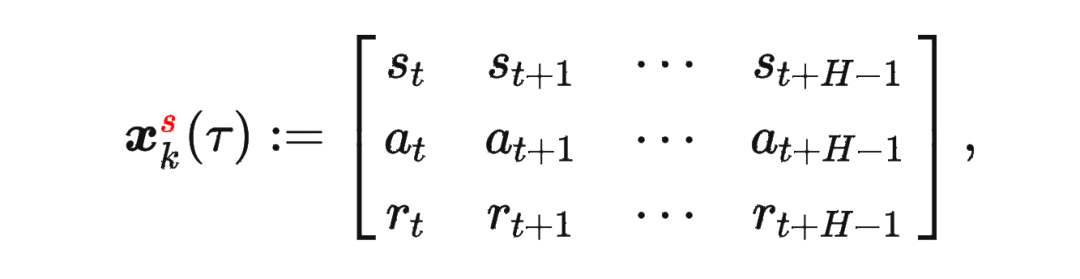
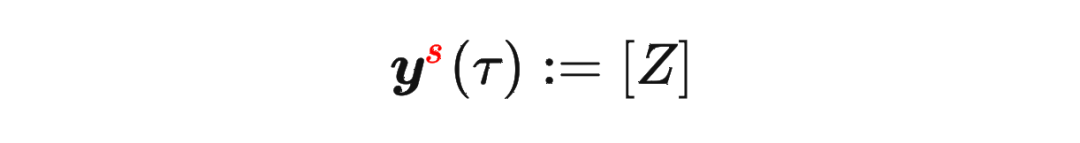

模型結(jié)構(gòu)
為了更好地建模多任務數(shù)據(jù),并且統(tǒng)一多樣化的輸入數(shù)據(jù),我們用 transformer 架構(gòu)替換了傳統(tǒng)的 U-Net 網(wǎng)絡,網(wǎng)絡結(jié)構(gòu)圖如下:

實驗
我們首先在 Meta-World MT50 上開展實驗并與 baselines 進行比較,我們在兩種數(shù)據(jù)集上進行實驗,分別是包含大量專家數(shù)據(jù),從 SAC-single-agent 中的 replay buffer 中收集到的 Near-optimal data(100M);以及從 Near-optimal data 中降采樣得到基本不包含專家數(shù)據(jù)的 Sub-optimal data(50M)。實驗結(jié)果如下:
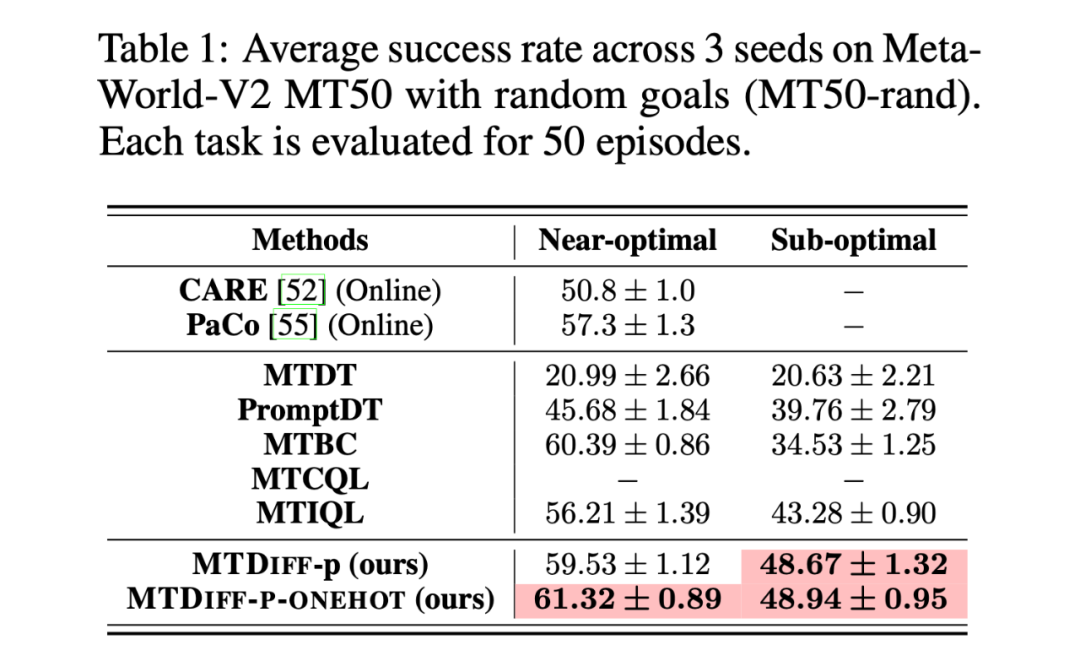
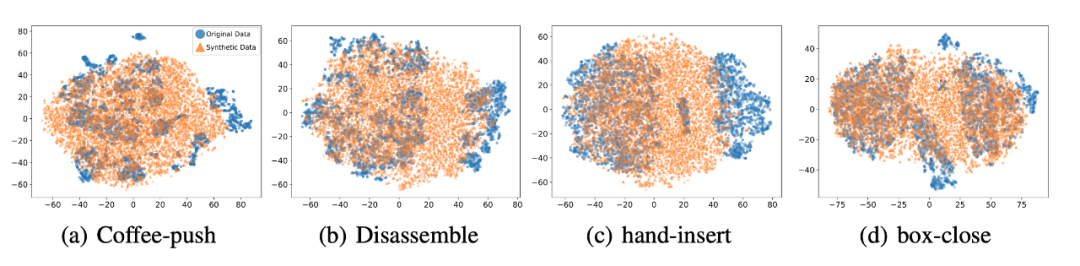
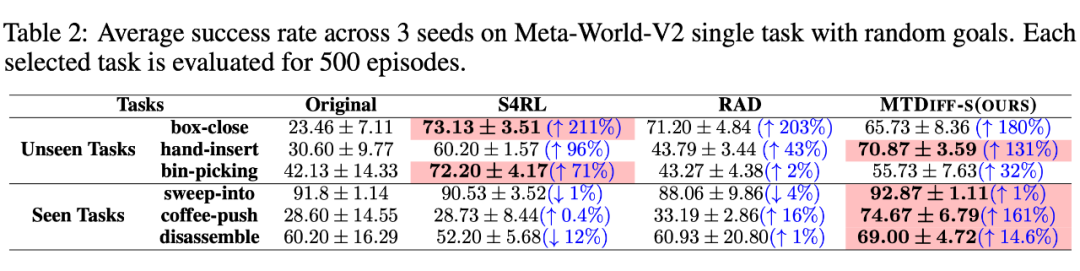 我們選取 45 個任務的 Near-optimal data 訓練 ,從表中我們可以觀察到在 見過的任務上,我們的方法均取得了最好的性能。甚至給定一段 demonstration prompt, 能泛化到?jīng)]見過的任務上并取得較好的表現(xiàn)。我們選取四個任務對原數(shù)據(jù)和 生成的數(shù)據(jù)做 T-SNE 可視化分析,發(fā)現(xiàn)我們生成的數(shù)據(jù)的分布基本匹配原數(shù)據(jù)分布,并且在不偏離的基礎(chǔ)上擴展了分布,使數(shù)據(jù)覆蓋更加全面。
我們選取 45 個任務的 Near-optimal data 訓練 ,從表中我們可以觀察到在 見過的任務上,我們的方法均取得了最好的性能。甚至給定一段 demonstration prompt, 能泛化到?jīng)]見過的任務上并取得較好的表現(xiàn)。我們選取四個任務對原數(shù)據(jù)和 生成的數(shù)據(jù)做 T-SNE 可視化分析,發(fā)現(xiàn)我們生成的數(shù)據(jù)的分布基本匹配原數(shù)據(jù)分布,并且在不偏離的基礎(chǔ)上擴展了分布,使數(shù)據(jù)覆蓋更加全面。

總結(jié)
我們提出了一種基于擴散模型(diffusion model)的一種新的、通用性強的多任務強化學習解決方案,它不僅可以通過單個模型高效完成多任務決策,而且可以對原數(shù)據(jù)集進行增強,從而提升各種離線算法的性能。我們未來將把 遷移到更加多樣、更加通用的場景,旨在深入挖掘其出色的生成能力和數(shù)據(jù)建模能力,解決更加困難的任務。同時,我們會將 遷移到真實控制場景,并嘗試優(yōu)化其推理速度以適應某些需要高頻控制的任務。
原文標題:NeurIPS 2023 | 擴散模型解決多任務強化學習問題
文章出處:【微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學習之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
物聯(lián)網(wǎng)
+關(guān)注
關(guān)注
2930文章
46151瀏覽量
391117
原文標題:NeurIPS 2023 | 擴散模型解決多任務強化學習問題
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
熱點推薦
快速入門——LuatOS:sys庫多任務管理實戰(zhàn)攻略!
在嵌入式開發(fā)中,多任務管理是提升系統(tǒng)效率的關(guān)鍵。本教程專為快速入門設計,聚焦LuatOS的sys庫,通過實戰(zhàn)案例帶你快速掌握多任務創(chuàng)建、調(diào)度與同步技巧。無論你是零基礎(chǔ)新手還是希望快速提升開發(fā)效率
18個常用的強化學習算法整理:從基礎(chǔ)方法到高級模型的理論技術(shù)與代碼實現(xiàn)
本來轉(zhuǎn)自:DeepHubIMBA本文系統(tǒng)講解從基本強化學習方法到高級技術(shù)(如PPO、A3C、PlaNet等)的實現(xiàn)原理與編碼過程,旨在通過理論結(jié)合代碼的方式,構(gòu)建對強化學習算法的全面理解。為確保內(nèi)容

詳解RAD端到端強化學習后訓練范式
受限于算力和數(shù)據(jù),大語言模型預訓練的 scalinglaw 已經(jīng)趨近于極限。DeepSeekR1/OpenAl01通過強化學習后訓練涌現(xiàn)了強大的推理能力,掀起新一輪技術(shù)革新。

了解DeepSeek-V3 和 DeepSeek-R1兩個大模型的不同定位和應用選擇
專業(yè)數(shù)據(jù)
注入大量數(shù)學/科學文獻與合成推理數(shù)據(jù)
微調(diào)策略
多任務聯(lián)合訓練
推理鏈強化學習(RLCF)+ 符號蒸餾
推理效率
均衡優(yōu)化(適合常規(guī)任務)
針對長邏輯鏈的并行加速技術(shù)
4. 典型應用場
發(fā)表于 02-14 02:08
【「基于大模型的RAG應用開發(fā)與優(yōu)化」閱讀體驗】+大模型微調(diào)技術(shù)解讀
Tuning)和Prompt-Tuning:通過在輸入序列中添加特定提示來引導模型生成期望的輸出,簡單有效,適用于多種任務。P-Tuning v1和P-Tuning v2:基于多任務學習
發(fā)表于 01-14 16:51
基于移動自回歸的時序擴散預測模型
回歸取得了比傳統(tǒng)基于噪聲的擴散模型更好的生成效果,并且獲得了人工智能頂級會議 NeurIPS 2024 的 best paper。 然而在時間序列預測領(lǐng)域,當前主流的擴散方法還是傳統(tǒng)的
智譜推出深度推理模型GLM-Zero預覽版
近日,智譜公司正式發(fā)布了其深度推理模型GLM-Zero的預覽版——GLM-Zero-Preview。這款模型標志著智譜在擴展強化學習技術(shù)訓練推理模型方面的重大突破,成為其首個專注于增強
智譜GLM-Zero深度推理模型預覽版正式上線
近日,智譜公司宣布其深度推理模型GLM-Zero的初代版本——GLM-Zero-Preview已正式上線。這款模型是智譜首個基于擴展強化學習技術(shù)訓練的推理模型,標志著智譜在AI推理領(lǐng)域
浙大、微信提出精確反演采樣器新范式,徹底解決擴散模型反演問題
隨著擴散生成模型的發(fā)展,人工智能步入了屬于?AIGC?的新紀元。擴散生成模型可以對初始高斯噪聲進行逐步去噪而得到高質(zhì)量的采樣。當前,許多應用都涉及擴

螞蟻集團收購邊塞科技,吳翼出任強化學習實驗室首席科學家
近日,專注于模型賽道的初創(chuàng)企業(yè)邊塞科技宣布被螞蟻集團收購。據(jù)悉,此次交易完成后,邊塞科技將保持獨立運營,而原投資人已全部退出。 與此同時,螞蟻集團近期宣布成立強化學習實驗室,旨在推動大模型強化
如何使用 PyTorch 進行強化學習
強化學習(Reinforcement Learning, RL)是一種機器學習方法,它通過與環(huán)境的交互來學習如何做出決策,以最大化累積獎勵。PyTorch 是一個流行的開源機器學習庫,
擴散模型的理論基礎(chǔ)
擴散模型的迅速崛起是過去幾年機器學習領(lǐng)域最大的發(fā)展之一。在這本簡單易懂的指南中,學習你需要知道的關(guān)于擴散

谷歌AlphaChip強化學習工具發(fā)布,聯(lián)發(fā)科天璣芯片率先采用
近日,谷歌在芯片設計領(lǐng)域取得了重要突破,詳細介紹了其用于芯片設計布局的強化學習方法,并將該模型命名為“AlphaChip”。據(jù)悉,AlphaChip有望顯著加速芯片布局規(guī)劃的設計流程,并幫助芯片在性能、功耗和面積方面實現(xiàn)更優(yōu)表現(xiàn)。
【《大語言模型應用指南》閱讀體驗】+ 基礎(chǔ)知識學習
今天來學習大語言模型在自然語言理解方面的原理以及問答回復實現(xiàn)。
主要是基于深度學習和自然語言處理技術(shù)。
大語言模型涉及以下幾個過程:
數(shù)據(jù)收集:大語言
發(fā)表于 08-02 11:03
【《大語言模型應用指南》閱讀體驗】+ 基礎(chǔ)篇
章節(jié)最后總結(jié)了機器學習的分類:有監(jiān)督學習、無監(jiān)督學習、半監(jiān)督學習、自監(jiān)督學習和強化學習。
1.3
發(fā)表于 07-25 14:33





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論