") RL究竟是如何與LLM做結(jié)合的?
RL究竟是如何與LLM做結(jié)合的?

RLHF 想必今天大家都不陌生,但在 ChatGPT 問世之前,將 RL 和 LM 結(jié)合起來的任務(wù)非常少見。這就導(dǎo)致此前大多做 RL 的同學(xué)不熟悉 Language Model(GPT)的概念,而做 NLP 的同學(xué)又不太了解 RL 是如何優(yōu)化的。在這篇文章中,我們將簡單介紹 LM 和 RL 中的一些概念,并分析 RL 中的「序列決策」是如何作用到 LM 中的「句子生成」任務(wù)中的,希望可以幫助只熟悉 NLP 或只熟悉 RL 的同學(xué)更快理解 RLHF 的概念。
1. RL: Policy-Based & Value Based
強(qiáng)化學(xué)習(xí)(Reinforcement Learning, RL)的核心概念可簡單概括為:一個機(jī)器人(Agent)在看到了一些信息(Observation)后,自己做出一個決策(Action),隨即根據(jù)采取決策后得到的反饋(Reward)來進(jìn)行自我學(xué)習(xí)(Learning)的過程。
光看概念或許有些抽象,我們舉個例子:現(xiàn)在有一個機(jī)器人找鉆石的游戲,機(jī)器人每次可以選擇走到相鄰的格子,如果碰到火焰會被燒死,如果碰到鉆石則通關(guān)。
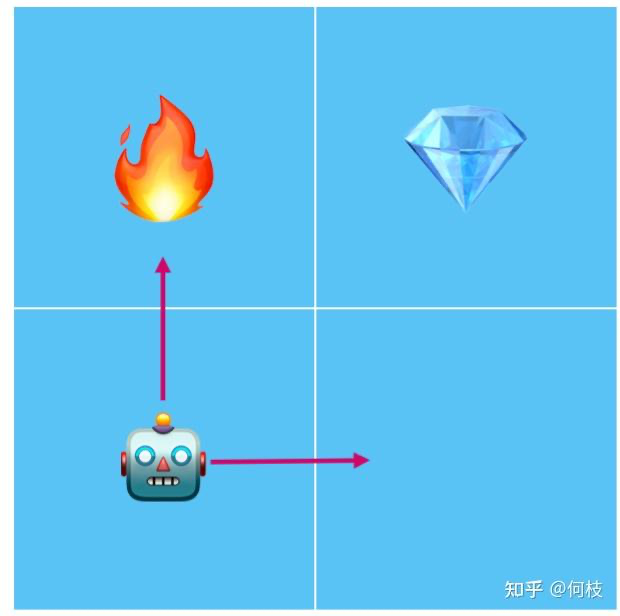
機(jī)器人找鉆石的例子:碰到火焰則會被燒死
在這個游戲中,機(jī)器人(Agent)會根據(jù)當(dāng)前自己的所在位置(Observation),做出一次行為選擇(Action):
如果它此時選擇「往上走」,則會碰到火焰,此時會得到一個來自游戲的負(fù)反饋(Reward),于是機(jī)器人會根據(jù)當(dāng)前的反饋進(jìn)行學(xué)習(xí)(Learning),總結(jié)出「在當(dāng)前的位置」「往上走」是一次錯誤的決策。
如果它此時選擇「向右走」,則不會碰到火焰,并且因?yàn)殡x鉆石目標(biāo)更近了一步,此時會得到一個來自游戲的正反饋(Reward),于是機(jī)器人會根據(jù)當(dāng)前的反饋進(jìn)行學(xué)習(xí)(Learning),總結(jié)出「在當(dāng)前位置」「往右走」是一次相對安全的決策。
通過這個例子我們可以看出,RL 的最終目標(biāo)其實(shí)就是要讓機(jī)器人(Agent)學(xué)會:在一個給定「狀態(tài)」下,選擇哪一個「行為」是最優(yōu)的。
一種很直覺的思路就是:我們讓機(jī)器人不斷的去玩游戲,當(dāng)它每次選擇一個行為后,如果這個行為得到了「正獎勵」,那么下次就多選擇這個行為;如果選擇行為得到了「負(fù)懲罰」,那么下次就少選擇這個行為。
為了實(shí)現(xiàn)「多選擇得分高的行為,少選擇得分低的行為」,早期存在 2 種不同的流派:Policy Based 和 Value Based。
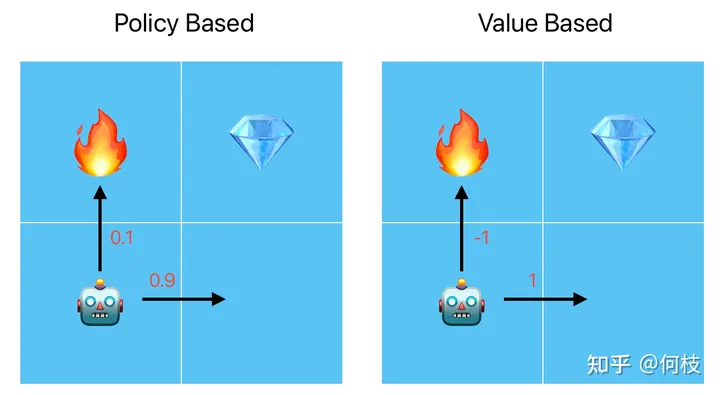
Policy Based 將行為量化為概率;Value Based 將行為量化為值
其實(shí)簡單來說,這 2 種流派的最大區(qū)別就是在于將行為量化為「概率」還是「值」,具體來講:
Policy Based:將每一個行為量化為「概率分布」,在訓(xùn)練的時候,好行為的概率值將被不斷提高(向右走,0.9),差行為的概率將被不斷降低(向上走,0.1)。當(dāng)機(jī)器人在進(jìn)行行為選擇的時候,就會按照當(dāng)前的概率分布進(jìn)行采樣,這樣就實(shí)現(xiàn)了「多選擇得分高的行為,少選擇得分低的行為」。
Value Based:將每一個行為量化為「值」,在訓(xùn)練的時候,好行為的行為值將被不斷提高(向右走,1分),差行為的行為值將被不斷降低(向上走,-1)。當(dāng)機(jī)器人在進(jìn)行行為選擇的時候會選擇「行為值最大的動作」,這樣也實(shí)現(xiàn)了「多選擇得分高的行為,少選擇得分低的行為」。
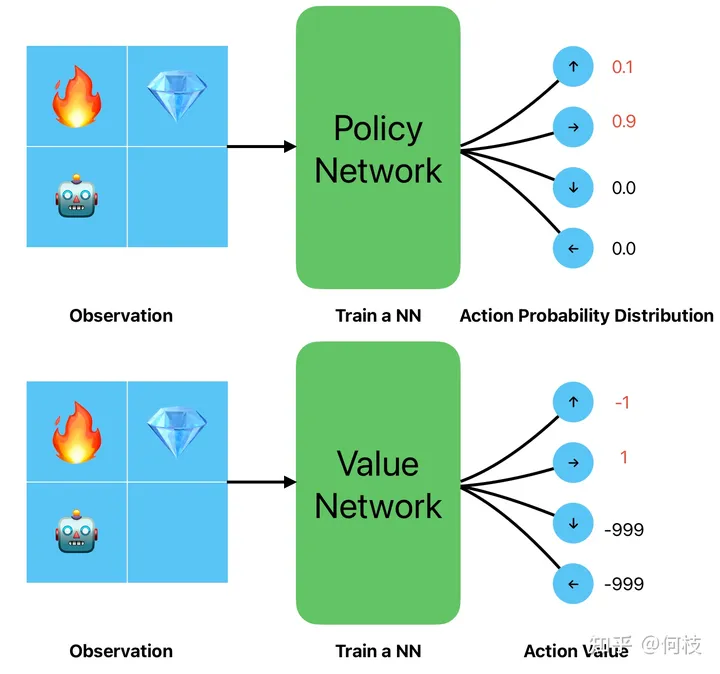
兩種策略輸入一樣,只是輸出的形式不一樣(概率 v.s. 值)
關(guān)于這 2 種流派的更多訓(xùn)練細(xì)節(jié)在這里就不再展開,如果感興趣可以看看比較出名的代表算法:[Policy Gradient](Policy Based)和 [Q-Learning](Value Based)。
講到這里,我們可以思考一下,Language Model(GPT)是屬于 Policy Based 還是 Value Based ?
為了弄明白這個問題,我們下面一起看看 GPT 是怎么工作的。
2. Language Model(GPT)是一種 Policy Based 還是一種 Value Based?
GPT 是一種 Next Token Prediction(NTP),即:給定一段話的前提下,預(yù)測這段話的下一個字是什么。
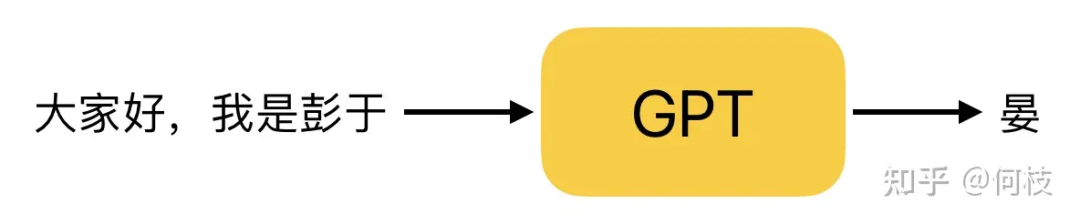
GPT 工作原理(Next Token Prediction,NTP)
而 GPT 在進(jìn)行「下一個字預(yù)測」的時候,會計(jì)算出所有漢字可能出現(xiàn)的概率,并根據(jù)這個概率進(jìn)行采樣。
在這種情況下,我們完全可以將「給定的一段話」看成是我們上一章提到的 Observation,
將「預(yù)測的下一個字」看成是上一章提到的 Action,而 GPT 就充當(dāng)了其中 Agent 的角色:
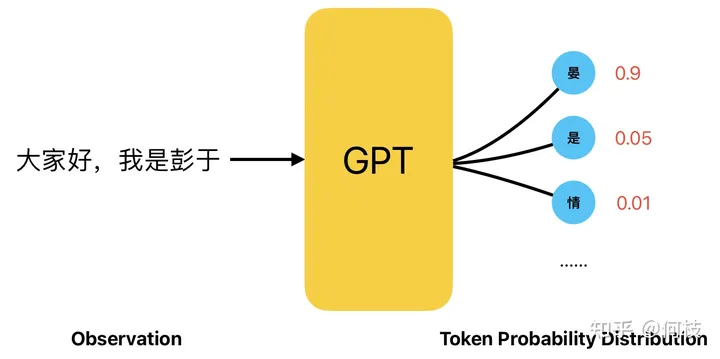
GPT 生成文本的過程,一個典型的 Policy Based 過程
如此看來,Language Model 的采樣過程其實(shí)和 Policy Based 的決策過程非常一致。
回顧一下我們之前提到過 RL 的目標(biāo):在一個給定「狀態(tài)」下,選擇哪一個「行為」是最優(yōu)的,
遷移到 GPT 生成任務(wù)上就變成了:在一個給定的「句子」下,選擇(續(xù)寫)哪一個「字」是最優(yōu)的。
因此,將 RL 中 Policy Based 的訓(xùn)練過程應(yīng)用到訓(xùn)練 GPT 生成任務(wù)里,一切都顯得非常的自然。

通過 RL 對 GPT 進(jìn)行訓(xùn)練,我們期望 GPT 能夠?qū)W會如何續(xù)寫句子才能夠得到更高的得分,
但,現(xiàn)在的問題是:游戲中機(jī)器人每走一步可以通過游戲分?jǐn)?shù)來得到 reward,GPT 生成了一個字后誰來給它 reward 呢?
3. 序列決策(Sequence Decision)以及單步獎勵(Step Reward)的計(jì)算
在第一章和第二章中,我們其實(shí)討論的都是「單步?jīng)Q策」:機(jī)器人只做一次決策,GPT 也只生成一個字。
但事實(shí)上,機(jī)器人想要拿到鉆石,通常需要做出 N 次行為選擇。
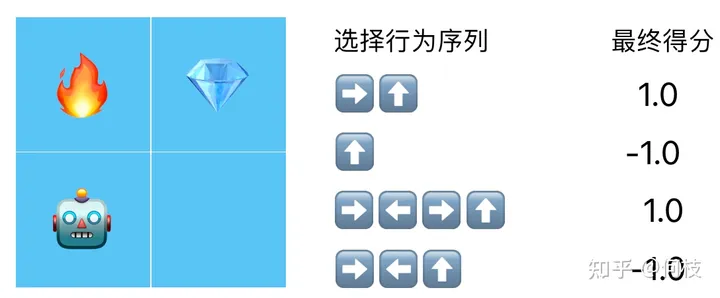
不同的行為選擇序列得到的得分:假設(shè)拿到 得1分,碰到 得-1分,其余情況不加分也不扣分
在這種情況下我們最終只有 1 個得分和 N 個行為,但是最終 RL 更新需要每個行為都要有對應(yīng)的分?jǐn)?shù),
我們該如何把這 1 個總得分對應(yīng)的分配給所有的行為呢?
答案是計(jì)算「折扣獎勵(discount reward)」。
我們認(rèn)為,越靠近最末端的行為對得分的影響越大,于是從后往前,每往前行為就乘以 1 次折扣因子 γ:
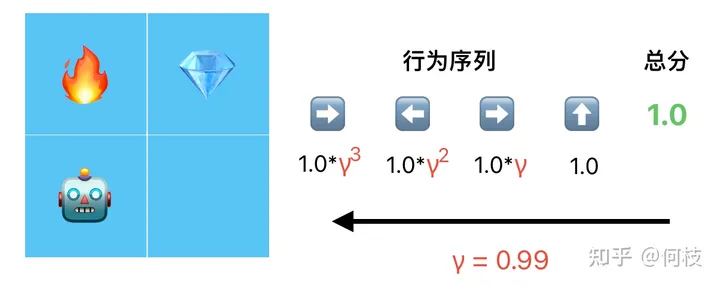
根據(jù)最終得分(total reward),從后往前倒推出每一個行為的得分(step reward)
同樣,GPT 在生成一個完整句子的過程中,也會做出 N 個行為(續(xù)寫 N 個字),
而我們在評分的時候,只會針對最后生成的完整句子進(jìn)行一個打分(而不是生成一個字打一個分),
最后,利用上述方法通過完整句子的得分倒推出每個字的對應(yīng)得分:
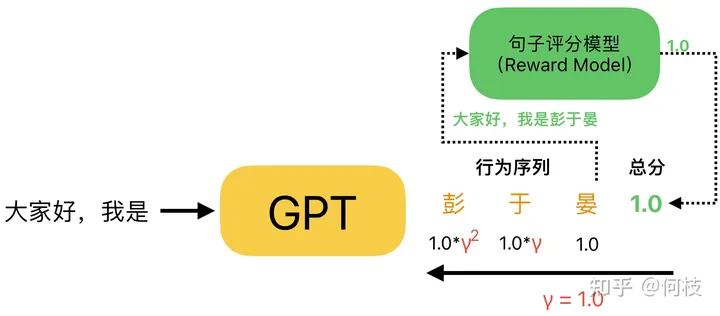
注意:在 GPT 的得分計(jì)算中,通常折扣因子(γ)取 1.0
值得注意的是:通常在對 GPT 生成句子進(jìn)行得分拆解的時候,折扣因子(γ)會取 1.0,
這意味著,在句子生成任務(wù)中,每一個字的生成都會同等重要地影響著最后生成句子的好壞。
我們可以這么理解:在找鉆石的游戲中,機(jī)器人采取了一些「不當(dāng)」的行為后是可以通過后續(xù)行為來做修正,比如機(jī)器人一開始向右走(正確行為),再向左走(不當(dāng)行為),再向右走(修正行為),再向上走(正確行為),這個序列中通過「修正行為」能夠修正「不當(dāng)行為」帶來的影響;但在句子生成任務(wù)中,一旦前面生成了一個「錯別字」,后面無論怎么生成什么樣的字都很難「修正」這個錯別字帶來的影響,因此在文本生成的任務(wù)中,每一個行為都會「同等重要」地影響最后句子質(zhì)量的好壞。
4. 加入概率差異(KL Penalty)以穩(wěn)定 RL 訓(xùn)練
除了折扣獎勵,在 OpenAI 的 [Learning to summarize from human feedback] 這篇工作中指出,
在最終生成句子的得分基礎(chǔ)上,我們還可以在每生成一個字時候,計(jì)算 RL 模型和 SFT 模型在生成當(dāng)前字的「概率差異」,并以此當(dāng)作生成當(dāng)前字的一個 step reward:

通過概率差異(KL)作為 reward 有 2 個好處:1. 避免模型崩潰到重復(fù)輸出相同的一個字(模式崩潰)。2. 限制 RL 不要探索的離一開始的模型(SFT)太遠(yuǎn)
通常在進(jìn)行 RL 訓(xùn)練時,初始都會使用 SFT 模型做初始化,隨即開始探索并學(xué)習(xí)。
由于 RL 的訓(xùn)練本質(zhì)就是:探索 + 試錯,
加上「概率差異」這一限制條件,就相當(dāng)于限制了 RL 僅在初始模型(SFT)的附近進(jìn)行探索,
這就大大縮小了 RL 的探索空間:既避免了探索到那些非常差的空間,又緩解了 Reward Model 可能很快被 Hacking 的問題。
我們舉一個具體的例子:
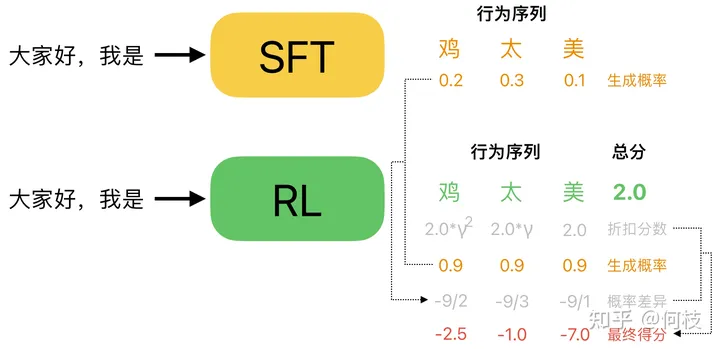
加上 KL 懲罰(概率差異)約束后的 step reward
如上圖所示,對于「大家好,我是」這個 prompt,Policy(RL)Model 認(rèn)為「雞太美」是一個很好的答案,
這可能是 Reward Model 打分不準(zhǔn)導(dǎo)致的(這很常見),上圖中 RM 給「雞太美」打出了 2 分的高分(綠色)。
但是,這樣一個不通順的句子在原始的模型(SFT Model)中被生成出來的概率往往是很低的,
因此,我們可以計(jì)算一下「雞太美」這 3 個字分別在 RL Model 和在 SFT Model 中被采樣出來的概率,
并將這個「概率差異」加到 RM 給出的「折扣分?jǐn)?shù)」中,
我們可以看到:盡管對于這個不通順的句子 RM 給了一個很高的分?jǐn)?shù),但是通過「概率差異」的修正,每個字的 reward 依然被扣除了很大的懲罰值,從而避免了這種「RM 認(rèn)為分?jǐn)?shù)很高,但實(shí)則并不通順句子」被生成出來的情況。
通過加入「概率差異」的限制,我們可以使得 RL 在 LM 的訓(xùn)練中更加穩(wěn)定,防止進(jìn)化為生成某種奇怪的句子,但又能「哄騙」Reward Model 給出很高分出的情況(RL 非常擅長這一點(diǎn))。
但,如果你的 RM 足夠的強(qiáng)大,永遠(yuǎn)無法被 Policy 給 Hack,或許你可以完全放開概率限制并讓其自由探索。
-
機(jī)器人
+關(guān)注
關(guān)注
213文章
29650瀏覽量
212304 -
強(qiáng)化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
269瀏覽量
11561 -
LLM
+關(guān)注
關(guān)注
1文章
324瀏覽量
788
原文標(biāo)題:RL 究竟是如何與 LLM 做結(jié)合的?
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄

FOC電機(jī)控制究竟該如何學(xué)?
工程師在產(chǎn)品選型的時究竟是選CAN還是CANFD接口卡呢?

室內(nèi)導(dǎo)航究竟是如何實(shí)現(xiàn)的
ADS1298R PACE_OUT1和PACE_OUT2這兩條引腿究竟是輸入還是輸出?有什么用?怎樣使用?
LoRa數(shù)據(jù)究竟是如何傳輸?shù)模?/a>

嵌入式和人工智能究竟是什么關(guān)系?
PCM1861 INT腳究竟是輸出還是輸入?
超高頻讀寫器究竟是什么,能做什么?一文讀懂!








 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論