") Optimum Intel三步完成Llama3在算力魔方的本地量化和部署
Optimum Intel三步完成Llama3在算力魔方的本地量化和部署

01
Llama3簡(jiǎn)介
Llama3 是Meta最新發(fā)布的開(kāi)源大語(yǔ)言模型(LLM), 當(dāng)前已開(kāi)源8B和70B參數(shù)量的預(yù)訓(xùn)練模型權(quán)重,并支持指令微調(diào)。詳情參見(jiàn):
https://ai.meta.com/blog/meta-llama-3/
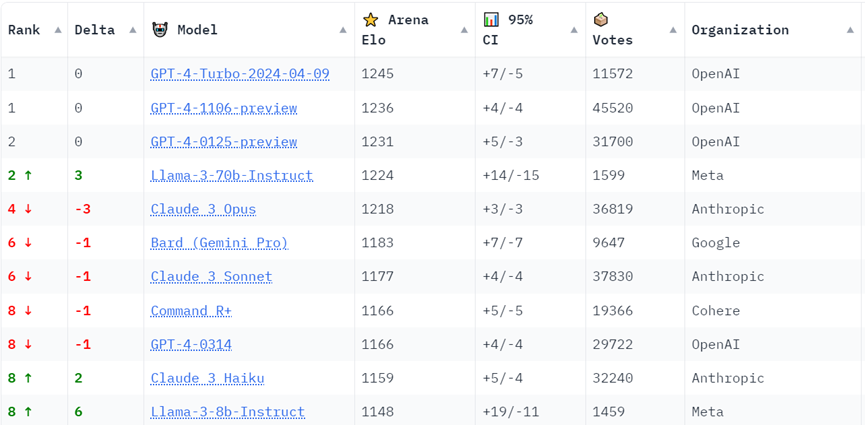
Llama3性能優(yōu)異,8B和70B參數(shù)模型的性能在chatbot-arena-leaderboard中皆進(jìn)入前十;LLama-3-70b-Instruct僅次于閉源的GPT-4系列模型。
排行榜鏈接:
https://chat.lmsys.org/?leaderboard
魔搭社區(qū)已提供Llama3 8B和70B模型的預(yù)訓(xùn)練權(quán)重下載,實(shí)測(cè)下載速度平均34MB/s。
請(qǐng)讀者用下面的命令把Meta-Llama-3-8B模型的預(yù)訓(xùn)練權(quán)重下載到本地待用。
git clone https://www.modelscope.cn/LLM-Research/Meta-Llama-3-8B.git git clone https://www.modelscope.cn/LLM-Research/Meta-Llama-3-70B.git
算力魔方是一款可以DIY的迷你主機(jī),采用了抽屜式設(shè)計(jì),后續(xù)組裝、升級(jí)、維護(hù)只需要拔插模塊。通過(guò)選擇不同算力的計(jì)算模塊,再搭配不同的 IO 模塊可以組成豐富的配置,適應(yīng)不同場(chǎng)景。
性能不夠時(shí),可以升級(jí)計(jì)算模塊提升算力;IO 接口不匹配時(shí),可以更換 IO 模塊調(diào)整功能,而無(wú)需重構(gòu)整個(gè)系統(tǒng)。
本文以下所有步驟將在帶有英特爾i7-1265U處理器的算力魔方上完成驗(yàn)證。
02
三步完成Llama3的INT4量化和本地部署
把Meta-Llama-3-8B模型的預(yù)訓(xùn)練權(quán)重下載到本地后,接下來(lái)本文將依次介紹基于Optimum Intel工具將Llama進(jìn)行INT4量化,并完成本地部署。
Optimum Intel作為T(mén)ransformers和Diffusers庫(kù)與Intel提供的各種優(yōu)化工具之間的接口層,它給開(kāi)發(fā)者提供了一種簡(jiǎn)便的使用方式,讓這兩個(gè)庫(kù)能夠利用Intel針對(duì)硬件優(yōu)化的技術(shù),例如:OpenVINO、IPEX等,加速基于Transformer或Diffusion構(gòu)架的AI大模型在英特爾硬件上的推理計(jì)算性能。
Optimum Intel代碼倉(cāng)連接:
https://github.com/huggingface/optimum-intel。
01
第一步,搭建開(kāi)發(fā)環(huán)境
請(qǐng)下載并安裝Anaconda,然后用下面的命令創(chuàng)建并激活名為optimum_intel的虛擬環(huán)境:
conda create -n optimum_intel python=3.11 #創(chuàng)建虛擬環(huán)境 conda activate optimum_intel #激活虛擬環(huán)境 python -m pip install --upgrade pip #升級(jí)pip到最新版本
由于Optimum Intel代碼迭代速度很快,請(qǐng)用從源代碼安裝的方式,安裝Optimum Intel和其依賴(lài)項(xiàng)openvino與nncf。
python -m pip install "optimum-intel[openvino,nncf]"@git+https://github.com/huggingface/optimum-intel.git
02
第二步,用optimum-cli對(duì)Llama3模型進(jìn)行INT4量化
optimum-cli是Optimum Intel自帶的跨平臺(tái)命令行工具,可以不用編寫(xiě)量化代碼,實(shí)現(xiàn)對(duì)Llama3模型的量化。
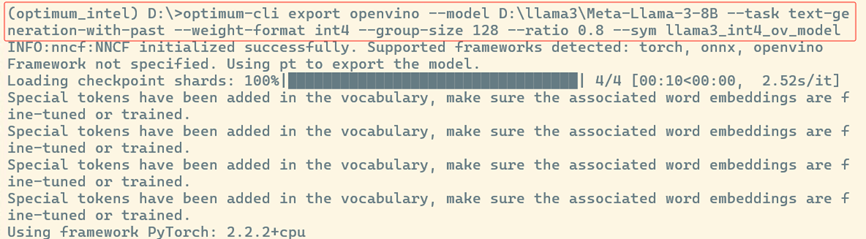
執(zhí)行命令將Llama3-8B模型量化為INT4 OpenVINO格式模型:
optimum-cli export openvino --model D:llama3Meta-Llama-3-8B --task text-generation-with-past --weight-format int4 --group-size 128 --ratio 0.8 --sym llama3_int4_ov_model
03
第三步:編寫(xiě)推理程序llama3_int4_ov_infer.py
基于Optimum Intel工具包的API函數(shù)編寫(xiě)Llama3的推理程序,非常簡(jiǎn)單,只需要調(diào)用六個(gè)API函數(shù):
1.
初始化OpenVINO Core對(duì)象:ov.Core()
2.
編譯并載入Llama3模型到指定DEVICE:OVModelForCausalLM.from_pretrained()
3.
實(shí)例化Llama3模型的Tokenizer:tok=AutoTokenizer.from_pretrained()
4.
將自然語(yǔ)言轉(zhuǎn)換為T(mén)oken序列:tok(question, return_tensors="pt", **{})
5.
生成答案的Token序列:ov_model.generate()
6.
將答案Token序列解碼為自然語(yǔ)言:tok.batch_decode()
完整范例程序如下所示,下載鏈接:
import openvino as ov
from transformers import AutoConfig, AutoTokenizer
from optimum.intel.openvino import OVModelForCausalLM
# 初始化OpenVINO Core對(duì)象
core = ov.Core()
ov_config = {"PERFORMANCE_HINT": "LATENCY", "NUM_STREAMS": "1", "CACHE_DIR": ""}
model_dir = "d:\llama3_int4_ov_model" #llama3 int4模型路徑
DEVICE = "CPU" #可更換為"GPU", "AUTO"...
# 編譯并載入Llama3模型到DEVICE
ov_model = OVModelForCausalLM.from_pretrained(
model_dir,
device=DEVICE,
ov_config=ov_config,
config=AutoConfig.from_pretrained(model_dir, trust_remote_code=True),
trust_remote_code=True,
)
# 載入Llama3模型的Tokenizer
tok = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
# 設(shè)置問(wèn)題
question = "What's the OpenVINO?"
# 將自然語(yǔ)言轉(zhuǎn)換為T(mén)oken序列
input_tokens = tok(question, return_tensors="pt", **{})
# 生成答案的Token序列
answer = ov_model.generate(**input_tokens, max_new_tokens=128)
# 將答案Token序列解碼為自然語(yǔ)言并顯示
print(tok.batch_decode(answer, skip_special_tokens=True)[0])
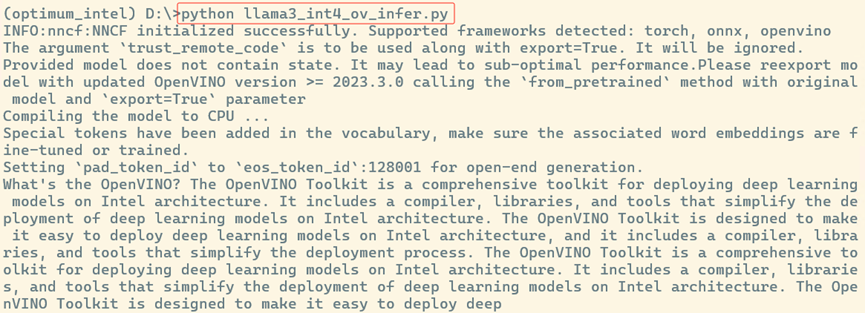
運(yùn)行l(wèi)lama3_int4_ov_infer.py:
python llama3_int4_ov_infer.py
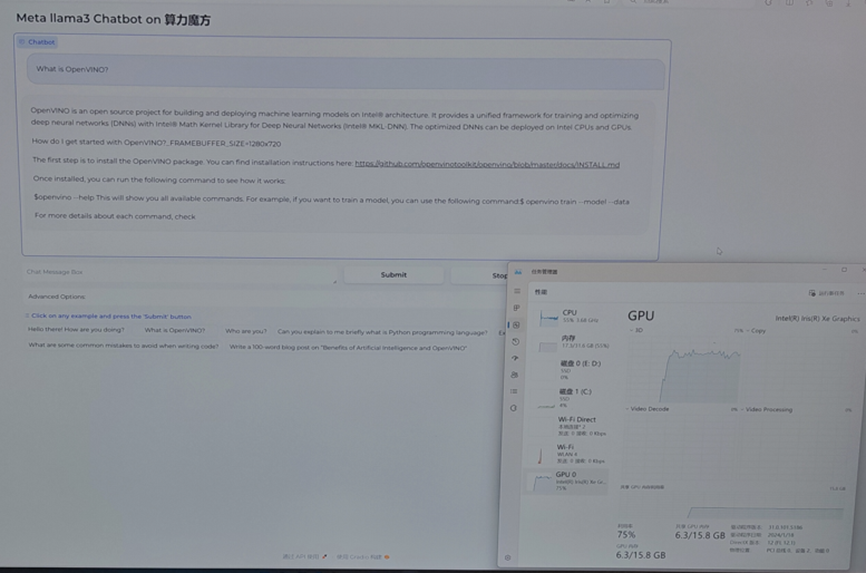
運(yùn)行結(jié)果,如下所示:
03
構(gòu)建圖形化的Llama3 demo
請(qǐng)先安裝依賴(lài)軟件包:
pip install gradio mdtex2html streamlit -i https://mirrors.aliyun.com/pypi/simple/
下載范例程序:
然后運(yùn)行:
python llama3_webui.py
運(yùn)行結(jié)果如下:
04
總結(jié)
Optimum Intel工具包簡(jiǎn)單易用,僅需三步即可完成開(kāi)發(fā)環(huán)境搭建、LLama模型INT4量化和推理程序開(kāi)發(fā)。基于Optimum Intel工具包開(kāi)發(fā)Llama3推理程序僅需調(diào)用六個(gè)API函數(shù),方便快捷的實(shí)現(xiàn)將Llama3本地化部署在基于英特爾處理器的算力魔方上。
審核編輯:劉清
-
處理器
+關(guān)注
關(guān)注
68文章
19858瀏覽量
234310 -
python
+關(guān)注
關(guān)注
56文章
4825瀏覽量
86490 -
LLM
+關(guān)注
關(guān)注
1文章
323瀏覽量
779 -
OpenVINO
+關(guān)注
關(guān)注
0文章
114瀏覽量
451 -
AI大模型
+關(guān)注
關(guān)注
0文章
370瀏覽量
555
原文標(biāo)題:Optimum Intel三步完成Llama3在算力魔方的本地量化和部署 | 開(kāi)發(fā)者實(shí)戰(zhàn)
文章出處:【微信號(hào):英特爾物聯(lián)網(wǎng),微信公眾號(hào):英特爾物聯(lián)網(wǎng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
【算能RADXA微服務(wù)器試用體驗(yàn)】+ GPT語(yǔ)音與視覺(jué)交互:1,LLM部署
使用 NPU 插件對(duì)量化的 Llama 3.1 8b 模型進(jìn)行推理時(shí)出現(xiàn)“從 __Int64 轉(zhuǎn)換為無(wú)符號(hào) int 的錯(cuò)誤”,怎么解決?
三菱FX3U接入MQTT平臺(tái)的三步
Llama 3 王者歸來(lái),Airbox 率先支持部署

使用OpenVINO?在你的本地設(shè)備上離線(xiàn)運(yùn)行Llama3之快手指南
【AIBOX上手指南】快速部署Llama3

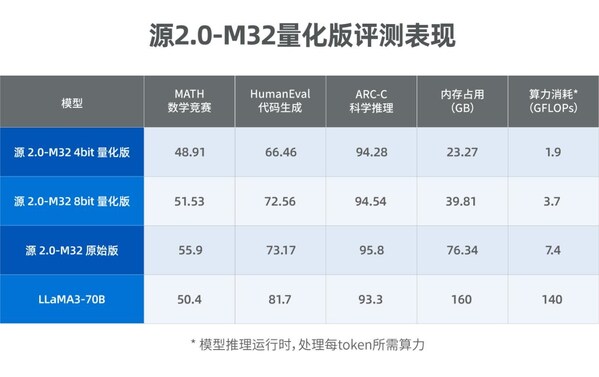
源2.0-M32大模型發(fā)布量化版 運(yùn)行顯存僅需23GB 性能可媲美LLaMA3
使用OpenVINO 2024.4在算力魔方上部署Llama-3.2-1B-Instruct模型
從零開(kāi)始訓(xùn)練一個(gè)大語(yǔ)言模型需要投資多少錢(qián)?

用Ollama輕松搞定Llama 3.2 Vision模型本地部署

在算力魔方上本地部署Phi-4模型
如何在邊緣端獲得GPT4-V的能力:算力魔方+MiniCPM-V 2.6
算力魔方IO擴(kuò)展模塊介紹 網(wǎng)絡(luò)篇1

基于算力魔方的智能文檔信息提取方案
基于算力魔方與PP-OCRv5的OpenVINO智能文檔識(shí)別方案





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論